A bioinformatics tool for genome-scale prediction of bacterial type IV secreted effectors using pre-trained protein language model.

Project description
T4SEfinder:
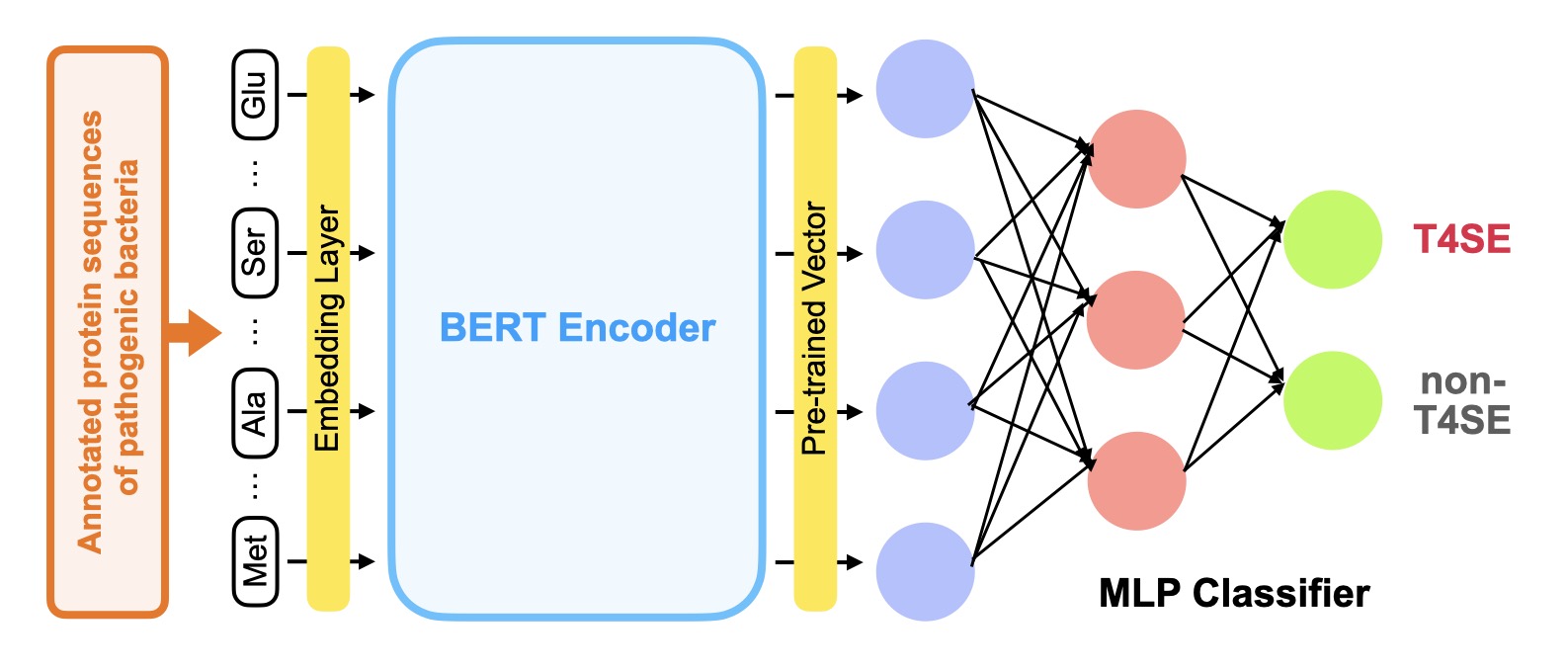
Pytorch implementation of T4SEfinder, a genome-scale annotation tool for bacterial type IV secretion system effectors (T4SEs) using pre-trained model. T4SEfinder integrates experimental verified T4SEs in SecReT4 database and those in other studies as the training dataset. It applies protein pre-trained language model(provided by TAPE repository) to the prediction task and achieves high testing accuracy(97.2%). It also provides genome-scale prediction for T4SEs.
Set up
The stand-alone version of T4SEfinder has been tested in Linux version 3.10.0-1062.12.1.el7.x86_64 as well as macOS Big Sur 11.2.3.
Before using the T4SEfinder, please ensure that Python has been installed in your server.
Please check the requirements.txt file for more details on required Python packages. You can create new environment and install all required packages with:
pip install -r requirements.txt
The model paramter files can be download at here.
Using T4SEfinder
T4SEfinder can predict T4SEs from protein sequences in the FASTA format.
python main.py -in example/demo.fasta -weights weights/mlp/ -vote tapebert_mlp
The prediction results can be found in results/, including predicted probabilities by model weights from 5-fold cross validation and putative T4SEs after voting.
Besides the most recommended model TAPEBert_MLP, T4SEfinder provides another three approaches in T4SEs prediction.
TAPEBert_SVM: replaces the downstream classifier into SVM.PSSM_CNN: based on positional-specific scoring matrix(PSSM) and CNN.HybridBiLSTM: conbines pre-trained feature and PSSM at C terminal in BiLSTM. If you want to used the model base on PSSM feature, NCBI BLAST+ 2.10.0 is required(can be downloaded from ftp.ncbi.nlm.nih.gov), and the Swissprot database can be downloaded at here.
T4SEfinder can annotate bacteria genome to discover T4SE-encoding genes.
./pred_all_model <NCBI Accession Number> # e.g. NC012442
You can receive the summarized results obtained by various methods in summary.csv.
Testing Result
We have compared T4SEfinder(TAPEBert_MLP) with existing prediction tools according to the perfomance on an independent test set(30 T4SEs + 150 none-T4SEs).
| Method | ACC | SN | SP | PR | F1 | MCC |
|---|---|---|---|---|---|---|
| T4SEpre_psAac | 90.0% | 63.3% | 95.3% | 73.1% | 0.679 | 0.622 |
| T4SEpre_bpbAac | 88.3% | 66.7% | 92.7% | 64.5% | 0.656 | 0.586 |
| DeepT4 | 86.7% | 80.0% | 88.0% | 57.1% | 0.667 | 0.599 |
| BastionX | 93.3% | 100.0% | 92.0% | 71.4% | 0.833 | 0.811 |
| CNNT4SE_Vote | 97.8% | 86.7% | 100.0% | 100.0% | 0.929 | 0.919 |
| TAPEBert_MLP | 97.2% | 93.3% | 98.0% | 90.3% | 0.918 | 0.901 |
Apart from the considerable prediction accuracy, T4SEfinder shows a major advantage in computational efficiency due to the adoptation of protein pre-trained langugae model.
Contact
Please contact Yumeng Zhang at zhangyumeng1@sjtu.edu.cn for questions.
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file T4SEfinder-0.1.0.tar.gz.
File metadata
- Download URL: T4SEfinder-0.1.0.tar.gz
- Upload date:
- Size: 6.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.7.1 importlib_metadata/4.8.1 pkginfo/1.8.2 requests/2.26.0 requests-toolbelt/0.9.1 tqdm/4.62.3 CPython/3.7.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a756434dd6387713552e0f30a7637d8b35a2df7e9223e3f5165c4f7abe50fae7
|
|
| MD5 |
003dbd427c13c4a08732fdbbc8dad8a5
|
|
| BLAKE2b-256 |
765aade4e8613f88a30a1cb4254af3b9748801d4c46cd2d5caaa6cbc99e5c3e9
|
File details
Details for the file T4SEfinder-0.1.0-py3-none-any.whl.
File metadata
- Download URL: T4SEfinder-0.1.0-py3-none-any.whl
- Upload date:
- Size: 8.2 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.7.1 importlib_metadata/4.8.1 pkginfo/1.8.2 requests/2.26.0 requests-toolbelt/0.9.1 tqdm/4.62.3 CPython/3.7.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
bacc4c338a759736ed926e9c2a649d847d6b82a0db6569281029ef89fb520077
|
|
| MD5 |
f222d237301ab614d874b28d2000f44c
|
|
| BLAKE2b-256 |
fe5b0c8aad70c65ea57ef17534b26bcf123b51257c853e611129c45d1c47ab6b
|







