Guidelines for Augmentation Selection in Contrastive Learning for Time Series Classification

Project description
TS-Contrastive-Augmentation-Recommendation


Recommend effective augmentations for self-supervised contrastive learning tailored for your time series dataset.
Code for paper: Guidelines for Augmentation Selection in Contrastive Learning for Time Series Classification
Self-supervised contrastive learning has become a key technique in deep learning, particularly in time series analysis, due to its ability to learn meaningful representations without explicit supervision. Augmentation is a critical component in contrastive learning, where different augmentations can dramatically impact performance, sometimes influencing accuracy by over 30%. However, the selection of augmentations is predominantly empirical which can be suboptimal, or grid searching that is time-consuming. In this paper, we establish a principled framework for selecting augmentations based on dataset characteristics such as trend and seasonality. Specifically, we construct 12 synthetic datasets incorporating trend, seasonality, and integration weights. We then evaluate the effectiveness of 8 different augmentations across these synthetic datasets, thereby inducing generalizable associations between time series characteristics and augmentation efficiency. Additionally, we evaluated the induced associations across 6 real-world datasets encompassing domains such as activity recognition, disease diagnosis, traffic monitoring, electricity usage, mechanical fault prognosis, and finance. These real-world datasets are diverse, covering a range from 1 to 12 channels, 2 to 10 classes, sequence lengths of 14 to 1280, and data frequencies from 250 Hz to daily intervals. The experimental results show that our proposed trend-seasonality-based augmentation recommendation algorithm can accurately identify the effective augmentations for a given time series dataset, achieving an average Recall@3 of 0.667, outperforming baselines. Our work provides guidance for studies employing contrastive learning in time series analysis, with wide-ranging applications.
Here is our simplified workflow:

Key contributions of this work
- We construct 12 synthetic time series datasets that cover linear and non-linear trends, trigonometric and wavelet-based seasonalities, and three types of weighted integration.
- We assess the effectiveness of 8 commonly used augmentations across all synthetic datasets, thereby elucidating the relationships between time series properties and the effectiveness of specific augmentations.
- We propose a trend-seasonality-based framework that precisely recommends the most suitable augmentations for a given time series dataset. Experimental results demonstrate that our recommendations significantly outperform those based on popularity and random selection.
Methods
Generating synthetic datasets and benchmarking the augmentations
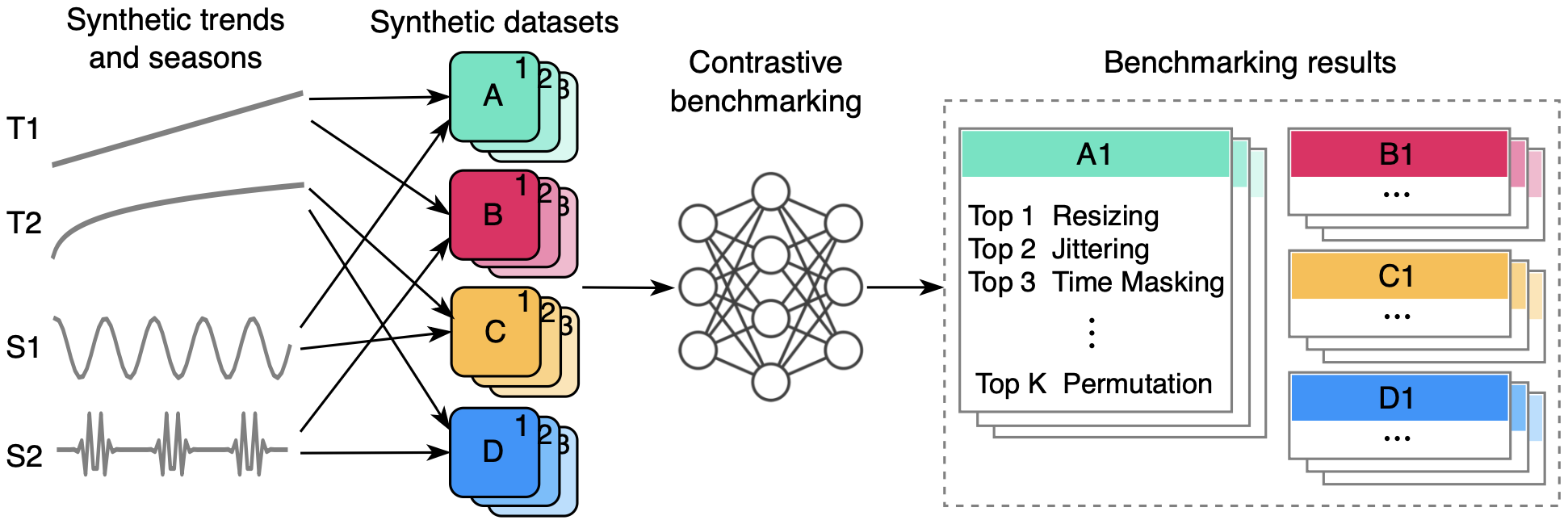
Tend-Seasonality-Based Recommendation System for Augmentations
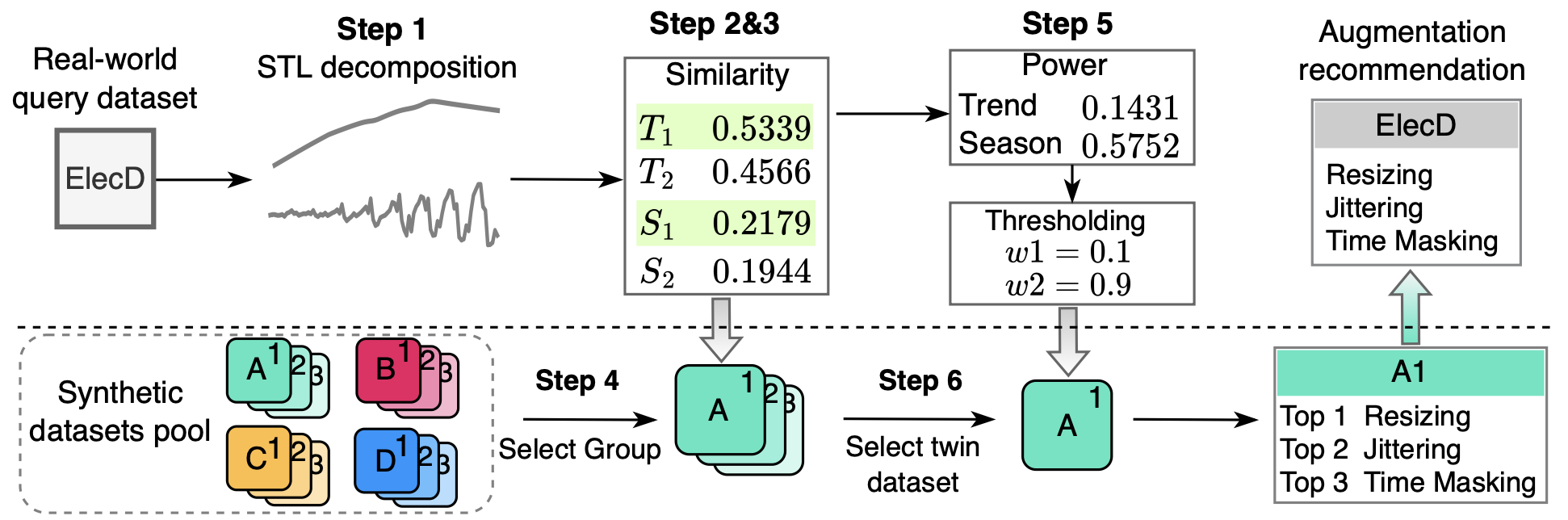
Recommendation Results
E.g., Recall@3 = 0.667 = 2/3 means that: 2 out of 3 recommended augmentations fall within the true 3 best augmentations.
| Recommendation method | Recall | HAR | PTB | FD | ElecD | SPX500 | Mean |
|---|---|---|---|---|---|---|---|
| Random | Recall@1 | 0.113 | 0.107 | 0.108 | 0.108 | 0.101 | 0.107 |
| Recall@2 | 0.235 | 0.217 | 0.222 | 0.218 | 0.209 | 0.22 | |
| Recall@3 | 0.335 | 0.331 | 0.336 | 0.339 | 0.331 | 0.334 | |
| Popularity | Recall@1 | 1 | 0 | 0 | 0 | 0 | 0.2 |
| Recall@2 | 1 | 0 | 0 | 0.5 | 0 | 0.3 | |
| Recall@3 | 0.667 | 0.333 | 0.667 | 0.667 | 0.667 | 0.6 | |
| Tend-Seasonality-Based (Ours) | Recall@1 | 1 | 0 | 1 | 1 | 0 | 0.6 |
| Recall@2 | 1 | 0 | 1 | 1 | 0.5 | 0.7 | |
| Recall@3 | 0.667 | 0.667 | 1 | 0.667 | 0.667 | 0.734 |
Installation
To install the Time Series Contrastive Augmentation Recommendation Method (TS_ARM) tool:
pip install ts_arm
The TS_ARM tool is lightweight and has minimal dependency on external packages:
numpy, scikit_learn, scipy, statsmodels, tqdm
Usage
For instance, when working with the FD dataset to obtain top 3 effective augmentations for building contrastive pairs in a time series classification task:
from ts_arm import aug_rec
import numpy as np
queryset = np.load("FD_trainx.npy") # training features of your query dataset
FD_top_augs = aug_rec.aug_rec_ts(queryset_name='FD',
K=3, # number of Augmentations you want to have
query_length=1280, # feature length in query dataset
query_period_list=[40], # list of potential periods, here we only take 40 as an example
queryset=queryset)
⚠️ Note: For some datasets, the first step, STL decomposition, may take a considerable amount of time.
The primary output will be the top three augmentations for your query dataset (the last line, displayed in bold and green, which may not appear correctly in GitHub's rendered view).
Additionally, the output includes supplementary information related to the calculations of key steps in our trend-seasonality-based recommendation methods, which can be useful if you need to understand the details of the process.
T1 Similarity: 0.0890
T2 Similarity: 0.0896
S1 Similarity: 0.1413
S2 Similarity: 0.1229
Trend Power:0.029475567737649352
Season Power:0.2485660294803488
Your twin dataset is: AC 1
Trend-season based top 3 augmentations are:['Resizing', 'Permutation', 'TimeMasking']
In addition, if you want to check the popularity-based recommendation baseline:
FD_augs_popular = aug_rec.aug_rec_popular(3)
The output:
Popularity-based top 3 recommendation: ['Jittering', 'TimeMasking', 'Resizing']
Cite us
If you find this work useful for your research, please consider citing this paper:
Future work
We have several exciting plans for the future development of this project, including but not limited to:
- More patterns of trends and seasonalities.
- More contrastive models.
- Alternative similarity metrics.
- Divergence score thresholding.
- More results analysis.
License
The TS-Contrastive-Augmentation-Recommendation project is licensed under the MIT License - see the LICENSE file for details.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file ts_arm-0.0.2.tar.gz.
File metadata
- Download URL: ts_arm-0.0.2.tar.gz
- Upload date:
- Size: 12.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.1 CPython/3.9.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
25e525d62785a39615a58a223f260021fc63f4974c340aa9d5118ae2cafe2f46
|
|
| MD5 |
2317781f495138a8562bd0907d1f6b10
|
|
| BLAKE2b-256 |
9ac06019b8e2ed2e369af7501dfa5273a761d11eb265a298627fb0dbf8f31d8d
|







