An efficient library for differentiable optimization for PyTorch.


Project description








Installation | Documentation | Tutorials | Examples | Paper | Citation
TorchOpt is an efficient library for differentiable optimization built upon PyTorch. TorchOpt is:
- Comprehensive: TorchOpt provides three differentiation modes - explicit differentiation, implicit differentiation, and zero-order differentiation for handling different differentiable optimization situations.
- Flexible: TorchOpt provides both functional and objective-oriented API for users' different preferences. Users can implement differentiable optimization in JAX-like or PyTorch-like style.
- Efficient: TorchOpt provides (1) CPU/GPU acceleration differentiable optimizer (2) RPC-based distributed training framework (3) Fast Tree Operations, to largely increase the training efficiency for bi-level optimization problems.
Beyond differentiable optimization, TorchOpt can also be regarded as a functional optimizer that enables JAX-like composable functional optimizer for PyTorch. With TorchOpt, users can easily conduct neural network optimization in PyTorch with a functional style optimizer, similar to Optax in JAX.
The README is organized as follows:
- TorchOpt as Functional Optimizer
- TorchOpt for Differentiable Optimization
- High-Performance and Distributed Training
- Visualization
- Examples
- Installation
- Changelog
- Citing TorchOpt
- The Team
- License
TorchOpt as Functional Optimizer
The design of TorchOpt follows the philosophy of functional programming.
Aligned with functorch, users can conduct functional style programming with models, optimizers and training in PyTorch.
We use the Adam optimizer as an example in the following illustration.
You can also check out the tutorial notebook Functional Optimizer for more details.
Optax-Like API
For those users who prefer fully functional programming, we offer Optax-Like API by passing gradients and optimizer states to the optimizer function.
Here is an example coupled with functorch:
class Net(nn.Module): ...
class Loader(DataLoader): ...
net = Net() # init
loader = Loader()
optimizer = torchopt.adam()
model, params = functorch.make_functional(net) # use functorch extract network parameters
opt_state = optimizer.init(params) # init optimizer
xs, ys = next(loader) # get data
pred = model(params, xs) # forward
loss = F.cross_entropy(pred, ys) # compute loss
grads = torch.autograd.grad(loss, params) # compute gradients
updates, opt_state = optimizer.update(grads, opt_state) # get updates
params = torchopt.apply_updates(params, updates) # update network parameters
We also provide a wrapper torchopt.FuncOptimizer to make maintaining the optimizer state easier:
net = Net() # init
loader = Loader()
optimizer = torchopt.FuncOptimizer(torchopt.adam()) # wrap with `torchopt.FuncOptimizer`
model, params = functorch.make_functional(net) # use functorch extract network parameters
for xs, ys in loader: # get data
pred = model(params, xs) # forward
loss = F.cross_entropy(pred, ys) # compute loss
params = optimizer.step(loss, params) # update network parameters
PyTorch-Like API
We also design a base class torchopt.Optimizer that has the same interface as torch.optim.Optimizer.
We offer origin PyTorch APIs (e.g. zero_grad() or step()) by wrapping our Optax-Like API for traditional PyTorch users.
net = Net() # init
loader = Loader()
optimizer = torchopt.Adam(net.parameters())
xs, ys = next(loader) # get data
pred = net(xs) # forward
loss = F.cross_entropy(pred, ys) # compute loss
optimizer.zero_grad() # zero gradients
loss.backward() # backward
optimizer.step() # step updates
Differentiable
On top of the same optimization function as torch.optim, an important benefit of the functional optimizer is that one can implement differentiable optimization easily.
This is particularly helpful when the algorithm requires differentiation through optimization updates (such as meta-learning practices).
We take as the inputs the gradients and optimizer states, and use non-in-place operators to compute and output the updates.
The processes can be automatically implemented, with the only need from users being to pass the argument inplace=False to the functions.
Check out the section Explicit Gradient (EG) functional API for example.
TorchOpt for Differentiable Optimization
We design a bilevel-optimization updating scheme, which can be easily extended to realize various differentiable optimization processes.
