SuperBased Observer — capture, normalize, compress, and analyze AI coding tool activity across Claude Code, Codex, Cursor, Cline/Roo, and Copilot.

Project description
superbased-observer




This is the PyPI distribution.
pip install superbased-observerbundles the same prebuilt binary that@superbased/observerships on npm — version numbers are kept in lock-step. Pick whichever package manager fits your environment; the resultingobservercommand on your$PATHis identical.
Capture, normalize, compress, and analyze every AI coding tool call you run — across Claude Code, Codex, Cursor, Cline / Roo Code, GitHub Copilot (VS Code), GitHub Copilot CLI, OpenCode, OpenClaw, Pi, Google Antigravity, Gemini CLI, and Cowork — in one local single-binary tool. No telemetry, no cloud, no data leaves your machine.
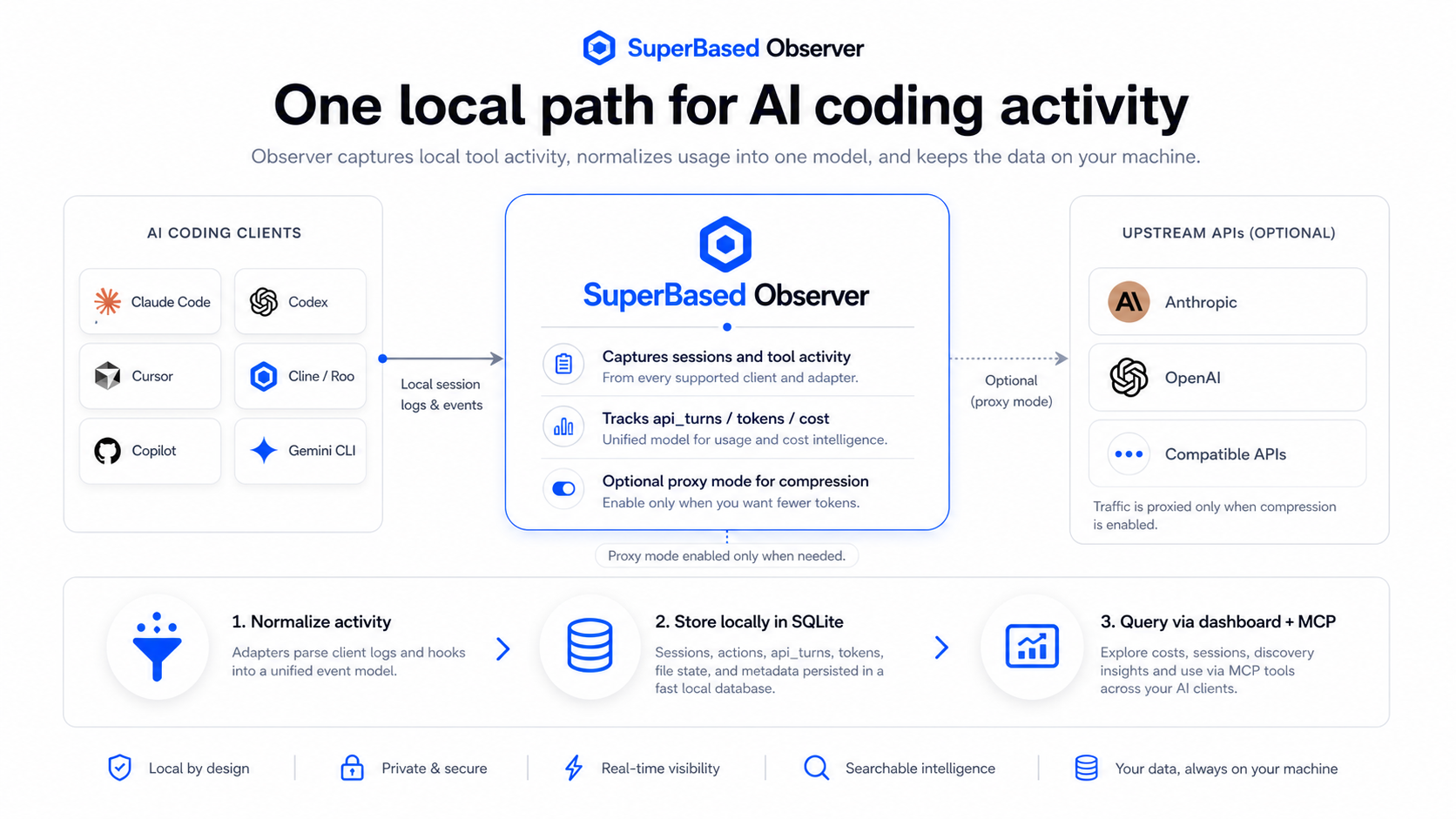
Table of contents
- Install
- Five-minute quickstart
- Per-AI-client setup
- Architecture in detail
- Dashboard tour
- MCP tools reference
- Compression mechanisms
- Cost and token math
- Terminology and glossary
- CLI reference
- Configuration
- Troubleshooting
- Security and privacy
- Source, contributing, license
Install
pip install superbased-observer
observer --version
Or with uv (recommended for tools — installs in an isolated env automatically):
uv tool install superbased-observer
observer --version
Or with pipx (same idea as uv tool):
pipx install superbased-observer
observer --version
Plain pip install --user superbased-observer works too, but
uv tool / pipx keep the install isolated from your project's
Python environment, which is generally what you want for a CLI tool.
Pre-built wheels ship for:
| Platform | Architecture | Wheel tag |
|---|---|---|
| Linux | x64 | manylinux2014_x86_64 (glibc ≥ 2.17) |
| Linux | arm64 | manylinux2014_aarch64 |
| macOS (Intel) | x64 | macosx_10_15_x86_64 |
| macOS (Apple Silicon) | arm64 | macosx_11_0_arm64 |
| Windows | x64 | win_amd64 |
Each wheel bundles its platform's prebuilt binary directly — no postinstall download, no compile step, no Go toolchain required. pip picks the right wheel for your machine automatically.
If your platform isn't listed, build from source — instructions in the main repo.
Already use @superbased/observer from npm? Don't install both
globally — whichever directory comes first on $PATH wins, which
gets confusing if their versions drift mid-upgrade. Pick one.
Five-minute quickstart
# 1) Install. `observer init` is OPTIONAL — only run it if you want
# the MCP server registered with your AI clients (gives them
# on-demand tools like check_file_freshness / get_cost_summary
# at the cost of ~1,800 tokens of schema per turn).
pip install superbased-observer # or: uv tool install superbased-observer
observer init # OPTIONAL — interactive: pick clients;
# writes MCP + codex proxy-route into AI client configs.
# Skip this step for an MCP-free install.
# 2) Start the long-running services (proxy + watcher + dashboard).
# Auto-registers HOOKS for every detected AI tool on first launch.
observer start &
# 3) Engage the proxy by pointing your AI client at the local URL.
# See "Per-AI-client setup" for the matching env var.
export ANTHROPIC_BASE_URL=http://127.0.0.1:8820 # Claude Code
export OPENAI_BASE_URL=http://127.0.0.1:8820/v1 # Codex / OpenAI
# 4) Open the dashboard.
open http://127.0.0.1:8081/ # macOS
xdg-open http://127.0.0.1:8081/ # Linux
start http://127.0.0.1:8081/ # Windows
What start does vs what init adds:
| Step | Hooks | Proxy listening | Watcher | Dashboard | MCP in AI clients | Codex proxy route |
|---|---|---|---|---|---|---|
observer start alone |
auto-registers ✓ | ✓ | ✓ | ✓ | — | — |
observer init + observer start |
✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
observer init --skip-mcp + start |
✓ | ✓ | ✓ | ✓ | — | ✓ |
MCP and codex routing are explicit-only because both write per-client
config files. Hooks self-heal on every start.
After ten minutes of normal AI-coding usage, the dashboard will be populated with cost over time, per-tool activity, compression savings, and stale-reread waste signals.
Per-AI-client setup
Different clients send to different upstreams. The local proxy on
127.0.0.1:8820 handles all of them — routes by URL path. Set the
env var that matches your client(s); both can coexist on one machine.
| AI client | Env var | Capture mode |
|---|---|---|
| Claude Code | ANTHROPIC_BASE_URL=http://127.0.0.1:8820 |
proxy + JSONL |
| Cursor (Anthropic mode) | ANTHROPIC_BASE_URL=http://127.0.0.1:8820 |
proxy + JSONL |
| Codex | OPENAI_BASE_URL=http://127.0.0.1:8820/v1 (note /v1) |
proxy + JSONL with API-key auth; ChatGPT-plan login currently behaves as JSONL only |
| Cursor (OpenAI mode) | OPENAI_BASE_URL=http://127.0.0.1:8820/v1 |
proxy + JSONL |
| Cline / Roo Code | ANTHROPIC_BASE_URL=... or OPENAI_BASE_URL=... per provider |
proxy + JSONL |
| GitHub Copilot | (no proxy yet) | JSONL only |
| OpenCode (opencode.ai) | (no proxy yet) | SQLite — actual install path is ~/.local/share/opencode/opencode.db (XDG). Captures token counts + model + cost per assistant message from OpenCode's InfoData (tokens.input/output/reasoning/cache.{read,write} + cost); subtask parts → spawn_subagent actions; todo table → todo_update actions; tool-name coverage extended to webfetch/websearch/task/todowrite/todoread/multiedit. Tagged Source=jsonl, Reliability=approximate. |
| OpenClaw (openclaw.ai) | (no proxy yet) | JSONL + sqlite — ~/.openclaw/tasks/runs.sqlite + ~/.openclaw/agents/<agent>/sessions/sessions.json |
| Pi (pi.dev) | (no proxy yet) | JSONL — ~/.pi/agent/sessions/--<path>--/*.jsonl (per upstream docs/session-format.md v3). Captures user / assistant / toolResult / bashExecution message roles; usage.cost.total → per-message USD; terminal stopReason (stop/length/error/aborted) → task_complete with success=false for failures (mid-turn toolUse is correctly skipped); thinking blocks surface as preceding reasoning. Tagged Source=jsonl, Reliability=approximate. |
| Google Antigravity | (no proxy yet) | Encrypted protobuf — ~/.gemini/antigravity/conversations/*.pb (Linux-native) and the matching Windows-side path on WSL2. Observer ships a per-OS Chromium-pattern oscrypt key fetcher (macOS Keychain / libsecret / DPAPI / WSL2-via-PowerShell helper) and a multi-cipher try-loop for local decryption. Sessions whose ciphers don't validate locally fall back to the language_server's GetCascadeTrajectory gRPC endpoint via a built-in helper (antigravity-bridge.exe on WSL2 / native gRPC elsewhere) — extracts model + per-turn token counts + Tier 0–6 ToolEvents (file views, artifact edits/writes, user prompts, assistant text, run_command terminal snapshots, structured plan steps, final summaries). State index + per-conversation title/workspace URI read from state.vscdb + state.vscdb.backup. Tagged Source=jsonl, Reliability=approximate. |
| Kilo Code IDE extension (legacy) | (no proxy yet) | JSON — <vsCodeGlobalStorage>/kilocode.kilo-code/tasks/<taskId>/api_conversation_history.json. The legacy Kilo extension is a Cline + Roo Code fork and shares the Cline parser; emitted rows are re-tagged Tool="kilo-code" so dashboard rollups don't blur Kilo activity into Cline. Tagged Source=jsonl, Reliability=approximate. |
| Kilo Code CLI (current) | Optional: OPENAI_BASE_URL=http://127.0.0.1:8820/v1 (Kilo Gateway is OpenAI-compatible at the wire) |
SQLite — ~/.local/share/kilo/kilo.db on every OS (Kilo intentionally mirrors XDG; Windows does NOT use %APPDATA%). The new @kilocode/cli (npm) is a fork of sst/opencode and uses the same message/part/todo tables shape with Kilo additions (project, workspace, event, session_message, account, permission, session_share). Captures token counts + model + cost per assistant message from message.data.tokens = {total, input, output, reasoning, cache: {read, write}}. Tool name coverage inherits OpenCode's surface (read → read_file, bash → run_command, websearch → web_search, etc.). Tagged Source=jsonl, Reliability=approximate. |
| Gemini CLI | (no proxy yet) | JSONL or single-object JSON — ~/.gemini/tmp/<hash>/chats/session-*.{json,jsonl}. Dual-format dispatch: legacy single-object JSON (size-based cursor, cline-style) and proposed JSONL event records (byte-offset cursor, issue #15292). Action mapping covers read_file / write_file / edit_file / run_command / search_files / web_fetch and arbitrary MCP tool calls. Project root falls back through tool-call cwd → ~/.gemini/history/<hash>/.git/config worktree pointer → synthetic [gemini-cli:<hash>] key (promoted via ON CONFLICT DO UPDATE on sessions.project_id once a future scan supplies a real cwd). Tagged Source=jsonl, Reliability=approximate. |
JSONL-only clients are captured passively by the watcher whenever
observer start is running. Hooks self-heal on every start, so a
fresh install captures the JSONL side without any init step. You won't see real-time cost numbers
for them on the Compression tab (those need the proxy), but every tool
call shows up on Sessions / Actions / Discovery / Tools / Patterns and
the JSONL-derived token counts feed the Cost tab. Reliability tagging
is per-adapter: Claude Code emits unreliable (the JSONL stream uses
streaming-time placeholder counts per spec §24); Codex / Cline / Pi /
OpenCode / OpenClaw / Antigravity / Gemini CLI / Kilo Code / Kilo Code CLI emit approximate
(provider-reported usage that hasn't been reconciled against an
upstream invoice).
For Codex specifically, Observer currently has two practical support modes:
Proxy + JSONL: Codex is routed throughOPENAI_BASE_URL=http://127.0.0.1:8820/v1and Observer can link proxy turns to the session, so live compression metrics are available.JSONL only: Observer can still recover sessions, actions, and approximate token counts from~/.codex/sessions, but live proxy compression is currently not available when Codex is logged in with a ChatGPT plan on the local machine.
Persistent setups
Claude Code (~/.claude/settings.json):
{
"env": { "ANTHROPIC_BASE_URL": "http://127.0.0.1:8820" },
"hooks": { /* `observer init` writes these */ }
}
Codex (~/.codex/config.toml):
[env]
OPENAI_BASE_URL = "http://127.0.0.1:8820/v1"
Shell rc (~/.bashrc / ~/.zshrc) — affects every program:
export ANTHROPIC_BASE_URL=http://127.0.0.1:8820
export OPENAI_BASE_URL=http://127.0.0.1:8820/v1
Architecture in detail
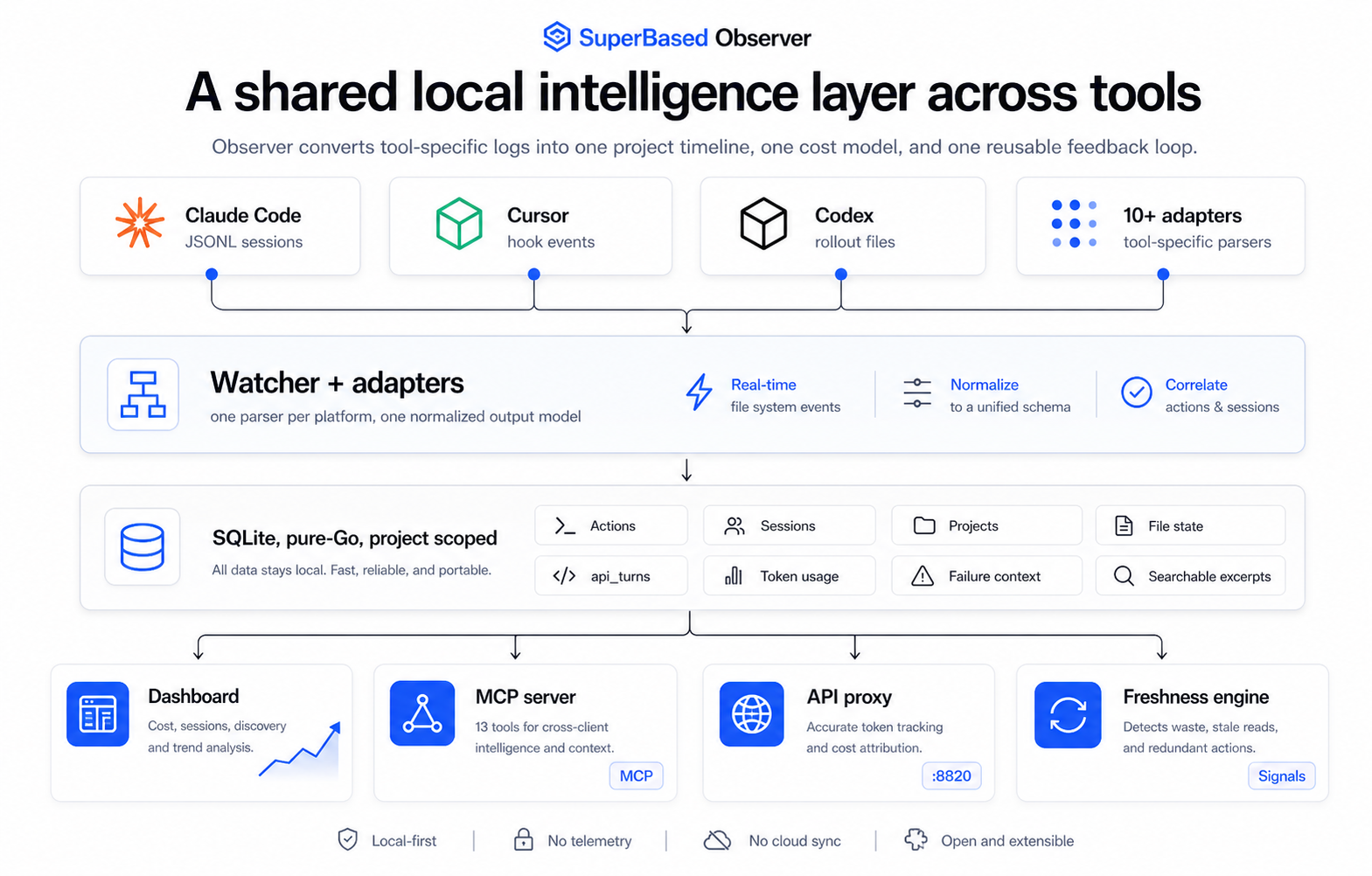
Five components running side by side:
1. JSONL adapters (passive ingest)
Watch ~/.claude/projects/, ~/.codex/sessions/,
~/.gemini/tmp/.../chats/, ~/.gemini/antigravity/conversations/
(and the matching Antigravity index state.vscdb), etc. for new
session log lines. Normalize per-client tool names to a shared
taxonomy (read_file, run_command, spawn_subagent, …) and write
them into the actions table. Active whenever observer start is
running; hooks self-heal on each start so no separate init step is
required for capture.
For Antigravity (which stores conversations as encrypted protobufs),
observer ships a per-OS oscrypt key fetcher (Chromium Safe Storage
pattern: macOS Keychain / Linux libsecret + peanuts fallback / Windows
DPAPI / WSL2-via-PowerShell helper) plus a language_server-aware
gRPC fallback that calls GetCascadeTrajectory through the bundled
antigravity-bridge.exe when local decryption can't validate the
ciphertext. Tier 0–6 ToolEvents (file views, artifact edits/writes,
user prompts, assistant text, run_command terminal snapshots,
structured plan steps, final summaries) are extracted from the
trajectory's wire format without committing to specific .proto field
numbers.
What this gets you: every tool call you've ever run, queryable.
2. API reverse proxy (active capture)
A localhost HTTP server (127.0.0.1:8820) you point your AI client
at via ANTHROPIC_BASE_URL / OPENAI_BASE_URL. Intercepts every
request before it hits Anthropic / OpenAI and:
- Records exact token usage from the upstream
usageenvelope (the most accurate cost source — proxy beats JSONL parsing here). - Runs the conversation compression pipeline to trim large
tool_resultblocks and drop low-importance messages before forwarding upstream. - Captures the
cost_usdthe upstream reports (when present).
What this gets you: ground-truth cost numbers and conversation compression savings you can measure.
3. SQLite store
A single file at ~/.observer/observer.db. Tables include:
projects,sessions,actions— the taxonomyapi_turns— one row per proxy-intercepted upstream requesttoken_usage— JSONL-derived token-row events (deduped via spec §A1)file_state— content hashes for freshness classificationcompression_events— per-event compression detail (post-migration 010)project_patterns— derived patterns fromobserver patternsfailure_context,action_excerpts— diagnostic data
Pure-Go via modernc.org/sqlite, no CGO. WAL mode by default.
4. Local dashboard (:8081)
Eight tabs covering: Overview, Cost, Sessions, Actions, Tools, Compression, Discovery, Patterns. See Dashboard tour.
Static HTML + Chart.js. No analytics, no external requests.
5. MCP server (stdio) — opt-in via observer init
13 read-only tools the AI client itself can call mid-conversation —
check_file_freshness, get_last_test_result, search_past_outputs,
etc. (plus retrieve_stashed when the proxy stash is configured).
Powers cross-client tool sharing: if Claude Code ran go test,
Cursor's MCP query for the latest test result will return Claude
Code's run. See MCP tools reference.
Lifecycle: the MCP server is a stdio subprocess spawned by your
AI tool — not by the observer daemon. It's registered into each AI
client's MCP config only when you run observer init. observer start alone does NOT register the MCP server. Adds roughly 1,800
tokens of tool-schema overhead per AI-client turn; opt out with
observer init --skip-mcp (registers hooks only) or by simply not
running init.
Dashboard tour
Open http://127.0.0.1:8081/ after observer start. Ten tabs.
Overview tab
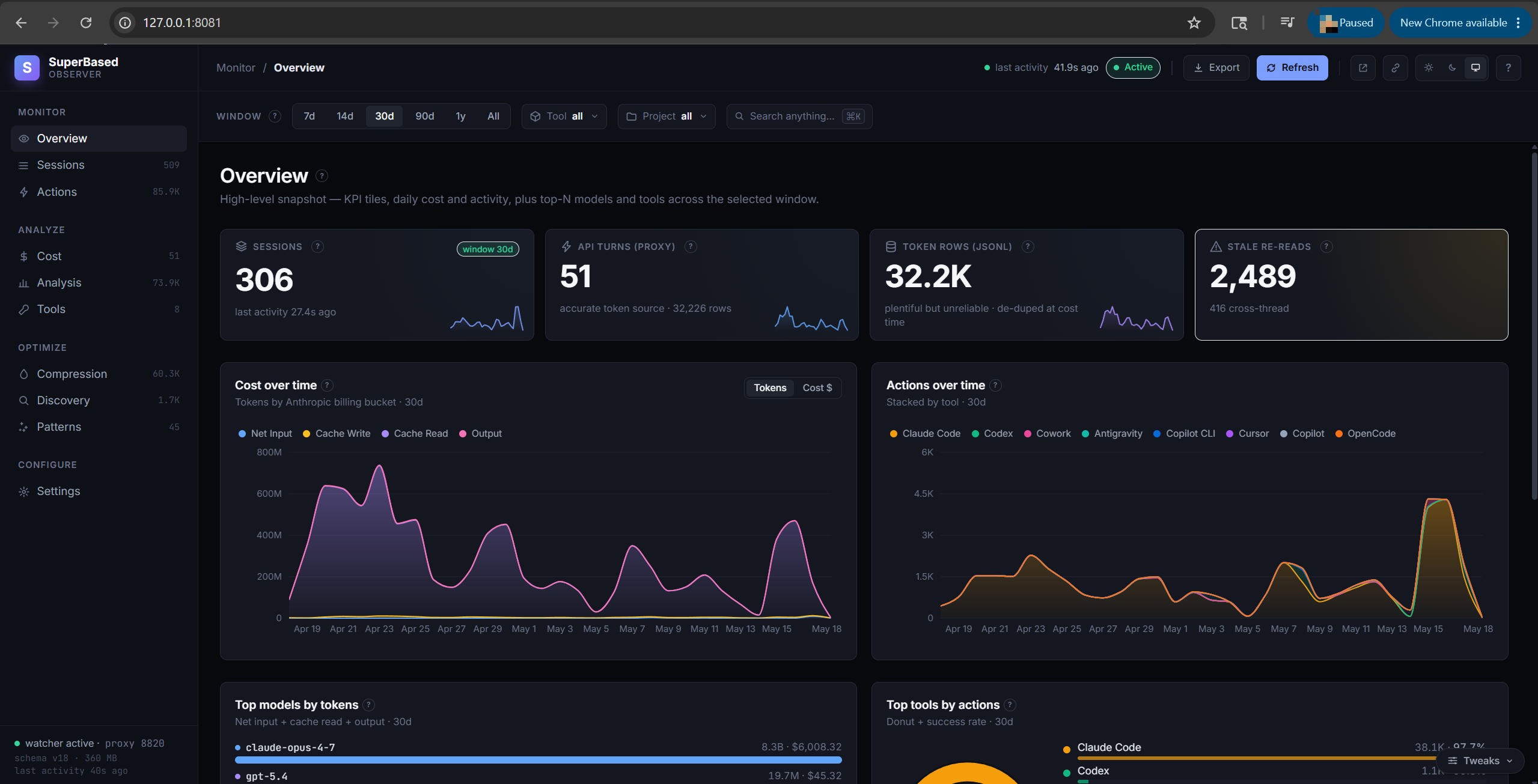
High-level snapshot of the selected window:
- KPI tiles: Sessions count, API turns (proxy-captured), Token rows (JSONL-recovered), Failures (24h)
- Cost over time chart — daily token volume, split into the four billable buckets (net input / cache read / cache write / output)
- Actions over time chart — total actions vs failures
- Top models (by tokens) chart — top-8 models stacked by net input / cache read / output
- Top tools (actions over time) — per-AI-client stacked-area showing when each client is active
Cost tab
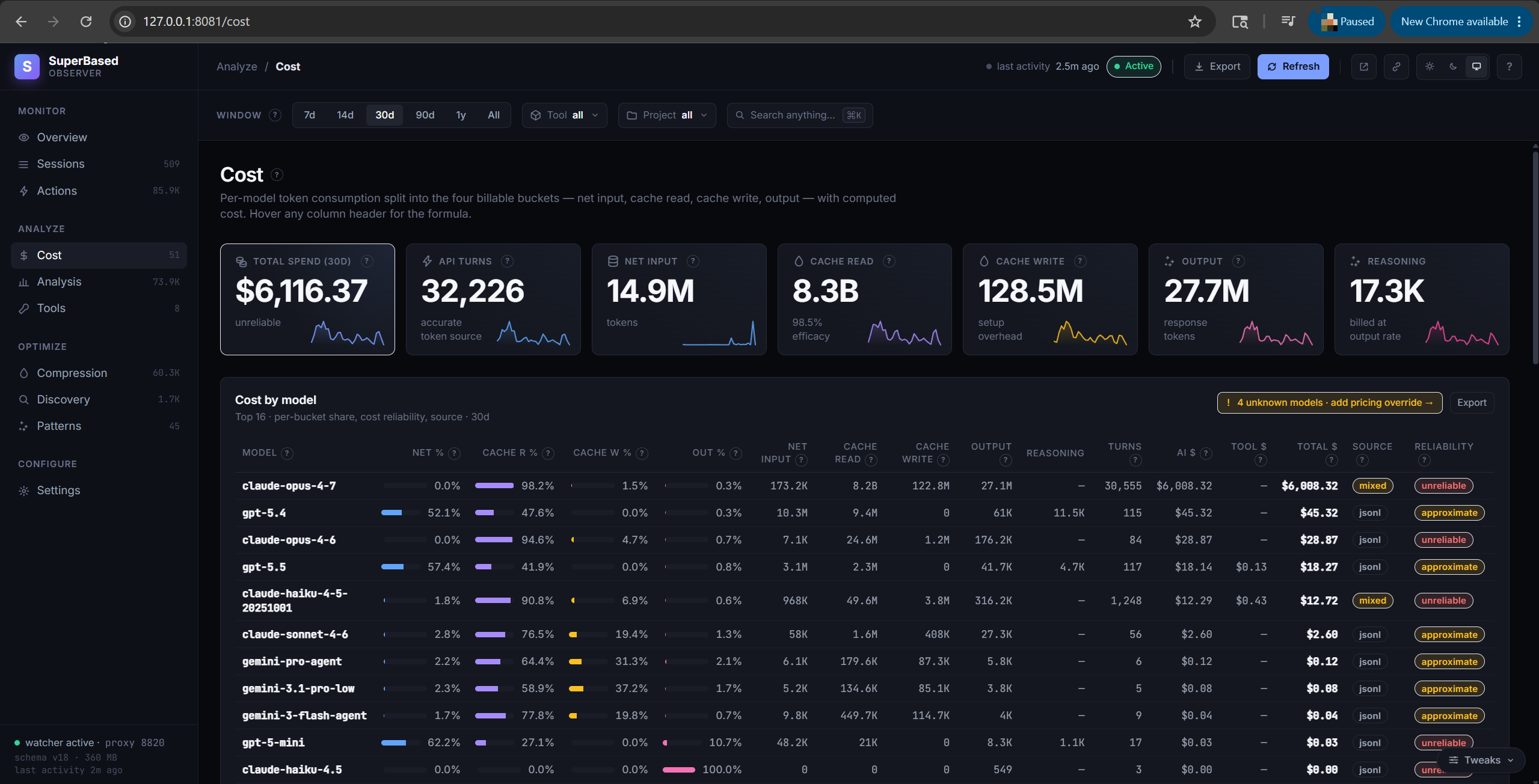
Per-model breakdown over the selected window. Tokens split into the
four billing buckets, with computed dollar cost and a reliability
flag. Cost is always computed locally as tokens × pricing_table[model]
— neither Anthropic nor OpenAI returns cost in their API responses, so
the proxy can't capture upstream-billed cost. Reliability values:
accurate (proxy-captured tokens, exact rate), approximate (JSONL-
sourced tokens, rate may be a family-prefix fallback), unreliable
(Claude Code JSONL streaming placeholders, ~10% off output), unknown
(no pricing entry for the model). Two adapters — OpenCode and Pi —
write their own per-turn cost into estimated_cost_usd; the engine
uses those as-is when present. See
docs/pricing-reference.md for the rate sheet.
Hover any column header for tooltip; click for the full definition in the help drawer.
Analysis tab
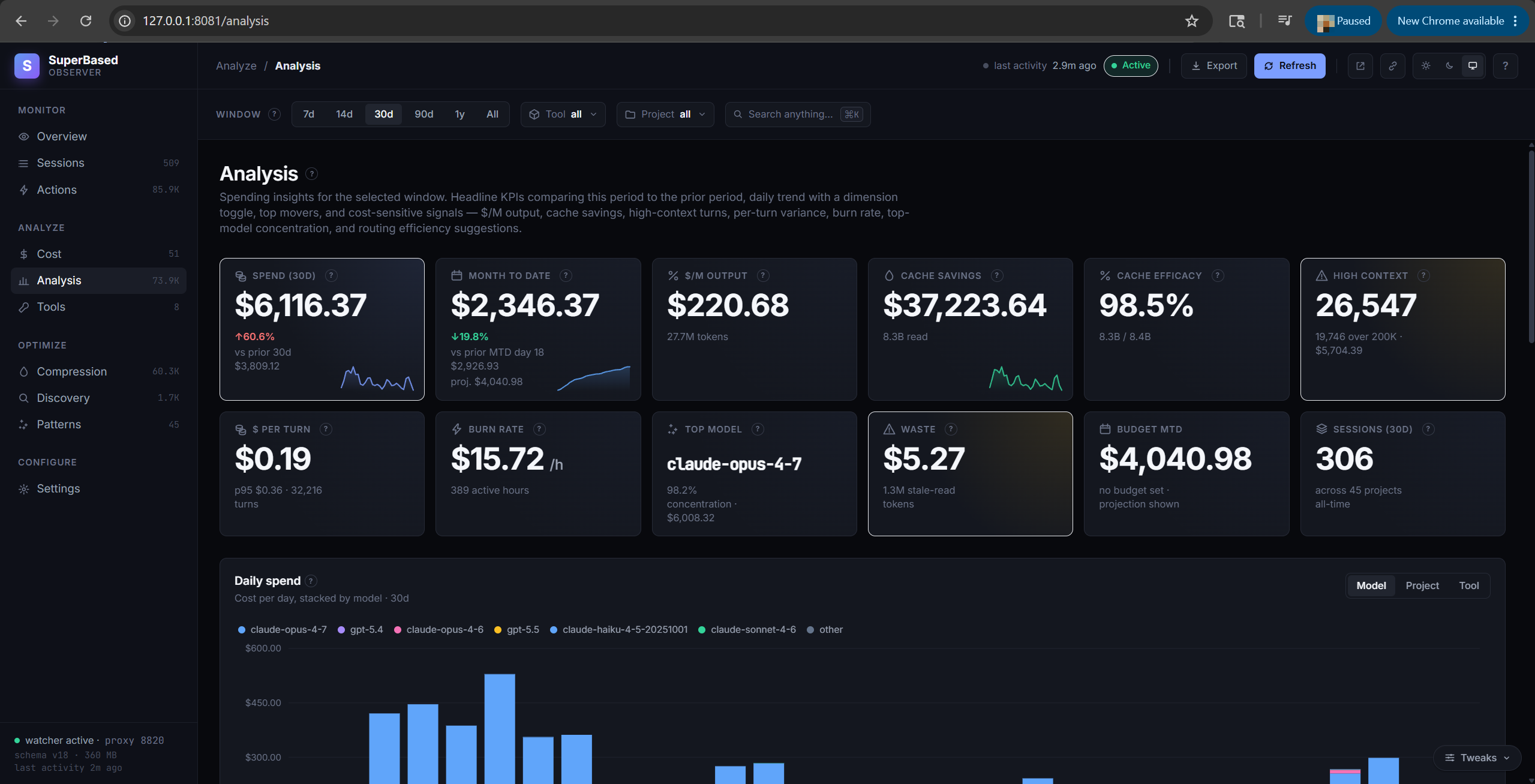
Spending insights for the selected window. Twelve headline KPI
tiles comparing this period to prior: spend Δ%, MTD vs budget with
projection bar, $/M output rate, cache savings + cache efficacy %,
high-context turn count, $/turn, burn rate ($/active hour), top
model concentration %, Discovery waste $, sessions total. Below
the tiles: a daily-spend stacked bar with Model / Project / Tool
dimension toggle, hour-of-day heatmap, top-12 expensive sessions
with explanatory badges (opus, lc_tier, many_turns,
large_prompt), period-over-period movers (top increases / decreases
/ new entrants), and routing-efficiency suggestions (trivial Opus
sessions that could have used Sonnet).
Sessions tab
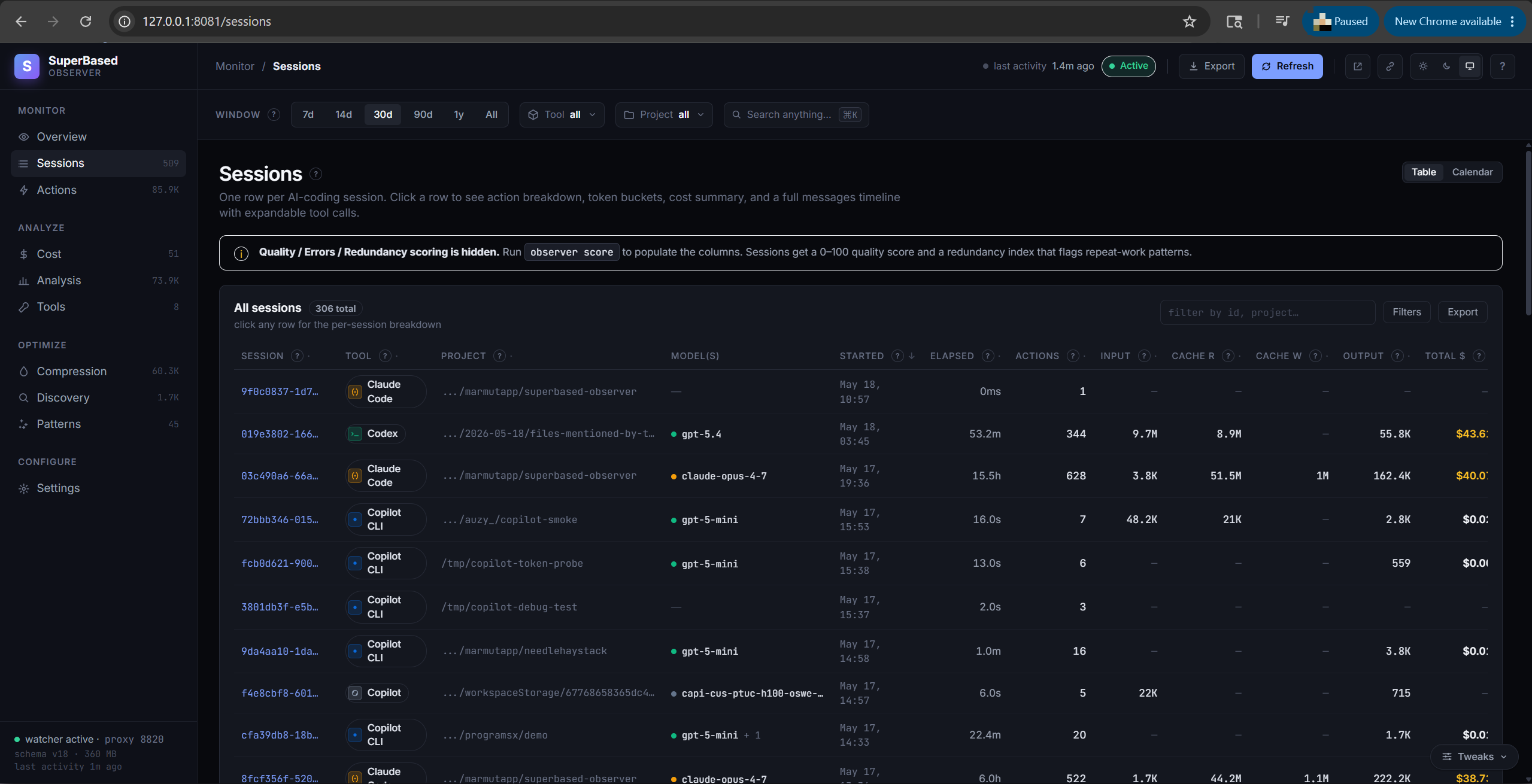
One row per AI-coding session. Each session has a stable ID, a tool
(claude-code / cursor / codex / cline / cline-cli / copilot / copilot-cli /
opencode / openclaw / pi / antigravity / gemini-cli / hermes /
kilo-code / kilo-code-cli), a working-directory project, action
count, sub-agent action count (when the session spawned sub-agents via
the Agent tool), per-session Tokens and Cost columns, and —
if observer score has run — quality / errors / redundancy ratios. The ~ suffix on Cost flags rows whose pricing
was tier-fallback rather than billing-grade ("accurate" reliability).
Click a row to open the session-detail panel:
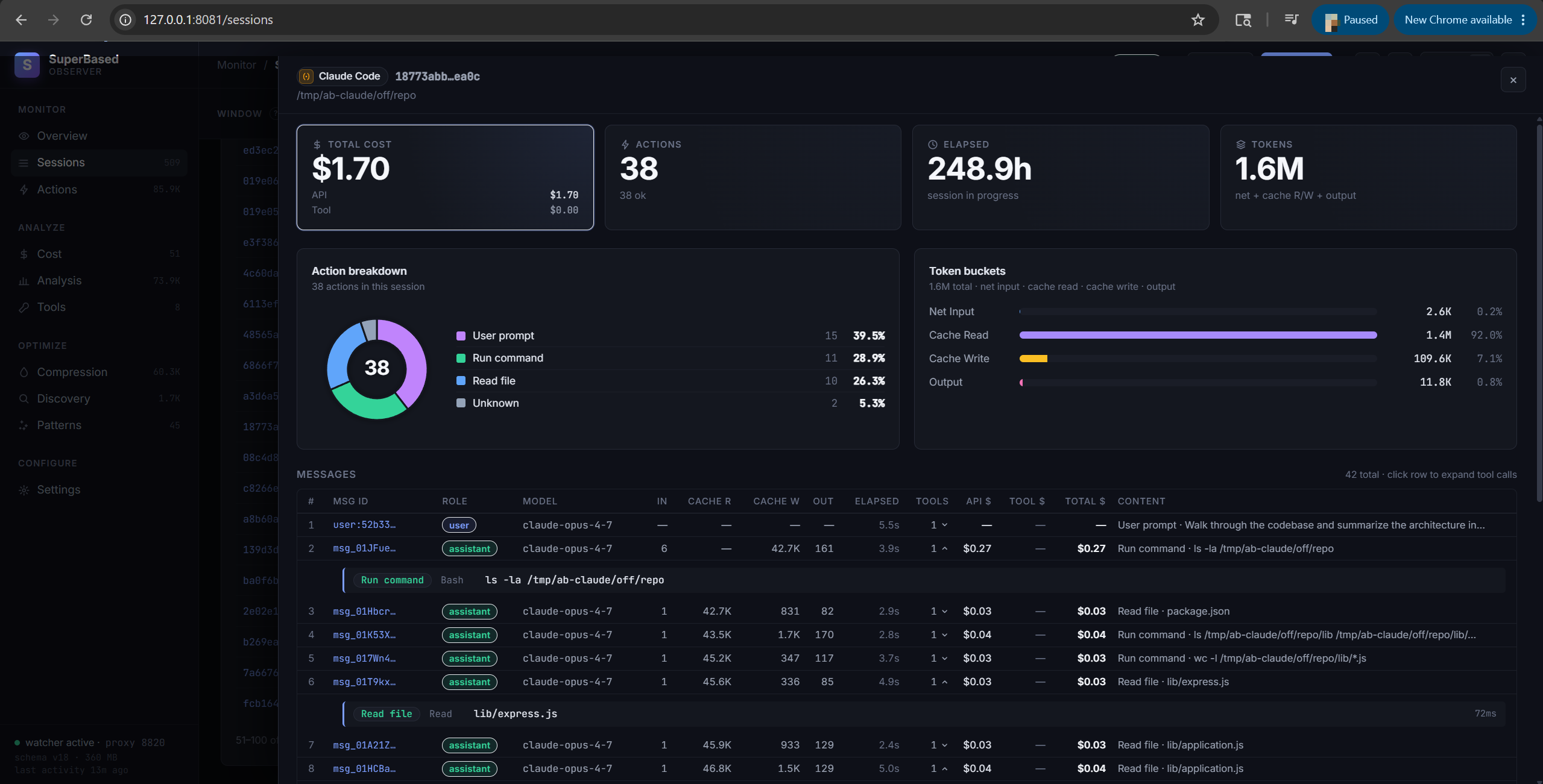
- Top tiles — Tool, Started, Actions count (ok/fail), Cost.
- Action breakdown — chart of action_type counts.
- Tokens — the four billing buckets (Net Input / Cache Read / Cache Write / Output) for the whole session, per-turn-deduped (proxy preferred, JSONL fills gaps).
- Per-model breakdown — when a session uses multiple models (Claude Code's main + sub-agent dispatches always do), a row per model with its tokens and cost.
- Messages — per-message timeline keyed on the upstream
Anthropic
msg_xxx. Each row shows the message id, role, model, the message's own token bucket, cost, and aN ▾pill that expands inline to show the contained tool calls. Toggle radio at the top: Tool messages only (default — assistant turns with ≥1 tool call + user prompts) vs All messages (also pure-text assistant replies). Truncated IDs (session_id, message_id) show a dotted underline on hover and copy the full value to clipboard on click; truncated text fields (target, error message) click to expand in-place. Server-side paginated at 50/100/200 messages per page (selectable in the panel footer) — keeps the browser responsive on multi-thousand-message sessions. Requiresobserver backfill --message-idon first upgrade for historical sessions to surface their parent message ids.
Actions tab
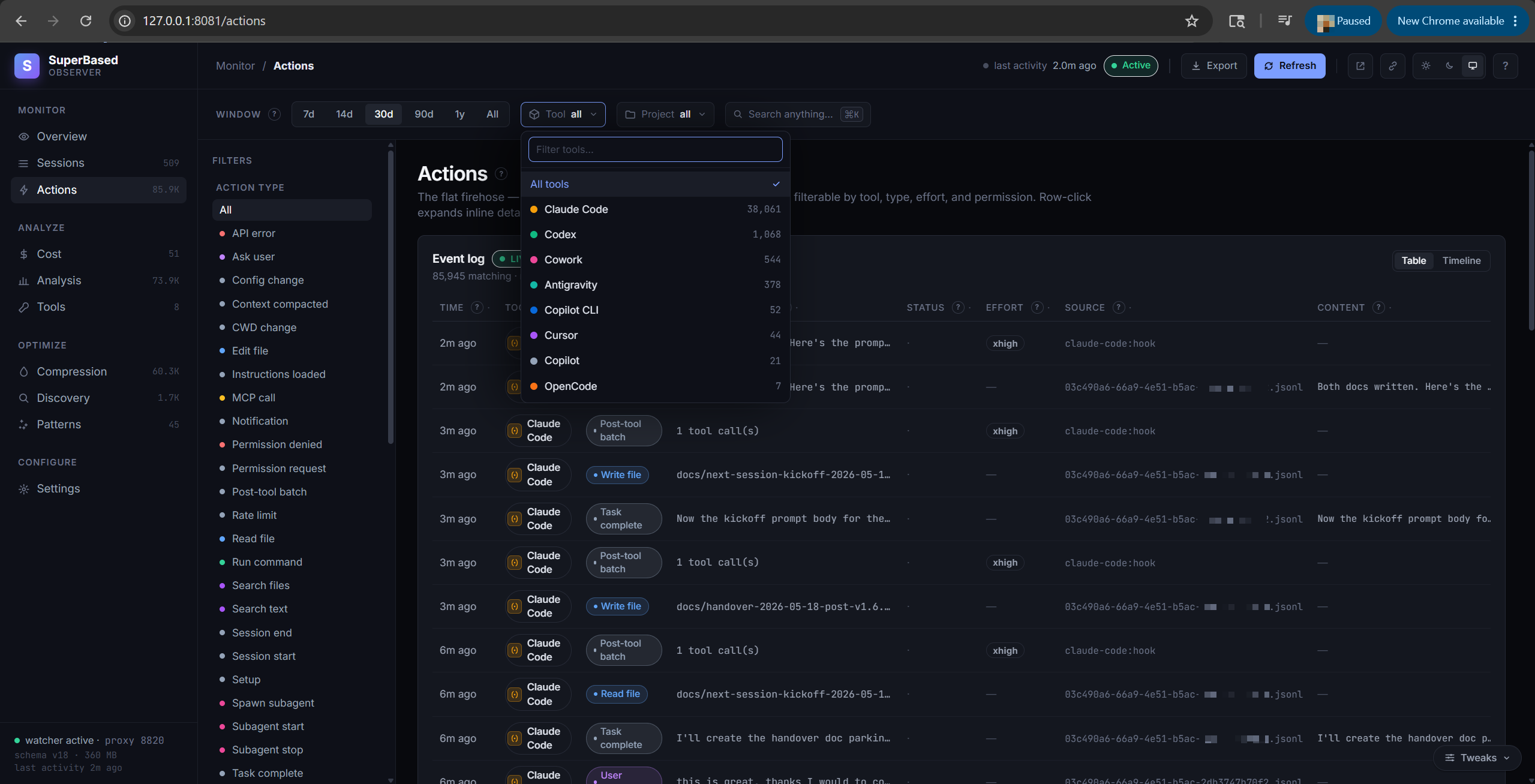
The flat firehose: every recorded tool call, normalized across
adapters. Filter by action type (read_file, write_file,
run_command, spawn_subagent, todo_update, mcp_call, …).
Pagination caps at 50 rows per page; total count is shown next to
the heading.
Tools tab
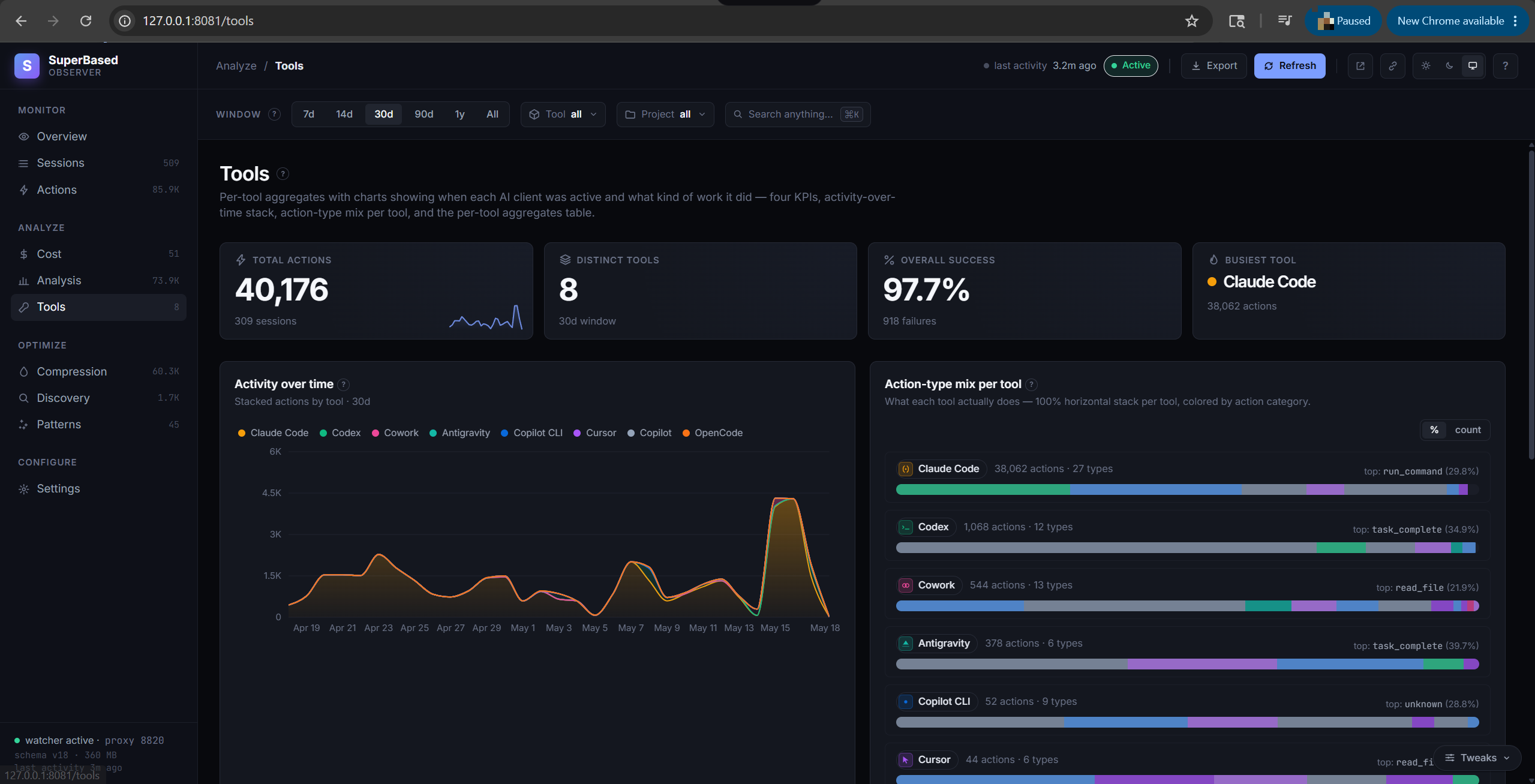
Per-AI-client (the client — claude-code / cursor / codex / etc., not the per-tool name) aggregates plus three views:
- KPI tiles: Total actions, Distinct tools, Overall success rate, Busiest tool
- Activity over time stacked-area showing per-tool action volume per day
- Action-type mix per tool horizontal stacked bar — what each tool actually does (read_file vs edit_file vs run_command vs search_text vs spawn_subagent)
- The full per-tool aggregate table with first/last seen
Compression tab
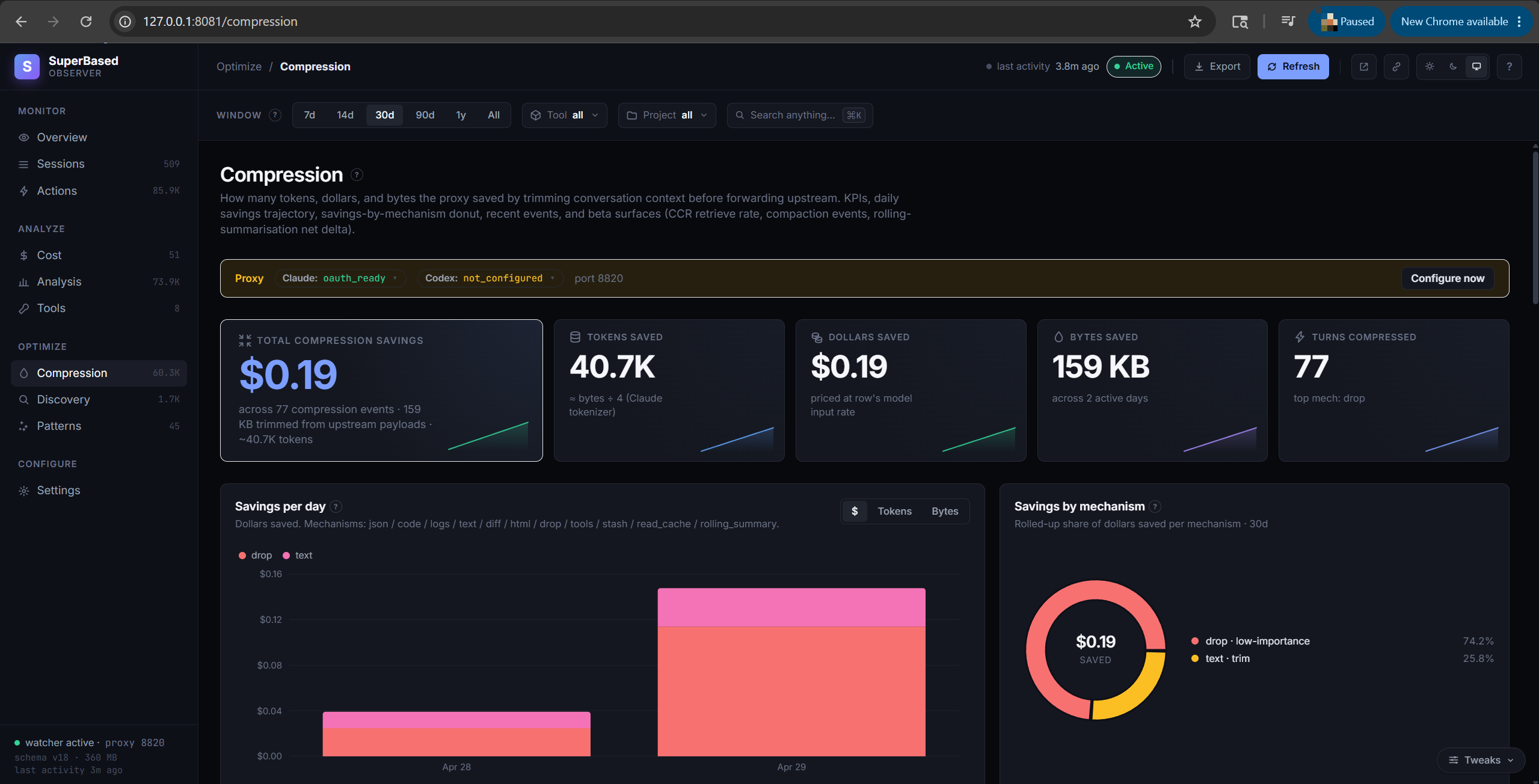
How many tokens and dollars the conversation-compression pipeline saved by trimming requests before forwarding upstream:
- KPI tiles: Tokens saved (est.), Dollars saved (est.), Bytes saved, Turns compressed
- Savings per day chart — daily tokens-saved (left axis) and bytes-saved (right axis)
- Savings by mechanism stacked bar — segments per mechanism (json / code / logs / text / diff / html / drop). Toggle the y-axis between tokens and bytes with the chart-header switch.
- Per-model breakdown table — tokens saved ~, $ saved ~, bytes saved, saved %, turns, tool-results compressed, dropped, markers
- Recent compression events — paginated per-event detail with mechanism, original / compressed / saved bytes, message slot, importance score (for drops), and a Source column showing whether the event came from a main-thread or sub-agent runtime call
Discovery tab
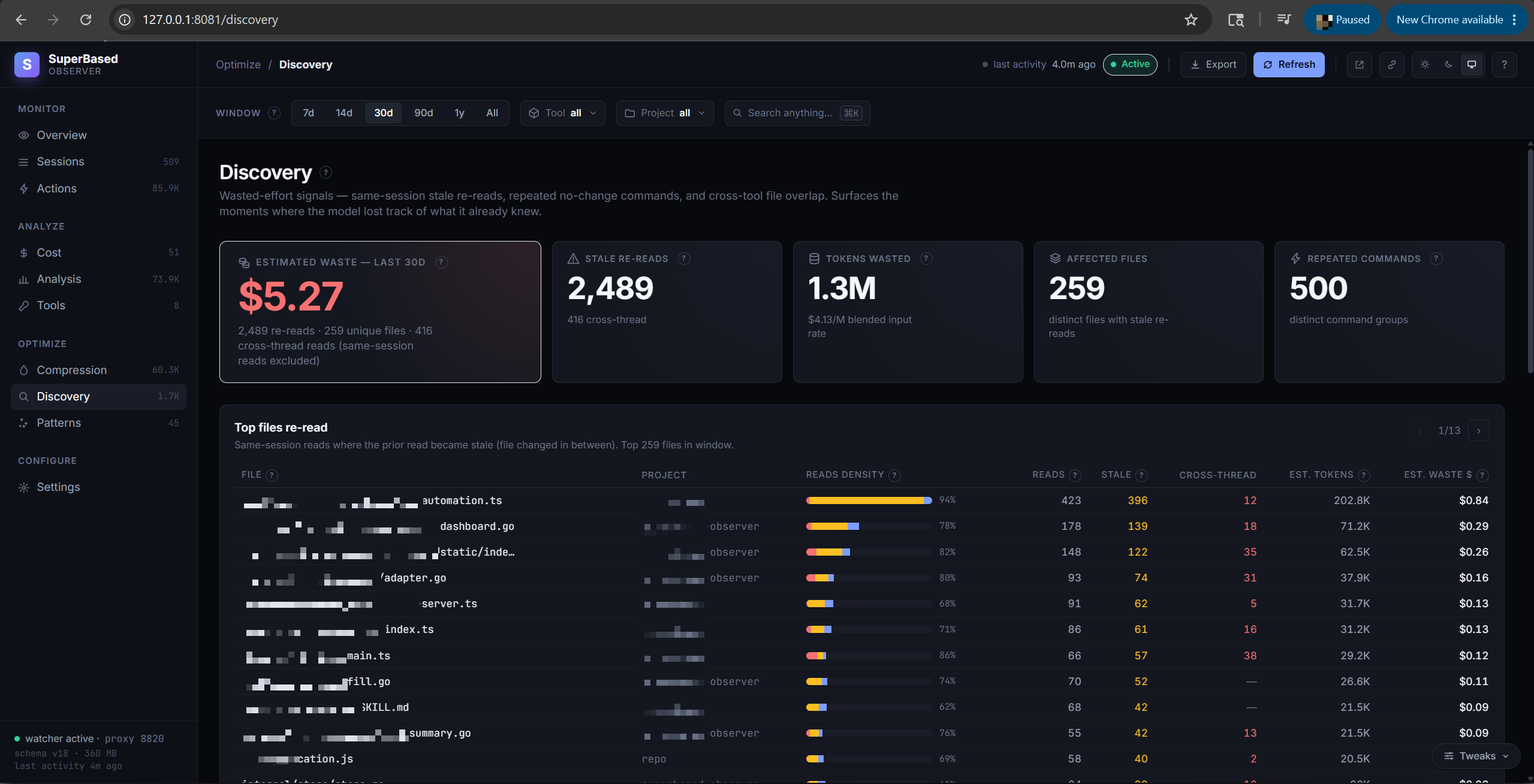
Wasted-effort signals:
- Stale rereads — files re-read after they changed inside the same session. KPI tiles show count, ~Tokens wasted, ~$ wasted (at your blended input rate), affected files. The CROSS-THREAD column flags re-reads that crossed the parent ↔ sub-agent boundary — these are the "pass content via Agent's prompt parameter" candidates.
- Repeated commands — commands run multiple times with no
relevant inputs changed in between (e.g. you ran
go testthree times without editing anything between runs). - Cross-tool overlap — files touched by ≥2 AI clients in the
window (e.g. claude-code AND cursor both edited
auth.ts). This is the visible side of cross-platform tool-call sharing via the MCP server.
Patterns tab
Repeatable behaviours the observer noticed across your sessions —
"after running go test, you almost always run go vet", "when
working on auth.ts, you also touch login.tsx", etc. Each pattern
has a confidence score (decay-weighted: more observations + recent
observations push it higher) and an observation count.
observer patterns derives them; observer suggest writes the
high-confidence ones into CLAUDE.md / AGENTS.md / .cursorrules
so new sessions inherit your habits.
Settings tab
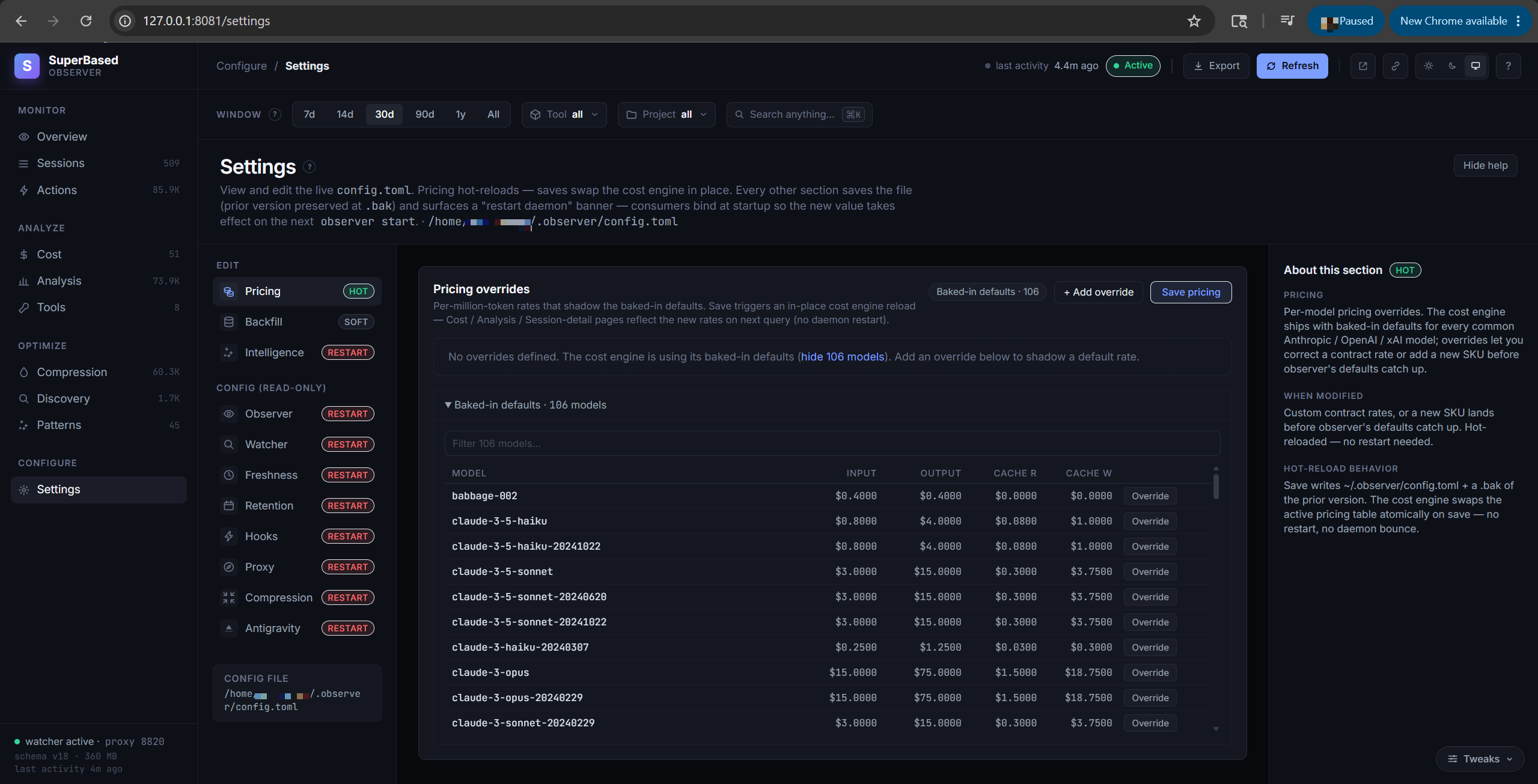
Fully editable visual editor for everything in config.toml.
Pricing overrides hot-reload (no daemon restart — cost.Engine
swaps the pricing table atomically via atomic.Pointer.Store).
The Backfill panel surfaces every observer backfill mode as
click-to-run buttons that spawn the CLI as a child process and
stream output back live. Watcher / Freshness / Retention / Hooks /
Proxy / Compression / Intelligence sections are schema-driven forms
with inline help; a "Restart daemon" banner appears whenever a
section is saved that consumers bind at startup.
Help drawer
Press ? anywhere on the dashboard or click the ? Help button in
the topbar. Every column header, KPI tile, chart label, and filter
control on every tab is annotated — hover any element to see a
one-liner tooltip; click to open the drawer at the matching glossary
entry.
The drawer has full descriptions, formulas, data sources, examples,
"why it matters", "what to do", and cross-links. Search at the top.
Deep-linkable via URL fragment — #help/metric.stale_count opens
the drawer at that entry.
Each compression mechanism (json / code / logs / text / diff / html / drop) has a "Full methodology · see more" expandable section explaining the actual algorithm.
MCP tools reference
Once you've run observer init (it's opt-in — observer start
alone does NOT register the MCP server), every connected AI client
gets these 13 tools registered as an MCP server — plus
retrieve_stashed when the proxy stash is configured. They're
read-only queries against the unified database, so any agent
can read any other agent's recorded work — true cross-platform
tool-call sharing.
| Tool | Purpose |
|---|---|
check_file_freshness |
Has this file been read in the current session? Has it changed since? |
get_file_history |
Full read/edit history of a file across all sessions and clients |
get_session_summary |
Roll-up stats for a session: action count, success rate, cost, token buckets |
search_past_outputs |
Full-text search across recorded tool outputs (FTS5-indexed) |
get_last_test_result |
Most recent go test / npm test / pytest etc. output |
get_failure_context |
Recent failures: which command, which file, which session |
get_action_details |
One specific action's full record (target, args, output excerpt) |
check_command_freshness |
Has this command been run in the current session? With what result? |
get_session_recovery_context |
Recent activity for resuming a paused session |
get_project_patterns |
High-confidence patterns derived from this project's history |
get_cost_summary |
Daily / per-model / per-session cost rollups |
get_redundancy_report |
Stale rereads, repeated commands, cross-tool overlap for the project |
list_actions_around |
±N actions adjacent to a pivot action_id — browse a session's local timeline cheaply |
retrieve_stashed (conditional) |
Pulls original bytes of a tool_result the proxy compressed away. Only registered when [compression.conversation].stash is configured. |
Cost trade-off: with the MCP registered, the AI client sends the
full tool-schema payload (~7.2 KB / ~1,800 tokens) in its system
context on every turn — whether or not the model actually invokes
any tool. To eliminate this overhead, run observer init --skip-mcp
(registers hooks only) or skip init entirely.
Cross-tool sharing: when observer init registers the MCP server
with Claude Code AND Cursor (and Codex…), all of them call the same
tools against the same database. Cursor's get_last_test_result
returns Claude Code's last test run; Codex's check_file_freshness
reflects edits made by Cursor.
Compression mechanisms
The conversation-compression pipeline runs inside the proxy on every
upstream request. It tries to fit the request body within
target_ratio × original_bytes (default 0.85) without breaking the
conversation's referential integrity.
Two passes, in order:
Pass 1 — per-content-type compression
Each tool_result block is sniffed for content type, then routed to
a content-aware compressor. Six compressors:
| Mechanism | What it does | When it fires |
|---|---|---|
| json | Replaces every scalar value with a type sentinel ("<string>", "<number>", …) preserving structure (keys, arrays, nesting). Arrays of length > 1 collapse to one element with _len: N. |
API responses, structured logs, telemetry exports. JSON tool_results are usually the biggest savings target. |
| code | Heuristic skeleton: keeps top-of-file imports + signature lines (function / method / class / struct / interface / type), drops bodies. | Source code files. On by default as of v1.7.23 for the claude-code recipe (V7-24 empirical winner). |
| logs | Two-pass: collapses adjacent identical lines to <line> [×N], then head+tail-truncates to 200 lines if still long. |
Log-shaped output — go test ./..., npm run build, polling/retry loops. Lossless on distinct lines; only the truncate pass is lossy. |
| text | Catch-all for content not classified as code/json/logs/diff/html. Head+tail truncation: keeps 40 + 40 lines on inputs over 80 lines. | Markdown bodies, README excerpts, narrative descriptions. |
| diff | Strips unified-diff context beyond ±1 line of each change. Keeps every header, every +/- line, drops the rest with elision markers. |
git diff, patch tool outputs. Lossless on changes; lossy only on the cheap-to-rebuild context. |
| html | Three regex passes: strips <script>, <style>, and HTML comments. Tag attributes + visible text + structural elements survive. |
web_fetch results pulling whole HTML pages — usually 80%+ scripts/styles. |
Pass 2 — drop with marker
If Pass 1's compressed body is still over budget, the budget enforcer ranks remaining messages by importance score (a deterministic weighted sum) and drops the lowest-scored non-preserved ones until the budget is met. Each dropped message is replaced by a single marker block (a placeholder text) so the conversation flow stays intact for the model.
Importance score = 0.4 × recency + 0.3 × reference + 0.15 × density + 0.15 × role
- Recency =
(i+1) / n— newest message scores 1.0, oldest scores 1/n - Reference =
1.0if any of the message'stool_use_idsis cited by a latertool_result, OR any of itsreferenced_idspoints to a live tool_use;0.0otherwise. Tool-pair-live messages always get full weight regardless of position. - Density = fraction of non-whitespace runes (whitespace-padded outputs get dropped first)
- Role =
system 1.0,user 0.9,assistant 0.7,tool 0.5(tool outputs are the most-compressible by policy)
Preserved messages (never droppable):
- The last
PreserveLastNmessages (default 4) - Any
systemrole message - Tool-pair-live messages: any message whose
tool_use_idis referenced by a later tool_result (parent side), AND anytool_resultmessage whosereferenced_idpoints to a live tool_use (consumer side)
Tool-pair preservation is symmetric — dropping either side leaves an orphan that Anthropic rejects with 400.
Per-event detail
Every drop and every per-type compression is recorded as a row in
the compression_events table (post migration 010). The Compression
tab's "Recent compression events" view surfaces these with
mechanism, original / compressed / saved bytes, message slot, and
importance score (for drops).
Tuning
observer config settings (in ~/.observer/config.toml). These are the only
keys the conversation compressor reads:
[compression.conversation]
enabled = true
mode = "cache_aware" # "token" | "cache" | "cache_aware" — default cache_aware; see matrix below
target_ratio = 0.85
preserve_last_n = 5 # never drop the most recent N messages
compress_types = ["json", "logs", "code"] # default; add "text", "diff", "html" to opt in
High importance scores on dropped events (≥0.5) suggest the threshold
is too aggressive — raise target_ratio (e.g. 0.9 or 0.95).
Choosing a mode: Anthropic vs Codex
Per-type tool_result compression runs in every mode; mode only changes how
messages are dropped and whether an Anthropic cache_control marker is injected.
mode |
What it does | Claude Code (Anthropic) | Codex / OpenAI |
|---|---|---|---|
token |
Per-type compress, then drop lowest-scored messages to hit target_ratio. |
✅ Works. | ✅ Clearest choice for Codex/OpenAI. |
cache |
Restrict drops to the tail half + inject a cache_control marker at the prefix boundary. |
✅ Anthropic-specific. | ⚠️ No effect beyond token. |
cache_aware (default) |
Skip drops, narrow compression to tool_result blocks, no marker; keep history byte-stable across turns so Anthropic's prefix cache keeps hitting. |
✅ Recommended for Anthropic Pro/Max — and the shipped default. | ⚠️ No effect beyond token. |
The shipped default is cache_aware (token is just the internal fallback when
mode is empty). The cache modes exist for Anthropic's content-hash prefix
cache (cache_control is an Anthropic Messages API concept). OpenAI/Codex
prompt caching is automatic and server-side — nothing to mark or tune, so
the proxy's OpenAI path is mode-agnostic (the default cache_aware behaves like
token there). So: keep cache_aware for Claude Code; mode = "token" reads
honestly for a Codex/OpenAI-only setup.
Beyond the keys above, three opt-in sub-features have their own tables —
[compression.conversation.stash] (Compressed-Content Retrieval),
[compression.conversation.rolling] (rolling summarisation, with a per-provider
summary model: summary_model for Anthropic, openai_summary_model for
OpenAI/Codex), and [compression.conversation.compaction]. The full knob
reference lives in docs/compression-modes.md.
Measured savings (v1.7.23)
We A/B every shipped recipe against an OFF baseline on a real refactor
workload (lumen TypeScript codebase, 408-line Zustand store →
4 domain sub-stores) on the v1.7.22 binary tip. The numbers below are
the most recent statistically-meaningful measurements.
Pick a recipe based on which model you're running:
| Recipe | Use when your model is… | Workload | n | Δ vs OFF (mean cost) | What's compressed |
|---|---|---|---|---|---|
claude-code (default) |
Any Anthropic Claude model — claude-sonnet-4-6, claude-opus-4-7, claude-haiku-4-5, … |
Refactor, Claude Sonnet 4.6 via Claude Code 2.1.158 | n=8 B vs n=4 OFF | −6.9% (CV 7.6%; tighter than OFF's 7.5%) | json + logs + code bodies; cache-aware; stash disabled |
codex-variant |
OpenAI's -codex reasoning fork — gpt-5.3-codex, gpt-5.4-codex, gpt-5-codex-agent, anything matching *-codex* |
Refactor, gpt-5.3-codex | n=10 B vs n=10 OFF | −10% ($0.270 vs $0.300) | Tools-defs trim; cache-aware; no per-type compression |
codex-safe |
Plain OpenAI GPT under the codex CLI — gpt-5.4, gpt-5.4-mini, gpt-5.5, gpt-4o, any non--codex |
Refactor, gpt-5.4 + apply_patch |
n=3 B vs n=4 OFF | not statistically distinguishable on this workload | logs only; cache-aware |
The word "variant" in codex-variant refers to the model variant (the -codex reasoning fork of GPT), NOT a variant of the codex CLI. Both codex recipes are for the codex CLI; they differ only in which model family they assume. codex-safe is so named because plain GPT models tolerate logs trimming safely — it's not "safer than codex-variant."
Honest caveats:
- Workload-dependent. The
codex-saferow on gpt-5.4 was inconclusive because the test workload usedapply_patch(classified ascode, notlogs) socompress_types=["logs"]never fired — the proxy was a functional no-op and the cost variance was session noise. A Bash-heavy workload would tell a different story. claude-coderequiresENABLE_TOOL_SEARCH=truein your shell. Without it, Claude Code's SDK disables ToolSearch underANTHROPIC_BASE_URLand eager-inlines all MCP schemas (~+21K tokens per turn). The proxy then becomes a net loss instead of the −6.9% above. Setup steps cover this; verify withprintenv ENABLE_TOOL_SEARCH.stashstays disabled by default for Anthropic (V7-25 finding: +25% cost on n=1 due to prefix-cache miss; stash markers break Anthropic's content-hash cache). Operators can opt in for a measured workload but should A/B their own.- Historic claims of higher savings are retracted. The v1.4.38 release notes cited −14.8%; the project itself walked that back after a deeper repro showed it was within noise. The numbers above are the post-retraction floor.
Reproduce it yourself:
# Full methodology, raw arm data, per-arm cost rows, and a reproducer
# script live in this repo:
docs/v1.7.23-compression-savings-empirical-2026-06-01.md
Cost and token math
Anthropic's usage envelope reports four token buckets per request, each at a different rate:
| Bucket | What it is | Bills at |
|---|---|---|
net_input |
Fresh prompt tokens not served from cache | model's standard input rate |
cache_read |
Prompt tokens served from Anthropic's ephemeral cache | ~10% of input rate |
cache_creation |
Tokens written to ephemeral cache | 1.25× input (5m tier) or 2× input (1h tier) |
output |
What the model generated | typically 5× input rate |
prompt_context = net_input + cache_read + cache_creation
total_tokens = prompt_context + output
The cost engine (internal/intelligence/cost) computes USD via:
cost_usd = (net_input × p.input + cache_read × p.cache_read +
cache_creation_5m × p.cache_creation +
cache_creation_1h × p.cache_creation_1h +
output × p.output) ÷ 1,000,000
When the upstream API returns cost_usd in the response envelope
(proxy-sourced rows), that value is preferred over the computed one —
ground truth, reliability=high.
Blended input rate
The Discovery tab's "~$ wasted" tile uses a blended input rate
computed from your last-30d api_turns mix: each model's input rate
weighted by the prompt-token volume it consumed. Example: if you
spent 70% of prompt tokens on opus-4-7 ($15/1M) and 30% on
haiku-4-5 ($1/1M), the blended rate is 0.7 × 15 + 0.3 × 1 = $10.80/1M.
Falls back to $3/1M (claude-sonnet-4 input) on fresh installs with no proxy data.
JSONL dedup
When the proxy isn't engaged, observer falls back to parsing the AI client's on-disk session log. Clients echo the same cumulative usage on every content block of a multi-block response, so naive parsing counts one API call 2-4×. Two layers of dedup catch this:
- Adapter-level: dedupes on Anthropic
message.idat write time - Cost-engine-level: dedupes on
(source_file, model, timestamp-bucketed-to-minute, tokens)at read time
Migration 007 ran a one-time pass collapsing pre-fix duplicates.
Terminology and glossary
Quick reference; the in-platform help drawer (press ? on the
dashboard) has the full versions with cross-links.
- Action — one normalized tool call recorded by an adapter. Action
types are taxonomic and cross-client:
read_file,write_file,edit_file,run_command,search_text,search_files,web_search,web_fetch,mcp_call,spawn_subagent,todo_update,ask_user,task_complete,user_prompt,api_error,turn_aborted(interrupted before completion — distinct from task_complete/success=false; v1.4.22+),context_compacted(upstream-emitted compaction marker, not searchable like file edits; v1.4.22+),system_prompt(system/developer/user-envelope content; v1.4.23+),unknown. - API turn — one HTTP request captured by the local proxy. Records
one row in
api_turnsper request, with the upstream usage envelope intact. - Cache 5m vs 1h tier — Anthropic's prompt cache has two TTLs.
Default is 5 minutes;
cache_control: {type: ephemeral, ttl: 3600}extends to 1 hour at 2× the write cost. Reads bill the same rate regardless of tier. - Compression event — one individual compression decision (one per-type compress, or one drop) recorded post migration 010.
- Conversation compression — pre-forward trimming of API request bodies. Pass 1 = per-content-type compression, Pass 2 = drop with marker. See Compression mechanisms.
- Cross-platform tool calling — every AI client connected via
observer initcan call the 12 MCP tools against the unified database. So Cursor'sget_last_test_resultcan return ago testClaude Code ran an hour earlier. - Cross-thread reread — the parent thread re-reads a file the
sub-agent already saw (or vice versa) within the same session. Fix:
pass content via the Agent tool's
promptparameter rather than letting the child re-read. - Freshness state — per-read tag from the freshness engine:
fresh(first read in this session, OR re-read with same content),stale(re-read after change in same session),missing(file no longer exists),modified-elsewhere(file changed by something other than an observable AI action). - Mechanism — one of
json,code,logs,text,diff,html(per-content-type compressor) ordrop(low-importance message replaced by a marker). - Pattern — a derived behaviour:
command_pair(X often followed by Y),cross_tool_file(file touched by multiple clients),knowledge_snippet(consistent topic-specific habit),failure_correlation(X often precedes a failure of Y),session_summary. Each has a decay-weighted confidence score 0-1. - Project — working-directory root that owns sessions and
actions. Derived from cwd at session start;
/.git/worktrees/...paths fold back to the working-tree root. - Proxy vs JSONL — proxy intercepts upstream HTTP calls (ground truth, reliability=high). JSONL parses the AI client's on-disk session log (works without configuring a base URL, but client echoes cumulative usage on every block, requiring dedup — reliability=unreliable for token counts on Claude Code).
- Reliability — cost-engine confidence:
high(upstream- reported),medium(computed from known pricing),low(some buckets estimated),unreliable(no pricing entry). - Session — one continuous AI-coding conversation in a single tool, scoped to one working directory. Has a stable ID (Claude Code's UUID, Codex's rollout ID, …).
- Sidechain — actions emitted inside a sub-agent runtime spawned
via the parent's
Agenttool. Sub-agents share the parent's session_id; theis_sidechaincolumn distinguishes them. The Discovery tab's CROSS-THREAD column counts stale rereads that crossed this boundary. - Stale reread — same-session re-read of a file whose content changed between reads. Cross-session reads are excluded (a fresh session has no memory of a prior session's read).
- Tool — in this dashboard, "tool" means the AI client
(claude-code, cursor, codex, cline, cline-cli, copilot, copilot-cli,
opencode, openclaw, pi, antigravity, gemini-cli, hermes, kilo-code,
kilo-code-cli), not the per-tool name (
read_file,run_command). The latter is "Tool name" on the Actions tab. - Tool-pair integrity — Anthropic requires every
tool_resultblock to have a correspondingtool_useblock in a preceding message. The compression pipeline preserves both sides of every live pair to satisfy this constraint.
CLI reference
Every command supports --help for the full surface.
| Subcommand | Purpose |
|---|---|
observer init |
Register hooks + MCP server with installed AI clients |
observer uninstall |
Reverse observer init |
observer start |
Run watcher + dashboard + proxy in one process (recommended). Flags: --dashboard-addr ADDR (default 127.0.0.1:8081), --no-dashboard to skip the HTTP UI. |
observer watch |
Long-running JSONL watcher only |
observer dashboard --addr ADDR |
HTTP dashboard only |
observer proxy start |
Reverse proxy only |
observer scan |
One-shot ingest of existing JSONL files (catch-up after install) |
observer status |
DB stats + recent activity |
observer doctor |
Diagnostic — checks paths, schemas, hook registration |
observer tail |
Live tail of incoming events |
observer cost |
Per-model cost summary CLI |
observer score |
Compute quality_score / error_rate / redundancy_ratio for sessions |
observer discover |
Stale rereads + repeated commands report (CLI version of the Discovery tab) |
observer patterns |
Derive patterns from session history |
observer learn |
Adapter for ingesting external JSONL exports |
observer suggest |
Write high-confidence patterns into CLAUDE.md / AGENTS.md / .cursorrules |
observer summarize |
Roll-up summary across sessions |
observer export |
Export DB to xlsx / json |
observer prune |
Manual retention pass (delete old data) |
observer backfill --is-sidechain |
Re-walk JSONL to populate actions.is_sidechain (added by migration 010) on pre-migration rows. |
observer backfill --cache-tier |
Re-walk JSONL to populate cache_creation_1h_tokens (added by migration 008) on pre-migration rows. Run once after upgrading to v1.4.16+ to correct historical 1h-tier cache writes that were silently billed at the cheaper 5m rate. |
observer backfill --message-id |
Re-walk JSONL to populate message_id on actions and token_usage (added by migration 012). Required by the per-message timeline view in the Sessions modal. |
observer backfill --all |
Run every supported backfill in one invocation. Idempotent — safe to re-run. |
observer metrics |
Prometheus-format metrics endpoint |
observer serve |
MCP server (stdio JSON-RPC) — usually invoked by observer init registration |
observer tail |
Live event stream |
Configuration
~/.observer/config.toml — created with defaults on first run.
[paths]
db_path = "~/.observer/observer.db"
log_dir = "~/.observer/logs"
[proxy]
listen_addr = "127.0.0.1"
port = 8820
anthropic_upstream = "https://api.anthropic.com"
openai_upstream = "https://api.openai.com"
[dashboard]
listen_addr = "127.0.0.1"
port = 8081
[compression.conversation]
enabled = false # opt-in; default off
mode = "cache_aware" # default; "token" | "cache" | "cache_aware" (see "Choosing a mode")
target_ratio = 0.85
preserve_last_n = 5
compress_types = ["json", "logs", "code"] # default; add "text"/"diff"/"html" to opt in
[compression.shell]
enabled = true
# per-command filters configured under [compression.shell.filters]
[retention]
prune_on_startup = true
max_actions = 5_000_000
max_age_days = 365
[pricing]
# Per-model overrides if the baked-in pricing is wrong for you.
# [pricing.models."claude-opus-4-7"]
# input = 15
# output = 75
# cache_read = 1.5
# cache_creation = 18.75
Troubleshooting
pip install fails with error: externally-managed-environment
Modern Linux distros (Debian 12+, Ubuntu 24.04+, Fedora 38+) mark the system Python as PEP 668 "externally managed" — installing into it would conflict with the OS package manager. Three fixes, pick one:
# 1) RECOMMENDED — uv tool install (isolated env, fastest)
curl -LsSf https://astral.sh/uv/install.sh | sh
uv tool install superbased-observer
# 2) pipx (same isolation, pre-PEP-668 idiomatic)
pipx install superbased-observer
# 3) Plain pip into your user site
pip install --user superbased-observer
# Make sure ~/.local/bin is on $PATH:
echo $PATH | tr ':' '\n' | grep -F "$(python3 -m site --user-base)/bin"
uv tool and pipx create a dedicated virtualenv per tool so the
install never collides with another project. Recommended unless you
have a reason to share the global env.
observer: command not found after install
The console-script entry point is wherever your installer dropped it:
| Installer | Location |
|---|---|
pip install --user |
$(python3 -m site --user-base)/bin/observer (often ~/.local/bin/observer) |
pipx install |
~/.local/bin/observer (symlink to the pipx-managed venv) |
uv tool install |
~/.local/share/uv/tools/superbased-observer/bin/observer (with ~/.local/bin/observer shim) |
Plain pip install in a venv |
<venv>/bin/observer |
Make sure the matching directory is on $PATH. If you see a
"command not found" error, run pip show -f superbased-observer | grep observer
to find the exact path.
observer init says "no tools selected and none auto-detected"
Auto-detection looks for the AI clients' default session-log dirs
(~/.claude/projects/, ~/.codex/sessions/, ~/.cursor/, etc.).
On a fresh machine where no client has run yet, those dirs don't
exist. Pass the flag explicitly:
observer init --claude-code # or --codex / --cursor / --cline / --all
This registers hooks regardless — the next time the client runs, its dirs get created and the watcher picks them up.
Empty dashboard / "No proxy traffic"
The JSONL adapter populates passively after observer init, but
ground-truth cost / compression numbers require the proxy. Set
ANTHROPIC_BASE_URL=http://127.0.0.1:8820 (Claude Code) or
OPENAI_BASE_URL=http://127.0.0.1:8820/v1 (Codex) in the shell
that launches your AI client.
Verify with observer status | grep api_turns — count should
climb during AI-client activity.
observer --version says dev
You're on a non-released build. Reinstall a tagged release with pip install --force-reinstall superbased-observer (or uv tool install --force superbased-observer), or rebuild with the workflow's -X main.version=$VERSION ldflag.
tool_result block must have a corresponding tool_use block
Anthropic 400. Means the conversation-compression pipeline dropped
a tool_use while keeping its matching tool_result. Versions
prior to 1.3.2 had this bug; upgrade. If you're on 1.3.2+ and still
see it, file an issue with the conversation prefix.
tool use concurrency issues
Anthropic 400 surfaced in Claude Code as this message. Means the
parallel-tool-use case (multiple tool_use blocks in one assistant
message) isn't paired correctly with the multi-block tool_result
that follows. Versions prior to 1.3.2 had this bug; upgrade.
Cross-thread numbers are 0
Pre-migration data was ingested without the is_sidechain flag.
Run observer backfill --is-sidechain once to re-walk JSONL and
populate the flag on existing rows.
Migration error: duplicate column name
Race condition between concurrent daemon startups, fixed in 1.4.1.
Upgrade. If you still see it, run daemons serially: observer watch, wait, then observer dashboard, then observer proxy start (or just use observer start which runs all three in one
process — proxy + watcher + dashboard).
observer start log says only proxy + observer — no :8081
You're on a pre-1.4.7 build. Earlier versions ran only proxy +
watcher under observer start; the dashboard had to be started
separately via observer dashboard --addr 127.0.0.1:8081. Upgrade
to 1.4.7+ — the dashboard goroutine is now part of observer start
and the log line confirms all three: proxy <addr> + watcher + dashboard http://127.0.0.1:8081. Pass --no-dashboard to opt out.
"address already in use" on port 8820
Another observer proxy start or observer start is still running.
Find it with pgrep -af 'observer (proxy|start)' and kill <pid>.
On macOS:
lsof -nP -iTCP:8820 -sTCP:LISTEN
kill <pid>
Dashboard port already in use
observer dashboard --addr 127.0.0.1:8082 # pick a different port
# or
[dashboard]
port = 8082 # in config.toml
Security and privacy
Local-only. No telemetry. No remote anything. The watcher, hook handler, dashboard, MCP server, and CLI never make an outbound network call on observer's behalf. The only code paths that touch the network are the optional API proxy (which forwards your requests unchanged to the AI provider you already use) and a handful of explicit opt-in features (message-summary LLM, codegraph MCP, Teams org-server).
The full privacy statement — what observer stores, what it reads,
what it never stores, the explicit list of outbound-network call sites
gated behind config, and how to verify "no telemetry" yourself with
grep, strings, and a network-namespaced shell — lives in
PRIVACY.md.
Operational shorthand:
- Local-only HTTP. The proxy and dashboard bind to
127.0.0.1by default. Don't bind to0.0.0.0unless you've thought about it — there's no auth. - Secrets scrubbing. Tool inputs and outputs pass through
internal/scrub/before persistence; review the regex set if your secrets follow non-default formats. - Database.
~/.observer/observer.dbis a SQLite file with the same security posture as your~/.claude/and~/.codex/session logs (which already hold the same content). Encrypt the disk if your threat model needs that. - Full delete.
rm -rf ~/.observer/removes everything observer ever stored — no traces elsewhere on your system.
Source, contributing, license
- Source: https://github.com/marmutapp/superbased-observer
- Specification:
superbased-final-spec-v2.mdin the repo - Issues: https://github.com/marmutapp/superbased-observer/issues
- License: Apache 2.0
- Author: Santosh Kathira contact@marmut.app
This PyPI package is a thin Python launcher (observer/__main__.py)
that os.execvs the bundled prebuilt binary. Same shape as ruff /
uv / polars — each platform-tagged wheel bundles its
platform's binary directly, and pip's wheel-tag selector picks the
matching one. The Go source lives in the main repo; binaries are
cross-compiled per release tag via GitHub Actions and published
as superbased-observer (PyPI) and @superbased/observer (npm)
side-by-side from the same v* tag.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distributions
Built Distributions
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file superbased_observer-1.8.2-py3-none-win_amd64.whl.
File metadata
- Download URL: superbased_observer-1.8.2-py3-none-win_amd64.whl
- Upload date:
- Size: 12.8 MB
- Tags: Python 3, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b0d99900c63849a0a54f00020424c99b282b8bfd17f6b739385b689b5c52c9b3
|
|
| MD5 |
a75171d2d5c4141f51bb705b79167df1
|
|
| BLAKE2b-256 |
a9220613adad4a06edac51c3e1656a57dcf075f42ecc31fdd46f0c0962acdde6
|
File details
Details for the file superbased_observer-1.8.2-py3-none-manylinux2014_x86_64.whl.
File metadata
- Download URL: superbased_observer-1.8.2-py3-none-manylinux2014_x86_64.whl
- Upload date:
- Size: 15.3 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
cd7844d88f7b3aca03b3d852e93711553a2e7b1fffa76032d3af57b4cfd21fed
|
|
| MD5 |
6c329552c281ecf92ffe4c31f0294614
|
|
| BLAKE2b-256 |
a7cfe5002aa6c8107dd90b5b14d388b5dc50427ff7c602783c1fe2986711063b
|
File details
Details for the file superbased_observer-1.8.2-py3-none-manylinux2014_aarch64.whl.
File metadata
- Download URL: superbased_observer-1.8.2-py3-none-manylinux2014_aarch64.whl
- Upload date:
- Size: 14.4 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
1de2c7df8d622569fb3b53a082843faae4190841fd2a42b7c83b1def5c3d184e
|
|
| MD5 |
830cdd1202793746a9c208c83d849ed6
|
|
| BLAKE2b-256 |
4b0f574766988ecc45c6ec0f0974d37d125d45e83cdd60f90e9938538a354329
|
File details
Details for the file superbased_observer-1.8.2-py3-none-macosx_11_0_arm64.whl.
File metadata
- Download URL: superbased_observer-1.8.2-py3-none-macosx_11_0_arm64.whl
- Upload date:
- Size: 12.1 MB
- Tags: Python 3, macOS 11.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c09be44730122916d9e84a6223a57915cd92482ee3239525a297f017e1a26e2e
|
|
| MD5 |
94601ecd557446af0cf53d0628399733
|
|
| BLAKE2b-256 |
2564bf4e96741e55a64fe4e6c0f59b3bdc6a7ee00b12f8ffa9389f159c4f30ba
|
File details
Details for the file superbased_observer-1.8.2-py3-none-macosx_10_15_x86_64.whl.
File metadata
- Download URL: superbased_observer-1.8.2-py3-none-macosx_10_15_x86_64.whl
- Upload date:
- Size: 12.8 MB
- Tags: Python 3, macOS 10.15+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
50a293c8e51542f3de35623de821f542df254428920ce1c75776a7c980fb50c6
|
|
| MD5 |
d66ce5a005f15219ba77fcad75742679
|
|
| BLAKE2b-256 |
67e6dad7089e6ed9845fc7bab3cfbb9145d7948ff1431eb392336b2290577eaa
|







