A package for text denoising : UL2

Project description
Masking implementation for Unifying Language Learning Paradigms (UL2)
Want to get better model with limited budgets? You are in the right place
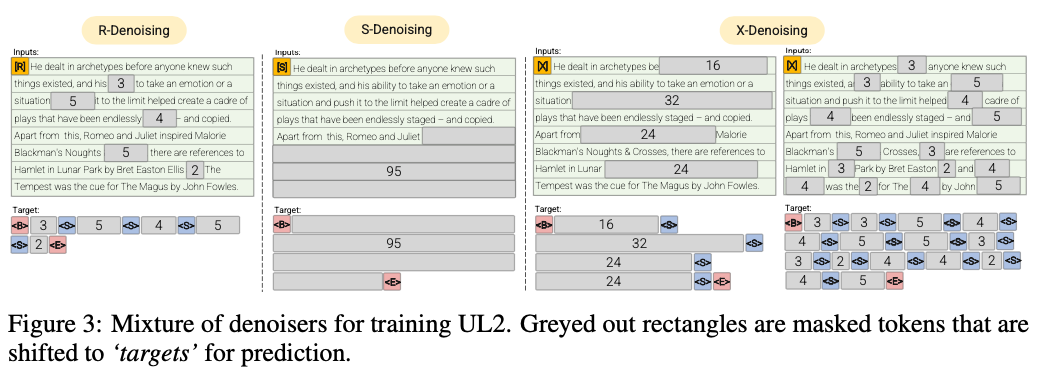
-
R-Denoiser (μ=3,r=0.15,n)∪ (μ=8,r=0.15,n)
The regular denoising is the standard span corruption introduced in Raffel et al. (2019) that uses a range of 2 to 5 tokens as the span length, which masks about 15% of input tokens
-
S-Denoiser (μ=L/4,r=0.25,1)
A specific case of denoising where we observe a strict sequential order when framing the inputs-to-targets task, i.e., prefix language modeling
-
X-Denoiser (μ = 3,r = 0.5,n)∪(μ = 8,r = 0.5,n)∪(μ = 64,r =0.15,n)∪ (μ=64,r=0.5,n)
An extreme version of denoising where the model must recover a large part of the input, given a small to moderate part of it. This simulates a situation where a model needs to generate long target from a memory with relatively limited information. To do so, we opt to include examples with aggressive denoising where approximately 50% of the input sequence is masked
2022 papers : Transcending Scaling Laws with 0.1% Extra Compute
we show an approximately 2x computational savings rate
-
Regular denoising whereby the noise is sampled as spans, replaced with sentinel tokens. This is also the standard span corruption task used in Raffel et al. (2019). Spans are typically uniformly sampled with a mean of 3 and a corruption rate of 15%.
-
Extreme denoising whereby the noise is increased to relatively ‘extreme‘ amounts in either a huge percentage of the original text or being very long in nature. Spans are typically uniformly sampled with a mean length of 32 OR a corruption rate of up to 50%.
-
Sequential denoising whereby the noise is always sampled from the start of the text to a randomly sampled point in the text. This is also known as the PrefixLM objective (not to be confused with the architecture).
This repo will just aim for accompolish this task instead, UL2 is way too complicated for my likings
50% PrefixLM, 25% Long (extreme) span corruption, and 25% regular span corruption to be quite simple and efficient
Experiments
Run a mT5 encoder pretraining on 3090 on pythia json.zst files
python pretrain_example.py
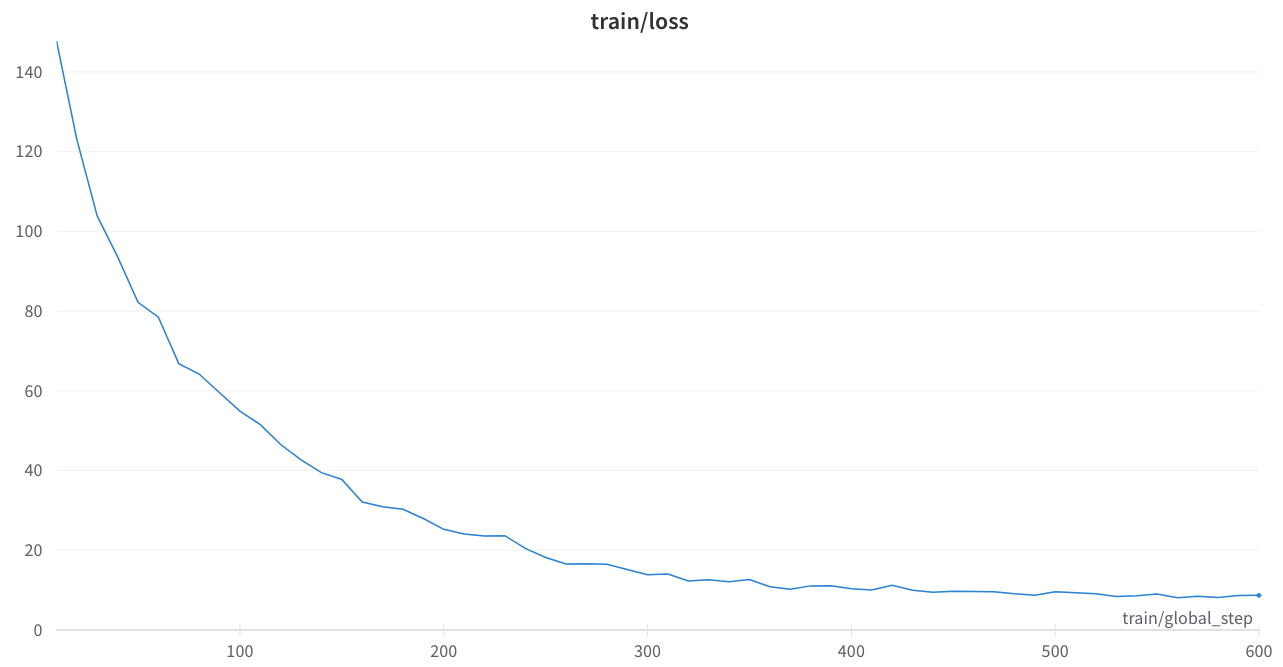
training loss was stable and no weird spikes
References
Core Papers
Transcending Scaling Laws with 0.1% Extra Compute
Unifying Language Learning Paradigms
Implements of t5 noise masking in huggingface transformers or python code
OSLO : very underrated, some tidy and documentation, this will be a very useful tool
-
Heavily inspired from this section
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file text-denoising-0.1.1.tar.gz.
File metadata
- Download URL: text-denoising-0.1.1.tar.gz
- Upload date:
- Size: 8.7 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.8.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
14a587b701d624a9b59e87b3a4534d419694bded85297b6a9ffa9772f5a80164
|
|
| MD5 |
2ce4b2304c06a5c703c65f58d007c716
|
|
| BLAKE2b-256 |
0faf07b22c85402c62c3824d48852b56e95b2de836e852b75bcf16298a032daa
|
File details
Details for the file text_denoising-0.1.1-py3-none-any.whl.
File metadata
- Download URL: text_denoising-0.1.1-py3-none-any.whl
- Upload date:
- Size: 7.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.8.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
62e4f1322ec6b2d94703f9b67d0d33e7814312503f6099f7f3953dd9900f3be2
|
|
| MD5 |
9e10dc08087277a7618fdb7fc26fa015
|
|
| BLAKE2b-256 |
cc82a19f630003111bcc6764fec64e692fd1e34153b261d4de18318472a46041
|







