Library to systematically track and evaluate LLM based applications.

Project description








🦑 Welcome to TruLens!

Don't just vibe-check your LLM app! Systematically evaluate and track your LLM experiments with TruLens. As you develop your app including prompts, models, retrievers, knowledge sources and more, TruLens is the tool you need to understand its performance.
Fine-grained, stack-agnostic instrumentation and comprehensive evaluations help you to identify failure modes & systematically iterate to improve your application.
Read more about the core concepts behind TruLens including Feedback Functions, The RAG Triad, and Honest, Harmless and Helpful Evals.
TruLens in the development workflow
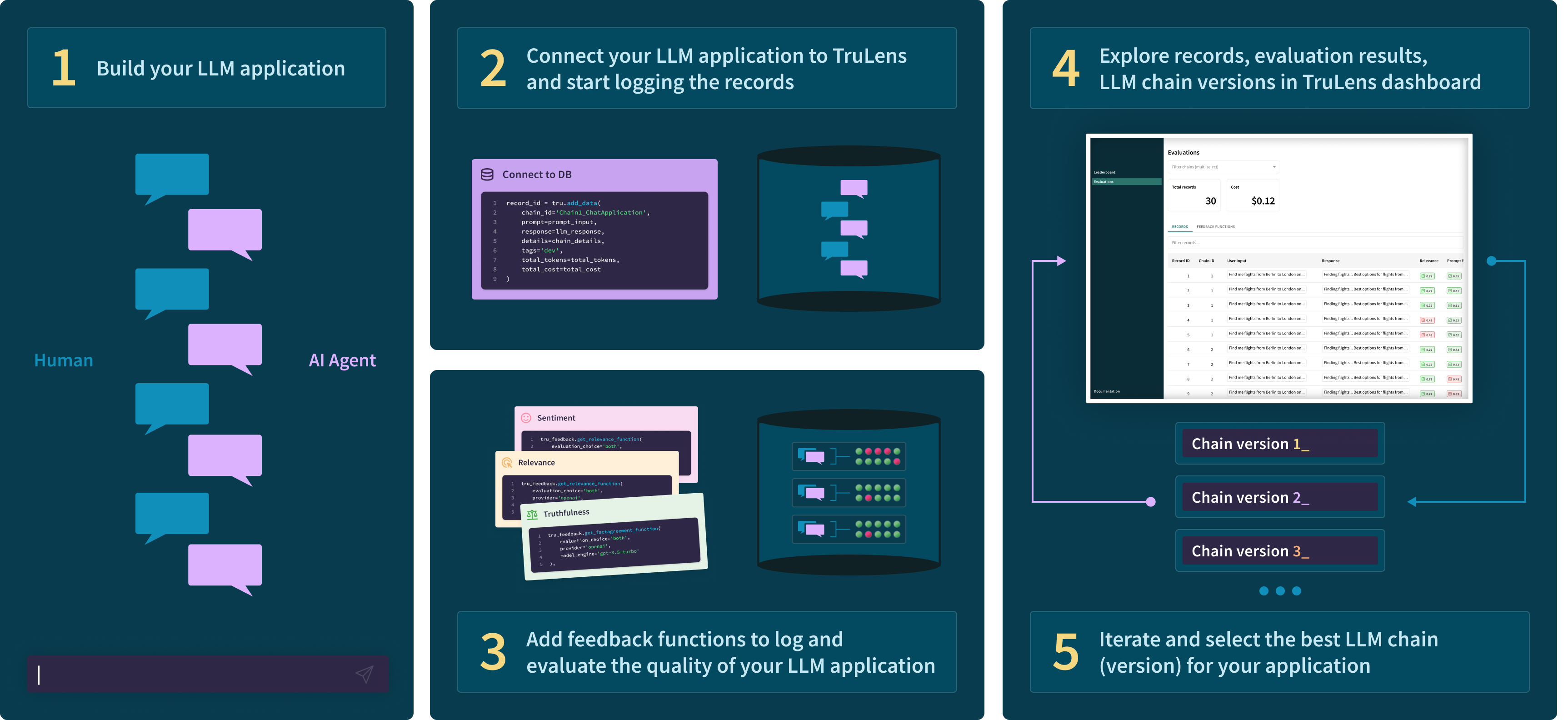
Build your first prototype then connect instrumentation and logging with TruLens. Decide what feedbacks you need, and specify them with TruLens to run alongside your app. Then iterate and compare versions of your app in an easy-to-use user interface 👇
Installation and Setup
Install the trulens pip package from PyPI.
pip install trulens
Quick Usage
Walk through how to instrument and evaluate a RAG built from scratch with TruLens.
💡 Contributing & Community
Interested in contributing? See our contributing guide for more details.
The best way to support TruLens is to give us a ⭐ on GitHub and join our discourse community!
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file trulens-2.6.0.tar.gz.
File metadata
- Download URL: trulens-2.6.0.tar.gz
- Upload date:
- Size: 4.2 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.1 CPython/3.11.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
49f430863f95022e1ae1b1693d8ad5034bc52c7bc2c58ea58aab17a6f43f7620
|
|
| MD5 |
1dfe52323ee254a1e8d57b89802ed8b9
|
|
| BLAKE2b-256 |
e3cf7ab93e2589c76b079536703cdc4a4014f5f02d1432c79719e171fcc8ec0d
|
File details
Details for the file trulens-2.6.0-py3-none-any.whl.
File metadata
- Download URL: trulens-2.6.0-py3-none-any.whl
- Upload date:
- Size: 3.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.1 CPython/3.11.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a960766fc6b66d55076409f15928060c82788909b2b93d4905be04caa33173c8
|
|
| MD5 |
0af292bb734184bdf58c88eea9af1015
|
|
| BLAKE2b-256 |
3cb6b1099d0aedad30d74c99df49916eacb077fdf82f35033fba05f415a17124
|







