Kernel similarity for classification and clustering of multi-variate time series with missing values.

Project description

The Time Series Cluster Kernel (TCK) is a kernel similarity for multivariate time series with missing values. The kernel can be used to perform tasks such as classification, clustering, and dimensionality reduction.
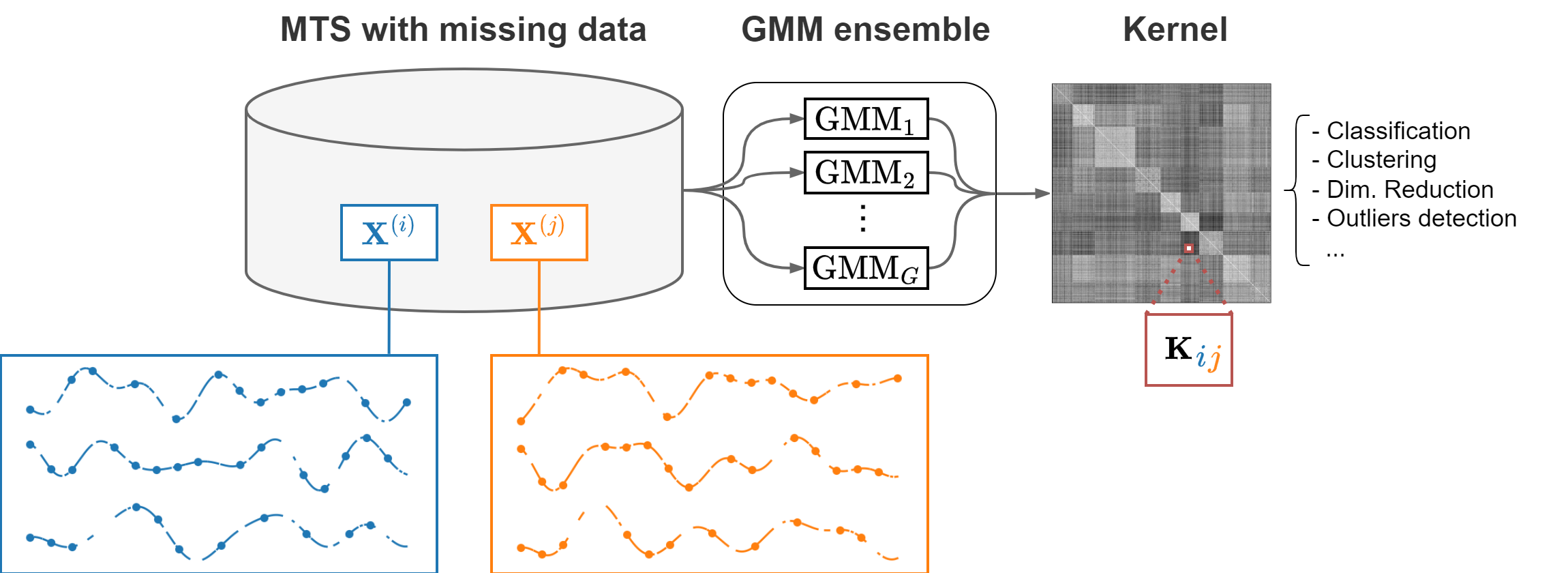
TCK is based on an ensemble of Gaussian Mixture Models for time series that use informative Bayesian priors robust to missing values. The similarity between two time series is proportional to the number of times the two time series are assigned to the same mixtures.
Installation
The recommended installation is with pip:
pip install tck
Alternatively, you can install the library from source:
git clone https://github.com/FilippoMB/https://github.com/FilippoMB/Time-Series-Cluster-Kernel.git
cd https://github.com/FilippoMB/Time-Series-Cluster-Kernel
pip install -e .
Quick start
The following scripts provide minimalistic examples that illustrate how to use the library for different tasks.
To run them, download the project and cd to the root folder:
git clone https://github.com/FilippoMB/https://github.com/FilippoMB/Time-Series-Cluster-Kernel.git
cd https://github.com/FilippoMB/Time-Series-Cluster-Kernel
Classification
python examples/classification.py
Clustering
python examples/clustering.py
The following notebooks illustrate more advanced use-cases.
- Perform time series dimensionality reduction, cluster analysis, and visualize the results: view or

Running on Windows
TCK uses multiprocessing. While using multiprocessing in Python on windows, it is necessary to protect the entry point of the program by using
if __name__ == '__main__':
Please, refer to the following examples.
Classification
python examples/classification_windows.py
Clustering
python examples/clustering_windows.py
Datasets
Data format
- TCK works both with univariate and multivariate time series. The dataset must be stored in a numpy array of shape
[N, T, V], whereNis the number of variables,Tis the number of time steps, andVis the number of variables (V=1in the univariate case). - If the time series in the same dataset have a different number of time steps,
Tcorresponds to the maximum length of the time series in the dataset. All the time series shorter thanTshould be padded with trailing zeros to match the dimensionT. Alternatively, one can use interpolation to stretch the shorter time series up to lengthT. - The time series can contain missing data. Missing data dare indicated by entries
np.nanin the data array.
Available datasets
There are several univariate and multivariate time series classification datasets immediately available for test and benchmarking purposes.
To list of available datasets can be retrieved as follows
from tck.datasets import DataLoader
downloader.available_datasets(details=True) # Leave at False to just get the names
A dataset can be loaded as follows
Xtr, Ytr, Xte, Yte = downloader.get_data('Japanese_Vowels')
Configuration and detailed usage
There are few hyperparameters that can be tuned to modify the TCK behavior.
tck = TCK(G, C)
Gis the number of GMMs.Cis the number of components in the GMMs.
Usually, the higher the better but the computations take longer.
tck.fit(X, minN, minV, maxV, minT, maxT, I)
minN: Minimum percentage of samples to be used in the training of the GMMs.
minV: Minimum number of attributes to be sampled from the dataset.
maxV: Maximum number of attributes to be sampled from the dataset.
minT: Minimum length of time segments to be sampled from the dataset.
maxT: Maximum length of time segments to be sampled from the dataset.
I: Number of iterations for the MAP-EM algorithm.
These parameters are usually less sensitive and can be left to their default value in most cases.
Ktr = tck.predict(mode='tr-tr')
Kte = tck.predict(Xte=Xte, mode='tr-te')
- If
mode='tr-tr', returns the similarity matrix between training samples, i.e.,Ktr[i,j]is the similarity between time seriesiandjin the training set. - If
mode='tr-te', it is necessary to pass the test setXteas additional imput. The returned similarity matrixKte[i,j]is the similarity between time seriesiin the test set and time seriesjin the training set.
Citation
Please, consider citing the original paper if you are using TCK in your reasearch.
@article{mikalsen2018time,
title={Time series cluster kernel for learning similarities between multivariate time series with missing data},
author={Mikalsen, Karl {\O}yvind and Bianchi, Filippo Maria and Soguero-Ruiz, Cristina and Jenssen, Robert},
journal={Pattern Recognition},
volume={76},
pages={569--581},
year={2018},
publisher={Elsevier}
}


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file tck-0.4.tar.gz.
File metadata
- Download URL: tck-0.4.tar.gz
- Upload date:
- Size: 11.4 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.0.0 CPython/3.10.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
21d1d1ed8c0d3407f406d9e94e2a4d93b50cf9f7d88a1ce4aab1c762d40afbe4
|
|
| MD5 |
770ca8f83e250f63eefbcaa4e4793277
|
|
| BLAKE2b-256 |
00582b34005a8dfc7a97085b00f0ff2f6b5ebab67c6ca1d5520ee9004597f012
|
File details
Details for the file tck-0.4-py3-none-any.whl.
File metadata
- Download URL: tck-0.4-py3-none-any.whl
- Upload date:
- Size: 10.5 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.0.0 CPython/3.10.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6fb6d571801fbce807985bbd2a76a276be8d3cf834c959f38894cbec82293953
|
|
| MD5 |
4bc1dedecf6f5b37f8154bf3f753963b
|
|
| BLAKE2b-256 |
f619d8650e8b2ac3429d907013234c619d0b42a2addf4e3d698f26a2afea7030
|







