PyTorch implementation of the Perceptual Evaluation of Speech Quality

Project description
Loss function inspired by the PESQ score



Implementation of the widely used Perceptual Evaluation of Speech Quality (PESQ) score as a torch loss function. The PESQ loss alone performs not good for noise suppression, instead combine with scale invariant SDR. For more information see 1,2.
Installation
To install the package just run:
$ pip install torch-pesq
Usage
import torch
from torch_pesq import PesqLoss
pesq = PesqLoss(0.5,
sample_rate=44100,
)
mos = pesq.mos(reference, degraded)
loss = pesq(reference, degraded)
print(mos, loss)
loss.backward()
Comparison to reference implementation
The following figures uses samples from the VCTK 1 speech and DEMAND 2 noise dataset with varying mixing factors. They illustrate correlation and maximum error between the reference and torch implementation:
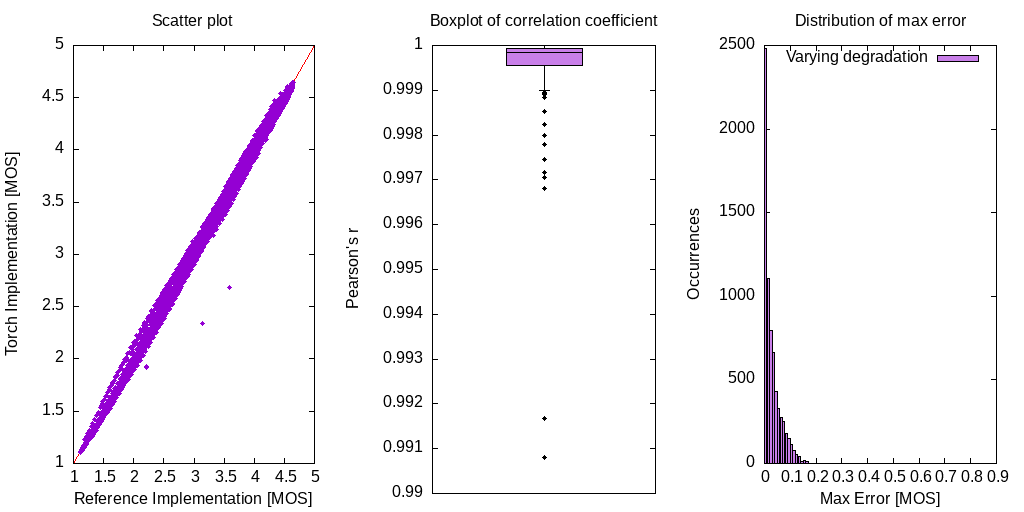
The difference is a result from missing time alignment implementation and a level alignment done with IIR filtering instead of a frequency weighting. They are minor and should not be significant when used as a loss function. There are two outliers which may degrade results and further investigation is needed to find the source of difference.
Validation improvements when used as loss function
Validation results for fullband noise suppression:
- Noise estimator: Recurrent SRU with soft masking. 8 layers, width of 512 result in ~1586k parameters of the unpruned model.
- STFT for signal coding: 512 window length, 50% overlap, hamming window
- Mel filterbank with 32 Mel features
The baseline system uses L1 time domain loss. Combining the PESQ loss function together with scale invariant SDR gives improvement of ~0.1MOS for PESQ and slight improvements in speech distortions, as well as a more stable training progression. Horizontal lines indicate the score of noisy speech.

Relevant references
- End-to-End Multi-Task Denoising for joint SDR and PESQ Optimization
- A Deep Learning Loss Function Based on the Perceptual Evaluation of the Speech Quality
- P.862 : Perceptual evaluation of speech quality (PESQ)
- Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs
- CSTR VCTK Corpus: English Multi-speaker Corpus for CSTR Voice Cloning Toolkit
- The Diverse Environments Multi-channel Acoustic Noise Database (DEMAND): A database of multichannel environmental noise recordings
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file torch-pesq-0.1.2.tar.gz.
File metadata
- Download URL: torch-pesq-0.1.2.tar.gz
- Upload date:
- Size: 44.0 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.8.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
4c5ecc0660eaa8bee3840efa1adcc84d7b53fdc51554c9b1affae4903218acbb
|
|
| MD5 |
d48fa3b53c7d0c65b562366236eece94
|
|
| BLAKE2b-256 |
7bc29bb24c373f5468c1c433e5703b7857af85a341cbe69e558ef858aa57ea0a
|
File details
Details for the file torch_pesq-0.1.2-py3-none-any.whl.
File metadata
- Download URL: torch_pesq-0.1.2-py3-none-any.whl
- Upload date:
- Size: 14.7 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.8.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6f3fa836f6517f86652332c67b653164c16a95867beb3095dd0392b814efda45
|
|
| MD5 |
009f0bb5cce57a1d2a79b762ae90ae56
|
|
| BLAKE2b-256 |
5099c07d07829b7f6e934c4d00d77c2bdc8e5f012cb0037a09c75aa1c78a55f9
|







