Pure-Python GPU layout algebra for NVIDIA and AMD tensor core access patterns — no GPU required
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description





A pure-Python implementation of the NVIDIA CuTe layout algebra. No GPU required.
CuTe layouts describe how logical coordinates map to memory offsets on GPUs.
This library lets you construct, compose, and visualize those layouts using
plain Python — useful for understanding tensor core access patterns, debugging
swizzled shared memory, and prototyping tiled GPU kernels without compiling any
CUDA. The code in src/tensor_layouts/layouts.py is intentionally written to
be readable and pedagogical for people learning layout algebra.
The visualization layer is also designed to be pedagogical: for example,
hierarchical layout views can explicitly show nested row/column coordinates and
the resulting offset for each displayed cell.
Project Status
The core implementation is already in very good shape: the layout algebra, tensor semantics, analysis helpers, and visualization surface are correct, usable, and mature. Most of the remaining work is in documentation, examples, packaging, and repository polish rather than in redesigning the underlying model.
Installation
pip install tensor-layouts
For visualization support:
pip install tensor-layouts[viz]
Quick Start
from tensor_layouts import Layout, compose, complement, logical_divide
# A 4x8 column-major layout: offset(i,j) = i + j*4
layout = Layout((4, 8), (1, 4))
print(layout) # (4, 8) : (1, 4)
print(layout(2, 3)) # 14
# Compose two layouts
a = Layout((4, 2), (1, 4))
b = Layout((2, 4), (4, 1))
print(compose(a, b))
# Tile a layout into 2x4 blocks
tiler = Layout((2, 4))
print(logical_divide(layout, tiler))
Core Concepts
A Layout is a function from logical coordinates to memory offsets, defined by
(shape, stride):
| Layout | Description |
|---|---|
Layout((4, 8), (8, 1)) |
4x8 row-major |
Layout((4, 8), (1, 4)) |
4x8 column-major |
Layout(((2,4), 8), ((1,16), 2)) |
Hierarchical (tiled) |
The algebra provides four key operations:
compose(A, B)— Function composition: apply B's indexing to A's codomaincomplement(L)— The "missing half" of a layout's codomainlogical_divide(L, T)— Factor a layout into tiles of shape Tlogical_product(A, B)— Replicate A's pattern across B's domain
Plus Swizzle(B, M, S) for XOR-based bank conflict avoidance patterns.
MMA Atoms
The library includes matrix-multiply atom definitions for NVIDIA, AMD, Intel Xe, and Intel AMX targets. The Intel mappings were derived from public Intel ISA documentation; the Xe DPAS layouts were derived primarily from Intel's public DPAS/VISA instruction documentation and cross-checked against the CUTLASS experimental Xe backend.
NVIDIA Atoms
from tensor_layouts.atoms_nv import *
atom = SM90_64x64x16_F16F16F16_SS
print(atom.name) # SM90_64x64x16_F16F16F16_SS
print(atom.shape_mnk) # (64, 64, 16)
print(atom.c_layout) # Thread-value layout for C accumulator
Supported architectures: SM70 (Volta), SM75 (Turing), SM80 (Ampere), SM89 (Ada Lovelace), SM90 (Hopper GMMA), SM100 (Blackwell UMMA), SM120 (Blackwell B200).
AMD Atoms
from tensor_layouts.atoms_amd import *
atom = CDNA3_32x32x16_F32F8F8_MFMA
print(atom.name) # CDNA3_32x32x16_F32F8F8_MFMA
print(atom.shape_mnk) # (32, 32, 16)
print(atom.c_layout) # Thread-value layout for C accumulator
Supported architectures: CDNA1 (gfx908 / MI100), CDNA2 (gfx90a / MI200), CDNA3 (gfx942 / MI300), CDNA3+ (gfx950).
Intel Xe DPAS Atoms
from tensor_layouts.atoms_xe import *
atom = XeHPC_8x8x8_F32F16F16_DPAS
print(atom.name) # XeHPC_8x8x8_F32F16F16_DPAS
print(atom.shape_mnk) # (8, 8, 8)
print(atom.c_layout) # Thread-value layout for C accumulator
Supported targets: Xe-HPC (Ponte Vecchio / Data Center Max) and Xe-HPG (Arc / DG2) subgroup DPAS instructions.
Intel AMX Atoms
from tensor_layouts.atoms_amx import *
atom = AMX_16x16x32_F32BF16BF16F32
print(atom.name) # AMX_16x16x32_F32BF16BF16F32
print(atom.shape_mnk) # (16, 16, 32)
print(atom.c_layout) # Thread-value layout for C accumulator
Supported targets: Intel AMX tile matrix-multiply instructions
(tdpbf16ps, tdpfp16ps, tdpbssd, tdpbsud, tdpbusd, tdpbuud).
Visualization
With pip install tensor-layouts[viz]:
from tensor_layouts import Layout, Swizzle
from tensor_layouts.viz import draw_layout, draw_swizzle
draw_layout(Layout((8, 8), (8, 1)), title="Row-Major 8x8", colorize=True)
draw_swizzle(Layout((8, 8), (8, 1)), Swizzle(3, 0, 3), colorize=True)
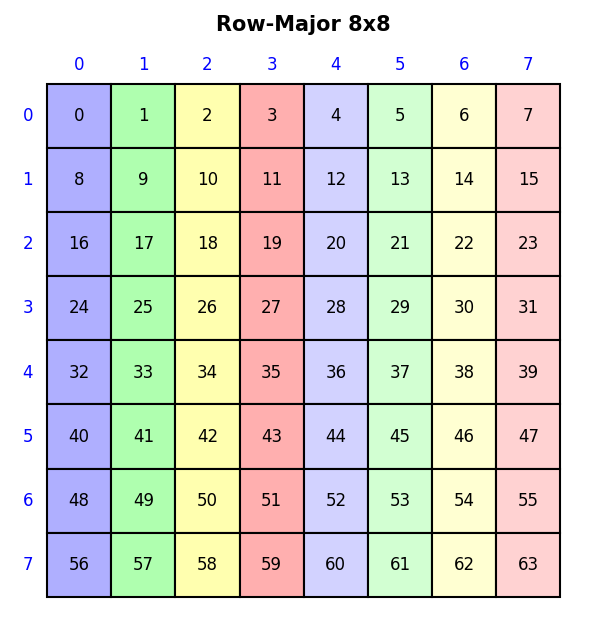
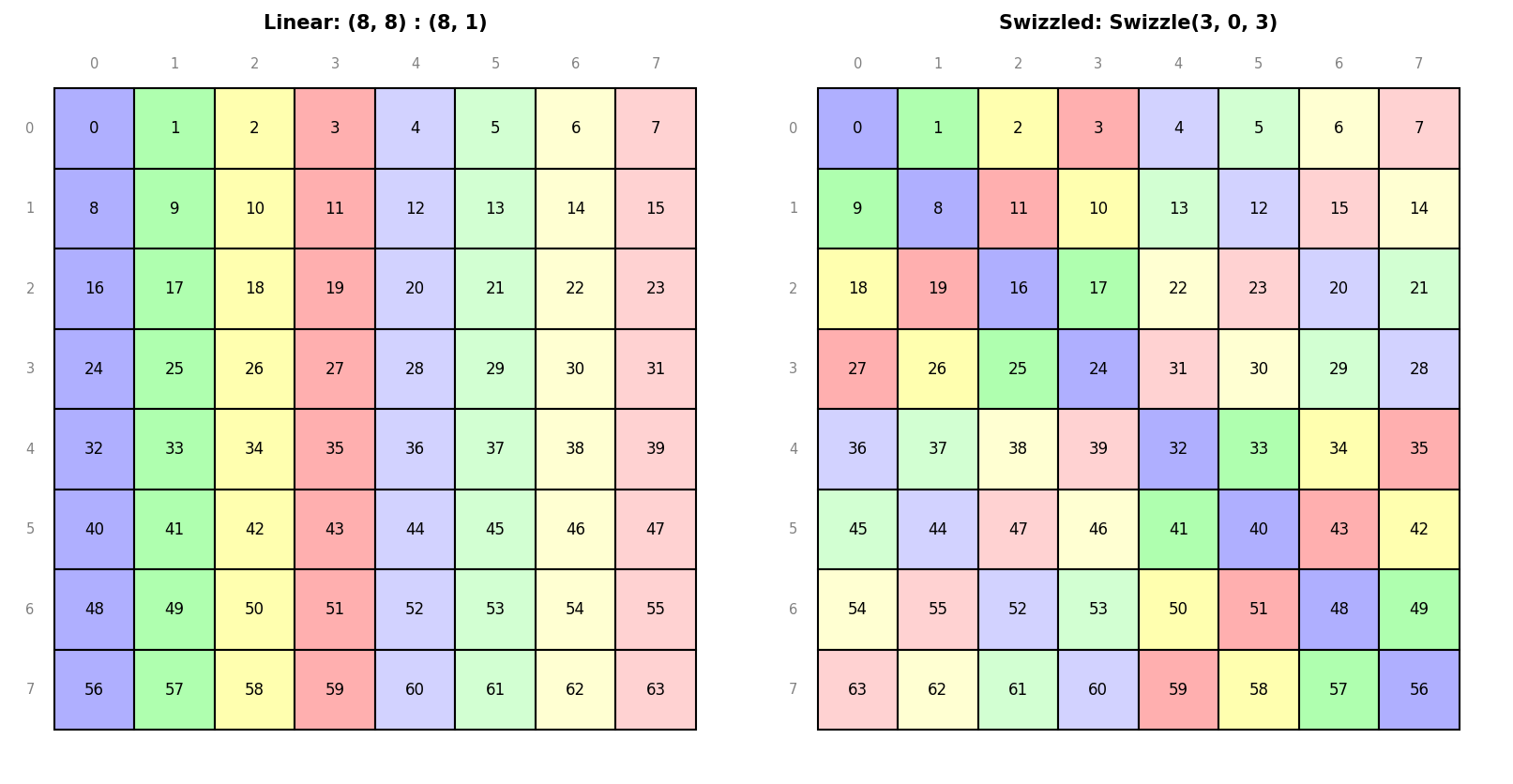
See examples/viz.ipynb for a full
gallery of layout, swizzle, MMA atom, and tiled MMA visualizations, and the
Notebook gallery below for the full set.
Documentation
- Example scripts assume
tensor-layoutsis installed. From a repo checkout, runpip install -e .first, orpip install -e ".[viz]"for visualization examples. - Layout Algebra API — construction, querying, compose, complement, divide, product
- Visualization API — draw_layout, draw_swizzle, draw_mma_layout, and more
- Layout Examples — runnable script covering the full algebra (
python3 examples/layouts.py) - Visualization Examples — runnable script generating all visualization types (
python3 examples/viz.py)
Notebook gallery
- Visualization Notebook —
viz.ipynb: layout, swizzle, MMA atom, and tiled MMA visualizations - Algorithms Notebook —
algorithms.ipynb: derivations of compose, complement, divide, product - Applications Notebook —
applications.ipynb: applied examples (paper-style) - GEMM Notebook —
gemm.ipynb: a fully explained NVIDIA GEMM kernel built up using layout algebra
Testing
pip install -e ".[test]"
pytest tests/
For local linting, install the dev extras and run Ruff on the Python sources:
pip install -e ".[dev]"
ruff check src/ tests/ examples/
The default Ruff configuration excludes *.ipynb; notebooks are treated as
worked material rather than part of the Python lint surface.
