Client for Swiss parliament API

Project description




swissparlpy
This module provides easy access to the data of the OData webservice of the Swiss parliament and the OpenParlData.ch REST API.
Table of Contents
Installation
swissparlpy is available on PyPI, so to install it simply use:
$ pip install swissparlpy
To install with visualization support (for plotting voting results):
$ pip install swissparlpy[visualization]
Usage
See the examples directory for more scripts.
Backend Selection
swissparlpy supports multiple data backends. By default, it uses the official OData API of parlament.ch, but you can also use the OpenParlData.ch REST API.
Using the default OData (parlament.ch) backend:
>>> import swissparlpy as spp
>>> tables = spp.get_tables() # Uses OData service of parlament.ch by default
Using the OpenParlData backend:
>>> import swissparlpy as spp
>>> tables = spp.get_tables(backend='openparldata')
>>> data = spp.get_data('cantons', backend='openparldata')
Using backends with SwissParlClient:
>>> from swissparlpy import SwissParlClient
>>>
>>> # OData backend
>>> odata_client = SwissParlClient(backend="odata")
>>> odata_client.get_tables()
['MemberParty', 'Party', 'Person', 'PersonAddress', 'PersonCommunication', 'PersonInterest', 'Session', 'Committee', 'MemberCommittee', 'Canton', 'Council', 'Objective', 'Resolution', 'Publication', 'External', 'Meeting', 'Subject', 'Citizenship', 'Preconsultation', 'Bill', 'BillLink', 'BillStatus', 'Business', 'BusinessResponsibility', 'BusinessRole', 'LegislativePeriod', 'MemberCouncil', 'MemberParlGroup', 'ParlGroup', 'PersonOccupation', 'RelatedBusiness', 'BusinessStatus', 'BusinessType', 'MemberCouncilHistory', 'MemberCommitteeHistory', 'Vote', 'Voting', 'SubjectBusiness', 'Transcript', 'ParlGroupHistory', 'Tags', 'SeatOrganisationNr', 'PersonEmployee', 'Rapporteur', 'Mutation', 'SeatOrganisationSr', 'MemberParlGroupHistory', 'MemberPartyHistory']
>>> # OpenParlData backend
>>> opd_client = SwissParlClient(backend="openparldata")
>>> opd_client.get_tables()
['bodies', 'speeches', 'persons', 'groups', 'meetings', 'agendas', 'texts', 'votes', 'docs', 'affairs', 'votings', 'interests', 'events', 'external_links', 'contributors', 'person_images', 'memberships', 'access_badges']
All module-level functions (get_tables(), get_variables(), get_overview(), get_glimpse(), get_data()) support the backend parameter.
Note: The OpenParlData backend is still under development. The actual API endpoints and query parameters may need to be adjusted based on the final OpenParlData.ch API specification.
Get tables and their variables
>>> import swissparlpy as spp
>>> spp.get_tables()[:5] # get first 5 tables
['MemberParty', 'Party', 'Person', 'PersonAddress', 'PersonCommunication']
>>> spp.get_variables('Party') # get variables of table `Party`
['ID', 'Language', 'PartyNumber', 'PartyName', 'StartDate', 'EndDate', 'Modified', 'PartyAbbreviation']
Get data of a table
>>> import swissparlpy as spp
>>> data = spp.get_data('Canton', Language='DE')
>>> data
<swissparlpy.client.SwissParlResponse object at 0x7f8e38baa610>
>>> data.count
26
>>> data[0]
{'ID': 2, 'Language': 'DE', 'CantonNumber': 2, 'CantonName': 'Bern', 'CantonAbbreviation': 'BE'}
>>> [d['CantonName'] for d in data]
['Bern', 'Neuenburg', 'Genf', 'Wallis', 'Uri', 'Schaffhausen', 'Jura', 'Basel-Stadt', 'St. Gallen', 'Obwalden', 'Appenzell A.-Rh.', 'Solothurn', 'Waadt', 'Zug', 'Aargau', 'Basel-Landschaft', 'Luzern', 'Thurgau', 'Freiburg', 'Appenzell I.-Rh.', 'Schwyz', 'Graubünden', 'Glarus', 'Tessin', 'Zürich', 'Nidwalden']
The return value of get_data is iterable, so you can easily loop over it. Or you can use indices to access elements, e.g. data[1] to get the second element, or data[-1] to get the last one.
