Thai phonology engine with pluggable transliteration systems.

Project description
thaiphon
A zero-dependency Thai phonological transliteration engine. 75 % exact-match
accuracy against independent Wiktionary IPA ground truth when installed with
the optional thaiphon-data-volubilis lexicon package; 57 % on the base
engine alone (see Accuracy for details).
- Try it online: rianthai.pro/thai-transliteration — no install needed. Built for teachers, Thai language learners, and anyone who just wants to type a word and see its pronunciation.
- Documentation: rianthai.pro/docs/thaiphon
What it does
Thai script goes in; transliteration comes out. The engine first resolves
the input into a phonological word — a tuple of syllables, each
decomposed into IPA-based onset, vowel quality, vowel length, coda, and
tone. Every output scheme is then a small declarative SchemeMapping
that renames those phonemes into a target surface form. Add a new
scheme by writing data, not code.
Three built-in renderers ship with the package:
ipa— IPA with tone contour digits (the default phonological representation used for the Wiktionary benchmark).tlc— thai-language.com "Enhanced Phonemic" with bracketed tone tags ({M},{L},{H},{F},{R}).morev— Cyrillic transliteration following the Russian-language tradition.
Custom schemes (Paiboon+, RTGS, or your own pedagogical convention) are
straightforward to register via SchemeMapping.
Install
uv add thaiphon thaiphon-data-volubilis
# or
pip install thaiphon thaiphon-data-volubilis
Requires Python 3.10+. The engine itself has no runtime dependencies.
thaiphon-data-volubilis is a companion package shipping a ~35 k-entry
Thai lexicon derived from the VOLUBILIS Mundo Dictionary. thaiphon
detects it automatically on import and uses it for word-boundary
segmentation and word-specific readings that a rule-based engine can't
infer from orthography alone.
The data package is CC-BY-SA 4.0, separate from the Apache-2.0 engine — installing it doesn't change the license of your own code.
Minimal install (not recommended for most users)
If there's a hard reason to keep dependencies lean:
pip install thaiphon
The engine still runs, but you give up a lot:
- Accuracy on the Wiktionary IPA etalon drops from ~75 % to ~57 %.
- Common words break in visible ways. ส้ม ("orange") comes out as
/sa˥˩.ma˦˥/— two syllables — when the correct reading is/som˥˩/, one closed syllable. The rules alone can't choose between "closed syllable with inherent /o/" and "two open syllables with inserted /a/"; the lexicon settles that kind of ambiguity. - Sanskrit-learned compounds miss their learned readings. มหาวิทยาลัย loses the /tʰa/ insertion between /wit̚/ and /jaː/. The spoken form is /wit̚.tʰa.jaː.laj/; the base engine emits /wit̚.jaː.laj/.
- Failures are silent. The engine always returns a transliteration — no error, no flag, no way to tell at the output layer which of the ~43 % of dictionary entries fell through. A caller can't filter out bad results after the fact.
For anything user-facing, indexing, or searching, install both packages.
Production footprint
thaiphon runs comfortably in long-lived web processes, container
orchestrators, and serverless runtimes. The engine is pure Python with
no heavyweight imports. The optional lexicon (when installed) ships as
a read-only SQLite database, memory-mapped at first use.
| Measurement | Engine alone | + thaiphon-data-volubilis |
|---|---|---|
RSS after first transcribe_sentence |
~10 MiB | ~19 MiB |
| RSS after 1 k lookups | ~10 MiB | ~47 MiB |
| Median lookup latency (lexicon hit) | — | ~13 µs |
| Cold-start import cost | negligible | negligible |
The ~30 MiB of additional resident set after warmup is a bounded
per-process LRU over the most recently inflated entries. The bulk of
the lexicon stays in mmap'd pages of lexicon.db, counted once by
the operating system regardless of how many Python workers have
imported the package.
Web servers (Django, FastAPI, Flask)
Run as many workers as your CPU budget allows. The lexicon does not multiply with worker count, because the OS page cache shares the mapped database across processes:
gunicorn -w 8 myapp.wsgi→ roughly8 × 50 MiBof Python objects plus one shared~25 MiBfor the lexicon. Not8 × 350 MiB.uvicorn --workers 4 myapp:appbehaves the same for FastAPI and Starlette. Inside one worker, async handlers share a SQLite connection-per-thread; the threadpool gets one connection per active thread, opened on first use.- Django works in sync views, async views, and
runserverwithout any setting changes.
The lexicon loads lazily. The first request that touches a Thai word pays the SQLite open and first index-page read (single-digit milliseconds). Subsequent requests within that worker hit the LRU.
Serverless (AWS Lambda, Cloud Run, Fargate)
Cold starts are dominated by your Python interpreter and your own
imports. thaiphon adds almost nothing at import time, since the
lexicon is only read from on first lookup. No eager inflation pass,
no .pyc of several hundred MiB to unpack. The 512 MiB Lambda tier
is plenty even with thaiphon-data-volubilis installed; the
lexicon's footprint is the on-demand LRU, not the full ~25 MiB
database.
Both packages fit comfortably in a Lambda layer.
Multi-process scripts (multiprocessing, joblib, Dask)
Worker processes spawned via fork() (Linux/macOS default) and
spawn() (Windows, or after set_start_method) both work. The
SQLite connection is held in a threading.local() slot, so it never
crosses the fork boundary. Each child opens its own connection on
first use; all of them read from the same mmap'd file.
Tests under pytest-xdist
Each xdist worker is a separate Python process. With the lexicon
installed, per-worker RSS after warmup is in the tens of MiB. Running
-n 8 on a laptop is uneventful.
Quick start
from thaiphon import (
transcribe, transcribe_word, transcribe_sentence, analyze, list_schemes,
)
# Discover available schemes.
list_schemes()
# ('ipa', 'morev', 'tlc')
# IPA — the phonological representation.
transcribe("ภูมิ", scheme="ipa")
# '/pʰuːm˧/'
# TLC — thai-language.com convention.
transcribe("ลิฟต์", scheme="tlc")
# 'lif{H}'
# Single-word shortcut that skips sentence tokenization.
transcribe_word("สวัสดี", scheme="ipa")
# '/sa˨˩.wat̚˨˩.diː˧/'
# Sentence segmentation + rendering.
transcribe_sentence("ฉันชอบกินข้าว", scheme="ipa")
# '/t͡ɕʰan˩˩˦/ /t͡ɕʰɔːp̚˥˩/ /kin˧/ /kʰaːw˥˩/'
# Reading profile switches colloquial vs citation pronunciation — see below.
transcribe("ลิฟต์", scheme="ipa", profile="etalon_compat")
# '/lip̚˦˥/'
# Access the intermediate phonological word.
result = analyze("ผลไม้")
for syl in result.best.syllables:
print(syl.onset, syl.vowel.symbol, syl.vowel_length.name, syl.coda, syl.tone.name)
Reading profiles
The profile argument controls how the engine handles foreign
phonotactics in loanwords, especially the coda consonants that native
Thai normally neutralises:
# "Lift" / elevator — final /f/ from English.
transcribe("ลิฟต์", scheme="ipa", profile="everyday") # '/lif˦˥/'
transcribe("ลิฟต์", scheme="ipa", profile="etalon_compat") # '/lip̚˦˥/'
# "Graph" — register-sensitive.
transcribe("กราฟ", scheme="ipa", profile="everyday") # '/kraːp̚˨˩/'
transcribe("กราฟ", scheme="ipa", profile="careful_educated") # '/kraːf˨˩/'
The four supported profiles:
everyday(default) — colloquial urban pronunciation. Preserves foreign codas in well-integrated modern loans (ลิฟต์, เคส, อีเมล) and collapses them in older or less register-sensitive words (กราฟ, กอล์ฟ, บัส).careful_educated— broadcast/formal register. Preserves more foreign codas thaneveryday.learned_full— restores full Sanskrit/Pali learned readings for Indic-derived words (ภูมิ, ปกติ).etalon_compat— dictionary-citation style; collapses every foreign coda to its native-Thai equivalent. Useful for matching pronunciation dictionaries.
Preservation is per-word, driven by the lexicon and attested usage — not by blanket rules that paper over lexical convention.
Accuracy
Measured by exact-match rate against independent, publicly-licensed Thai phonology corpora:
| Corpus | License | Size | Scheme | Base engine | With thaiphon-data-volubilis |
|---|---|---|---|---|---|
| kaikki.org Thai Wiktionary | CC-BY-SA 4.0 | 17,014 | ipa |
~57 % | ~75 % |
| PyThaiNLP G2P (Wiktionary) | CC0 | 15,782 | ipa |
— | ~73 % |
"Base engine" is pip install thaiphon on its own. The jump to 75 %
comes from the thaiphon-data-volubilis lexicon (see
Install) — the word-boundary and variant coverage a
rule-based engine can't infer from orthography alone.
Both numbers come from public data. The primary kaikki.org etalon and PyThaiNLP's independent G2P extraction are cross-checks on each other; if the engine breaks in a way that only one source catches, the other will usually catch it too.
Reproducing the numbers yourself:
The repository ships a 2,500-entry random sample of the kaikki.org Thai Wiktionary dump (seed 20260421, CC-BY-SA 4.0) as a bundled pytest fixture. Install the data package, then run the etalon tests:
# Ensure both packages are installed (see Install section).
pip install thaiphon thaiphon-data-volubilis
# Bundled sample — runs in seconds, no external download:
pytest tests/etalon/test_wiktionary_ipa_sample.py -v
# Floor: 72 %. Measured: ~74 % on the sample.
# Full 17,014-entry measurement — download the kaikki.org dump first:
# https://kaikki.org/dictionary/rawdata.html (Thai entries, ~43 MB)
# Place at ~/.cache/thaiphon/kaikki-thai.jsonl (or set $THAIPHON_KAIKKI)
pytest tests/etalon/test_wiktionary_ipa_full.py -v
# Floor: 73 %. Measured: ~75 % on the full corpus.
If thaiphon-data-volubilis is not installed, both etalon tests skip
with a message pointing at the install command, so make test always
finishes cleanly whatever your setup. See tests/README.md for more
detail and tests/fixtures/README.md for fixture licensing and sampling
parameters.
Custom schemes
from thaiphon.model.enums import VowelLength
from thaiphon.renderers.mapping import SchemeMapping, MappingRenderer
from thaiphon.registry import RENDERERS
from thaiphon import transcribe
pedagogical = SchemeMapping(
scheme_id="ped",
onset_map={"kʰ": "kh", "k": "k", "tɕ": "j", "m": "m", "n": "n", ...},
vowel_map={
("a", VowelLength.SHORT): "a",
("a", VowelLength.LONG): "aa",
...
},
coda_map={"m": "m", "n": "n", "ŋ": "ng", "p̚": "p", "t̚": "t", "k̚": "k"},
tone_format=lambda base, syl: base, # no tone decoration
syllable_separator="-",
)
RENDERERS.register("ped", lambda: MappingRenderer(pedagogical))
transcribe("สวัสดี", scheme="ped")
Architecture
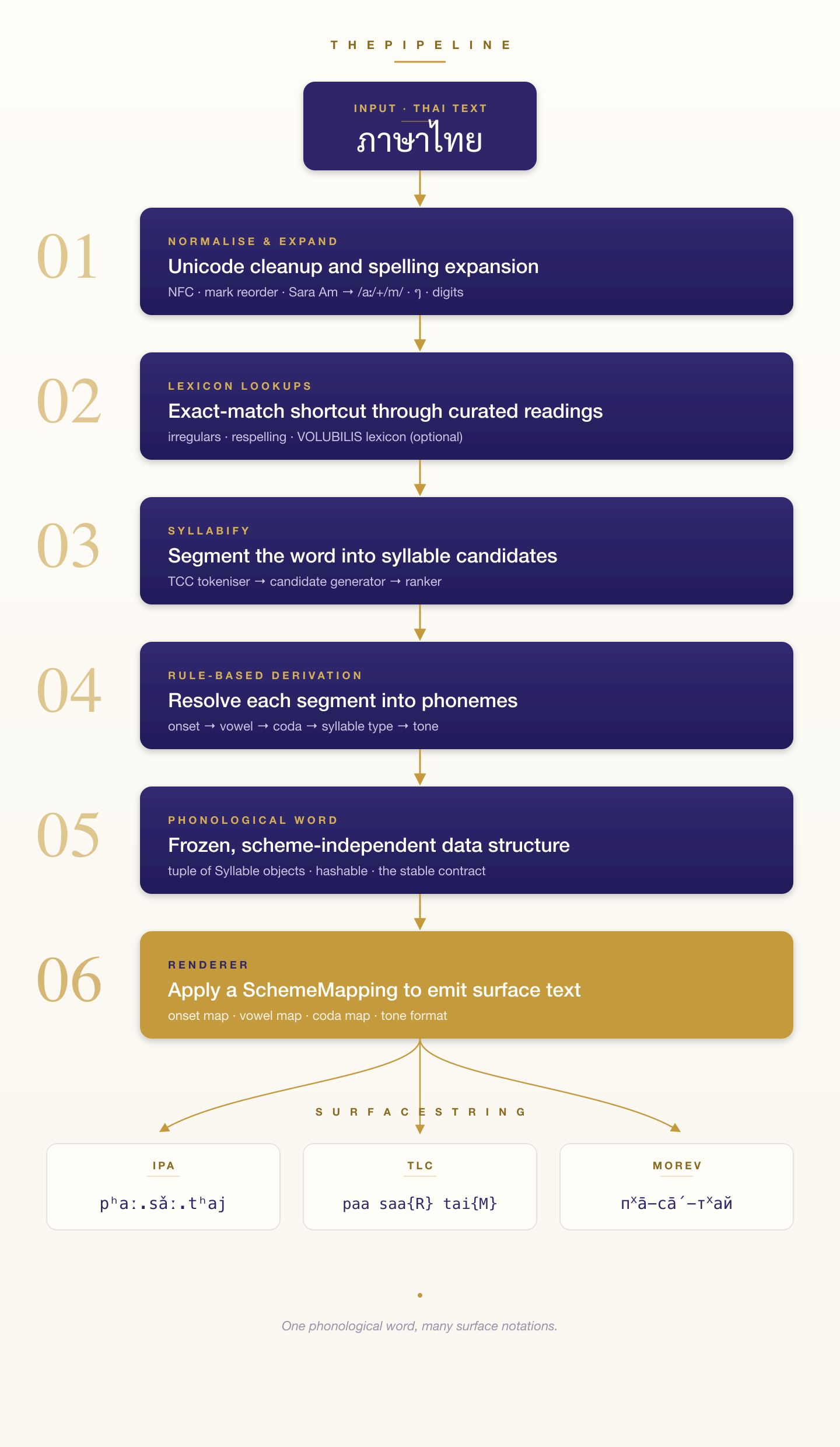
Key design decisions:
- Zero runtime dependencies. The full phonology, rules, and lexicon ship as plain Python with no C or FFI.
- Immutable phonological model via frozen dataclasses.
- Lexicons (loanword overrides, Indic learned readings, royal vocabulary, etc.) are module-level Python literals — auditable and grep-able.
- Scheme-specific editorial conventions live in the renderer layer, not the phonology. Improvements to onset/vowel/coda derivation show up in every output scheme at once.
Development
git clone https://github.com/5w0rdf15h/thaiphon
cd thaiphon
make dev # install with dev dependencies via uv
make test # pytest -q
make lint # ruff
make typecheck # mypy src/thaiphon
make check # test + lint + typecheck
make format # black + isort
The test suite is organised in two layers:
tests/*.py— public API surface and representative regression examples. Fast, deterministic, and doubles as living API documentation.tests/rules/*.py— internal phonological-rule coverage (tone matrix, coda collapse, onset resolution, cluster strategies, lexicon membership, etc.). Exercises internal modules directly; the right place to add a regression when fixing a derivation bug.
All example words in tests are hand-curated from openly-licensed sources
only — Wiktionary (CC-BY-SA 4.0) and VOLUBILIS Mundo Dictionary
(CC-BY-SA 4.0). See tests/fixtures/README.md for the full provenance
policy.
Credits
Includes code adapted from the PyThaiNLP project (Apache-2.0). See
NOTICE for the full attribution. Optional lexicon data in
thaiphon-data-volubilis derives from the VOLUBILIS Mundo Dictionary
(CC-BY-SA 4.0).
Acknowledgements
Personal thanks to the teachers and principal at RTL School — Rak Thai Language School for teaching and explaining Thai to me. This engine's phonological intuitions come directly from their patient, careful instruction.
License
Apache-2.0. See LICENSE.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file thaiphon-0.3.0.tar.gz.
File metadata
- Download URL: thaiphon-0.3.0.tar.gz
- Upload date:
- Size: 487.0 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
5b0f603a4066d49736d92eca63aa8f6abe435d43393f0bcb12d6e5c24342ef00
|
|
| MD5 |
f76a8b856150eb490f1a5ca5e735ead0
|
|
| BLAKE2b-256 |
c61c339fd70a607aa9d8ef0ce04c05f09a338c404ce92a947d1e207fe0990891
|
Provenance
The following attestation bundles were made for thaiphon-0.3.0.tar.gz:
Publisher:
publish.yml on 5w0rdf15h/thaiphon
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
thaiphon-0.3.0.tar.gz -
Subject digest:
5b0f603a4066d49736d92eca63aa8f6abe435d43393f0bcb12d6e5c24342ef00 - Sigstore transparency entry: 1362896262
- Sigstore integration time:
-
Permalink:
5w0rdf15h/thaiphon@fa9838544c13986b42d01a3d6bb1c1b1197d13b2 -
Branch / Tag:
refs/tags/v0.3.0 - Owner: https://github.com/5w0rdf15h
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@fa9838544c13986b42d01a3d6bb1c1b1197d13b2 -
Trigger Event:
release
-
Statement type:
File details
Details for the file thaiphon-0.3.0-py3-none-any.whl.
File metadata
- Download URL: thaiphon-0.3.0-py3-none-any.whl
- Upload date:
- Size: 119.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a1c88fbb2adf90d8e86e4d9d26803c1a9fe768f1b4f61cc6bfbc8ec40e83d9c2
|
|
| MD5 |
ab49a92a2e835962af12780810ec61a1
|
|
| BLAKE2b-256 |
abde06b99f78aa81ddd6cd964c6af35214599c0f88fe4d22f04e49a1f6e1bad9
|
Provenance
The following attestation bundles were made for thaiphon-0.3.0-py3-none-any.whl:
Publisher:
publish.yml on 5w0rdf15h/thaiphon
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
thaiphon-0.3.0-py3-none-any.whl -
Subject digest:
a1c88fbb2adf90d8e86e4d9d26803c1a9fe768f1b4f61cc6bfbc8ec40e83d9c2 - Sigstore transparency entry: 1362896323
- Sigstore integration time:
-
Permalink:
5w0rdf15h/thaiphon@fa9838544c13986b42d01a3d6bb1c1b1197d13b2 -
Branch / Tag:
refs/tags/v0.3.0 - Owner: https://github.com/5w0rdf15h
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@fa9838544c13986b42d01a3d6bb1c1b1197d13b2 -
Trigger Event:
release
-
Statement type:







