logWMSE is an audio quality metric & loss function with support for digital silence target. Useful for training and evaluating audio source separation systems.

Project description



This repository contains the torch implementation of an audio quality metric, logWMSE, originally proposed by Iver Jordal. In addition to the original metric, this implementation can also be used as a loss function for training audio separation and denoising models.
logWMSE is a custom metric and loss function for audio signals that calculates the logarithm (log) of a frequency-weighted (W) Mean Squared Error (MSE). It is designed to address several shortcomings of common audio metrics, most importantly the lack of support for digital silence targets.
Installation



pip install torch-log-wmse
Usage Example
import torch
from torch_log_wmse import LogWMSE
# Tensor shapes
audio_length = 1.0
sample_rate = 44100
audio_stems = 4 # 4 audio stems (e.g. vocals, drums, bass, other)
audio_channels = 2 # stereo
batch = 4 # batch size
# Instantiate logWMSE
# Set `return_as_loss=False` to resturn as a positive metric (Default: True)
# Set `bypass_filter=True` to bypass frequency weighting (Default: False)
log_wmse = LogWMSE(
audio_length=audio_length,
sample_rate=sample_rate,
return_as_loss=True, # optional
bypass_filter=False, # optional
)
# Generate random inputs (scale between -1 and 1)
audio_lengths_samples = int(audio_length * sample_rate)
unprocessed_audio = 2 * torch.rand(batch, audio_channels, audio_lengths_samples) - 1
processed_audio = 2 * torch.rand(batch, audio_channels, audio_stems, audio_lengths_samples) - 1
target_audio = torch.zeros(batch, audio_channels, audio_stems, audio_lengths_samples)
log_wmse = log_wmse(unprocessed_audio, processed_audio, target_audio)
print(log_wmse) # Expected output: approx. -18.42
logWMSE accepts three torch tensors of the following shapes:
- unprocessed_audio:
[batch, audio_channels, samples] - processed_audio:
[batch, audio_channels, audio_stems, samples] - target_audio:
[batch, audio_channels, audio_stems, samples]
Each dimension being:
batch: Number of audio files in a batch (i.e. batch size).audio_channels: Number of channels (i.e. 1 for mono and 2 for stereo).audio_stems: Number of separate audio sources. For source separation, this could be multiple different instruments, vocals, etc. For denoising audio, this will be 1.samples: Number of audio samples (e.g. 1 second of audio @ 44.1kHz is 44100 samples).
Motivation
The goal of this metric is to account for several factors not present in current audio evaluation metrics, such as dealing with digital silence. Mean Squared Error (MSE) is well-defined for digital silence targets, but has its own set of drawbacks. Attempting to mitigate these issues, the following are some attributes of logWMSE:
- Supports digital silence targets not supported by other audio metrics. i.e. (SI-)SDR, SIR, SAR, ISR, VISQOL_audio, STOI, CDPAM, and VISQOL.
- Overcomes the small value range issue of MSE (i.e. between 1e-8 and 1e-3), making number formatting and sight-reading easier. It is scaled similarly to SI-SDR for consistency with current benchmark metrics (i.e. 3 is poor, 30 is very good).
- Scale-invariant, aligns with the frequency sensitivity of human hearing.
- Invariant to the tiny errors of MSE that are inaudible to humans.
- Logarithmic, reflecting the logarithmic sensitivity of human hearing.
- Tailored specifically for audio signals.
Frequency Weighting
To measure the frequencies of a signal closer to that of human hearing, the following frequency weighting is applied. This helps the model effectively pay less attention to errors at frequencies that humans are not sensitive to (e.g. 50 Hz) and give more weight to those that we are acutely tuned to (e.g. 3kHz).
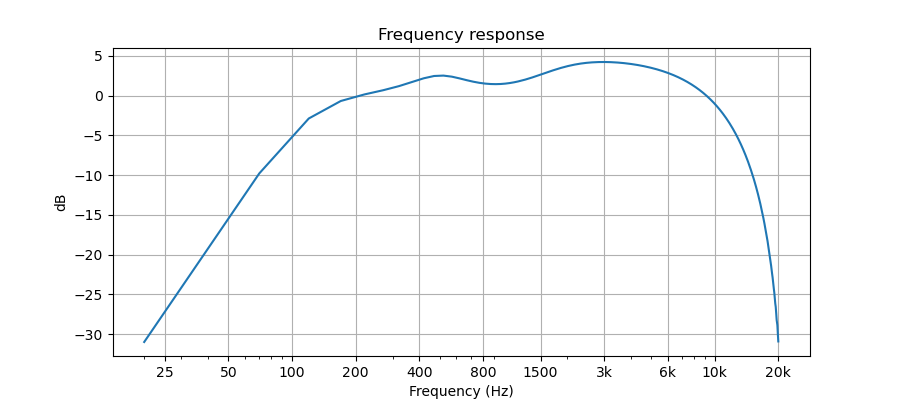
This metric has been constructed with high-fidelity audio in mind (sample rates ≥ 44.1kHz). It theoretically could work for lower sample rates, like 16kHz, but the metric performs an internal resampling to 44.1kHz for consistency across any input sample rates.
Inputs
Unlike many audio quality metrics, logWMSE accepts 3 audio inputs rather than 2:
- Unprocessed audio (e.g. raw, noisy audio)
- Processed audio (e.g. denoised or separated audio)
- Target audio (e.g. ground truth, clean audio)
Typically audio loss functions only use the processed audio and target audio to compare against one another. However, logWMSE requires the initial, unprocessed audio because it needs to be able to measure how well the processed audio was attenuated from the unprocessed version. This adds a factor that accounts for when the input contains silence (digital zero).
This also adds a factor of scale invariance in the sense that the processed audio needs to be scaled appropriately relative to both the unprocessed audio and ground truth. Conceptually, this means that if all 3 inputs are gained by the same arbitrary amount, the metric score will stay the same.
Limitations
- The metric isn't invariant to arbitrary scaling, polarity inversion, or offsets in the estimated audio relative to the target.
- Although it incorporates frequency filtering inspired by human auditory sensitivity, it doesn't fully model human auditory perception. For instance, it doesn't consider auditory masking.
Contributing
Contributions are welcome! Please open an issue or submit a pull request if you have any improvements or new features to suggest.
License
This project is licensed under the Apache License 2.0. See LICENSE for details.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file torch_log_wmse-0.3.1.tar.gz.
File metadata
- Download URL: torch_log_wmse-0.3.1.tar.gz
- Upload date:
- Size: 43.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.8.18
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e0dccf5522fef2d10efacab3c3f042f7fe5c87d1f7a7c99ab5d7474f1f8bc7c3
|
|
| MD5 |
0a6e3f591c211ffb7063586a8a196134
|
|
| BLAKE2b-256 |
6db8fd7817134e152727c7f81b1a12bd2c9ec127800d0cc27b1a5c66f3fdeb44
|
File details
Details for the file torch_log_wmse-0.3.1-py3-none-any.whl.
File metadata
- Download URL: torch_log_wmse-0.3.1-py3-none-any.whl
- Upload date:
- Size: 39.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.8.18
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c632d4607f0e743630b4b9efd3f2a9c30e3f45057d701041c2fef89e7e849c32
|
|
| MD5 |
2fda568cb014d89bb1b64b4e48b6850b
|
|
| BLAKE2b-256 |
d80fb1b0551f522ce05b6ddb835264bb865ac3aa8955b832e1756d179fd87af7
|







