Serverless Posttraining for Agents - Core AI functionality and tracing

Project description
Synth







Serverless Posttraining APIs for Developers
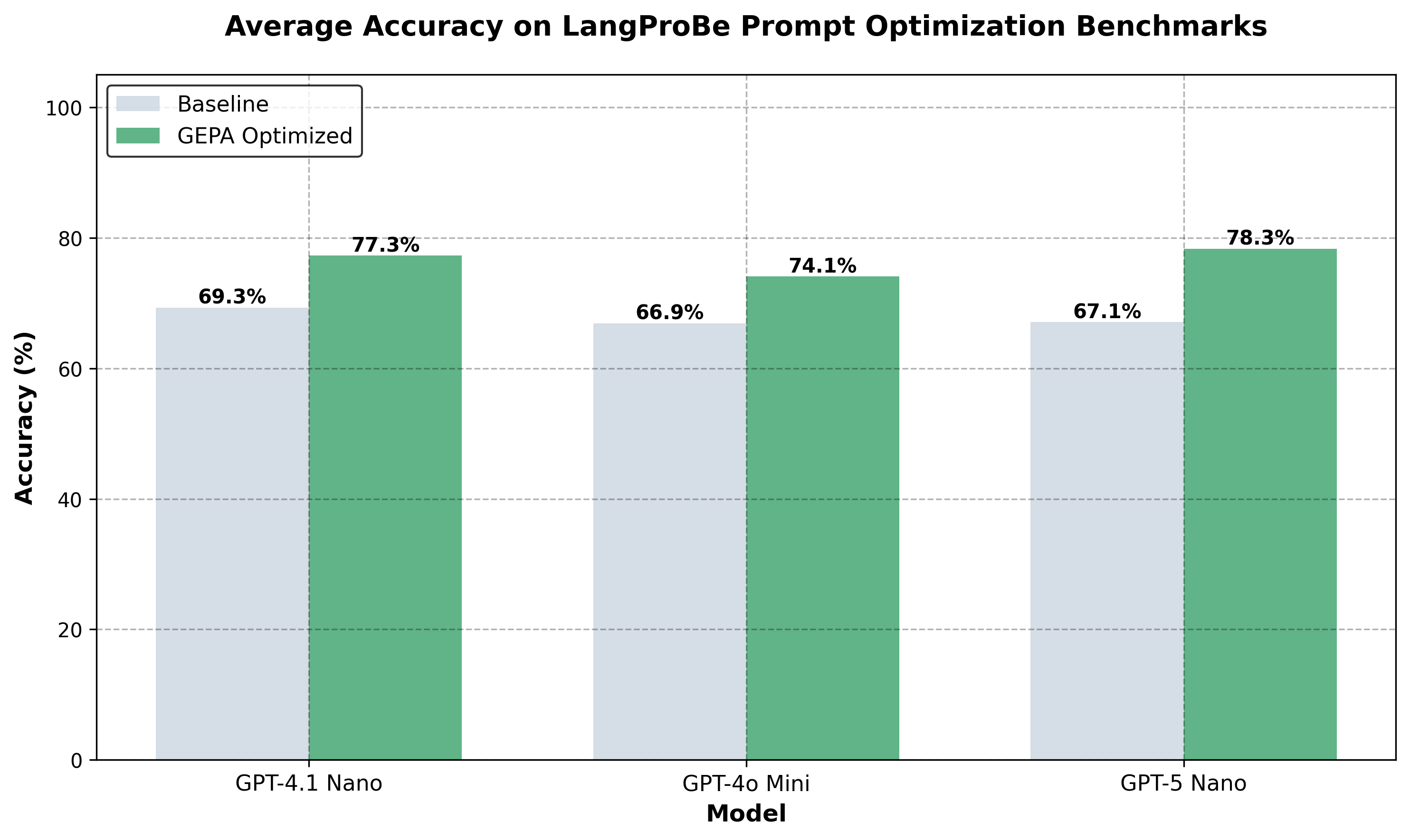
Average accuracy on LangProBe prompt optimization benchmarks.
Demo Notebooks (Colab)
- GEPA Banking77 Prompt Optimization
- GEPA Crafter VLM Verifier Optimization
- GraphGen Image Style Matching
Highlights
- 🚀 Train across sft, RL, and prompt opt by standing up a single cloudflared Fastapi wrapper around your code. No production code churn.
- ⚡️ Parallelize training and achieve 80% GPU util. via PipelineRL
- 🗂️ Train prompts and models across multiple experiments
- 🛠️ Spin up experiment queues and datastores locally for dev work
- 🔩 Run serverless training via cli or programmatically
- 🏢 Scales gpu-based model training to 64 H100s seemlessly
- 💾 Use GEPA-calibrated verifiers for fast, accurate rubric scoring
- 🖥️ Supports HTTP-based training across all programming languages
- 🤖 CLI utilities tuned for use with Claude Code, Codex, Opencode
Getting Started
# Use with OpenAI Codex
uvx synth-ai codex
# Use with Opencode
uvx synth-ai opencode
Testing
Run the TUI integration tests:
cd synth_ai/_tui
bun test
Synth is maintained by devs behind the MIPROv2 prompt optimizer.
Documentation
In-Process Runner (SDK)
Run GEPA/MIPRO/RL jobs against a tunneled task app without the CLI:
import asyncio
import os
from synth_ai.sdk.task import run_in_process_job
result = asyncio.run(
run_in_process_job(
job_type="prompt_learning",
config_path="configs/style_matching_gepa.toml",
task_app_path="task_apps/style_matching_task_app.py",
overrides={"prompt_learning.gepa.rollout.budget": 4},
backend_url=os.getenv("TARGET_BACKEND_BASE_URL"), # resolves envs automatically
)
)
print(result.job_id, result.status.get("status"))
Zero-Shot Verifiers (SDK)
Run a built-in verifier graph with rubric criteria passed at runtime:
import asyncio
import os
from synth_ai.sdk.graphs import VerifierClient
async def run_verifier():
client = VerifierClient(
base_url=os.environ["SYNTH_BACKEND_BASE"],
api_key=os.environ["SYNTH_API_KEY"],
)
result = await client.evaluate(
job_id="zero_shot_verifier_single",
trace={"session_id": "s", "session_time_steps": []},
rubric={
"event": [{"id": "accuracy", "weight": 1.0, "description": "Correctness"}],
"outcome": [{"id": "task_completion", "weight": 1.0, "description": "Completed task"}],
},
options={"event": True, "outcome": True, "model": "gpt-5-nano"},
policy_name="my_policy",
task_app_id="my_task",
)
return result
asyncio.run(run_verifier())
You can also call arbitrary graphs directly:
from synth_ai.sdk.graphs import GraphCompletionsClient
client = GraphCompletionsClient(base_url="https://api.usesynth.ai", api_key="...")
resp = await client.run(
graph={"kind": "zero_shot", "verifier_shape": "mapreduce", "verifier_mode": "rubric"},
input_data={"trace": {"session_id": "s", "session_time_steps": []}, "rubric": {"event": [], "outcome": []}},
)
GraphGen: Train Custom Verifier and RLM Graphs
Train custom verifier and RLM graphs using GraphGen:
from synth_ai.sdk.api.train.graphgen import GraphGenJob
# Train a verifier graph
verifier_job = GraphGenJob.from_dataset(
dataset="verifier_dataset.json",
graph_type="verifier",
policy_models=["gpt-4.1"],
proposer_effort="medium", # Use "medium" (gpt-4.1) or "high" (gpt-5.2)
rollout_budget=200,
)
verifier_job.submit()
result = verifier_job.stream_until_complete(timeout=3600.0)
# Run inference with trained verifier
verification = verifier_job.run_verifier(
trace=my_trace,
context={"rubric": my_rubric},
)
print(f"Score: {verification.score}, Reasoning: {verification.reasoning}")
# Train an RLM graph (massive context via tools)
rlm_job = GraphGenJob.from_dataset(
dataset="rlm_dataset.json",
graph_type="rlm",
configured_tools=[
{"name": "materialize_context", "kind": "rlm_materialize", "stateful": True},
{"name": "local_grep", "kind": "rlm_local_grep", "stateful": False},
{"name": "codex_exec", "kind": "daytona_exec", "stateful": True},
],
policy_models=["gpt-4.1"],
proposer_effort="medium",
rollout_budget=100,
)
rlm_job.submit()
result = rlm_job.stream_until_complete(timeout=3600.0)
# Run inference with trained RLM graph
output = rlm_job.run_inference({"query": "Find relevant sections", "context": large_document})
Graph Types:
verifier: Trains a verifier graph that evaluates traces and returns structured rewardsrlm: Trains a graph optimized for massive contexts (1M+ tokens) using tool-based searchpolicy: Trains a standard input→output graph (default)
RLM Tools:
materialize_context- Store input fields for fast searching (~1ms local)local_grep- Regex search on materialized content (~1ms)local_search- Substring search (~1ms)query_lm- Sub-LM calls for processing chunkscodex_exec- Shell execution for complex operations
When to use RLM:
- Context exceeds ~100K tokens (too large for prompt)
- You need to search/filter large datasets
- RAG-style workflows over massive corpora
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file synth_ai-0.4.6.tar.gz.
File metadata
- Download URL: synth_ai-0.4.6.tar.gz
- Upload date:
- Size: 1.3 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.9.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9a2fc15d43e17b27522a2bfe8e8240e9e9d7d0e69a324ac8d85fbd8b5f3d7202
|
|
| MD5 |
e4a8cc7f2ecf030fc9b6cefa0588d39f
|
|
| BLAKE2b-256 |
cf938c30ffcd4f19616b166adcb0f6299ee9309b21c54f7716dda90a1c8ccc27
|
File details
Details for the file synth_ai-0.4.6-py3-none-any.whl.
File metadata
- Download URL: synth_ai-0.4.6-py3-none-any.whl
- Upload date:
- Size: 1.4 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.9.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
fb9e802392657a7986e451b98006773efda9147611377e3d6e203de55c8c2d49
|
|
| MD5 |
e9633bc247adfce086fb203520451014
|
|
| BLAKE2b-256 |
ee522b820149cbe1f476ab6327b3299fdd453c19138f5a1617d204eb6a23db1b
|