Oracle tests cross-validate against vendor reference implementations and are skipped automatically if the corresponding tool is unavailable:
# NVIDIA pycute oracle
pip install -e ".[test,oracle-nv]"
pytest tests/oracle_nv.py
# Direct CuTe C++ oracle
# Requires a C++ compiler plus CUTLASS/CUDA headers in the active environment.
pytest tests/oracle_cute_cpp.py
# AMD (cross-validation against amd_matrix_instruction_calculator)
pip install -e ".[test,oracle-amd]"
pytest tests/oracle_amd.py
References
- CuTe Layout Representation and Algebra — Cris Cecka
- Categorical Foundations for CuTe Layouts — Jack Carlisle, Jay Shah, Reuben Stern, Paul VanKoughnett
- CuTe Documentation
- NVIDIA PTX ISA
- NVIDIA Cutlass
- Cutlass MMA Atoms
- AMD Matrix Instruction Calculator
- AMD Matrix Cores Lab Notes
- Intel DPAS / VISA instruction specification
- Intel Architecture Instruction Set Extensions Programming Reference (AMX)
- Intel 64 and IA-32 Architectures Software Developer's Manual, Volume 2A
License
MIT License. See LICENSE for details.
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file tensor_layouts-0.3.2.tar.gz.
File metadata
- Download URL: tensor_layouts-0.3.2.tar.gz
- Upload date:
- Size: 133.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
73d6e452ffee33d1ccbec2714746e87bccb8b125b67f6c58fb3acf98b4542baf
|
|
| MD5 |
a1e01d0353d24daaaad0585110db1c3e
|
|
| BLAKE2b-256 |
b782b0a9cff14cf9003e1c241fc1d0bc5987f5f747d6ca28f1a5c2489f567717
|
Provenance
The following attestation bundles were made for tensor_layouts-0.3.2.tar.gz:
Publisher:
publish.yml on facebookresearch/tensor-layouts
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
tensor_layouts-0.3.2.tar.gz -
Subject digest:
73d6e452ffee33d1ccbec2714746e87bccb8b125b67f6c58fb3acf98b4542baf - Sigstore transparency entry: 1549555196
- Sigstore integration time:
-
Permalink:
facebookresearch/tensor-layouts@e732284db9d3b5dd89acfbc41339b0213830bd70 -
Branch / Tag:
refs/tags/v0.3.2 - Owner: https://github.com/facebookresearch
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@e732284db9d3b5dd89acfbc41339b0213830bd70 -
Trigger Event:
release
-
Statement type:
File details
Details for the file tensor_layouts-0.3.2-py3-none-any.whl.
File metadata
- Download URL: tensor_layouts-0.3.2-py3-none-any.whl
- Upload date:
- Size: 140.8 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
befda524188f97507b775cc4199bbb0cead20ff58aa07e2e9643188eb503d894
|
|
| MD5 |
307b6b2b9048dc7065d25e0cde860cf3
|
|
| BLAKE2b-256 |
8112455a47d9d522ca0e6be2cb70867bf081f16b05b0b2ba019fe9dd19ac5ec2
|
Provenance
The following attestation bundles were made for tensor_layouts-0.3.2-py3-none-any.whl:
Publisher:
publish.yml on facebookresearch/tensor-layouts
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
tensor_layouts-0.3.2-py3-none-any.whl -
Subject digest:
befda524188f97507b775cc4199bbb0cead20ff58aa07e2e9643188eb503d894 - Sigstore transparency entry: 1549555235
- Sigstore integration time:
-
Permalink:
facebookresearch/tensor-layouts@e732284db9d3b5dd89acfbc41339b0213830bd70 -
Branch / Tag:
refs/tags/v0.3.2 - Owner: https://github.com/facebookresearch
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@e732284db9d3b5dd89acfbc41339b0213830bd70 -
Trigger Event:
release
-
Statement type:







