Python package which to access the Twitter database without API

Project description




tweety
Twitter's API is annoying to work with, and has lots of limitations. tweety scrape all the tweets using python and selenium - No API rate limits. No restrictions. Extremely fast.
| Source | Link |
|---|---|
| PyPI: | https://pypi.org/project/tweety/ |
| Repository: | https://santhoshse7en.github.io/tweety/ |
| Documentation: | https://santhoshse7en.github.io/tweety_doc/ |
Average Tweets
It appears you can ask for up to 25 pages around tweets reliably (~1200 tweets)
Dependencies
- beautifulsoup4
- selenium
- chromedriver-binary
- vaderSentiment
- textblob
- pandas
Dependencies Installation
Use the package manager pip to install following
pip install -r requirements.txt
Usage
Download it by clicking the green download button here on Github. You only need to parse argument specific Twitter keyword.
>>> from twitter.tweety import tweets
>>> tweety = tweets('Super Deluxe')
Directory of tweety

Output
>>> print("Polarity Scores" + " : " + str(tweety.final_sentiment_scores))
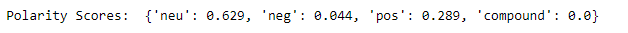
Contributing
Pull requests are welcome. For major changes, please open an issue first to discuss what you would like to change.
Please make sure to update tests as appropriate.
License
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file tweety-0.1.6.tar.gz.
File metadata
- Download URL: tweety-0.1.6.tar.gz
- Upload date:
- Size: 4.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/1.13.0 pkginfo/1.5.0.1 requests/2.22.0 setuptools/41.0.1 requests-toolbelt/0.9.1 tqdm/4.32.1 CPython/3.7.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
1844530a67948b9c72cfaa6bc1664717fa3b662d5f830d786f970451a0883e3d
|
|
| MD5 |
2e78d319adda86d0a067f143f9c17de6
|
|
| BLAKE2b-256 |
0cb81aaac0db3ce8a58234d5d02c76ebc5768250a22f8556b547279e0860f9b5
|