Even slicing is supported, so you can do things like only iterate over the first 5 elements using
for rec in data[:5]:
print(rec)
Get data from a specific backend
Use the backend parameter to specify which backend you want to query.
>>> import swissparlpy as spp
>>> data = spp.get_data('persons', firstname="Stefan", backend="openparldata")
>>> data
<swissparlpy.client.SwissParlResponse object at 0x0000023357FF9F60>
>>> data.count
234
>>> data[0]
{'id': 11374, 'url_api': 'https://api.openparldata.ch/v1/persons/11374', 'body_key': 'LU', 'external_id': '890ce2d9430741659346d8f2d9074e77', 'external_alternative_id': None, 'title': None, 'fullname': 'Stefan Roth', 'firstname': 'Stefan', 'lastname': 'Roth', 'body_id': 261, 'party_de': 'CVP', 'party_fr': None, 'party_it': None, 'party_external_id': None, 'party_harmonized_de': 'Christlichdemokratische Volkspartei der Schweiz', 'party_harmonized_fr': 'Parti démocrate-chrétien', 'party_harmonized_it': 'Partito popolare democratico', 'party_harmonized_en': "Christian Democratic People's Party", 'party_harmonized_wikidata_id': 'Q659461', 'website_parliament_url_de': 'https://www.lu.ch/kr/mitglieder_und_organe/mitglieder/mitglieder_detail?Id=890ce2d9430741659346d8f2d9074e77', 'website_parliament_url_fr': None, 'website_parliament_url_it': None, 'image_url_external': 'https://www.lu.ch/kr/parlamentsgeschaefte/CdwsFiles?fotoid=890ce2d9430741659346d8f2d9074e77-1664&version=2', 'image_url_oparl': 'https://files.openparldata.ch/images/persons/original/LU-11374_v1.jpg', 'email': None, 'phone': None, 'birthday': '1960-01-01', 'birthday_format': 'year', 'deathday': None, 'street': None, 'postal_code': None, 'city': 'Luzern', 'occupation_de': 'Betriebsökonom FH / Executive MBA', 'occupation_fr': None, 'occupation_it': None, 'marital_status_de': None, 'marital_status_fr': None, 'marital_status_it': None, 'electoral_district_de': 'Luzern-Stadt', 'electoral_district_fr': None, 'electoral_district_it': None, 'website_personal': None, 'gender': 'm', 'parliamentary_group_name_de': None, 'parliamentary_group_name_fr': None, 'parliamentary_group_name_it': None, 'parliamentary_group_name_rm': None, 'parliamentary_group_external_id': None, 'parliament_sector': None, 'parliament_seat': None, 'active': False, 'language': 'de', 'function_latest_de': None, 'function_latest_fr': None, 'function_latest_it': None, 'function_latest_rm': None, 'function_latest_external_id': None, 'wikidata_id': None, 'updated_external_at': None, 'updated_at': '2026-02-22T11:57:59', 'created_at': '2025-08-14T06:31:49', 'links': {'memberships': 'https://api.openparldata.ch/v1/persons/11374/memberships', 'interests': 'https://api.openparldata.ch/v1/persons/11374/interests', 'access_badges': 'https://api.openparldata.ch/v1/persons/11374/access_badges', 'contributors': 'https://api.openparldata.ch/v1/persons/11374/contributors', 'affairs': 'https://api.openparldata.ch/v1/persons/11374/affairs', 'speeches': 'https://api.openparldata.ch/v1/persons/11374/speeches', 'votes': 'https://api.openparldata.ch/v1/persons/11374/votes', 'external_links': 'https://api.openparldata.ch/v1/persons/11374/external_links', 'person_images': 'https://api.openparldata.ch/v1/persons/11374/person_images', 'bodies': 'https://api.openparldata.ch/v1/persons/11374/bodies'}}
Or create a client object to create a specfic backend
import swissparlpy as spp
opd_client = spp.SwissParlClient(backend="openparldata")
