TrimKV: token retention for memory-bounded key-value eviction
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
TrimKV: Token Retention for Memory-Bounded Key-Value Eviction

🚀 Updates
- 🆕 DBTrimKV — dynamic-budget variant powered by
PagedTrimKVCache. A single global KV budget is shared across all layers and heads and reallocated on the fly at every step, instead of fixing a per-head budget upfront. The retention gate's final projection is tied across layers and heads, and the runtime usesPagedTrimKVCache— a paged-attention-style cache where blocks are dynamically (re)assigned to the heads that currently need them. The result: significantly outperforms TrimKV at low KV budgets, and matches or even beats the full KV cache — without any per-head tuning. Same training surface as TrimKV — just two env-var flips (RETENTION_GATE=rg10,GLOBAL_CAPACITY=True). Public LLM checkpoints: - 🆕 First VLM release — TrimKV / DBTrimKV go multimodal. Full Qwen3-VL / Qwen2.5-VL / LLaVA support with end-to-end training recipes in
train/vlm/and an evaluation harness inexperiments/lmms-eval/andexperiments/mmdu/. Auto-downloading data prep for R1-Onevision, M4-Instruct, LLaVA-Video-178K, MMDU, and OpenR1-Math-220k undertrain/vlm/scripts/data/. Public VLM checkpoints (DBTrimKV): - Codebase refactor for transformers v4.57.0. This release freezes the codebase at a version close to what produced the paper results, so all reported numbers are reproducible. If you hit issues, please open a GitHub issue.
What is TrimKV?
An efficient and learnable key–value eviction strategy designed to improve the efficiency of large language models (LLMs) in long-horizon inference.
Imagine what if our brain worked like a transformer:

This is because it tried to remember every single detail (token) forever. TrimKV lets your model forget the parts that aren't very important so it doesn't melt its VRAM. Don't let the brain (or GPU) explode. 💥🧠
The core idea behind TrimKV is to learn the intrinsic importance of each key–value pair at creation time — what we call token retention — and then decay this importance exponentially over time to mimic standard inference running with eviction.
The retention score is query-agnostic and captures the long-term utility of tokens. This is different from attention scores, which are query-dependent: they capture short-term utility for predicting the next token, are recomputed at every step, and are highly dependent on the transient decoding state.
TrimKV vs DBTrimKV
Both variants share the same training loop, datasets, and loss surface. They differ in how the KV budget is allocated, which retention-gate parameterisation is used, and which cache class powers inference:
| TrimKV | DBTrimKV (new) | |
|---|---|---|
| Budget semantics | per-layer, per-head local budget M_local = M |
single global budget M_global = M × num_layers × num_heads, redistributed dynamically across layers/heads |
| Gate parameterisation | independent retention gate per head | final projection of the gate tied across layers and heads |
| Inference cache | TrimKVCache (fixed per-head allocation) |
PagedTrimKVCache — paged-attention-style blocks dynamically (re)assigned to heads that currently need capacity |
RETENTION_GATE flag |
rg |
rg10 |
GLOBAL_CAPACITY flag |
False |
True |
DBTrimKV's combination of the global retention gate with PagedTrimKVCache lets it run at much tighter average budgets while preserving accuracy — heads with high retention demand temporarily borrow capacity from heads with low demand on a per-step basis. See train/llm/README.md and train/vlm/README.md for the full training surface, and src/trimkv/cache_utils.py for the cache implementations.
Why TrimKV?
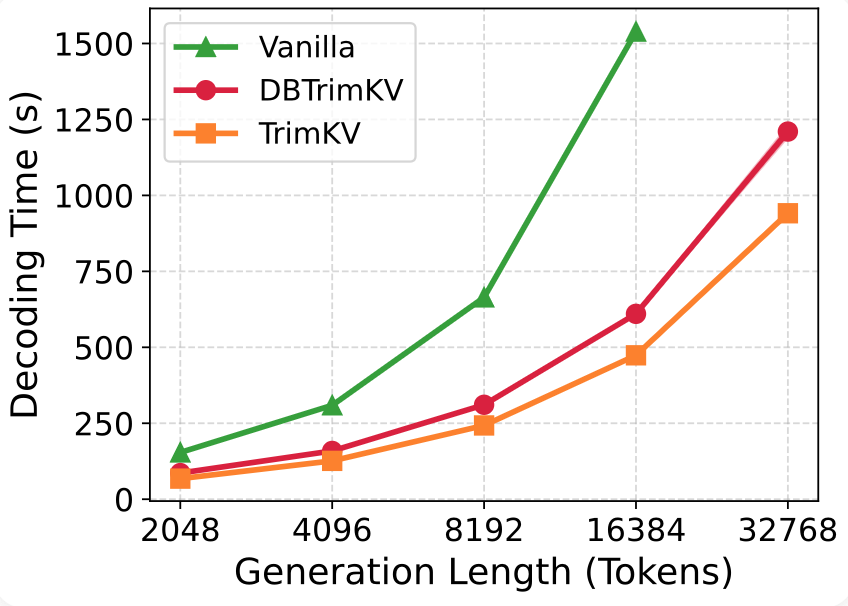
It's fast
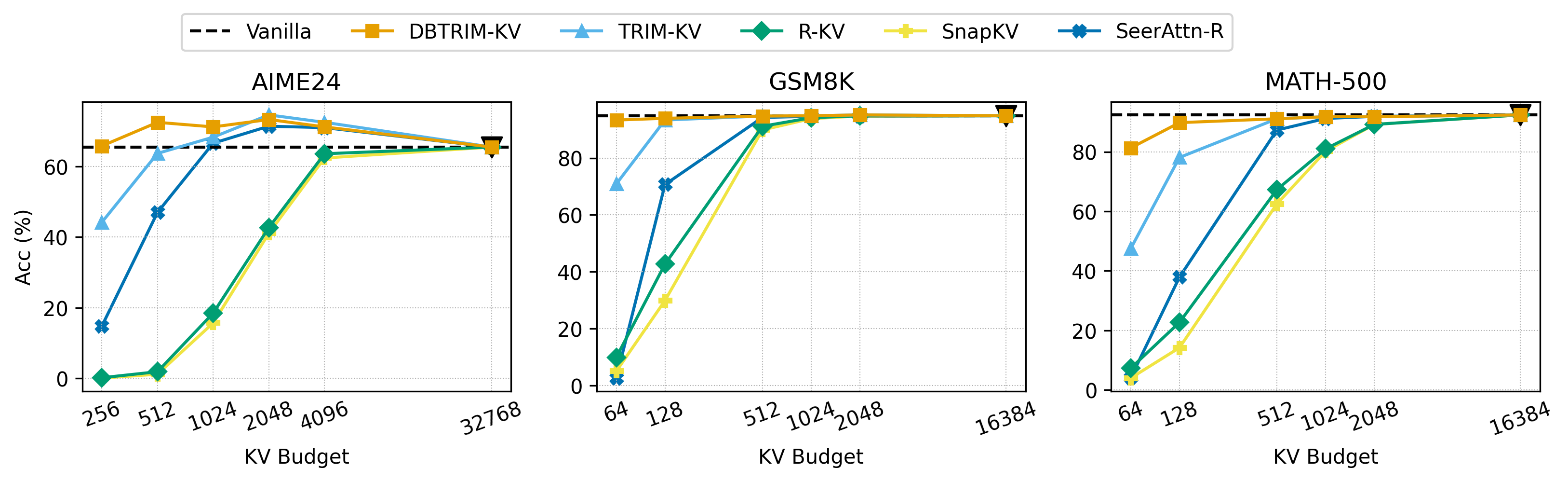
It's smart
Getting started
Requirements
- Python 3.11 or higher (tested with 3.12)
- PyTorch 2.7.0 or higher (tested with 2.8.0)
- FlashAttention 2.7.2.post1 or higher (tested with 2.8.0)
- Transformers 4.57.1
pip install -r requirements.txt
This is a minimal set of requirements for training. Additional dependencies may be needed for individual experiments; see examples/env.yaml for a full reproducible environment.
Installation
pip install trimkv
Quick start
import torch
from trimkv.models.qwen3 import TrimKVQwen3ForCausalLM
from trimkv.cache_utils import TrimKVCache, PagedTrimKVCache
from transformers import AutoTokenizer
# Pick any TrimKV / DBTrimKV checkpoint from the table below
model_path = "ngocbh/DBTrimKV-Qwen3-4B-Math"
download_from = "huggingface" # also: "wandb", "local"
model = TrimKVQwen3ForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
load_trimkv_weights=True,
download_from=download_from,
use_cache=True,
device_map="cuda",
)
model.config._attn_implementation = "flash_attention_2"
tokenizer = AutoTokenizer.from_pretrained(
model.config.base_model, use_fast=True, padding_side="left"
)
# PagedTrimKVCache is the inference-time cache used by DBTrimKV. It allocates a
# global pool of blocks and (re)assigns them to heads on the fly so heads with
# high retention demand can borrow capacity from heads with low demand.
# For (non-DB) TrimKV, swap in TrimKVCache(memory_size=..., buffer_size=..., device="cuda").
past_key_values = PagedTrimKVCache(
num_layers=model.config.num_hidden_layers,
num_heads=model.config.num_key_value_heads,
max_seq_len=32768,
memory_size=128,
num_blocks_ratio=1.0,
buffer_size=32,
strategy="fixed_budget",
device="cuda",
)
# Use model.generate as normal — pass past_key_values to enable TrimKV eviction.
For a runnable end-to-end example see examples/test_qwen3.py. VLM checkpoints use TrimKVQwen3VLForConditionalGeneration from trimkv.models.qwen3_vl and the same PagedTrimKVCache, but read model.config.text_config.num_hidden_layers / num_key_value_heads instead.
Training
- LLMs (Qwen3, Qwen2, Llama, Phi-3):
train/llm/— DeepSpeed + 🤗 Trainer. Two recipes (train_trimkv_long.shfor long-context KL distillation,train_trimkv_math.shfor R1-style math reasoning). Same recipes train both TrimKV and DBTrimKV — flipRETENTION_GATE/GLOBAL_CAPACITYto switch. - VLMs (Qwen2.5-VL, Qwen3-VL, LLaVA):
train/vlm/— same harness extended for visual data. Auto-downloading data prep for R1-Onevision, M4-Instruct, LLaVA-Video-178K, MMDU, and OpenR1-Math-220k undertrain/vlm/scripts/data/.
Experiments
Per-benchmark evaluation harnesses live in experiments/ — see experiments/README.md for the full index.
- Baselines: TrimKV, DBTrimKV, R-KV, SeerAttention, SnapKV, StreamingLLM, H2O, KeyDiff, LocRet.
- Long-horizon generation: GSM8K, MATH-500, AIME-24, LongProc.
- Long-context understanding: SCBench, LongMemEval, LongBench, LongBench v2.
- Multimodal: lmms-eval task suite (mathvision_testmini, video_mmmu_*, mmmu_pro_vision, videomme, videomathqa_mcq, mmstar) plus MMDU.
Released models
LLM checkpoints
| Base Model | Variant | Checkpoint | Training Datasets | Max Context Len | Training $M$ |
|---|---|---|---|---|---|
| Qwen3-1.7B | TrimKV | TrimKV-Qwen3-1.7B-Math | OpenR1-Math-220k | 16K | 512 |
| Qwen3-4B | TrimKV | TrimKV-Qwen3-4B-Math | OpenR1-Math-220k | 16K | 512 |
| Qwen3-8B | TrimKV | TrimKV-Qwen3-8B-Math | OpenR1-Math-220k | 16K | 512 |
| Qwen3-14B | TrimKV | TrimKV-Qwen3-14B-Math | OpenR1-Math-220k | 16K | 512 |
| Qwen3-4B-Instruct-2507 | TrimKV | TrimKV-Qwen3-4B-Instruct-2507 | Synth-Long, BookSum, Buddhi | 128K | 4096 |
| Phi-3-mini-128k-instruct | TrimKV | TrimKV-Phi-3-mini-128k-instruct | LongAlpaca | 128K | 2048 |
| Qwen3-4B | DBTrimKV 🆕 | DBTrimKV-Qwen3-4B-Math | OpenR1-Math-220k | 32K | 128 |
| Qwen3-4B-Instruct-2507 | DBTrimKV 🆕 | DBTrimKV-Qwen3-4B-Instruct-2507 | Synth-Long, BookSum, Buddhi | 128K | 512 |
VLM checkpoints — first multimodal release 🆕
| Base Model | Variant | Checkpoint | Training Datasets | Max Context Len | Training $M$ |
|---|---|---|---|---|---|
| Qwen3-VL-8B-Thinking | DBTrimKV | DBTrimKV-Qwen3-VL-8B-Thinking | R1-Onevision, M4-Instruct, LLaVA-Video-178K, MMDU, OpenR1-Math-220k | 32K | 32 |
| Qwen3-VL-4B-Instruct | DBTrimKV | DBTrimKV-Qwen3-VL-4B-Instruct | M4-Instruct, MMDU | 32K | 32 |
Happy to mention here if you have your own checkpoints for different settings.
Acknowledgements
A large portion of this repository is adapted from or built on top of the following projects:
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file trimkv-0.1.5.tar.gz.
File metadata
- Download URL: trimkv-0.1.5.tar.gz
- Upload date:
- Size: 111.2 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
96d4efce664f1e0efc7340749823a92d885252d306e979f062eecd9c8e89aaa8
|
|
| MD5 |
4988d7194bfefc318693e0ca0ff4dc07
|
|
| BLAKE2b-256 |
3c3810ebdfe10ed7dcdc1c97be1ddb13ccf51469e7a436e65d56975a10780465
|
Provenance
The following attestation bundles were made for trimkv-0.1.5.tar.gz:
Publisher:
publish.yml on ngocbh/trimkv
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
trimkv-0.1.5.tar.gz -
Subject digest:
96d4efce664f1e0efc7340749823a92d885252d306e979f062eecd9c8e89aaa8 - Sigstore transparency entry: 1485469888
- Sigstore integration time:
-
Permalink:
ngocbh/trimkv@9e2c60a6f0c80a5a20f9a34ff68fed0da474aa95 -
Branch / Tag:
refs/tags/v0.1.5 - Owner: https://github.com/ngocbh
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@9e2c60a6f0c80a5a20f9a34ff68fed0da474aa95 -
Trigger Event:
release
-
Statement type:
File details
Details for the file trimkv-0.1.5-py3-none-any.whl.
File metadata
- Download URL: trimkv-0.1.5-py3-none-any.whl
- Upload date:
- Size: 117.7 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8a3f8ea3e495292056d617b4f95c94fe3cb8f94c46a45ebcde19943423cea453
|
|
| MD5 |
652d9fe35d45a10b83919aadc4a4c7e4
|
|
| BLAKE2b-256 |
54de69826ce4e8c93f237bc645b1e1c13f4ff218d62b1501e7ae36a14a346144
|
Provenance
The following attestation bundles were made for trimkv-0.1.5-py3-none-any.whl:
Publisher:
publish.yml on ngocbh/trimkv
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
trimkv-0.1.5-py3-none-any.whl -
Subject digest:
8a3f8ea3e495292056d617b4f95c94fe3cb8f94c46a45ebcde19943423cea453 - Sigstore transparency entry: 1485469952
- Sigstore integration time:
-
Permalink:
ngocbh/trimkv@9e2c60a6f0c80a5a20f9a34ff68fed0da474aa95 -
Branch / Tag:
refs/tags/v0.1.5 - Owner: https://github.com/ngocbh
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@9e2c60a6f0c80a5a20f9a34ff68fed0da474aa95 -
Trigger Event:
release
-
Statement type:







