Hotelling's T-squared (T2) for process monitoring and MYT decomposition


Project description
TSquared
Python implementation of Hotelling's T-squared (T2) for process monitoring and MYT decomposition.
Table of Contents
- Features
- Installation
- Questions
- How TSquared is related to t-test?
- How TSquared is related to Mahalanobis Distance?
- How TSquared is related to MCD?
- Should I use PCA with TSquared?
- Can I apply TSquared to any kind of process? What are the conditions on parameters to use TSquared?
- Should I clean dataset before training? Is there a procedure to clean the data?
- What variables cause the outlier? What is MYT decomposition?
- How deviation types impact TSquared?
- Is a TSquared monitoring sufficient? Or do I still need univariate monitoring?
- UCL, what does that mean in multivariate context? How to compute UCL?
- My data are not normally distributed. Does it help to apply a Box-Cox transformation on each variables?
- References
Features
- Classical multivariate T2 chart in which Hotelling's T2 statistic is computed as a distance of a multivariate observation from the multivariate mean scaled by the covariance matrix of the variables
- Python scikit-learn -like implementation
- Efficient with large datasets
- MYT decomposition
Installation
TSquared requires:
- Python (>= 3.6)
- NumPy
- Pingouin
- scikit-learn
- SciPy
TSquared can be installed from PyPI:
pip install tsquared
Questions
How TSquared is related to t-test?
Hotelling's T2 is a generalization of the t-statistic for multivariate hypothesis testing When a single multivariate observation is compared to a reference distribution, it can be viewed as a generalization of the z-score. The difference is the nature of the entities (point >< distribution) that are considered in the distance computation and in the denominator of the equation also.
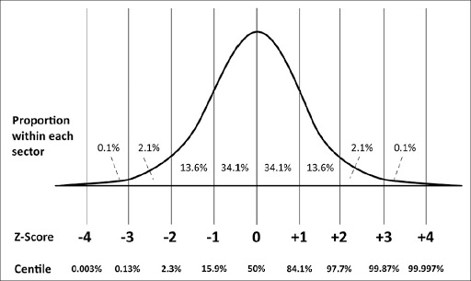
What's the relationship with z-score then?

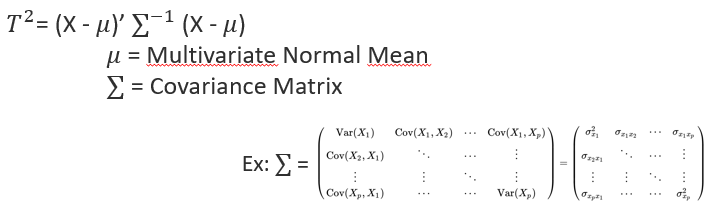
X is in this case the observation (point) in the multivariate space.
The covariance matrix of the reference multivariate distribution is formed by covariance terms between each dimensions and by variance terms (square of standard deviations) on the diagonal.
How TSquared is related to Mahalanobis Distance?
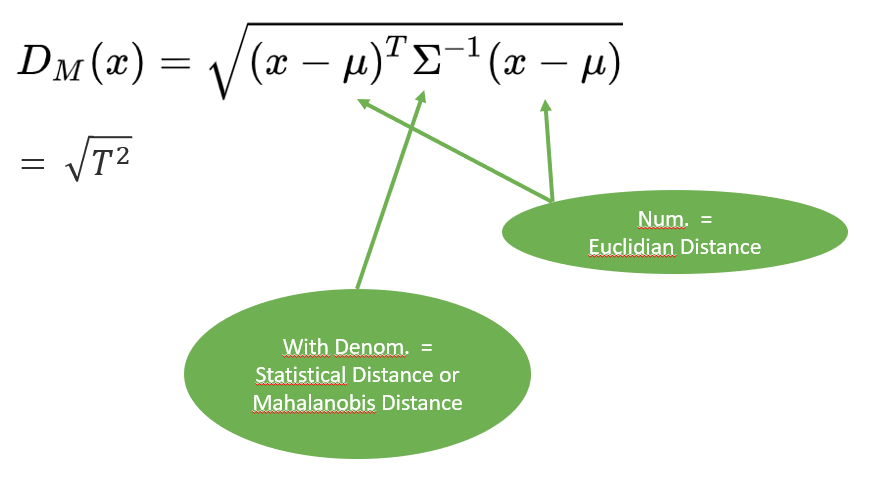
How TSquared is related to MCD?
MCD = minimum covariance determinant is an algorithm available in the Outlier Detection framework pyOD MCD is based on Mahalanobis Squared Distance (MSD =~ Hotelling's T2) Based on the distribution of MSD, the training consists to find the subgroup of points ($h < n$) that minimizes the covariance determinant. This subgroup of points can be thought of as the minimum number of points which must not be outlying (with $h > n/2$ to keep a sufficient number of point)
⟹ It is equivalent to the cleaning operation in TSquared.
Should I use PCA with TSquared?
Yes, you can!
But this should be done cautiously
- PCA defines new coordinates for each points
- PCA is often used to reduce dimensionality by selecting the strongest "principal" components defining the underlying relation between variables
- T2 score on all PCA components = T2 on all original variables
Can we apply T2 on a reduced number of (principal) components? Let's try a 2D example. In the following picture, the relation between Var1 and Var2 is mostly linear, these variables are strongly correlated. Let's suppose that the first component of the PCA is sufficient to define the relation, second component being the noisy part of the relation.
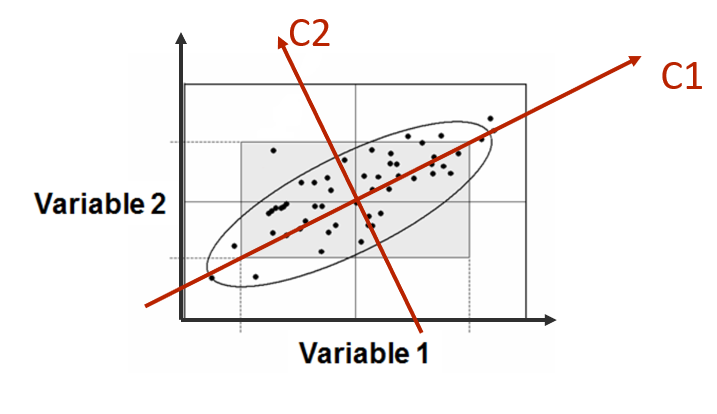
In this case, monitoring any future observation is like applying a z-score (1 dimension) to this observation compared to the distribution of all past observations projected on the first component axis.
If a loss of correlation happened between Var1 and Var2, it won't be seen on this univariate monitoring because it is the second component that will be impacted. This can happened if the sensor capturing Var2 is defective.
By extension to more dimensions, we understand that reducing "blindly" the number of components before a TSquared monitoring is not advised. It is certainly not a thing to do in case of sensors validation.
Instead, if PCA is used to reduce the dimensionality, it is advised to monitor as well the residual group of components in a separated monitoring.
Can I apply TSquared to any kind of process? What are the conditions on parameters to use TSquared?
The basic assumption is that all variables should be normally distributed. However, the algorithm is tolerant to some extent if the distributions are not perfectly normal.
Should I clean dataset before training? Is there a procedure to clean the data?
Yes, the cleaner the better
The TSquared procedure can be applied 1 or 2 times to the training set and outliers can be filtered at each round.
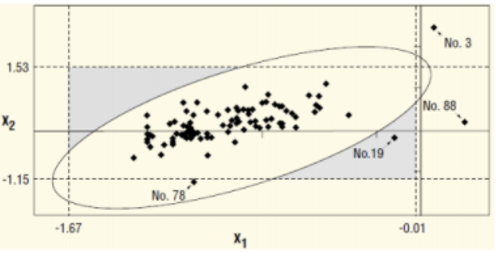
The risk to work with a training set not clean is to have an univariate outlier which is an inlier in multivariate, the multivariate UCL being too large (Observation n°78).
What variables cause the outlier? What is MYT decomposition?
How deviation types impact TSquared?
Is a TSquared monitoring sufficient? Or do I still need univariate monitoring?
UCL, what does that mean in multivariate context? How to compute UCL?
My data are not normally distributed. Does it help to apply a Box-Cox transformation on each variables?
The experiment was done using TSquared auto-cleaning function and Box-Cox transformation on each variables.
References
-
Decomposition of T2 for Multivariate Control Chart Interpretation, ROBERT L. MASON, NOLA D. TRACY and JOHN C. YOUNG
-
Application of Multivariate Statistical Quality Control In Pharmaceutical Industry, Mesut ULEN, Ibrahim DEMIR
-
Identifying Variables Contributing to Outliers in Phase I, ROBERT L. MASON, YOUN-MIN CHOU, AND JOHN C. YOUNG
-
Multivariate Control Charts for Individual Observations, NOLA D. TRACY, JOHN C. YOUNG, ROBERT L. MASON
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file tsquared-1.1.0.tar.gz.
File metadata
- Download URL: tsquared-1.1.0.tar.gz
- Upload date:
- Size: 15.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.10.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
19de741cde00a49771ef5c17b4a12137f743cce503775b59413f14c5391725a9
|
|
| MD5 |
9e1cf57e626df3e27cd768a1d386a765
|
|
| BLAKE2b-256 |
789f92d36f943d06aaefc4a99043781aa9b23d57789c6aa50259017f1acf86fb
|
File details
Details for the file tsquared-1.1.0-py3-none-any.whl.
File metadata
- Download URL: tsquared-1.1.0-py3-none-any.whl
- Upload date:
- Size: 14.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.10.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
67db12bbf607ac34ee31e957a664f1560148c6958529706f19833cc1773cd52f
|
|
| MD5 |
cf6a049cad39755751ea976b2a5801ce
|
|
| BLAKE2b-256 |
6d1203f6d7fa576380c043744aa0221e0b893567a4d5f6c1b1006a638d8ac55c
|







