A tool for indexing and searching YouTube transcripts.

Project description
Transcripter



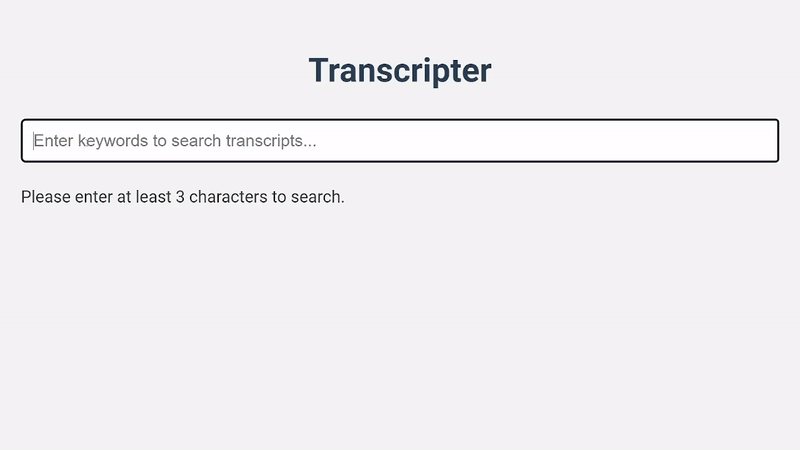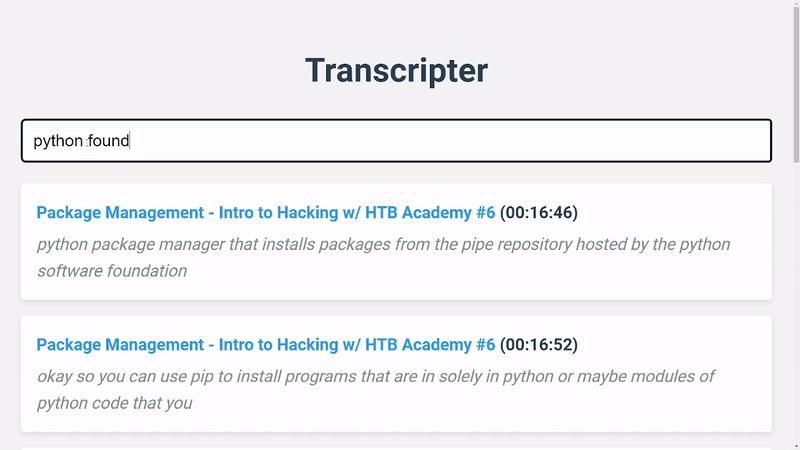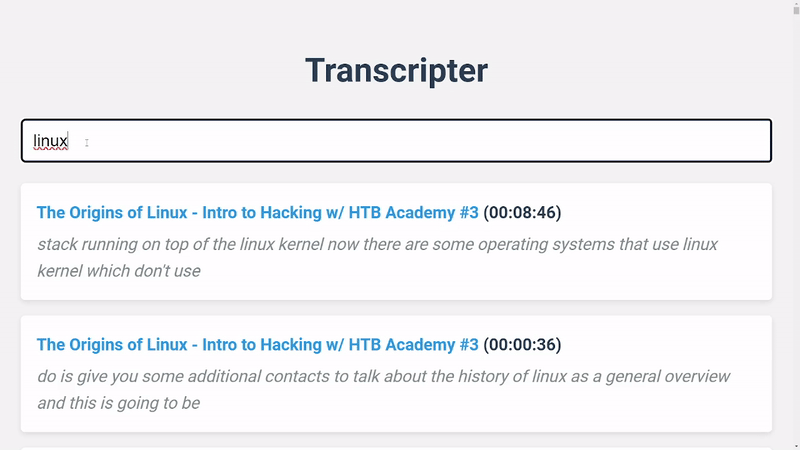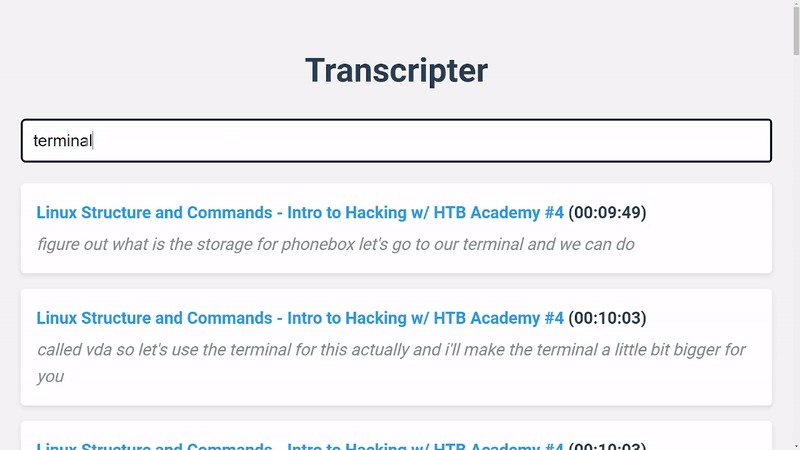
Transcripter is a tool for indexing and searching YouTube video transcripts. It makes use of the YouTube Data API to fetch video details and transcripts, and collates and stores the transcript chunks in Redis for efficient full-text search.
Transcripter's main purpose is to provide a simple way to add transcript-search functionality to your application. Inspired by (but unrelated to) https://ippsec.rocks/.
Structure
transcripter/: Main packagecore/: Core functionalityredis_manager.py: Manages Redis operationsyoutube_manager.py: Handles YouTube API interactions
services/: Service layerindexing_service.py: Manages the indexing processsearch_service.py: Manages the search process
config.py: Configuration managementlogs.py: Logging management
examples/: Example applicationsbasic/: Basic exampleapp.py: Simple application demonstrating usage
index-config.yml: Configuration file for indexing. Used by the example app.docker-compose.yml: Docker compose file for the example app.
How It Works
- The
IndexingServiceperiodically fetches video details and transcripts from configured YouTube playlists, channels, or individual videos. - Transcripts are processed and stored in Redis using the
RedisManager. - The
YouTubeManagerhandles interactions with the YouTube API. - Indexed data can be searched efficiently using Redis's full-text search capabilities.
Installation
make install
or
pip3 install git+https://github.com/0xRy4n/transcripter
Note: Transcripter requires a Redis Stack server to run. It's recommended to use the official Docker image like so:
docker run -d --name redis-stack-server -p 6379:6379 redis/redis-stack-server:latest`
You can run the Redis Stack either locally or remote, depending on your preference.
Configuration
Environment Variables
Set the following environment variables:
YOUTUBE_API_KEY: Your YouTube API keyREDIS_HOST: Redis server hostREDIS_PORT: Redis server portREDIS_PASSWORD: Redis server password (if applicable)REDIS_INDEX: Name of the Redis index to useTRANSCRIPTER_LOG_LEVEL: Log level (DEBUG, INFO, WARNING, ERROR, CRITICAL)
Indexing Configuration
Configure the indexing process in your application by specifying a indexing-config.yml file like so:
# Change me
sources:
playlists:
# playlist id
- PLlkHl5i0GaAlBvAhi9R7S4vQ0IhR3ePCU
channels:
- # channel id
videos:
- # video id
indexing:
interval: 3600 # Reindex every hour
You can then pass the path to this file in to the Config object:
config = Config(config_path='path/to/indexing-config.yml')
By default, it will search for a file called indexing-config.yml in the root directory of the repository (one directory up from the transcripter directory).
Alternatively, you can simply instantiate Config without any arguments, and set each property directly:
from transcripter.config import Config
config = Config()
config.playlists = ['playlist_id1', 'playlist_id2']
config.channels = ['channel_id1', 'channel_id2']
config.videos = ['video_id1', 'video_id2']
config.indexing_interval = 3600 # Indexing interval in seconds
Starting the Indexing Service
from transcripter.services.indexing_service import IndexingService
indexing_service = IndexingService(config)
Indexing your videos is easy.
indexing_service.index_all()
Once a video has been indexed, it will not be indexed again, and it's transcript won't be pulled on successive runs.
You'll likely want to run the indexing service periodically as a background job. It is up to you to decide how you would like to implement this.
Searching
You can search the indexed data using the SearchService class.
from transcripter.services.search_service import SearchService
search_service = SearchService(config)
You can then search for videos by title:
search_service.search('search query')
It will return a list of stored transcript chunks in the following format:
[
{
"snippet": "directory don't worry about it too much it's not going to be on the test there's not going to be a test but if there were",
"start_time": 300.56,
"timecode": "00:05:00",
"video_id": "_haJQY-Y70E",
"video_title": "Linux Structure and Commands - Intro to Hacking w/ HTB Academy #4"
},
{
"snippet": "directory don't worry about it too much it's not going to be on the test there's not going to be a test but if there were",
"start_time": 300.56,
"timecode": "00:05:00",
"video_id": "_haJQY-Y70E",
"video_title": "Linux Structure and Commands - Intro to Hacking w/ HTB Academy #4"
}
]
Example Web App
A fully functional example web app is included in the examples/basic directory. It is a simple web app that allows you to search for videos by title. It is built with Flask and uses Bootstrap for the frontend.
You can change the index-config.yml file in the root of the repository to configure the playlists, channels, and videos you want to index.
Additionally, you can opt to either create a .env file in the root of the repository and set the environment variables directly, or set them in your operating system's environment variables.
The example app is containerized with Docker, making it simple to run:
docker compose up
Alternatively, you can run the app without Docker by installing the dependencies and running the app.py directly:
First you'll need to run Redis Stack in a docker container:
docker run -d --name redis-stack-server -p 6379:6379 redis/redis-stack-server:latest
Then install the dependencies and run the app:
pip3 install -e .
python3 examples/basic/app.py
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file transcripter-0.1.0.tar.gz.
File metadata
- Download URL: transcripter-0.1.0.tar.gz
- Upload date:
- Size: 33.3 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.1 CPython/3.9.19
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
7418e5dbc8217ac3a20d3af98847c8d273b2b9395ce674ee8ee0a088e73b9aa5
|
|
| MD5 |
07b60f4b1fbf2bbf3e44278eabab6bf6
|
|
| BLAKE2b-256 |
4bee34b645f8607a104575d70c94c8c34a9343c013a55efc0b8b4af8d0a0ee98
|
File details
Details for the file transcripter-0.1.0-py3-none-any.whl.
File metadata
- Download URL: transcripter-0.1.0-py3-none-any.whl
- Upload date:
- Size: 14.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.1 CPython/3.9.19
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
eeb242eecec92f2c728e49f0ebb0f0fb72e3933534e8ceb4eeb94f80c4eaeb21
|
|
| MD5 |
201a10be7065df97e3d61470a9810c18
|
|
| BLAKE2b-256 |
70906274e267b318cc39ebb6ee4f5f880e77c8b7e6703dcb6db9b98fadef4f59
|







