Supervisor-orchestrated multi-agent swarms with shared, outcome-optimized context.
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
swarmweave
Multi-agent swarms you can actually see, debug, and improve.



Sequential or parallel multi-agent orchestration on top of LangGraph + the OpenAI API, with three capabilities that most multi-agent frameworks don't bundle together:
- Live terminal dashboard —
swarmweave watch your_swarm.pyopens a split-screen Rich TUI that streams worker status, tool calls, shared-context flow, and accumulating token cost in real time. No moreprint-statement debugging. - Self-improving via lessons — every successful run can distill 1-5 transferable lessons. The next similar run pre-loads them into shared context. Plain JSONL under
~/.swarmweave/lessons/, fully editable, no telemetry. - Shared-context substrate — workers in sequential pipelines read each other's findings via embedding-based retrieval (default
text-embedding-3-small, automatic Jaccard fallback offline).
git clone https://github.com/manav8498/swarmweave
cd swarmweave
./init.sh
source .venv/bin/activate
export OPENAI_API_KEY=sk-...
swarmweave watch examples/03_support_triage_swarm/main.py
The 30-line quickstart
from swarmweave import Supervisor, Worker, SharedContext
from swarmweave.backends import LocalBackend
ctx = SharedContext(backend=LocalBackend())
supervisor = Supervisor(
shared_context=ctx,
model="gpt-4o-mini",
mode="sequential", # or "parallel"
workers=[
Worker(name="classifier", role="Categorize the ticket"),
Worker(name="resolver", role="Draft a reply using the category"),
Worker(name="verifier", role="Check the draft against policy"),
],
)
result = supervisor.run("Handle this support ticket: ...")
print(result.final_output)
The whole public API is three primitives — SharedContext, Supervisor, Worker. Optional Mentor for cross-run learning, EventBus for custom observability.
Should you use this?
Use swarmweave if you're building:
- Sequential pipelines like classify → draft → verify, where later workers genuinely need earlier work
- Multi-specialist reviewers (security / perf / style / coverage) that produce one prioritized output
- Research-style fan-out with shared synthesis
- Anything where you've been fighting LangGraph's state graph to express "worker B reads what worker A wrote"
Don't use it if:
- Your task is a single LLM call — use the OpenAI SDK directly
- You need production observability (traces, eval datasets, dashboards) — use Langfuse or LangSmith
- You need cost/rate guardrails at the proxy level — use LiteLLM
- You've already built on CrewAI/LangGraph/AutoGen and it works — switching cost isn't worth it
This library is a focused scaffold, not a replacement for the broader ecosystem.
Why this pattern
Most multi-agent systems coordinate through the supervisor. Workers run in private context windows; everything they know about each other has to fit in whatever the supervisor relays at handoff. Re-summarization is lossy, workers redo each other's work, and every additional worker makes the coordination problem worse.
swarmweave replaces that with a thin shared-context layer. In sequential mode, each worker's SharedContext.aread() returns every prior worker's findings — so verifier reads resolver's draft, fixer reads investigator's analysis, etc. In parallel mode, workers fan out simultaneously and the supervisor synthesizes from their collective trace.
Architecture
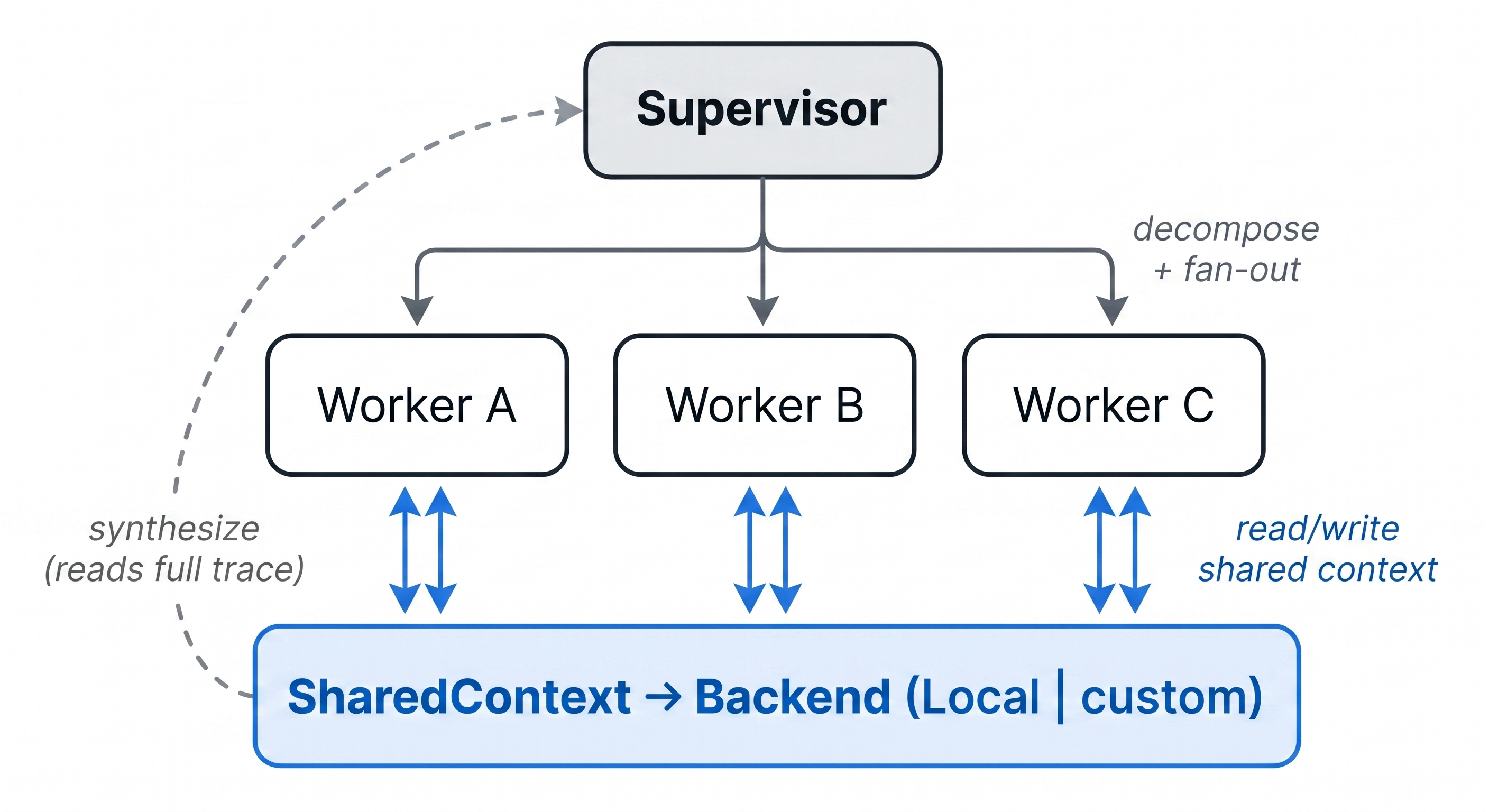
| Class | Role |
|---|---|
SharedContext |
The substrate. aread() returns the slice of past observations most relevant to a task; awrite() appends a new one. Backed by a swappable Backend. |
Supervisor |
Decomposes the task, runs workers (parallel or sequential), synthesizes the final answer, finalizes the outcome. |
Worker |
One specialist. Reads context, autonomously calls tools, writes a finding. Has a forced wrap-up call so reasoning models actually commit to an answer when their tool budget runs out. |
EventBus |
Optional. Streams every event for live observability or custom dashboards. |
Mentor / LessonBook |
Optional. Persistent cross-run memory that makes the swarm self-improving. |
Live TUI — swarmweave watch
┌────── workers ──────┐ ┌────────── shared-context flow ──────────┐
│ classifier ✓ done │ │ 14:22:01 [supervisor] decompose_done │
│ resolver ⠋ tool │ │ 14:22:14 [classifier] WRITE → billing │
│ verifier · idle │ │ 14:22:30 [resolver] READ ← 1 prior │
└─────────────────────┘ │ 14:23:11 [resolver] tool_call: lookup │
└─────────────────────────────────────────┘
┌─ metrics ───────────────────────────────────────────────────────┐
│ elapsed 02:14 │ calls 12 │ in 8,420 │ out 23,991 │ ~$0.0040 │
└──────────────────────────────────────────────────────────────────┘
Built on Rich. 8 fps refresh. Opt-in via EventBus — zero overhead when unused.
Self-improving — Mentor + LessonBook
from swarmweave import Mentor
mentor = Mentor(book="customer_support")
await mentor.before_run(supervisor, user_task) # preloads relevant past lessons
result = await supervisor.arun(user_task)
await mentor.after_run(supervisor, user_task, result) # extracts new lessons
Lessons live as plain JSONL under ~/.swarmweave/lessons/<book>.jsonl. Fully readable, editable, deletable. No telemetry leaves your machine.
Run examples/04_self_improving_swarm/main.py twice — round 2 reads lessons from round 1. The improvement is demonstrable, not theoretical.
Examples
Four runnable examples under examples/. Each is ~80 lines.
| Example | Pattern | What it shows |
|---|---|---|
01_research_swarm |
parallel fan-out | Three researchers + supervisor synthesis |
02_code_review_swarm |
parallel specialists | security / perf / style / coverage → prioritized review |
03_support_triage_swarm |
sequential pipeline | classify → resolve → verify with policy check |
04_self_improving_swarm |
sequential + Mentor | Same task run twice, second round reads first round's lessons |
Watch any of them live in the TUI:
swarmweave watch examples/03_support_triage_swarm/main.py
Benchmark
A 20-task multi-hop benchmark comparing isolated-context (each worker has private memory) against shared-context (workers read each other's findings), sequential mode, same workers, same model, same tools — only the backend differs.
Across two runs of the same benchmark, both modes landed in the 85–100% accuracy range, essentially tied within the variance of gpt-4o-mini outputs. For a concrete qualitative demonstration of where shared context changes worker behavior (e.g., verifier correcting resolver's phrasing based on policy), run examples/03_support_triage_swarm/main.py, or use scripts/real_world_review.py to A/B test both modes against your own codebase.
Reproduce with:
python benchmarks/run_benchmark.py
Full methodology, rubric, and per-task results are in benchmarks/README.md.
Installation
pip install swarmweave
Or from source:
git clone https://github.com/manav8498/swarmweave
cd swarmweave
# macOS / Linux
./init.sh && source .venv/bin/activate
# Windows (PowerShell)
./init.ps1
# Cross-platform alternative (works anywhere Python is)
python -m venv .venv && source .venv/bin/activate # or .venv\Scripts\Activate.ps1 on Windows
pip install -e ".[dev]"
export OPENAI_API_KEY=sk-...
Requirements: Python 3.11+, an OpenAI API key. Default model is gpt-4o-mini — cheap, fast, available to every account.
Cost note: The examples under
examples/and the benchmark underbenchmarks/call the real OpenAI API. Withgpt-4o-minidefaults, a full example run costs roughly $0.001–$0.01; the full 20-task benchmark costs roughly $0.05–$0.20. No telemetry is sent anywhere else.
How this compares
| LangGraph | CrewAI | AutoGen | swarmweave | |
|---|---|---|---|---|
| Graph orchestration | ✅ | partial | partial | ✅ (built on LangGraph) |
| Sequential workers see each other's findings | manual | partial | manual | ✅ via SharedContext |
| Live terminal UI | — | — | — | ✅ swarmweave watch |
| Cross-run learning | — | partial | — | ✅ Mentor + LessonBook |
| Embedding retrieval as default | — | configurable | — | ✅ text-embedding-3-small |
| Forced wrap-up when reasoning models loop | — | — | — | ✅ |
| Apache-2.0, no telemetry | ✅ | ✅ | ✅ | ✅ |
We sit on top of LangGraph, not against it. Bring an existing LangGraph app and compose build_swarm_graph(supervisor) as a sub-graph.
Documentation
docs/architecture.md— the thesis, why shared context mattersdocs/api_reference.md— every public class and methoddocs/custom_backends.md— bring your own retrieval backend in ~80 linesCHANGELOG.md— release history
Roadmap
- v0.1 (this release) —
LocalBackendwith embeddings + Jaccard fallback, LangGraph adapter, sequential/parallel modes, live TUI,Mentor/LessonBook,EventBus, four example swarms, reproducible benchmark. - v0.2 — OpenAI Agents SDK adapter, Anthropic Agent SDK adapter, MCP-tool support in
Worker,swarmweave replay <session>, production-grade cost guardrails. - v0.3 — durable cross-process sessions, structured per-worker output schemas, cloud backend.
Contributing
PRs welcome. See CONTRIBUTING.md for dev setup and the lint/type/test gates, and CODE_OF_CONDUCT.md.
Security
Please report vulnerabilities per SECURITY.md. Do not open public issues for suspected security bugs.
License
Apache-2.0. See LICENSE.
Maintainer
swarmweave is an independent open-source project by @manav8498. Issues and PRs welcome.
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file swarmweave-0.1.0.tar.gz.
File metadata
- Download URL: swarmweave-0.1.0.tar.gz
- Upload date:
- Size: 42.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.12.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a18c7f7e078786d75eb475ee5f412338795a61137f3a3bffc4b1a6448f2b3be9
|
|
| MD5 |
499a21cafdc3842114f59d540e6d8413
|
|
| BLAKE2b-256 |
7e83b366380b4d83cdf7d657a4c00505412bba24582f574be94c60d9ffc27bc1
|
Provenance
The following attestation bundles were made for swarmweave-0.1.0.tar.gz:
Publisher:
release.yml on manav8498/swarmweave
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
swarmweave-0.1.0.tar.gz -
Subject digest:
a18c7f7e078786d75eb475ee5f412338795a61137f3a3bffc4b1a6448f2b3be9 - Sigstore transparency entry: 1346236357
- Sigstore integration time:
-
Permalink:
manav8498/swarmweave@f3d9db9850e2b615f5ac04c441e977413918d491 -
Branch / Tag:
refs/tags/v0.1.0 - Owner: https://github.com/manav8498
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release.yml@f3d9db9850e2b615f5ac04c441e977413918d491 -
Trigger Event:
push
-
Statement type:
File details
Details for the file swarmweave-0.1.0-py3-none-any.whl.
File metadata
- Download URL: swarmweave-0.1.0-py3-none-any.whl
- Upload date:
- Size: 43.8 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.12.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
4adcb46830dc62b3d4bd10ad2e4326b62279d1e0ee8669451499a0ad4e119ab4
|
|
| MD5 |
dba1eacdccef00cd528f183d9aa653ae
|
|
| BLAKE2b-256 |
23523ac8905063688a22d051a502f99ec4d908e5724b5051b94441ca4c8ec2c1
|
Provenance
The following attestation bundles were made for swarmweave-0.1.0-py3-none-any.whl:
Publisher:
release.yml on manav8498/swarmweave
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
swarmweave-0.1.0-py3-none-any.whl -
Subject digest:
4adcb46830dc62b3d4bd10ad2e4326b62279d1e0ee8669451499a0ad4e119ab4 - Sigstore transparency entry: 1346236448
- Sigstore integration time:
-
Permalink:
manav8498/swarmweave@f3d9db9850e2b615f5ac04c441e977413918d491 -
Branch / Tag:
refs/tags/v0.1.0 - Owner: https://github.com/manav8498
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release.yml@f3d9db9850e2b615f5ac04c441e977413918d491 -
Trigger Event:
push
-
Statement type:







