A pytorch implementation of transformer encoder

Project description
Transformer Encoder

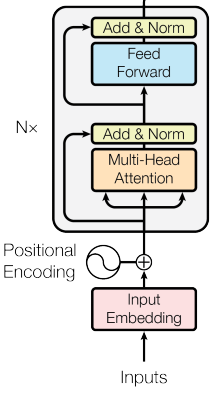
Examples
Quickstart
import torch
from transformer_encoder import TransformerEncoder
from transformer_encoder.utils import PositionalEncoding
# Model
encoder = TransformerEncoder(d_model=512, d_ff=2048, n_heads=8, n_layers=6, dropout=0.1)
# Input embeds
input_embeds = torch.nn.Embedding(num_embeddings=6, embedding_dim=512)
pe_embeds = PositionalEncoding(d_model=512, dropout=0.1, max_len=5)
encoder_input = torch.nn.Sequential(input_embeds, pe_embeds)
# Input data (zero-padding)
batch_seqs = torch.tensor([[1,2,3,4,5], [1,2,3,0,0]], dtype=torch.long)
mask = batch_seqs.ne(0)
# Run model
out = encoder(encoder_input(batch_seqs), mask)
Using the built-in warming up optimizer
import torch.optim as optim
from transformer_encoder.utils import WarmupOptimizer
model = ...
base_optimizer = optim.Adam(model.parameters(), lr=1e-3)
optimizer = WarmupOptimizer(base_optimizer, d_model=512, scale_factor=1, warmup_steps=100)
optimizer.zero_grad()
loss = ...
loss.backward()
optimizer.step()
Install from PyPI
Requires python 3.5+, pytorch 1.0.0+
pip install transformer_encoder
API
transformer_encoder.TransformerEncoder(d_model, d_ff, n_heads=1, n_layers=1, dropout=0.1)
d_model: dimension of each word vectord_ff: hidden dimension of feed forward layern_heads: number of heads in self-attention (defaults to 1)n_layers: number of stacked layers of encoder (defaults to 1)dropout: dropout rate (defaults to 0.1)
transformer_encoder.TransformerEncoder.forward(x, mask)
x (~torch.FloatTensor): shape (batch_size, max_seq_len, d_model)mask (~torch.ByteTensor): shape (batch_size, max_seq_len)
transformer_encoder.utils.PositionalEncoding(d_model, dropout=0.1, max_len=5000)
d_model: same as TransformerEncoderdropout: dropout rate (defaults to 0.1)max_len: max sequence length (defaults to 5000)
transformer_encoder.utils.PositionalEncoding.forward(x)
x (~torch.FloatTensor): shape (batch_size, max_seq_len, d_model)
transformer_encoder.utils.WarmupOptimizer(base_optimizer, d_model, scale_factor, warmup_steps)
base_optimizer (~torch.optim.Optimzier): e.g. adam optimzierd_model: equals d_model in TransformerEncoderscale_factor: scale factor of learning ratewarmup_steps: warming up steps
Contribution
Any contributions are welcome!
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file transformer_encoder-0.0.3.tar.gz.
File metadata
- Download URL: transformer_encoder-0.0.3.tar.gz
- Upload date:
- Size: 6.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/2.0.0 pkginfo/1.5.0.1 requests/2.24.0 setuptools/49.2.0.post20200714 requests-toolbelt/0.9.1 tqdm/4.47.0 CPython/3.8.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
df6151470817f153849043bee241b920163345364e3d621ab7d92087a071c55a
|
|
| MD5 |
7b3d587d6e8d815983bf63e4d0500f71
|
|
| BLAKE2b-256 |
68deaa92453adf1b2a4a94dc0c0fa4df70bdaecd3f0cfc0cb85814de287ef9c8
|
File details
Details for the file transformer_encoder-0.0.3-py3-none-any.whl.
File metadata
- Download URL: transformer_encoder-0.0.3-py3-none-any.whl
- Upload date:
- Size: 9.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/2.0.0 pkginfo/1.5.0.1 requests/2.24.0 setuptools/49.2.0.post20200714 requests-toolbelt/0.9.1 tqdm/4.47.0 CPython/3.8.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8da07f3c35aab23c271b1f7e13dd6596cee4b32277b0bd0d3136293b2891d08c
|
|
| MD5 |
0c6dec48d6d393944cdded7b20fbf95a
|
|
| BLAKE2b-256 |
c739e957723b095616a72e974bf27d2365a5d7f17ee0254f6ec0b9e9c8bc1781
|







