A Python Module for Comprehensive Text Mining, including Keyword Extraction and Text Analysis.

Project description
Text Mining Module Library
Overview
The textmining_module is a comprehensive Python library designed to
facilitate text mining, keyword extraction, and text analysis tasks. It
provides a suite of tools for preprocessing textual data, extracting
meaningful insights, and transforming texts into formats suitable for
various analysis and machine learning models.
Features
- Text Preprocessing: Simplify the preparation of text data with functions for cleaning, normalizing, and preprocessing textual content.
- Keyword Extraction: Utilize built-in functionalities to extract significant keywords and phrases from large volumes of text.
- Text Analysis: Leverage tools to analyze and understand the content, structure, and composition of your text data.
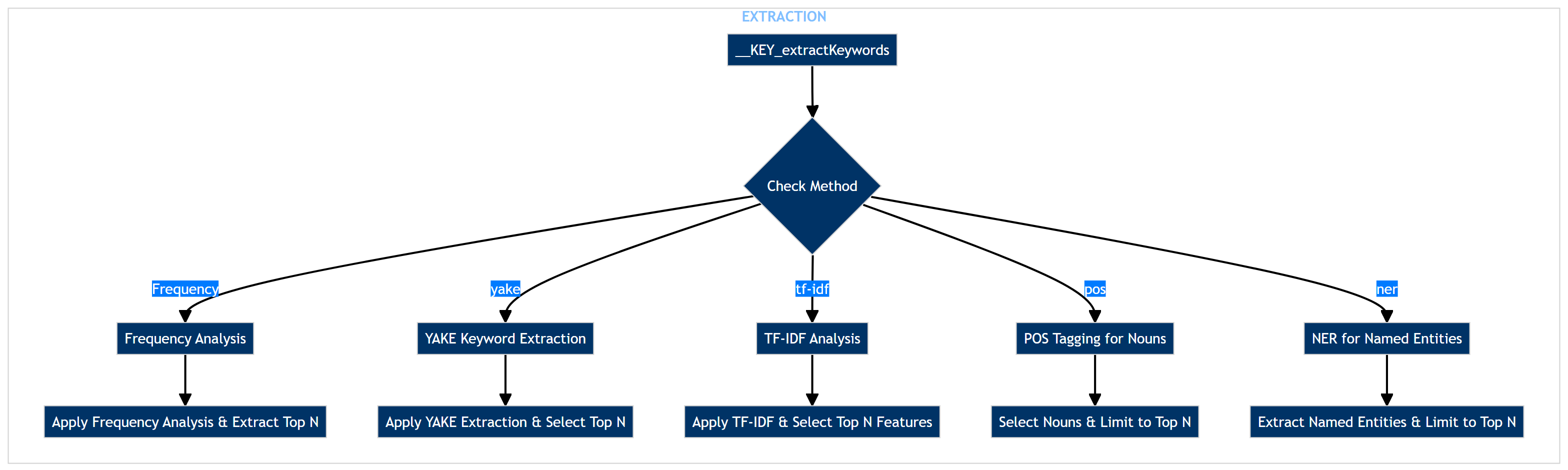
Developer Manual for KeywordsExtractor
Functions Map
User Manual
Installation
This is the environment we need to load.
pip install textmining_module==2.1.2
Load Package
from textmining_module import KeywordsExtractor
Base Operations
Extract Keywords From Dataset
keywords_df = KeywordsExtractor(data,
text_column= 'text_column',
method= 'yake',
n=3,
stopword_language= 'english')
The KeywordsExtractor extracts keywords from textual data within a
pandas DataFrame. Here's a detailed look at each of its arguments:
data: ThepandasDataFrame containing thetext datafrom which you want to extract keywords. This DataFrame should have at least onetext_columnspecified by the text_column argument.text_column: (str) The name of the column within the data DataFrame that contains the textual data for keyword extraction.method: (str) Specifies the method to be used for keyword extraction. The function supports the following methods:frequency: Extracts keywords based on word frequency, excluding common stopwords.yake: Utilizes YAKE (Yet Another Keyword Extractor), an unsupervised method that considers word frequency and position.- -tf-idf: Employs Term Frequency-Inverse Document Frequency, highlighting words that are particularly indicative of the text's content.pos: Focuses on part-of-speech tagging, typically selecting nouns as keywords.ner: Uses Named Entity Recognition to identify and extract entities (e.g., people, organizations) as keywords.
n: (int) The number of keywords to extract from each piece of text.stopwords_language: (str) Indicates the language of the stopwords to be used for filtering during the keyword extraction process. This is relevant for methods that remove common words to focus on more meaningful content.
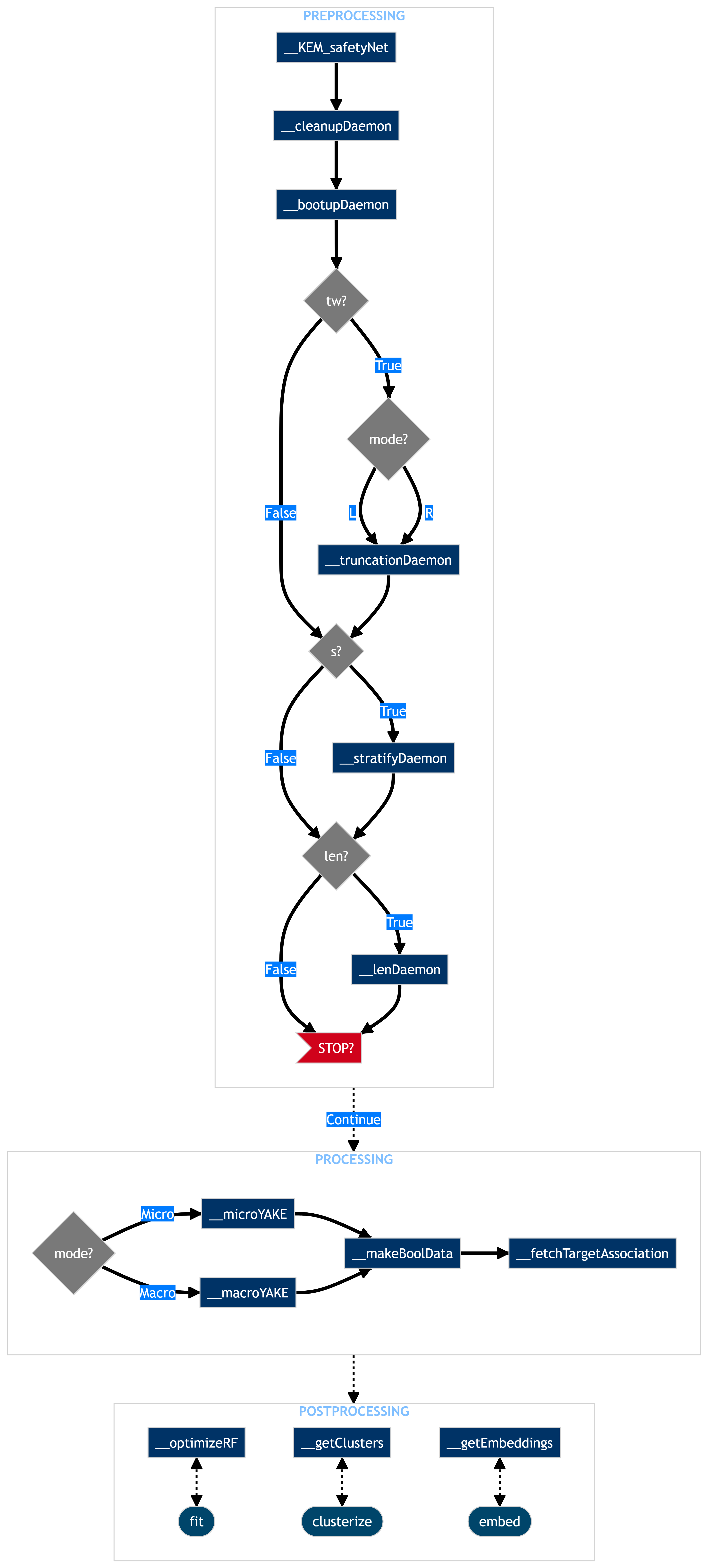
Developer Manual for TextMiner
Functions Map
User Manual
Installation
This is the environment we need to load.
pip install textmining_module==2.1.2
Load Package
from textmining_module import TextMiner
Base Operations
Prepare Text Dataset
Cleaner = TextMiner(data, comment_variable='Text_column', target_variable='Target_column',
truncation_words=None, truncation_mode='right',
preprocessing_only=True, verbose=True)
data['Cleaned_text_column'] = Cleaner.reqCleanedData()['Text_column']
Text_column may have translations at the end that we want to remove.
We can use TextMiner to obtain [preprocessed]{.coop_blue} messages
that are [right truncated]{.coop_blue} after some stop words we
identified.
- Required 1st argument : (
pandasdataframe) of dataset; comment_variable: (str) name of the comment variable inpandasdataframe;target_variable : (str) name of the target variable inpandasdataframe;truncation_words: (str list) words where a split occur to truncate a message to the left/right - i.e. if french copy before/after an english message;truncation_mode : (str) {'right' : remove rhs of message at truncation_word, 'left' : remove lhs of message at truncation_word};preprocessing_only : (bool) if True, only clean (opt.), format, stratify (opt.) and truncate (opt.) given dataset;verbose: (bool) if True, show a progress bar.
Fetch Association
Let's review how to use TextMiner to fetch [processed]{.coop_blue}
keywords that are associated with ratings. The most challenging part of
most unsupervised algorithms is to find the correct hyperparameters. For
TextMiner, pay attention to fpg_min_support, n and top. Keyword
extraction may fail with an exponentially growing time complexity if too
many n-grams are fetched at a low support. A low fpg_min_support means
that we tolerate keywords that appear in a low number of observations. A
low n with a high top will lead to grams that are more likely to be
common to many messages, hence increasing time complexity as there would
be too many permutations to check. A high n with a low top, on the
other hand, will lead to grams that are too specific.
strata_variable: (str) name of the strata variable inpandasdataframe, for a stratified analysis - i.e. break down by LoB;req_len_complexity: (bool) if True, include message length quartiles in analysis as a new qualitative attribute;removeOutersection : (bool) if True, exclude keywords that contain other fetched keywords;search_mode: (str) {'macro' : (for each strata) concatenate all rows in one chunk before extracting keywords, 'micro' : extract keywords row-wise}n: (int) maximal number of grams (words excludingstop_words) that can form akeyword;top : (int) how many n-grams to fetch;stop_words: (str list) words to disregard in generation of n-grams;fpg_min_support: (float) minimal support for FP Growth - try higher value if FPG takes too long;keep_strongest_association: (bool) filter One Hot Data to keep highest supported bits before fetching association.
path_to_stopwords = "./stop_keywords.txt" # optional
stopwords = open(path_to_stopwords, 'r').read().split('\n')
text_modeling = TextMiner(data,
comment_variable='Cleaned_text_column', target_variable='Target_column',
strata_variable='LoB_column', keywords_variable=None, clean_words=None, # data
search_mode='micro', n=3, top=1, stop_words=None, truncation_words=None, truncation_mode='right', # YAKE
fpg_min_support=1E-3, keep_strongest_association=False, removeOutersection=False, # FPG
req_len_complexity=False, req_importance_score=False, # Random Forest
verbose=True, preprocessing_only=False) # class use
We can view the keywords that are associated to each pair (strata -
specific category, target - specific category). TextMiner allows some
rare keywords (may happen) that have low support but high confidence
score.
text_modeling.reqKeywordsByTarget()['LoB_column_category']['Target_column_category']
We can also request the best target for each keyword based on support only.
text_modeling.bestbucket_by_s['LoB_column_category']
We can also request the strata of the data.
text_modeling.reqUniqueStratas()
We can also request the targets of the data.
text_modeling.reqUniqueTargets()
We can also request the keywords extracted from the data per strata
text_modeling.reqYAKEKeywords()['LoB_column_category']
Micro vs Macro
Our text_modeling object fetched keywords with micro search,
could've been macro search instead. In both cases, the objective is to
build a list of unique keywords and show every keywords from that list
that are found in each and every given comment. Let's now review the key
differences.
microfetchestopkeywords (n-grams) row-by-row and adds columnkeywords_yaketo internally managed data.- faster for smaller data
- better to fetch unique keywords in indiviudal messages within smaller stratas;
- tends to make clusters of high variability in size, but mostly considers minority data;
- needs lower 'top' argument as it is per message (<= 2).
path_to_stopwords = "./stop_keywords.txt" # optional
stopwords = open(path_to_stopwords, 'r').read().split('\n')
text_modeling_micro = TextMiner(data,
comment_variable='Cleaned_text_column', target_variable='Target_column',
strata_variable='LoB_column', keywords_variable=None, clean_words=None, # data
search_mode='micro', n=3, top=1, stop_words=None, truncation_words=None, truncation_mode='right', # YAKE
fpg_min_support=1E-3, keep_strongest_association=False, removeOutersection=False, # FPG
req_len_complexity=False, req_importance_score=True) # Random Forest
OR
path_to_stopwords = "./stop_keywords.txt" # optional
stopwords = open(path_to_stopwords, 'r').read().split('\n')
text_modeling_micro = TextMiner(data,
comment_variable='Cleaned_text_column', target_variable='Target_column',
strata_variable='LoB_column', keywords_variable=None, clean_words=None, # data
search_mode='micro', n=3, top=1, stop_words=stopwords, fpg_min_support=1E-3,
keep_strongest_association=False, removeOutersection=False) # no filter
macrofetches and creates internally managed macro-keywords (stratified) dataframe(s). Uses text chunks for operations.- faster for bigger data;
- better to fetch keywords typically common for every messages within large stratas;
- tends to make clusters of same size but ignores minority data;
- needs higher 'top' argument as it is for all messages (>= 15);
- filters are recommended (have critical thinking).
path_to_stopwords = "./stop_keywords.txt" # optional
stopwords = open(path_to_stopwords, 'r').read().split('\n')
text_modeling_macro = TextMiner(data,
comment_variable='Cleaned_text_column', target_variable='Target_column',
strata_variable='LoB_column', keywords_variable=None, clean_words=None, # data
search_mode='macro', n=3, top=1, stop_words=None, truncation_words=None, truncation_mode='right', # YAKE
fpg_min_support=1E-3, keep_strongest_association=False, removeOutersection=False, # FPG
req_len_complexity=False, req_importance_score=True) # Random Forest
OR
path_to_stopwords = "./stop_keywords.txt" # optional
stopwords = open(path_to_stopwords, 'r').read().split('\n')
text_modeling_macro = TextMiner(data,
comment_variable='Cleaned_text_column', target_variable='Target_column',
strata_variable='LoB_column', keywords_variable=None, clean_words=None, # data
search_mode='macro', n=3, top=1, stop_words=stopwords, fpg_min_support=1E-3,
keep_strongest_association=False, removeOutersection=False) # no filter
Advanced Operations
Similarity Matrix
TextMiner objects can compute a matrix where each element represents
the similarity score between a pair of documents, texts or keywords. It
uses the Jaccard similarity measure, calculating the intersection over
the union of the sets of words (or other tokens) for each pair.
text_modeling_similarity = TextMiner(data,
comment_variable='Cleaned_text_column', target_variable='Target_column',
strata_variable='LoB_column', keywords_variable=None, clean_words=None, # data
search_mode='micro', n=3, top=1, stop_words=None, fpg_min_support=1E-3,
keep_strongest_association=False, removeOutersection=False) # no filter
text_modeling_similarity.reqSimilarityMatrix()
We can also view the similarity matrix by a (strata - specific category).
text_modeling_similarity.reqSimilarityMatrix()['LoB_column_category']
Clusterize
TextMiner objects can cluster given data set using the fetched
keywords with the command clusterize. By default, it returns clusters
row- and column-wise. The treshold is the distance tolerance (in (0,
1]) that is accepted to merge clusters.
text_modeling_cluster = = TextMiner(data,
comment_variable='Cleaned_text_column', target_variable='Target_column',
strata_variable='LoB_column', keywords_variable=None, clean_words=None, # data
search_mode='micro', n=3, top=1, stop_words=None, fpg_min_support=1E-3,
keep_strongest_association=False, removeOutersection=False) # no filter
cluster_observations, cluster_keywords = text_modeling_cluster.clusterize(treshold=0.9)
When clusterize is used, it adds to the internally managed data the
row-wise clusters.
text_modeling_cluster.reqCleanedData()
Be Careful
Comments used for unsupervised clustering doesn't always have the needed keywords to fetch meaningful clusters - meaningful as they don't require a rigorous manual verification.
Weighted Balanced Random Forest
TextMiner objects can fit a Weighted Balanced Random Forest (WBRF)
given data set using the fetched keywords with the command fit. By
default, it uses a train-val-test split with randomized hyperparameters
search on a K-Fold validation process.
req_importance_score: (bool) find importance score for all bags of relevant keywords (atTextMinerobject initialization, seetext_modeling_clusteratclusterize);k_neighbors: (int) fine-tune the balance between classes;train_ratio: (float) ratio in (0, 1) for train data in train-test-split;n_fold: (int) number of folds in K-Fold hyperparameter tuning;n_round: (int) number of rounds (new hyperparameter candidates) for K-Fold hyperparamters tuning;optim_metric: (str) skl target metric for RandomizedSearchCV.
text_modeling = TextMiner(data,
comment_variable='Cleaned_text_column', target_variable='Target_column',
strata_variable='LoB_column', keywords_variable=None, clean_words=None, # data
search_mode='macro', n=3, top=1, stop_words=None, truncation_words=None, truncation_mode='right', # YAKE
fpg_min_support=1E-3, keep_strongest_association=False, removeOutersection=False, # FPG
req_len_complexity=False, req_importance_score=True) # Random Forest
model = text_modeling.fit(k_neighbors=3, n_round=5, n_fold=3, train_ratio=0.6, optim_metric='accuracy', n_jobs=1, skl_verbose=0, verbose=False)
This is important for scoring
Make sure
req_importance_score=True in theTextMiner.
With the above, we can now find the best set of hyperparameters :
text_modeling.best_hp_by_s
That leads to these performance in training :
text_modeling.train_cm_by_s
text_modeling.train_metrics_by_s
for s in text_modeling.reqUniqueStratas():
print(f'Strata : {s} \n')
print(text_modeling.train_cm_by_s[s])
print(text_modeling.train_metrics_by_s[s]) # for each strata
And leads to these performance in test :
text_modeling.test_cm_by_s
text_modeling.test_metrics_by_s
for s in text_modeling.reqUniqueStratas():
print(f'Strata : {s} \n')
print(text_modeling.test_cm_by_s[s])
print(text_modeling.test_metrics_by_s[s]) # for each strata
We can dig deeper by looking at the importance scores (that we required).
Mean Decrease in Impurity (MDI) : After the model is trained, you
can access the MDI scores to understand which features had the most
substantial impact on the model's decisions. This insight is
particularly useful for feature selection, understanding the data, and
interpreting the model's behavior, allowing you to make informed
decisions about which features to keep, discard, or further investigate.
We can view by No Strata (Remember to set strata_variable = 'None' in TextMiner then fit the model)
mdi_importances_df = pd.DataFrame(text_modeling.mdi_importances.items(), columns=['Feature', 'Importance'])
We can view by Strata (Remember to set strata_variable = 'LoB_column' in TextMiner then fit the model)
results_df = pd.DataFrame()
for s in text_modeling.reqUniqueStratas():
temp_df = pd.DataFrame(list(text_modeling.mdi_importances_by_s[s].items()), columns=['Keyword', f'{s}_Importance'])
if results_df.empty:
results_df = temp_df
else:
results_df = pd.merge(results_df, temp_df, on='Keyword', how='outer')
results_df
Permutation : Unlike MDI (Mean Decrease in Impurity), which is
specific to tree-based models, permutation importance can be applied to
any model. It measures the increase in the model's prediction after
permuting the feature's values, which breaks the relationship between
the feature and the true outcome.
We can view by No Strata (Remember to set strata_variable = 'None' in TextMiner then fit the model)
perm_importances_df = pd.DataFrame(text_modeling.perm_importances.items(), columns=['Feature', 'Importance'])
We can view by Strata (Remember to set strata_variable = 'LoB_column' in TextMiner then fit the model)
results_df = pd.DataFrame()
for s in text_modeling.reqUniqueStratas():
temp_df = pd.DataFrame(list(text_modeling.perm_importances_by_s[s].items()), columns=['Keyword', f'{s}_Importance'])
if results_df.empty:
results_df = temp_df
else:
results_df = pd.merge(results_df, temp_df, on='Keyword', how='outer')
results_df
We see that permutations score is much more 'aggressive' as it leads to smaller importances scores. A score close to 0 happens when a keyword's presence doesn't improve accuracy. A negative score happens when a keyword's presence decreases impurity i.e. a feature that should be masked.
We can interpret both importance scores at once, for a bad of keywords
found in a given comment. Let $m_k$ be the MDI score and $p_k$ be the
permutations score for keyword $k \in K$, where $K$ is a set of keywords
found in a comment. TextMiner computes the Harmonic Importance as
$$ h := \frac{1}{(\sum_K \text{ReLU}(m_k))^{-1} + (\sum_K \text{ReLU}(p_k))^{-1}}. $$
Harmonic Importance uses ReLU to disregard negative importance scores. The choice of Harmonic Mean boils down to giving more importance to permutations scores as they are typically cleaner. The resulting Harmonic score can be requested by calling YAKE keywords output.
text_modeling.reqYAKEKeywords()
Best Scoring Method
The most suitable scoring method for assessing feature importance in machine learning models ultimately depends on the user's specific needs and context. In my view, all three methods---Mean Decrease in Impurity (MDI), Harmonic Mean, and Permutation Importance---offer valid approaches for evaluating feature significance. Each method has its strengths and can be effectively applied across various scenarios, making any one of them a potentially good choice depending on the particular requirements and goals of the analysis.
Ideal Use Cases
-
Sentiment Analysis Ideal for businesses looking to gauge customer sentiment from reviews, social media posts, or feedback surveys. TextMiner can help identify positive, negative, and neutral sentiments, enabling companies to understand customer perceptions and improve their products or services accordingly.
-
Topic Modeling Useful for content aggregators, news agencies, or researchers who need to categorize large volumes of text into coherent topics. TextMiner can automate the discovery of prevailing themes in documents, making content navigation and organization more efficient.
-
SEO Keyword Extraction Digital marketers and content creators can leverage TextMiner to extract relevant keywords from articles, blog posts, or web pages. This assists in optimizing content for search engines, improving visibility, and driving traffic.
-
Document Summarization Beneficial for legal professionals, academics, or anyone who needs to digest large amounts of text. TextMiner can be used to generate concise summaries of lengthy documents, saving time and highlighting critical information.
-
Fraud Detection In finance and cybersecurity, TextMiner can analyze communication or transaction descriptions to detect patterns indicative of fraudulent activity. This proactive identification helps mitigate risks and safeguard assets.
-
Competitive Analysis Business analysts and strategists can use TextMiner to extract insights from competitor publications, press releases, or product descriptions. This enables a deeper understanding of market positioning, product features, and strategic moves.
-
Customer Support Automation For businesses looking to enhance their customer support, TextMiner can categorize incoming queries, route them to the appropriate department, and even suggest automated responses, improving efficiency and response time.
-
Academic Research Researchers can employ TextMiner to sift through academic papers, journals, or datasets, extracting relevant information, identifying research trends, and facilitating literature reviews.
-
Social Media Monitoring Marketing teams and social media managers can use TextMiner to track brand mentions, analyze public opinion, and understand consumer trends on social media platforms, informing marketing strategies and engagement efforts.
-
Language Learning Applications Developers of educational software can integrate TextMiner to analyze language usage, generate exercises, or provide feedback on language learning progress, enriching the learning experience.
The TextMiner component, with its comprehensive text analysis capabilities, offers a powerful tool for extracting actionable insights from textual data. Its application can significantly impact decision-making, strategic planning, and operational efficiency across a wide range of sectors.
Contributing
We welcome contributions, suggestions, and feedback to make this library even better. Feel free to fork the repository, submit pull requests, or open issues.
Documentation & Examples
For documentation and usage examples, visit the GitHub repository: https://github.com/knowusuboaky/textmining_module
Author: Kwadwo Daddy Nyame Owusu - Boakye
Email: kwadwo.owusuboakye@outlook.com
License: MIT


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file textmining_module-2.1.2.tar.gz.
File metadata
- Download URL: textmining_module-2.1.2.tar.gz
- Upload date:
- Size: 27.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.8.18
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b0660453eadcc605e15bc6b3d4689c4a8f241e5a4297cb832c31fe7658247279
|
|
| MD5 |
8e6f188be8132e415d293e557c490dcb
|
|
| BLAKE2b-256 |
eda8426a3a74574b7a403a5e4a8e88afb7a7284c1e6a4f16c8915bf0be95ed6f
|







