Near-optimal weight quantization for LLMs using the TurboQuant algorithm
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
turboQuant
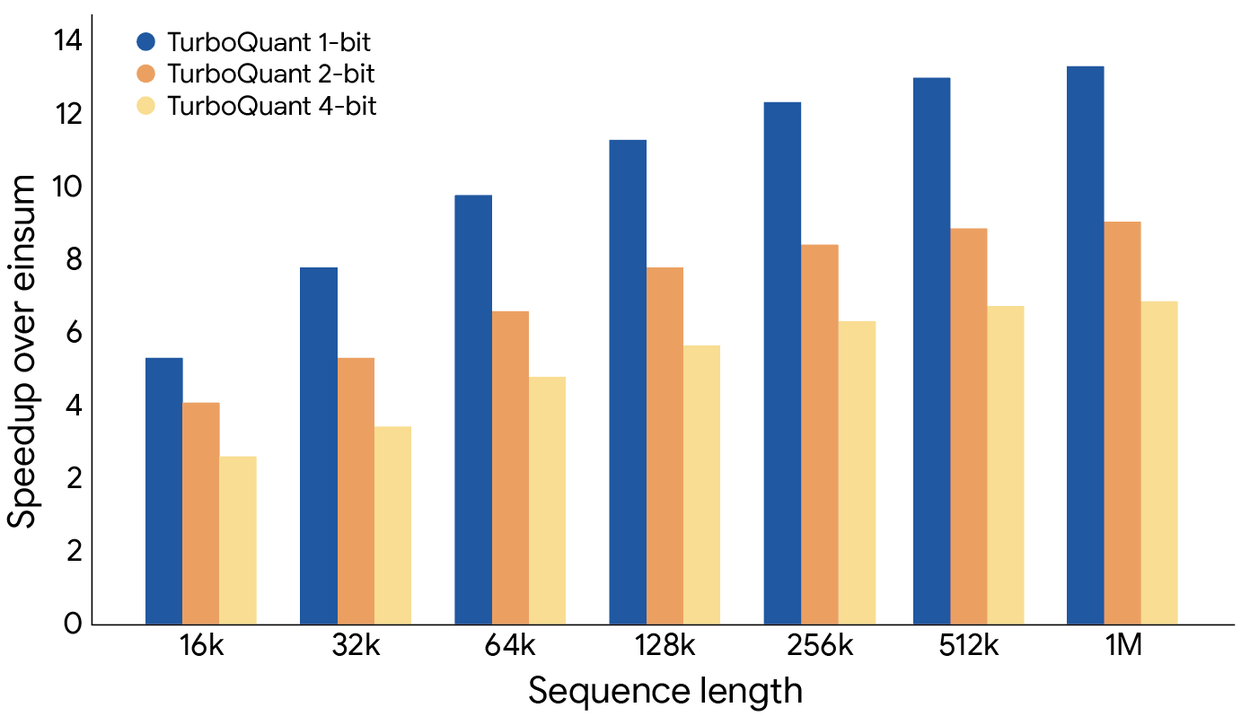
Weight quantization for Large Language Models
Adapted from the TurboQuant algorithm by Google Research (ICLR 2026)





Quantize any HuggingFace model to 2-4 bits per weight with minimal quality loss. No calibration data required.
Features
- 2/3/4-bit weight quantization using TurboQuant's random-rotation + Lloyd-Max pipeline
- No calibration data needed -- uses mathematical properties of random rotations, not model-specific tuning
- Residual quantization -- optional second pass (e.g., 4+4 = 8 bit) for near-lossless compression
- Wide HuggingFace model support -- works with Llama, Mistral, Qwen, Gemma, Phi, and other models using
nn.Linear(CausalLM, Seq2Seq, classification via--model-class) - KV cache compression -- runtime cache compression with proper bit-packing for longer contexts
- CLI included -- quantize models from the command line
- Pure PyTorch -- no CUDA/Triton dependency required
Installation
# Core (PyTorch only)
pip install turboquant-hf
# With HuggingFace support (recommended)
pip install turboquant-hf[transformers]
# Development
pip install turboquant-hf[dev]
Or install from source:
git clone https://github.com/singhsidhukuldeep/turboQuant.git
cd turboQuant
pip install -e ".[all]"
Quick Start
Python API
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from turboquant import TurboQuantConfig, quantize_model, save_quantized, load_quantized
# Load a model
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen2.5-0.5B", torch_dtype=torch.float16
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-0.5B")
# Quantize to 4-bit
config = TurboQuantConfig(bit_width=4, group_size=128)
model = quantize_model(model, config)
# Save
save_quantized(model, config, "./qwen-0.5b-tq4", save_tokenizer=True, tokenizer=tokenizer)
# Load later
model = load_quantized("Qwen/Qwen2.5-0.5B", "./qwen-0.5b-tq4")
# Generate
inputs = tokenizer("The meaning of life is", return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=50)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
Higher Quality with Residual Quantization
# 4+4 = 8-bit total, near-lossless
config = TurboQuantConfig(bit_width=4, residual_bit_width=4, group_size=128)
model = quantize_model(model, config)
KV Cache Compression
from turboquant import TurboQuantKVCache
cache = TurboQuantKVCache(key_bits=4, value_bits=4, residual_window=128)
# During generation, compress and store:
# cache.update(layer_idx, key_states, value_states)
# keys, values = cache.get(layer_idx)
Command Line
# Quantize a model
turboquant quantize \
--model Qwen/Qwen2.5-0.5B \
--output ./quantized \
--bits 4 \
--group-size 128
# Estimate compression ratio
turboquant estimate --model Qwen/Qwen2.5-0.5B --bits 4
# Generate text with a quantized model
turboquant generate \
--model Qwen/Qwen2.5-0.5B \
--quantized ./quantized \
--prompt "Hello, world!"
# Inspect a quantized model
turboquant info ./quantized
How It Works
This library adapts the TurboQuant vector quantization algorithm for model weight compression:
- Normalize: Extract per-group norms (stored in float32)
- Rotate: Apply a random orthogonal transform (Walsh-Hadamard or Haar). After rotation, each coordinate follows a known Beta((d-1)/2, (d-1)/2) distribution regardless of the original weight values
- Quantize: Apply a precomputed Lloyd-Max optimal scalar quantizer tailored to this Beta distribution
- Pack: Bit-pack the quantization indices for compact storage
The key insight from the TurboQuant paper is that random rotation makes the statistical properties of rotated coordinates predictable and universal, enabling an optimal quantizer without any calibration data.
Scope and Relationship to the Paper
The TurboQuant paper (Zandieh et al., 2025) focuses on KV cache compression and nearest-neighbor search. This library applies the paper's core technique (Algorithm 1: random rotation + Lloyd-Max scalar quantization) to weight quantization, which is a community-driven adaptation not covered in the original paper.
The paper also describes a two-stage approach (Algorithm 2: MSE + 1-bit QJL correction) for unbiased inner product estimation. Community testing has shown that QJL correction hurts in practice for softmax attention and weight reconstruction, so this library uses the MSE-only quantizer (Algorithm 1) and offers an optional multi-bit residual pass instead.
Why No Calibration?
Traditional quantization methods (GPTQ, AWQ) require calibration data to determine optimal quantization parameters per-layer. TurboQuant sidesteps this: after rotation, the coordinate distribution is determined by dimensionality alone. The optimal codebook is precomputed once for each (dimension, bit-width) pair.
Supported Configurations
Compression ratios account for per-group float32 norms and remainder column overhead at group_size=128:
| Config | Total Bits | Approx. Compression | Quality |
|---|---|---|---|
| 4-bit | 4 | ~3.7x | Good for most tasks |
| 3-bit | 3 | ~4.8x | Acceptable for large models (7B+) |
| 2-bit | 2 | ~6.6x | Aggressive, some quality loss |
| 4+4 residual | 8 | ~1.9x | Near-lossless |
| 4+2 residual | 6 | ~2.5x | Balanced |
Citations
Adapted from research by Google:
- TurboQuant (Zandieh et al., 2025) -- Online vector quantization with near-optimal distortion rate. ICLR 2026.
- QJL (Zandieh et al., 2024) -- 1-bit quantized JL transform for KV cache quantization with zero overhead. AAAI 2025.
- PolarQuant (Han et al., 2025) -- Quantizing KV caches with polar transformation. AISTATS 2026.
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file turboquant_hf-0.1.1.tar.gz.
File metadata
- Download URL: turboquant_hf-0.1.1.tar.gz
- Upload date:
- Size: 43.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
895bded0f8498105e5872536c16a833b25797295dc96c062955fca75e94a697a
|
|
| MD5 |
08e371402def29d4eb7985d0dfb83387
|
|
| BLAKE2b-256 |
5224f77b0949c8d4752672219ebb586b9a2db3b4b2b970d837eb598087eb6cbb
|
Provenance
The following attestation bundles were made for turboquant_hf-0.1.1.tar.gz:
Publisher:
publish.yml on singhsidhukuldeep/turboQuant
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
turboquant_hf-0.1.1.tar.gz -
Subject digest:
895bded0f8498105e5872536c16a833b25797295dc96c062955fca75e94a697a - Sigstore transparency entry: 1205927293
- Sigstore integration time:
-
Permalink:
singhsidhukuldeep/turboQuant@a13cfab192a8b1668580aec2bc19717db17a8031 -
Branch / Tag:
refs/tags/v0.1.1 - Owner: https://github.com/singhsidhukuldeep
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@a13cfab192a8b1668580aec2bc19717db17a8031 -
Trigger Event:
release
-
Statement type:
File details
Details for the file turboquant_hf-0.1.1-py3-none-any.whl.
File metadata
- Download URL: turboquant_hf-0.1.1-py3-none-any.whl
- Upload date:
- Size: 37.7 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
1f4cd238d4a500ce9ff4b66d1ef4fc4dda13256b69ec2c552a7f80c6dd16b39b
|
|
| MD5 |
5b168b289cc5aadb2c2f000fa24498e5
|
|
| BLAKE2b-256 |
11f6dd949d64ac17e377ef8894ab7cdf5be13980181c0ef407dd10776cbbec61
|
Provenance
The following attestation bundles were made for turboquant_hf-0.1.1-py3-none-any.whl:
Publisher:
publish.yml on singhsidhukuldeep/turboQuant
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
turboquant_hf-0.1.1-py3-none-any.whl -
Subject digest:
1f4cd238d4a500ce9ff4b66d1ef4fc4dda13256b69ec2c552a7f80c6dd16b39b - Sigstore transparency entry: 1205927314
- Sigstore integration time:
-
Permalink:
singhsidhukuldeep/turboQuant@a13cfab192a8b1668580aec2bc19717db17a8031 -
Branch / Tag:
refs/tags/v0.1.1 - Owner: https://github.com/singhsidhukuldeep
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@a13cfab192a8b1668580aec2bc19717db17a8031 -
Trigger Event:
release
-
Statement type:







