Reflect on how you actually use AI coding agents. Reads your local Claude Code, Codex, and Gemini CLI traces, builds rich per-session narratives, and synthesizes cross-session patterns you can act on this week — with an interactive HTML dashboard.

Project description
tessera
Reflect on how you actually use AI coding agents.
Reads your local Claude Code, Codex, and Gemini CLI session traces, builds rich per-session narratives, then synthesizes cross-session patterns you can act on this week — surfaced as an interactive HTML dashboard you open in any browser. No API key, no server, no telemetry.
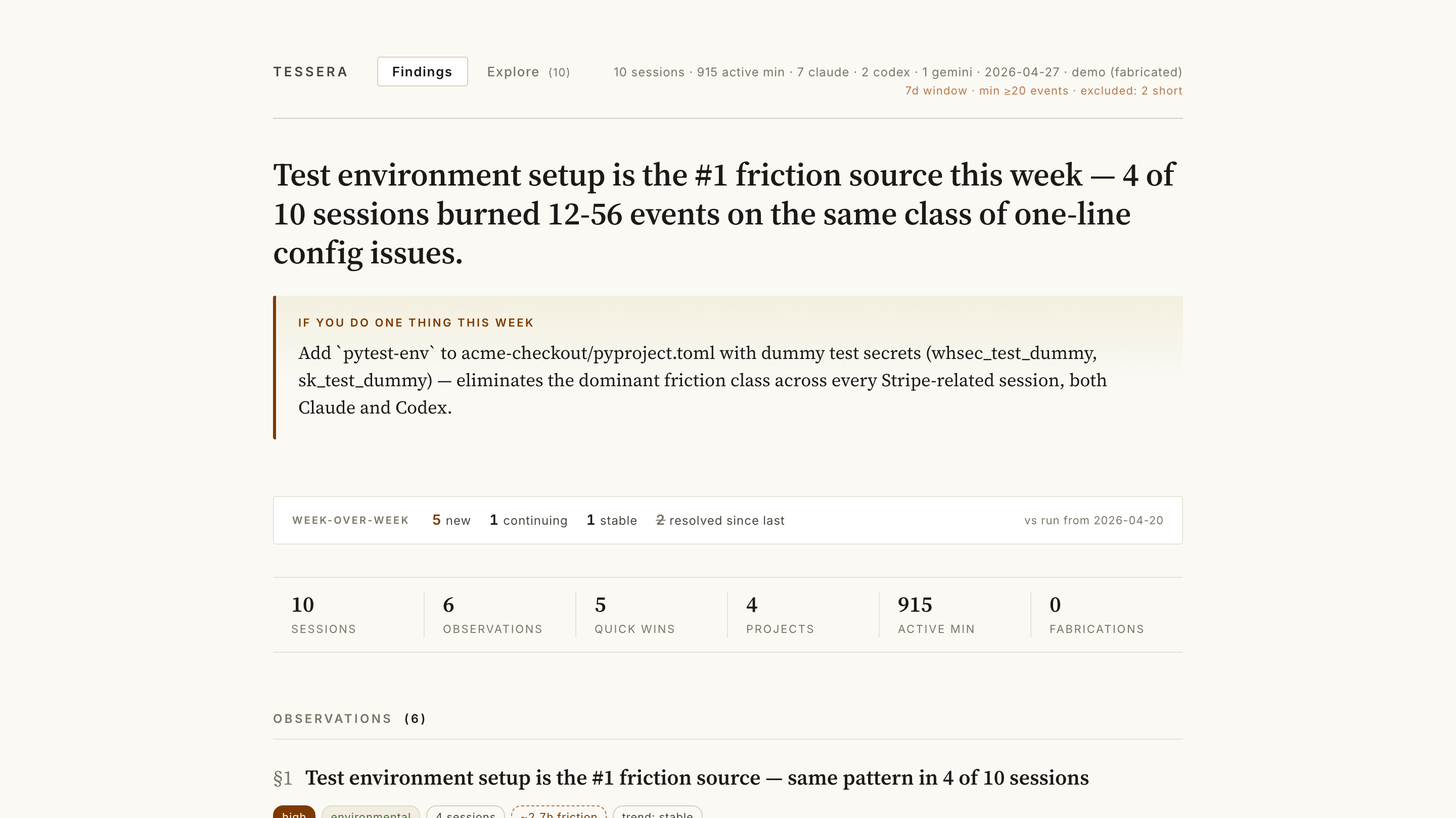
🔍 Live demo → (fictional data, click around to see what tessera produces — no install needed)
Adding another agent CLI is one parser function; the narrative + synthesis layers are agent-agnostic.
What you actually get
Run one command, open one HTML file. Two views:
Findings — the cross-session synthesis:
Headline: 40+ atella sessions each rediscover python=.venv/bin/python, git-root≠stella-backend/, PYTHONPATH=src — a single CLAUDE.md would eliminate 200+ wasted events/week
If you do one thing this week:
printf '...' >> stella-backend/pyproject.tomlAND createstella-backend/CLAUDE.md: …§3 Missing git fetch before PR diff inflates scope 5-10x high · workflow · 8 sessions · ~46m friction · trend: stable In 6 sessions, diffing a PR against local main without first fetching showed 35-69 files instead of 6-14. Fix: prepend
git fetch origin main &&to the array-pr-review skill.Week-over-week: 4 new · 2 continuing · 1 worsening · 3 resolved since last
Plus quick wins (one-line fixes you can copy with a button), per-project drilldowns, and inline [u]/[w]/[k]/[s] rating buttons that feed the next run's prompt.
Explore — browse all the data:
- Sessions table (sortable, filterable by agent / project / waste signature, click to drill into the full per-session narrative — tasks, friction with quotes, key decisions with retrospectives, dead ends, env issues, deterministic stats)
- All recurring environmental issues across all sessions, sorted by occurrence count
- All counterfactuals + lessons in three columns
- Per-project deep view
Every cited session is verifiable — citations use 4-char ref tokens (S001–S{n}) that map deterministically back to real session_ids. Fabrication rate by design: 0%.
The output is also written as synthesis.json (raw) and synthesis.md (shareable markdown).
How it works
~/.claude/projects/ ─┐
~/.codex/sessions/ ─┤ [1] normalize [2] per-session [3] cross-session [4] dashboard
~/.gemini/tmp/ ─┴──▶ symlink into temp ─▶ narrative (1 LLM call ─▶ synthesis (1 LLM call ─▶ synthesis.html
no copies, no per session, cached by on all narratives, (Findings + Explore,
source mods) content hash) ref-token citations) inline rating)
Two LLM stages, both via your local claude CLI:
- Per-session narrative — each session's compressed event stream (~30-50K tokens) gets one Sonnet 4.6 call producing structured narrative (goal, tasks, friction moments, key decisions, dead ends, recurring env issues, counterfactual). Cached by content hash; re-runs skip unchanged sessions.
- Cross-session synthesis — all narratives compacted to high-signal fields (~150K tokens), one Sonnet 4.6 call producing observations + quick wins + per-project headlines. Validator drops any cited ref not in the input set.
See docs/schema/v1.md for the full per-session schema and docs/ARCHITECTURE.md for module-level flow.
Install
Requires Python 3.11+ and an authenticated claude CLI (version 2+). No ANTHROPIC_API_KEY — token usage routes through your existing Claude Code auth.
pip install tessera-agents
# or
uv tool install tessera-agents
The PyPI package is
tessera-agents(the bare nametesserawas taken). The CLI binary, slash command, and import are all justtessera.
Use
Weekly retrospective (the main flow)
tessera run # last 30 days, ~5min cached / ~50min cold
open synthesis.html # read findings, drill in, rate inline
After rating: click the floating SAVE button on the dashboard, paste the resulting one-liner in your terminal. Ratings feed the next run's synthesis prompt and the in-session coach (see below).
tessera run --all-time # full history, no time filter
tessera run --lookback-days 60 # custom window
tessera run --min-events 5 # include shorter sessions (default 20)
In-session real-time nudges (sibling tool)
The tessera-live plugin watches your live sessions for known waste patterns (browser spirals, blind retries, runaway call rates, etc.) and nudges Claude with a short note when one appears. Silent on the happy path. Reads your dashboard ratings to enrich nudges with your validated playbook.
Power-user subcommands
tessera narrate # per-session extraction only (no synthesis)
tessera synthesize # synthesis only (reads existing narratives)
tessera synthesize --project atella # filter to one project
tessera dashboard # re-render the HTML from existing synthesis + narratives
tessera rate # interactive CLI rating (alternative to inline)
tessera rate-import < ratings.json # apply ratings from dashboard
tessera eval # quality metrics (fabrication rate, etc.)
Slash command (inside Claude Code)
/tessera # 30-day window
/tessera 60 # 60-day window
/tessera all-time # everything
Common options
--lookback-days N Window in days. Default 30. Use --all-time for no cap.
--min-events N Skip sessions with fewer events. Default 20.
--limit N Cap to N most-recent sessions. 0 = no limit.
--model NAME Claude model. Default claude-sonnet-4-6.
--concurrency N Per-session extraction concurrency. Default 10.
--force Bypass narrative cache (still writes).
--output PATH Where to write synthesis JSON. Default ./synthesis.json.
--narratives-dir DIR Per-session JSON output dir. Default ./narratives.
--format text|json|markdown Terminal output format. Default text.
--no-history Don't read or save to history.
--prior-runs N How many prior runs to feed back as context. Default 3.
--claude-projects DIR Override Claude Code projects dir.
--codex-sessions DIR Override Codex sessions dir.
--gemini-tmp DIR Override Gemini CLI tmp dir.
Cost
| Scenario | Sessions | Cost (Sonnet 4.6) | Wall clock |
|---|---|---|---|
| Weekly run, cache hits | 50-100 | ~$1-3 | 5-10 min |
| Cold run on a new machine | 50-100 | ~$5-12 | 30-50 min |
| Full historical backfill | 1000-2000 | ~$15-30 (one-time) | 4-6 hours |
| Re-synthesis only (no narrate) | any | ~$0.50 | 5-15 min |
All token usage routes through your claude CLI auth — no separate billing.
What it doesn't do
- Doesn't run continuously. Call it when you want a reflection.
- Doesn't score your work. No leaderboard, no "healthy %."
- Doesn't hallucinate evidence. Every cited ref maps to a real session; fabricated refs are dropped with a visible count in the dashboard's "Fabrications" stat.
- Doesn't classify with keywords. Task types and waste signatures come from LLM judgment grounded in event evidence, validated against a closed vocabulary.
- Doesn't send your data anywhere. Local read of trace files; LLM calls go through your existing auth; output stays on disk.
Privacy
Everything runs locally. Trace files are read from ~/.claude/projects/, ~/.codex/sessions/, and ~/.gemini/tmp/ (or wherever you've configured those agents). The two LLM calls (per-session narrative + cross-session synthesis) route through your existing authenticated claude CLI — no separate API key, no telemetry, no analytics. Cached narratives, synthesis output, and run history live under ~/.cache/tessera/ and ~/.config/tessera/.
The dashboard quotes verbatim text from your sessions — friction moments, error messages, decision rationale. Review before sharing screenshots or synthesis.md — they may contain code snippets, file paths, secrets you typed into prompts, or other content from your sessions.
Repo layout
tessera/
├── .claude-plugin/plugin.json # Claude Code plugin manifest
├── commands/tessera.md # /tessera slash command
├── docs/
│ ├── schema/v1.md # per-session narrative schema spec
│ └── ARCHITECTURE.md # module-level pipeline overview
├── pyproject.toml # publishes tessera to PyPI
├── src/tessera/
│ ├── cli.py # `tessera <command>` entry points
│ ├── pipeline.py # symlink-based normalize orchestrator
│ ├── _normalize_script.py # cross-agent event schema normalizer
│ ├── history.py # ratings + prior-run context store
│ ├── narratives/
│ │ ├── deterministic.py # event-stream metadata extraction
│ │ ├── compressor.py # event stream → compact narrative
│ │ ├── extractor.py # per-session LLM call
│ │ ├── validator.py # schema validation rules
│ │ ├── cache.py # per-session content-hash cache
│ │ ├── pipeline.py # per-session orchestrator
│ │ ├── synthesis.py # cross-session LLM call + ref-citation validator
│ │ ├── render.py # text + markdown renderers
│ │ ├── dashboard.py # interactive HTML dashboard
│ │ └── eval.py # quality metrics
│ └── coach/ # in-session hook (separate plugin: ../tessera-live/)
├── tests/ # pytest
├── CONTRIBUTING.md
├── LICENSE # MIT
└── README.md
One repo, three distribution paths. The Claude Code plugin and the pip package share the same source.
Contributing
See CONTRIBUTING.md. The most useful PR is probably a parser for a new agent CLI — drop a normalize_<agent>() function into _normalize_script.py matching the existing event schema, and the entire downstream pipeline (narratives, synthesis, dashboard) works on it for free.
License
MIT — see LICENSE.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file tessera_agents-0.4.1.tar.gz.
File metadata
- Download URL: tessera_agents-0.4.1.tar.gz
- Upload date:
- Size: 190.2 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.14.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
95c481ef302e3189595ca7f9682c4e602b4075491a69dd932a4677562c74f032
|
|
| MD5 |
c12dc8c70fa5161a0608be3574bccc10
|
|
| BLAKE2b-256 |
7210368e174f03997dc333555f56ee18eff939b004b1f9f26780a221261fbd9f
|
File details
Details for the file tessera_agents-0.4.1-py3-none-any.whl.
File metadata
- Download URL: tessera_agents-0.4.1-py3-none-any.whl
- Upload date:
- Size: 137.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.14.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
428cc67ee7154a1fda6c7fb745d446df3fd9f43d370749dafc0bf21bfac75365
|
|
| MD5 |
5963bd79be5ef21dfcd258bc666b668b
|
|
| BLAKE2b-256 |
352dd0e484491a1ae34b9602c9e882b466d60285f8306577399365ba4dee4d52
|