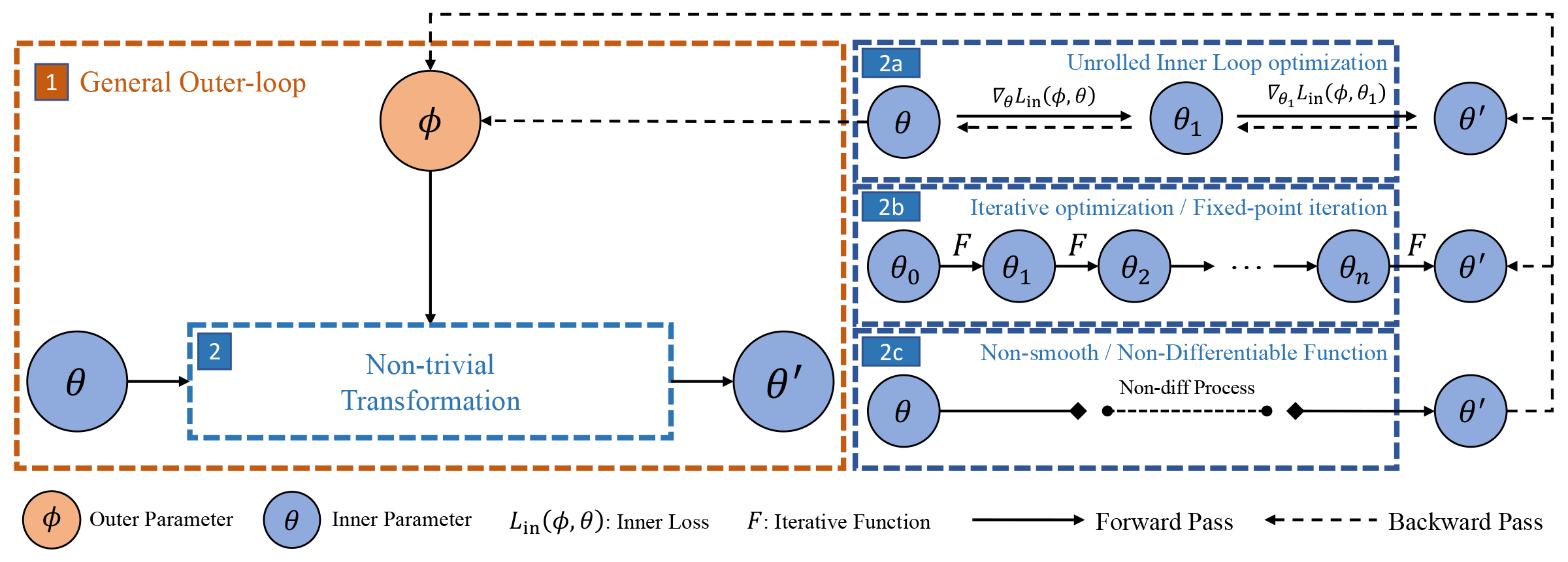
As shown above, the scheme contains an outer level that has parameters $\phi$ that can be learned end-to-end through the inner level parameters solution $\theta^{\prime}(\phi)$ by using the best-response derivatives $\partial \theta^{\prime}(\phi) / \partial \phi$. TorchOpt supports three differentiation modes. It can be seen that the key component of this algorithm is to calculate the best-response (BR) Jacobian. From the BR-based perspective, existing gradient methods can be categorized into three groups: explicit gradient over unrolled optimization, implicit differentiation, and zero-order gradient differentiation.
Explicit Gradient (EG)
The idea of the explicit gradient is to treat the gradient step as a differentiable function and try to backpropagate through the unrolled optimization path. This differentiation mode is suitable for algorithms when the inner-level optimization solution is obtained by a few gradient steps, such as MAML and MGRL. TorchOpt offers both functional and object-oriented API for EG to fit different user applications.
Functional API
The functional API is to conduct optimization in a functional programming style.
Note that we pass the argument inplace=False to the functions to make the optimization differentiable.
Refer to the tutorial notebook Functional Optimizer for more guidance.
# Define functional optimizer
optimizer = torchopt.adam()
# Define meta and inner parameters
meta_params = ...
fmodel, params = make_functional(model)
# Initial state
state = optimizer.init(params)
for iter in range(iter_times):
loss = inner_loss(fmodel, params, meta_params)
grads = torch.autograd.grad(loss, params)
# Apply non-inplace parameter update
updates, state = optimizer.update(grads, state, inplace=False)
params = torchopt.apply_updates(params, updates)
loss = outer_loss(fmodel, params, meta_params)
meta_grads = torch.autograd.grad(loss, meta_params)
OOP API
TorchOpt also provides OOP API compatible with the PyTorch programming style. Refer to the example and the tutorial notebook Meta-Optimizer, Stop Gradient for more guidance.
# Define meta and inner parameters
meta_params = ...
model = ...
# Define differentiable optimizer
optimizer = torchopt.MetaAdam(model) # a model instance as the argument instead of model.parameters()
for iter in range(iter_times):
# Perform inner update
loss = inner_loss(model, meta_params)
optimizer.step(loss)
loss = outer_loss(model, meta_params)
loss.backward()
Implicit Gradient (IG)
By treating the solution $\theta^{\prime}$ as an implicit function of $\phi$, the idea of IG is to directly get analytical best-response derivatives $\partial \theta^{\prime} (\phi) / \partial \phi$ by implicit function theorem. This is suitable for algorithms when the inner-level optimal solution is achieved ${\left. \frac{\partial F (\theta, \phi)}{\partial \theta} \right\rvert}_{\theta=\theta^{\prime}} = 0$ or reaches some stationary conditions $F (\theta^{\prime}, \phi) = 0$, such as iMAML and DEQ. TorchOpt offers both functional and OOP APIs for supporting both conjugate gradient-based and Neumann series-based IG methods. Refer to the example iMAML and the notebook Implicit Gradient for more guidance.
Functional API
For the implicit gradient, similar to JAXopt, users need to define the stationary condition and TorchOpt provides the decorator to wrap the solve function for enabling implicit gradient computation.
# The stationary condition for the inner-loop
def stationary(params, meta_params, data):
# Stationary condition construction
return stationary condition
# Decorator for wrapping the function
# Optionally specify the linear solver (conjugate gradient or Neumann series)
@torchopt.diff.implicit.custom_root(stationary, solve=linear_solver)
def solve(params, meta_params, data):
# Forward optimization process for params
return output
# Define params, meta_params and get data
params, meta_prams, data = ..., ..., ...
optimal_params = solve(params, meta_params, data)
loss = outer_loss(optimal_params)
meta_grads = torch.autograd.grad(loss, meta_params)
OOP API
TorchOpt also offers an OOP API, which users need to inherit from the class torchopt.nn.ImplicitMetaGradientModule to construct the inner-loop network.
Users need to define the stationary condition/objective function and the inner-loop solve function to enable implicit gradient computation.
# Inherited from the class ImplicitMetaGradientModule
# Optionally specify the linear solver (conjugate gradient or Neumann series)
class InnerNet(ImplicitMetaGradientModule, linear_solve=linear_solver):
def __init__(self, meta_param):
super().__init__()
self.meta_param = meta_param
...
def forward(self, batch):
# Forward process
...
def optimality(self, batch, labels):
# Stationary condition construction for calculating implicit gradient
# NOTE: If this method is not implemented, it will be automatically
# derived from the gradient of the `objective` function.
...
def objective(self, batch, labels):
# Define the inner-loop optimization objective
...
def solve(self, batch, labels):
# Conduct the inner-loop optimization
...
# Get meta_params and data
meta_params, data = ..., ...
inner_net = InnerNet(meta_params)
# Solve for inner-loop process related to the meta-parameters
optimal_inner_net = inner_net.solve(data)
# Get outer loss and solve for meta-gradient
loss = outer_loss(optimal_inner_net)
meta_grads = torch.autograd.grad(loss, meta_params)
Zero-order Differentiation (ZD)
When the inner-loop process is non-differentiable or one wants to eliminate the heavy computation burdens in the previous two modes (brought by Hessian), one can choose Zero-order Differentiation (ZD). ZD typically gets gradients based on zero-order estimation, such as finite-difference, or Evolutionary Strategy. Instead of optimizing the objective $F$, ES optimizes a smoothed objective. TorchOpt provides both functional and OOP APIs for the ES method. Refer to the tutorial notebook Zero-order Differentiation for more guidance.
Functional API
For zero-order differentiation, users need to define the forward pass calculation and the noise sampling procedure. TorchOpt provides the decorator to wrap the forward function for enabling zero-order differentiation.
# Customize the noise sampling function in ES
def distribution(sample_shape):
# Generate a batch of noise samples
# NOTE: The distribution should be spherical symmetric and with a constant variance of 1.
...
return noise_batch
# Distribution can also be an instance of `torch.distributions.Distribution`, e.g., `torch.distributions.Normal(...)`
distribution = torch.distributions.Normal(loc=0, scale=1)
# Specify method and hyper-parameter of ES
@torchopt.diff.zero_order(distribution, method)
def forward(params, batch, labels):
# Forward process
...
return objective # the returned tensor should be a scalar tensor
OOP API
TorchOpt also offers an OOP API, which users need to inherit from the class torchopt.nn.ZeroOrderGradientModule to construct the network as an nn.Module following a classical PyTorch style.
Users need to define the forward process zero-order gradient procedures forward() and a noise sampling function sample().
# Inherited from the class ZeroOrderGradientModule
# Optionally specify the `method` and/or `num_samples` and/or `sigma` used for sampling
class Net(ZeroOrderGradientModule, method=method, num_samples=num_samples, sigma=sigma):
def __init__(self, ...):
...
def forward(self, batch):
# Forward process
...
return objective # the returned tensor should be a scalar tensor
def sample(self, sample_shape=torch.Size()):
# Generate a batch of noise samples
# NOTE: The distribution should be spherical symmetric and with a constant variance of 1.
...
return noise_batch
# Get model and data
net = Net(...)
data = ...
# Forward pass
loss = Net(data)
# Backward pass using zero-order differentiation
grads = torch.autograd.grad(loss, net.parameters())
High-Performance and Distributed Training
CPU/GPU accelerated differentiable optimizer
We take the optimizer as a whole instead of separating it into several basic operators (e.g., sqrt and div).
Therefore, by manually writing the forward and backward functions, we can perform the symbolic reduction.
In addition, we can store some intermediate data that can be reused during the backpropagation.
We write the accelerated functions in C++ OpenMP and CUDA, bind them by pybind11 to allow they can be called by Python, and then define the forward and backward behavior using torch.autograd.Function.
Users can use it by simply setting the use_accelerated_op flag as True.
Refer to the corresponding sections in the tutorials Functional Optimizer](tutorials/1_Functional_Optimizer.ipynb) and Meta-Optimizer
optimizer = torchopt.MetaAdam(model, lr, use_accelerated_op=True)
Distributed Training
TorchOpt provides distributed training features based on the PyTorch RPC module for better training speed and multi-node multi-GPU support.
Different from the MPI-like parallelization paradigm, which uses multiple homogeneous workers and requires carefully designed communication hooks, the RPC APIs allow users to build their optimization pipeline more flexibly.
Experimental results show that we achieve an approximately linear relationship between the speed-up ratio and the number of workers.
Check out the Distributed Training Documentation and distributed MAML example for more specific guidance.
OpTree
We implement the PyTree to enable fast nested structure flattening using C++.
The tree operations (e.g., flatten and unflatten) are very important in enabling functional and Just-In-Time (JIT) features of deep learning frameworks.
By implementing it in C++, we can use some cache/memory-friendly structures (e.g., absl::InlinedVector) to improve the performance.
For more guidance and comparison results, please refer to our open-source project OpTree.
Visualization
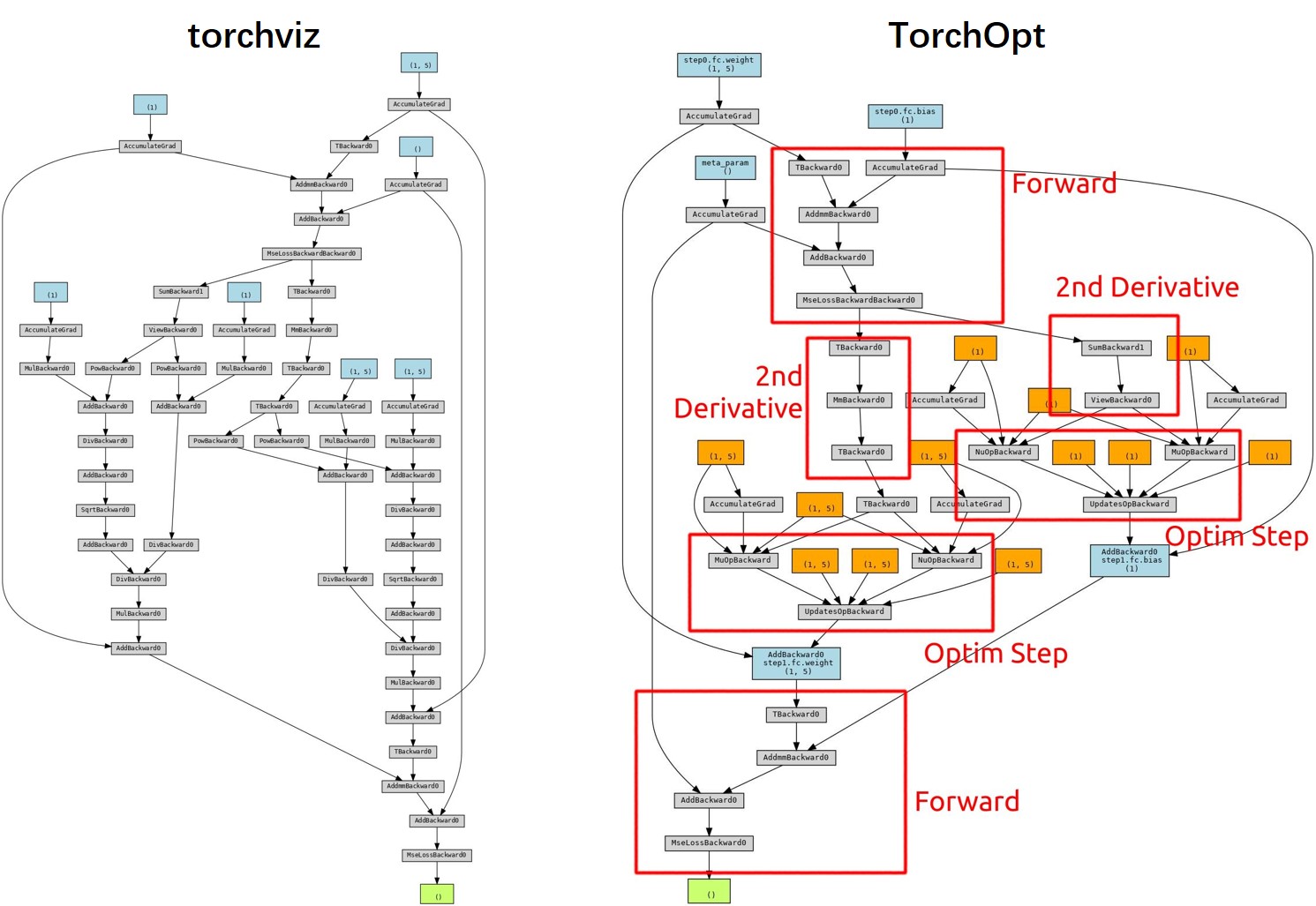
Complex gradient flow in meta-learning brings in a great challenge for managing the gradient flow and verifying its correctness of it.
TorchOpt provides a visualization tool that draws variable (e.g., network parameters or meta-parameters) names on the gradient graph for better analysis.
The visualization tool is modified from torchviz.
Refer to the example visualization code and the tutorial notebook Visualization for more details.
The figure below shows the visualization result.
Compared with torchviz, TorchOpt fuses the operations within the Adam together (orange) to reduce the complexity and provide simpler visualization.
Examples
In the examples directory, we offer several examples of functional optimizers and lightweight meta-learning examples with TorchOpt.
- Model-Agnostic Meta-Learning (MAML) - Supervised Learning (ICML 2017)
- Learning to Reweight Examples for Robust Deep Learning (ICML 2018)
- Model-Agnostic Meta-Learning (MAML) - Reinforcement Learning (ICML 2017)
- Meta-Gradient Reinforcement Learning (MGRL) (NeurIPS 2018)
- Learning through opponent learning process (LOLA) (AAMAS 2018)
- Meta-Learning with Implicit Gradients (NeurIPS 2019)
Also, check examples for more distributed/visualization/functorch-compatible examples.
Installation
Requirements
- PyTorch
- (Optional) For visualizing computation graphs
- Graphviz (for Linux users use
apt/yum install graphvizorconda install -c anaconda python-graphviz)
- Graphviz (for Linux users use
Please follow the instructions at https://pytorch.org to install PyTorch in your Python environment first.
Then run the following command to install TorchOpt from PyPI (

pip3 install torchopt
If the minimum version of PyTorch is not satisfied, pip will install/upgrade it for you. Please be careful about the torch build for CPU / CUDA support (e.g. cpu, cu116, cu117).
You may need to specify the extra index URL for the torch package:
pip3 install torchopt --extra-index-url https://download.pytorch.org/whl/cu117
See https://pytorch.org for more information about installing PyTorch.
You can also build shared libraries from source, use:
git clone https://github.com/metaopt/torchopt.git
cd torchopt
pip3 install .
We provide a conda environment recipe to install the build toolchain such as cmake, g++, and nvcc.
You can use the following commands with conda / mamba to create a new isolated environment.
git clone https://github.com/metaopt/torchopt.git
cd torchopt
# You may need `CONDA_OVERRIDE_CUDA` if conda fails to detect the NVIDIA driver (e.g. in docker or WSL2)
CONDA_OVERRIDE_CUDA=11.7 conda env create --file conda-recipe-minimal.yaml
conda activate torchopt
make install-editable # or run `pip3 install --no-build-isolation --editable .`
Changelog
See CHANGELOG.md.
Citing TorchOpt
If you find TorchOpt useful, please cite it in your publications.
@article{torchopt,
title = {TorchOpt: An Efficient Library for Differentiable Optimization},
author = {Ren, Jie and Feng, Xidong and Liu, Bo and Pan, Xuehai and Fu, Yao and Mai, Luo and Yang, Yaodong},
journal = {arXiv preprint arXiv:2211.06934},
year = {2022}
}
The Team
TorchOpt is a work by Jie Ren, Xidong Feng, Bo Liu, Xuehai Pan, Luo Mai, and Yaodong Yang.
License
TorchOpt is released under the Apache License, Version 2.0.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distributions
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file torchopt-0.7.2.tar.gz.
File metadata
- Download URL: torchopt-0.7.2.tar.gz
- Upload date:
- Size: 118.7 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.11.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
874a1d4db557186f339be0f1e1f57e7c4b79869b4e8b0bab2a9c2703c0af25ec
|
|
| MD5 |
20e888112d950f72516cbc8fcd0c5566
|
|
| BLAKE2b-256 |
1e6a029334ff3fdfb8fa269b38ef4f94e63f652687dbad522c43e571d4a786a1
|
File details
Details for the file torchopt-0.7.2-py3-none-any.whl.
File metadata
- Download URL: torchopt-0.7.2-py3-none-any.whl
- Upload date:
- Size: 167.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.11.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8baf8c18f6307eb184b0fc5a7ccf6acd03b0061eb46716e3bdeebbeb7b20e2e7
|
|
| MD5 |
ebe1e4dad8f2994009f2ef1f5f51d0f1
|
|
| BLAKE2b-256 |
8789e8f3e2cbb0e5e5b929efe47e7a5b3c390b370a6169dcd3776d043acb2cb4
|
File details
Details for the file torchopt-0.7.2-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.
File metadata
- Download URL: torchopt-0.7.2-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
- Upload date:
- Size: 691.3 kB
- Tags: CPython 3.11, manylinux: glibc 2.17+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.11.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
1f8d60f5ffe97bae88d7f037c6eb9ff5b0dac09e0b34763f4fddfe6b7fc02e39
|
|
| MD5 |
ca77472d4a2866c56f4114fcc49cd396
|
|
| BLAKE2b-256 |
2cedce0d96708fa87b311c0f3a2b0cbfcdcc6cb049b3a164383678f079ff7228
|
File details
Details for the file torchopt-0.7.2-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.
File metadata
- Download URL: torchopt-0.7.2-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
- Upload date:
- Size: 691.3 kB
- Tags: CPython 3.10, manylinux: glibc 2.17+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.11.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
1c73b5d2865493cdf2fa06e3fd40de8946def22ace25e915b1ba6fa7c3db9eb5
|
|
| MD5 |
1f8b65844c6c95834f3424694cea2b9c
|
|
| BLAKE2b-256 |
42ebd83c5dd938280e4f39edd9a0045892cc30ff1e2e081551c2a2f09691e8d6
|
File details
Details for the file torchopt-0.7.2-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.
File metadata
- Download URL: torchopt-0.7.2-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
- Upload date:
- Size: 691.5 kB
- Tags: CPython 3.9, manylinux: glibc 2.17+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.11.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
aec580d57af139fe491ebb2eedf7a40dcf62f3bf0203467b8276628d1f424f2b
|
|
| MD5 |
4ff28625dccb11d0b14139d1a51be8f0
|
|
| BLAKE2b-256 |
55d5367a1e6399c37bf0f2403e2184f9b644ea5590dd79cb0a69866e26a73185
|
File details
Details for the file torchopt-0.7.2-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.
File metadata
- Download URL: torchopt-0.7.2-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
- Upload date:
- Size: 691.3 kB
- Tags: CPython 3.8, manylinux: glibc 2.17+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.11.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
be90ae6e20a01f33e22da576c970343dfcb0bae9fc92bc4e6c17ba9328495e46
|
|
| MD5 |
3e49af098dfe41415404104f5df3bcbc
|
|
| BLAKE2b-256 |
fa957ad486baa6af989b0daf931050a98037211e77e4d25b2fbe6e24036c2a3e
|







