Training methodologies for Autoregressive Neural Emulators in JAX built on top of Equinox & Optax.

Project description
Learning Methodologies for Autoregressive Neural Emulators.





Installation • Quickstart • Background • Features • Taxonomy • License
Convenience abstractions using optax to train neural networks to
autoregressively emulate time-dependent problems taking care of trajectory
subsampling and offering a wide range of training methodologies (regarding
unrolling length and including differentiable physics).
Installation
Clone the repository, navigate to the folder and install the package with pip:
pip install trainax
Requires Python 3.10+ and JAX 0.4.13+. 👉 JAX install guide.
Documentation
The documentation is available at fkoehler.site/trainax.
Quickstart
Train a kernel size 2 linear convolution (no bias) to become an emulator for the 1D advection problem.
import jax
import jax.numpy as jnp
import equinox as eqx
import optax # pip install optax
import trainax as tx
CFL = -0.75
ref_data = tx.sample_data.advection_1d_periodic(
cfl = CFL,
key = jax.random.PRNGKey(0),
)
linear_conv_kernel_2 = eqx.nn.Conv1d(
1, 1, 2,
padding="SAME", padding_mode="CIRCULAR", use_bias=False,
key=jax.random.PRNGKey(73)
)
sup_1_trainer, sup_5_trainer, sup_20_trainer = (
tx.trainer.SupervisedTrainer(
ref_data,
num_rollout_steps=r,
optimizer=optax.adam(1e-2),
num_training_steps=1000,
batch_size=32,
)
for r in (1, 5, 20)
)
sup_1_conv, sup_1_loss_history = sup_1_trainer(
linear_conv_kernel_2, key=jax.random.PRNGKey(42)
)
sup_5_conv, sup_5_loss_history = sup_5_trainer(
linear_conv_kernel_2, key=jax.random.PRNGKey(42)
)
sup_20_conv, sup_20_loss_history = sup_20_trainer(
linear_conv_kernel_2, key=jax.random.PRNGKey(42)
)
FOU_STENCIL = jnp.array([1+CFL, -CFL])
print(jnp.linalg.norm(sup_1_conv.weight - FOU_STENCIL)) # 0.033
print(jnp.linalg.norm(sup_5_conv.weight - FOU_STENCIL)) # 0.025
print(jnp.linalg.norm(sup_20_conv.weight - FOU_STENCIL)) # 0.017
Increasing the supervised unrolling steps during training makes the learned stencil come closer to the numerical FOU stencil.
Background
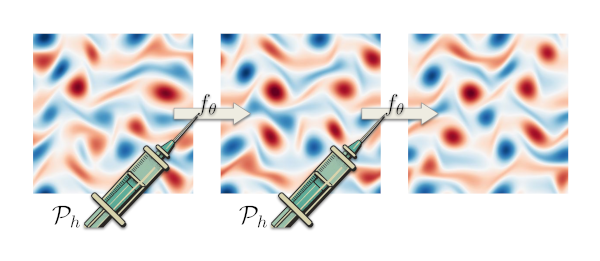
After the discretization of space and time, the simulation of a time-dependent partial differential equation amounts to the repeated application of a simulation operator $\mathcal{P}h$. Here, we are interested in imitating/emulating this physical/numerical operator with a neural network $f\theta$. This repository is concerned with an abstract implementation of all ways we can frame a learning problem to inject "knowledge" from $\mathcal{P}h$ into $f\theta$.
Assume we have a distribution of initial conditions $\mathcal{Q}$ from which we sample $S$ initial conditions, $u^{[0]} \propto \mathcal{Q}$. Then, we can save them in an array of shape $(S, C, *N)$ (with C channels and an arbitrary number of spatial axes of dimension N) and repeatedly apply $\mathcal{P}$ to obtain the training trajectory of shape $(S, T+1, C, *N)$.
For a one-step supervised learning task, we substack the training trajectory into windows of size $2$ and merge the two leftover batch axes to get a data array of shape $(S \cdot T, 2, N)$ that can be used in supervised learning scenario
$$ L(\theta) = \mathbb{E}{(u^{[0]}, u^{[1]}) \sim \mathcal{Q}} \left[ l\left( f\theta(u^{[0]}), u^{[1]} \right) \right] $$
where $l$ is a time-level loss. In the easiest case $l = \text{MSE}$.
Trainax supports way more than just one-step supervised learning, e.g., to
train with unrolled steps, to include the reference simulator $\mathcal{P}_h$ in
training, train on residuum conditions instead of resolved reference states, cut
and modify the gradient flow, etc.
Features
- Wide collection of unrolled training methodologies:
- Supervised
- Diverted Chain
- Mix Chain
- Residuum
- Based on JAX:
- One of the best Automatic Differentiation engines (forward & reverse)
- Automatic vectorization
- Backend-agnostic code (run on CPU, GPU, and TPU)
- Build on top and compatible with Equinox
- Batch-Parallel Training
- Collection of Callbacks
- Composability
Acknowledgements
Citation
This package was developed as part of the APEBench paper (accepted at Neurips 2024), we will soon add the citation here.
Funding
The main author (Felix Koehler) is a PhD student in the group of Prof. Thuerey at TUM and his research is funded by the Munich Center for Machine Learning.
License
MIT, see here
fkoehler.site · GitHub @ceyron · X @felix_m_koehler · LinkedIn Felix Köhler
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file trainax-0.0.2.tar.gz.
File metadata
- Download URL: trainax-0.0.2.tar.gz
- Upload date:
- Size: 29.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/5.1.1 CPython/3.12.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
3c7eeeb94e351db7ff0b036b1c1fb6f78ddc25ab72d6c1afe69547cbefa70ca8
|
|
| MD5 |
0c85bc6358373e8781105e8d1ed9505b
|
|
| BLAKE2b-256 |
95e4ba802dff60d93f8701f9910546c848356b34816d67993d990efb0e5a7faf
|
File details
Details for the file trainax-0.0.2-py3-none-any.whl.
File metadata
- Download URL: trainax-0.0.2-py3-none-any.whl
- Upload date:
- Size: 41.8 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/5.1.1 CPython/3.12.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
402a798beb17534c61ca383ce354a2325c395e8fe6125603a73cdc85f30b8f0c
|
|
| MD5 |
6b611b99644ff0771c7401af1435d2e1
|
|
| BLAKE2b-256 |
d3f9747a4d67dcbb0e6925a0902abf9239ba9f80aeb672501db416459e9c77ec
|