odata_client = SwissParlClient(backend="odata")
# then use the client to query the backend
person_vars_opd = opd_client.get_variables("persons")
person_vars_odata = odata_client.get_variables("Person")
Use together with pandas
To create a pandas DataFrame from get_data simply pass the return value to the constructor:
>>> import swissparlpy as spp
>>> import pandas as pd
>>> parties = spp.get_data('Party', Language='DE')
>>> parties_df = pd.DataFrame(parties)
>>> parties_df
ID Language PartyNumber ... EndDate Modified PartyAbbreviation
0 12 DE 12 ... 2000-01-01 00:00:00+00:00 2010-12-26 13:05:26.430000+00:00 SP
1 13 DE 13 ... 2000-01-01 00:00:00+00:00 2010-12-26 13:05:26.430000+00:00 SVP
2 14 DE 14 ... 2000-01-01 00:00:00+00:00 2010-12-26 13:05:26.430000+00:00 CVP
3 15 DE 15 ... 2000-01-01 00:00:00+00:00 2010-12-26 13:05:26.430000+00:00 FDP-Liberale
4 16 DE 16 ... 2000-01-01 00:00:00+00:00 2010-12-26 13:05:26.430000+00:00 LDP
.. ... ... ... ... ... ... ...
78 1582 DE 1582 ... 2000-01-01 00:00:00+00:00 2015-12-03 08:48:38.250000+00:00 BastA
79 1583 DE 1583 ... 2000-01-01 00:00:00+00:00 2019-03-07 17:24:15.013000+00:00 CVPO
80 1584 DE 1584 ... 2000-01-01 00:00:00+00:00 2019-11-08 17:28:43.947000+00:00 Al
81 1585 DE 1585 ... 2000-01-01 00:00:00+00:00 2019-11-08 17:41:39.513000+00:00 EàG
82 1586 DE 1586 ... 2000-01-01 00:00:00+00:00 2021-08-12 07:59:22.627000+00:00 M-E
[83 rows x 8 columns]
Or use the convenience method .to_dataframe():
>>> import swissparlpy as spp
>>> parties_df = spp.get_data('Party', Language='DE').to_dataframe()
Large queries
Large queries (especially the tables Voting and Transcripts) may result in server-side errors (500 Internal Server Error). In these cases it is recommended to download the data in smaller batches, save the individual blocks and combine them after the download.
This is an example script to download all votes of the legislative period 50, session by session, and combine them afterwards in one DataFrame:
import swissparlpy as spp
import pandas as pd
import os
__location__ = os.path.realpath(os.getcwd())
path = os.path.join(__location__, "voting50")
# download votes of one session and save as pickled DataFrame
def save_votes_of_session(id, path):
if not os.path.exists(path):
os.mkdir(path)
data = spp.get_data("Voting", Language="DE", IdSession=id)
print(f"{data.count} rows loaded.")
df = pd.DataFrame(data)
pickle_path = os.path.join(path, f'{id}.pks')
df.to_pickle(pickle_path)
print(f"Saved pickle at {pickle_path}")
# get all session of the 50 legislative period
sessions50 = spp.get_data("Session", Language="DE", LegislativePeriodNumber=50)
sessions50.count
for session in sessions50:
print(f"Loading session {session['ID']}")
save_votes_of_session(session['ID'], path)
# Combine to one dataframe
df_voting50 = pd.concat([pd.read_pickle(os.path.join(path, x)) for x in os.listdir(path)])
OData backend specific options
Some features (like advanced filters) or only available with the OData backend.
Substrings
If you want to query for substrings there are two main operators to use:
__startswith:
>>> import swissparlpy as spp
>>> persons = spp.get_data("Person", Language="DE", LastName__startswith='Bal')
>>> persons.count
12
__contains
>>> import swissparlpy as spp
>>> co2_business = spp.get_data("Business", Title__contains="CO2", Language = "DE")
>>> co2_business.count
265
You can suffix any field with those operators to query the data.
Date ranges
To query for date ranges you can use the operators...
__gt(greater than)__gte(greater than or equal)__lt(less than)__lte(less than or equal)
...in combination with a datetime object.
>>> import swissparlpy as spp
>>> from datetime import datetime
>>> business = spp.get_data(
... "Business",
... Language="DE",
... SubmissionDate__gt=datetime.fromisoformat('2019-09-30'),
... SubmissionDate__lte=datetime.fromisoformat('2019-10-31')
... )
>>> business.count
22
Advanced filter
Text query
It's possible to write text queries using operators like eq (equals), ne (not equals), lt/lte (less than/less than or equals), gt / gte (greater than/greater than or equals), startswith() and contains:
import swissparlpy as spp
import pandas as pd
persons = spp.get_data(
"Person",
filter="(startswith(FirstName, 'Ste') or LastName eq 'Seiler') and Language eq 'DE'"
)
df = pd.DataFrame(persons)
print(df[['FirstName', 'LastName']])
Callable Filter
You can provide a callable as a filter which allows for more advanced filters.
swissparlpy.Filter provides or_ and and_.
import swissparlpy as spp
import pandas as pd
# filter by FirstName = 'Stefan' OR LastName == 'Seiler'
def filter_by_name(ent):
return spp.Filter.or_(
ent.FirstName == 'Stefan',
ent.LastName == 'Seiler'
)
df = spp.get_data("Person", filter=filter_by_name, Language='DE').to_dataframe()
print(df[['FirstName', 'LastName']])
Documentation
The referencing table has been created and is available here. It contains the dependency diagram between all of the tables as well, some exhaustive descriptions as well as the code needed to generate such interactive documentation. The documentation can indeed be recreated using dbdiagram.io.
Below is a first look of what the dependencies are between the tables contained in the API:

Visualize voting results
The plot_voting function allows you to visualize voting results of the Swiss National Council according to the seating order.
Warning: The mapping from seats to persons is currently not historized, so "older" votes might not be displayed correctly. You can provide your own mapping with the seats parameter.
Note: This feature requires matplotlib and pandas. Install with: pip install swissparlpy[visualization]
>>> import swissparlpy as spp
>>> import matplotlib.pyplot as plt
>>>
>>> # Get voting data for a specific vote
>>> votes = spp.get_data("Voting", Language="DE", IdVote=23458)
>>>
>>> # Create visualization with default scoreboard theme
>>> fig = spp.plot_voting(votes, theme='scoreboard', result=True)
>>> plt.show()
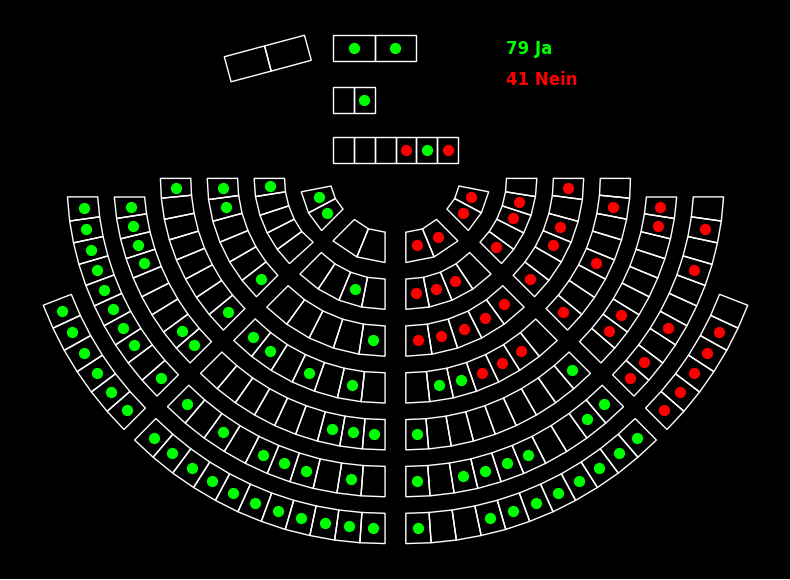
The function supports different themes:
scoreboard: Imitates the council hall scoreboard (neon colors on black background)sym1,sym2: Colored symbols on light backgroundpoly1,poly2,poly3: Color-filled polygons with different edge styles
You can also highlight specific parliamentary groups:
>>> # Highlight a parliamentary group
>>> fig = spp.plot_voting(
... votes_df,
... theme='poly1',
... highlight={'ParlGroupCode': ["S"]},
... result=True
... )
>>> plt.show()
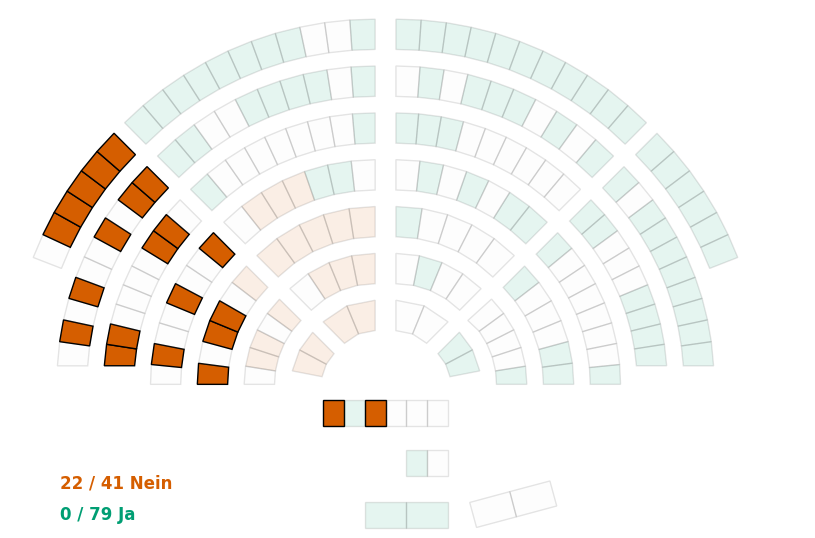
See the visualization example for more details.
OpenParlData backend specific options
Search
The OpenParlDataBackend has the ability to filter and search, all the parameters described in the API documentation can be used here.
Filter by values
>>> import swissparlpy as spp
>>>
>>> opd_client = spp.SwissParlClient(backend="openparldata")
>>> response = opd_client.get_data("persons", firstname="Karin", lastname="Keller-Sutter")
>>> df = response.to_dataframe()
>>> print(df[['firstname', 'lastname', "title"]])
firstname lastname title
0 Karin Keller-Sutter Dipl. Konferenzdolmetscherin
Search in the data
>>> import swissparlpy as spp
>>>
>>> opd_client = spp.SwissParlClient(backend="openparldata")
>>> response = opd_client.get_data("speeches", search_mode="natural", search_scope="all", search_language="de", search="Budget")
>>> len(response)
457
>>> df = response.to_dataframe()
>>> df[["id", "body_key", "person_id", "meeting_id", "date_start", "date_end", "text_content_de"]]
id body_key person_id meeting_id date_start date_end text_content_de
0 1100333 351 4256.0 1262 2024-11-14T18:18:52 None <p><b>Corina Liebi (JGLP)</b> für die PVS: Für...
1 1100301 351 4191.0 1578 2024-05-30T22:24:34 None <p><b>Ursina Anderegg (GB)</b> für die Fraktio...
2 1100187 351 4139.0 1219 2025-11-20T18:02:10 None <p><b>Debora Alder-Gasser (EVP)</b> für die Ko...
3 1100167 351 4315.0 1219 2025-11-20T17:11:50 None <p><b>Simone Richner (FDP)</b> für die Kommiss...
4 1100016 351 4237.0 1628 2024-06-27T13:44:06 None <p><b>Franziska Geiser (GB)</b> für die FIKO: ...
.. ... ... ... ... ... ... ...
452 1088291 351 4237.0 1193 2025-03-27T21:51:35 None <p><b>Franziska Geiser (GB)</b> für die Frakti...
453 1088272 351 4162.0 1404 2025-03-20T17:36:23 None <p><b>Janina Aeberhard (GLP)</b> für die Kommi...
454 1088255 351 4123.0 1870 2023-09-21T15:50:27 None <p><b>Barbara Keller (SP)</b> für die SBK: Ich...
455 1088206 351 4114.0 1404 2025-03-20T17:50:35 None <p><b>Laura Curau (Mitte)</b> für die Fraktion...
456 1088186 351 4237.0 1404 2025-03-20T18:39:10 None <p><b>Franziska Geiser (GB)</b> für die Frakti...
[457 rows x 7 columns]
Get related data
The OpenParlData-API returns related tables/entities for their data. E.g. if you query persons the API will return all related entities like memberships or affairs.
>>> import swissparlpy as spp
>>>
>>> opd_client = spp.SwissParlClient(backend="openparldata")
>>> geru = opd_client.get_data("persons", firstname="Gerhard", lastname="Andrey")[0]
>>> geru.get_related_tables()
['memberships', 'interests', 'access_badges', 'contributors', 'affairs', 'speeches', 'votes', 'external_links', 'person_images', 'bodies']
>>> member_df = geru.get_related_data('memberships').to_dataframe()
>>> print(member_df[["external_id", "group_name_de", "role_name_de", "type_harmonized"]].head())
external_id group_name_de role_name_de type_harmonized
0 CHE_interest_kultur_4245 Kultur Mitglied interest_group
1 936edfe6-f8fd-4667-a986-ab5200acafb9 Gruppe Parlaments-IT (PIT) Mitglied committee_ad_hoc
2 6f42fed7-0dc6-4ed7-b655-b391ad828068 Gruppe Parlaments-IT (PIT) Mitglied committee_ad_hoc
3 63898798-ac17-469f-bb21-5e562d76b1de Gruppe Parlaments-IT (PIT) Vizepräsident/in committee_ad_hoc
4 28d9ed41-e55c-4c55-a1f3-ab1300c25d52 Büro NR Stimmenzähler/in committee
Similar libraries for other languages
- R: zumbov2/swissparl
- JavaScript: michaelschoenbaechler/swissparl
Credits
This library is inspired by the R package swissparl of David Zumbach.
Ralph Straumann initial asked about a Python version of swissparl on Twitter, which led to this project.
Development
To develop on this project, install uv:
curl -LsSf https://astral.sh/uv/install.sh | sh
uv pip install -e ".[dev,test]"
Alternatively, use the provided setup script:
./dev_setup.sh
Release
To create a new release, follow these steps (please respect Semantic Versioning):
- Adapt the version number in
swissparlpy/__init__.py - Update the CHANGELOG with the version
- Update the website in the
websitedirectory if necessary (at least the version number) - Create a pull request to merge
developintomain(make sure the tests pass!) - Create a new release/tag on GitHub (on the main branch)
- The publication on PyPI happens via GitHub Actions on every tagged commit


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file swissparlpy-1.0.0.tar.gz.
File metadata
- Download URL: swissparlpy-1.0.0.tar.gz
- Upload date:
- Size: 1.7 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.10.6 {"installer":{"name":"uv","version":"0.10.6","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true}
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
7379e471c94c715ba4f15b7e64f44a66774756ad04cb605d3c17a15b01ca6d1b
|
|
| MD5 |
60b39cfaf0c07bc0e8580d106c2701df
|
|
| BLAKE2b-256 |
c06ca78b6ca960cb0009ee6780007a114e52aa01e1af373f27de80d041537c67
|
File details
Details for the file swissparlpy-1.0.0-py3-none-any.whl.
File metadata
- Download URL: swissparlpy-1.0.0-py3-none-any.whl
- Upload date:
- Size: 31.4 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.10.6 {"installer":{"name":"uv","version":"0.10.6","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true}
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
2224346a8567e3873dbdd95edbcdd722a40297db2a1e9bf8dce6b7292b43cbf6
|
|
| MD5 |
572e731c18c11287879fb2543ce2d554
|
|
| BLAKE2b-256 |
b4a5e1747abbf7f84075dac039cd6ac874dfb600b71ab167e0b4ead806a0ba77
|







