Data utility code for Mongoose Traveller TTRPG.

This project has been archived.
The maintainers of this project have marked this project as archived. No new releases are expected.
Project description
Python library and assorted tools for assisting with the Mongoose Traveller TTRPG system.
The extracted data is not for redistribution, as it is almost certainly subject to copyright (I am not a lawyer - but it’s safer to assume caution over distribution). This utility (and its output) is intended as an aid to those who legally own a copy of the Mongoose Traveller materials, and wish to make use of the data for their own direct purposes. It is the sole responsibility of the user of this program to use the extracted data in a manner that respects the publisher’s IP rights.
The purpose of this tool is to extract the data for usage by the legal owner of a copy of the original materal that it was extracted from.
Reporting issues
Report any problems you encounter or feature requests to https://github.com/huin/travdata/issues.
Please include:
information about which operating system you are using the program on,
steps to reproduce the problem,
what you expected to happen,
what actually happened.
Ideally include text output of any error messages from the program, and/or screenshots to demonstrate the problem if text output is not relevant.
Usage
This package is primarily intended for the provided CLI tools, but API access is also possible.
Requirements
Java Runtime Environment (JRE) must be installed. This is required by the code that extracts tables from PDFs. If not already installed, get it from java.com.
Installation
Prebuilt
You can download an executable version of the application for your platform at github.com/huin/travdata/releases. Currently executables are only generated for Linux and Windows, and seem to work on the author’s machines. A MacOS binary is also released, but it has not been tested.
Once downloaded, extract the .zip file to a suitable location. You can most easily use the command line interface from the directory that it was unpacked to.
You may also wish to make a shortcut to the travdata_gui executable, but it can also be run directly from the unzipped directory.
Pip install
This may work on platforms that have no prebuilt executable. Assuming that you have Python 3.11 or later installed, and you are running something similar to Linux, perform the following commands to install into a Python virtual environment:
mkdir travdata
cd travdata
python -m venv venv
source ./venv/bin/activateYou will also need to download a copy of the source code, in order to get a copy of the configuration. Visit releases, pick a recent release, and download the “Source code” zip file. Extract the config directory from it, and place it in the travdata directory you created earlier, such that the travdata directory contains two subdirectories:
config
venv
At this point, you can run python -m travdata.cli.cli instead of running travdata_cli from other examples.
GUI travdata_gui
The GUI binary provides a user interface to aid in extracting CSV files, similarly to travdata_cli extractcsvtables.
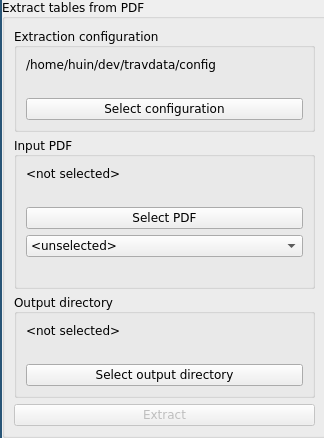
“Extraction configuration” selects the configuration for extraction from PDFs. It should detect its own configuration automatically. If it does not, click “Select configuration” and select the _internal/config directory that should have come with the download of the program.
“Input PDF” selects the PDF to extract from, and the book that that PDF corresponds to.
Note: only a very limited number of books are supported - at the time of writing, only the Core Rulebook 2022 update.
Click “Select PDF” and choose the input PDF file.
If selecting a PDF file did not automatically choose the correct book (based on its filename), choose it from the drop-down box below “Select PDF”.
“Output directory” selects a directory to write the extracted CSV data into. Choose an empty directory.
“Extract” should now be enabled. Click it to start extraction. It will open a window to display progress and any errors.
Close the extraction window once extraction is completed (and if you no longer need the output).
Note: the program will not extract the same table again if it sees that the CSV file is present in the output directory. If you wish to force re-extraction, delete some or all files from the output directory.
CLI travdata_cli extractcsvtables
This tool extracts CSV files from tables in the given PDF, based on the given configuration files that specifies the specifics of how those tables can be turned into useful CSV data. As such, it only supports extraction of tables from known PDF files, where the individual tables have been configured.
The general form of the command is:
travdata_cli extractcsvtables BOOK_NAME INPUT.PDF OUT_DIRWhere:
- BOOK_NAME
is the identifier for the book to extract tables from. This selects the correct book’s configuration from the files that . Use travdata_cli listbooks to list accepted values for this argument.
- INPUT.PDF
is the path to the PDF file to read tables from.
- OUT_DIR
is the path to a (potentially not existing) directory to output the resulting CSV files. This will result in containing a directory and file structure that mirrors that in CONFIG_DIR, but will contain .csv rather than .tabula-template.json files.
At the present time, the only supported input PDF file is the Mongoose Traveller Core Rulebook 2022, and not all tables are yet supported for extraction.
Example:
travdata_cli extractcsvtables \
core_rulebook_2022 path/to/update_2022_core_rulebook.pdf \
path_to_output_dirDeveloping
See `development.adoc <https://github.com/huin/travdata/blob/main/development.adoc>`__ for more information on developing and adding more tables to the configuration.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file travdata-0.6.2.tar.gz.
File metadata
- Download URL: travdata-0.6.2.tar.gz
- Upload date:
- Size: 51.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/1.8.3 CPython/3.10.12 Linux/6.5.0-1025-azure
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
76f4ca8127e7c79b99886934b5c04dc7eb02ecbaec0a39538b6ea5c3bbbbef6e
|
|
| MD5 |
761871abfa9d8c525e6f9471590d8739
|
|
| BLAKE2b-256 |
3239a51e5a1f52dd8c44f292d81f1816abcdfccea24856ee6f029f80210cdc27
|
File details
Details for the file travdata-0.6.2-py3-none-any.whl.
File metadata
- Download URL: travdata-0.6.2-py3-none-any.whl
- Upload date:
- Size: 65.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/1.8.3 CPython/3.10.12 Linux/6.5.0-1025-azure
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
53a54bbc1365ec47f07e16f6ee0089df34337587b9cdb7be4b18a0970e2f6639
|
|
| MD5 |
cf588073ac4960f798112bc647a7a1b2
|
|
| BLAKE2b-256 |
15ea3ece8adeb6a85a71c3a4b0556fdd1daa87fb607c92fb719f83e08f9e65a0
|







