UniPercept: Towards Unified Perceptual-Level Image Understanding

Project description
UniPercept: Towards Unified Perceptual-Level Image Understanding across Aesthetics, Quality, Structure, and Texture

⭐️ More Research:
- ArtiMuse: Fine-Grained Image Aesthetics Assessment with Joint Scoring and Expert-Level Understanding
🚀 News & Updates
-
[Jan 04, 2026] 📦 Package Release. We now support
unipercept-rewardas a standalone Python package! You can easily integrate perceptual scoring into your workflow viapip install unipercept-reward. Please refer to the Quick Start section for usage. -
[Dec 29, 2025] 🔥 Official Release
- Technical Report
- Project Page
- UniPercept-Bench: A comprehensive perceptual-level understanding benchmark for MLLMs, spanning Image Aesthetics Assessment (IAA), Image Quality Assessment (IQA), and Image Structure & Texture Assessment (ISTA) across Visual Rating (VR) and Visual Question Answering (VQA) tasks.
- UniPercept: A powerful baseline MLLM specialized for perceptual image understanding, optimized via Domain-Adaptive Pre-Training and Task-Aligned RL.
🚀 Quick Start
Installation
Install the package via pip:
pip install unipercept-reward
Recommended: To enable Flash Attention for faster inference and lower memory usage, install with the flash extra:
pip install "unipercept-reward[flash]"
Basic Usage
Simple Inference Example
from unipercept_reward import UniPerceptRewardInferencer
# 1. Initialize the inferencer
# This will automatically download weights from HF: Thunderbolt215215/UniPercept
inferencer = UniPerceptRewardInferencer(device="cuda")
# 2. Prepare image paths
image_paths = [
"test.png"
]
# 3. Get reward scores
# Returns a list of dictionaries containing scores for multiple dimensions
rewards = inferencer.reward(image_paths=image_paths)
# 4. Print results
for path, score in zip(image_paths, rewards):
if score:
print(f"Image: {path}")
print(f" ➤ Aesthetics (IAA): {score['iaa']:.4f}")
print(f" ➤ Quality (IQA): {score['iqa']:.4f}")
print(f" ➤ Structure (ISTA): {score['ista']:.4f}")
You can also load a model from a local checkpoint path:
inferencer = UniPerceptRewardInferencer(
model_path="/path/to/local/checkpoint",
device="cuda"
)
Output Metrics
The .reward() method returns a dictionary with three perceptual metrics for each image. All scores are on a scale of 0 to 100, where higher scores indicate better performance/quality.
| Key | Metric Name | Description |
|---|---|---|
iaa |
Image Aesthetics Assessment | Evaluates the aesthetic quality of the image. |
iqa |
Image Quality Assessment | Evaluates the quality. |
ista |
Image Structure & Texture Assessment | Evaluates the richness of structure and texture details. |
🌟 Abstract
Multimodal large language models (MLLMs) have achieved remarkable progress in visual understanding tasks such as visual grounding, segmentation, and captioning. However, their ability to perceive perceptual-level image features remains limited. In this work, we present UniPercept-Bench, a unified framework for perceptual-level image understanding across three key domains: Aesthetics, Quality, and Structure and Texture. We establish a hierarchical definition system and construct large-scale datasets to evaluate perceptual-level image understanding. Based on this foundation, we develop a strong baseline UniPercept trained via Domain-Adaptive Pre-Training and Task-Aligned RL, enabling robust generalization across both Visual Rating (VR) and Visual Question Answering (VQA) tasks. UniPercept outperforms existing MLLMs on perceptual-level image understanding and can serve as a plug-and-play reward model for text-to-image generation. This work defines Perceptual-Level Image Understanding in the era of MLLMs and, through the introduction of a comprehensive benchmark together with a strong baseline, provides a solid foundation for advancing perceptual-level multimodal image understanding.
📊 UniPercept-Bench
We introduce UniPercept-Bench, a systematic benchmark for perceptual image understanding:
- Comprehensive Coverage: Spans 3 domains (IAA, IQA, ISTA), 17 categories, and 43 criteria.
- Perceptual Tasks: Supports both Visual Rating (VR) and Visual Question Answering (VQA).
Download: 🤗 UniPercept-Bench

🔍 UniPercept
UniPercept is a strong baseline MLLM trained via Domain-Adaptive Pre-Training and Task-Aligned RL to handle both Visual Rating (VR) (continuous scoring) and Visual Question Answering (VQA) (reasoning).
🛠️ Setup
conda create -n unipercept python=3.10
conda activate unipercept
cd UniPercept
pip install -r requirements.txt
📉 Evaluation
Please download the UniPercept weights from 🤗 UniPercept and place them in the ckpt/ directory.
Visual Rating (VR)
Please download the datasets listed below and place them in the corresponding paths.
| Dataset | Domain | Download | Path |
|---|---|---|---|
| ArtiMuse-10K | IAA | 🤗 Link | benchmark/VR/IAA/ArtiMuse-10K/image |
| AVA | IAA | Link | benchmark/VR/IAA/AVA/image |
| TAD66K | IAA | Link | benchmark/VR/IAA/TAD66K/image |
| FLICKR-AES | IAA | Link | benchmark/VR/IAA/FLICKR-AES/image |
| KonIQ-10K | IQA | Link | benchmark/VR/IQA/KonIQ-10K/image |
| SPAQ | IQA | Link | benchmark/VR/IQA/SPAQ/image |
| KADID | IQA | Link | benchmark/VR/IQA/KADID/image |
| PIPAL | IQA | Link | benchmark/VR/IQA/PIPAL/image |
| ISTA-10K | ISTA | 🤗 Link | benchmark/VR/ISTA/ISTA-10K/image |
After setting up the data, you can configure the target datasets and devices in src/eval/eval_vr.sh. The results will be saved to results/vr.
cd UniPercept
bash src/eval/eval_vr.sh
Visual Question Answering (VQA)
Please download UniPercept-Bench-VQA from 🤗 UniPercept-Bench and place them into benchmark/VQA.
Then you can configure the target domain in src/eval/eval_vqa.sh. The evaluation results will be saved to results/vqa.
cd UniPercept
bash src/eval/eval_vqa.sh
Interactive Image Perception
You can engage in comprehensive conversations with UniPercept regarding various aspects of an image, such as its aesthetics, quality, and structural details. An example is provided below, which you can customize based on your needs, or refer to InternVL for further implementation details.
cd UniPercept
bash src/eval/conversation.sh
🏆 Performance
UniPercept consistently outperforms proprietary models (e.g., GPT-4o, Gemini-2.5-Pro), leading open-source models (InternVL3, Qwen3-VL) and across all three perceptual domains (IAA, IQA, ISTA) and tasks (VR, VQA).
Performance on UniPercept-Bench-VR
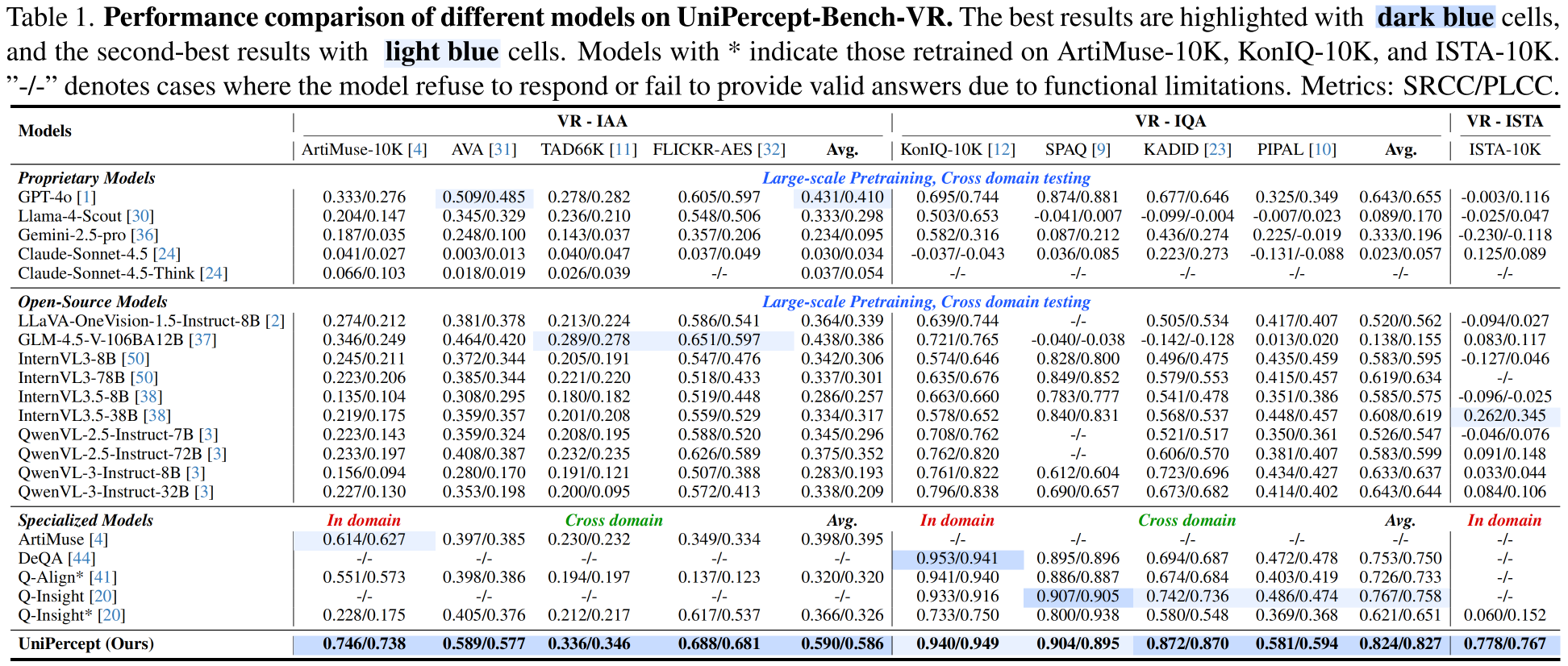
Performance on UniPercept-Bench-VQA (IAA)
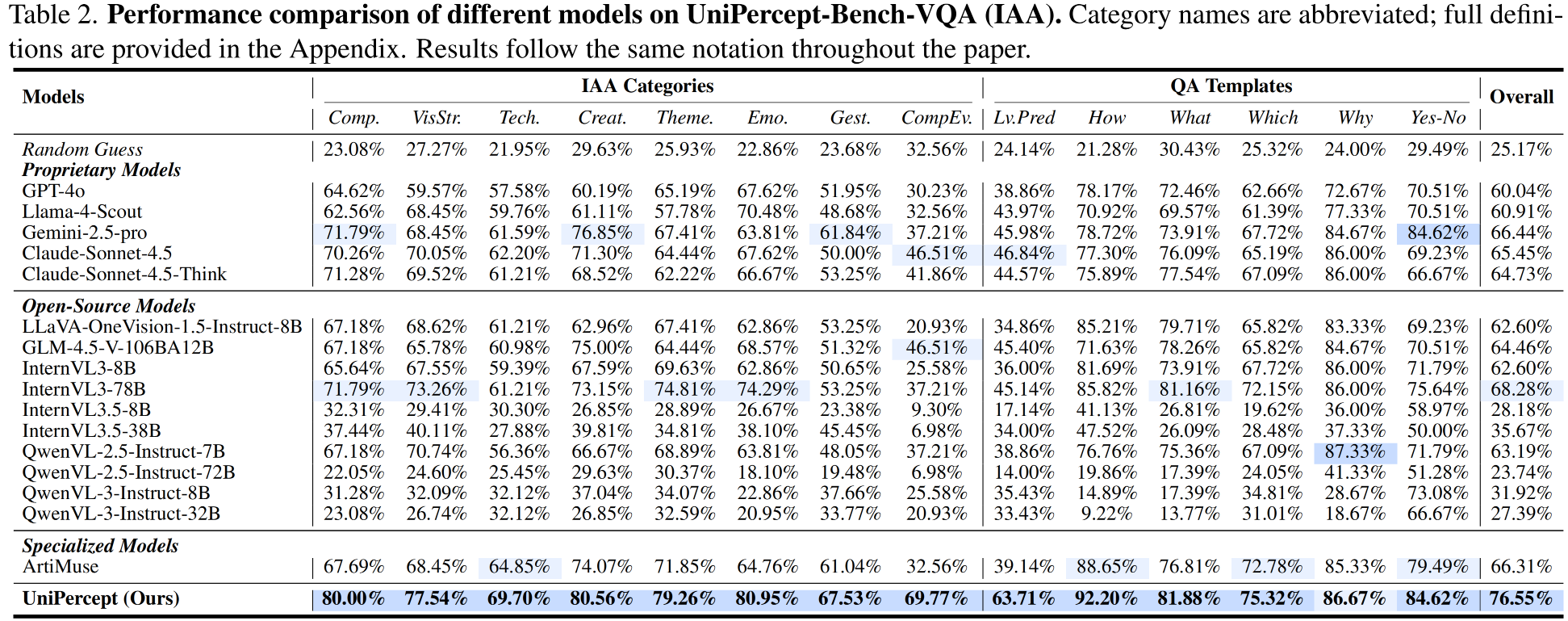
Performance on UniPercept-Bench-VQA (IQA)
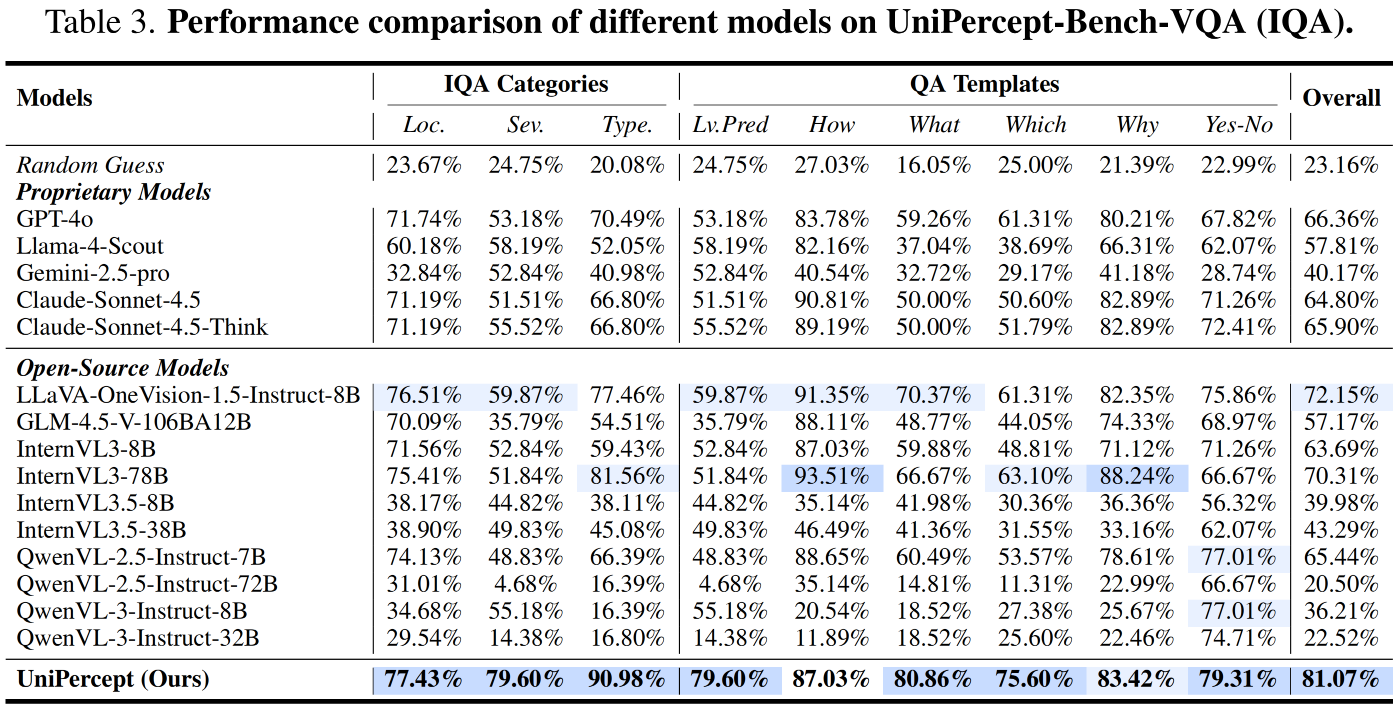
Performance on UniPercept-Bench-VQA (ISTA)
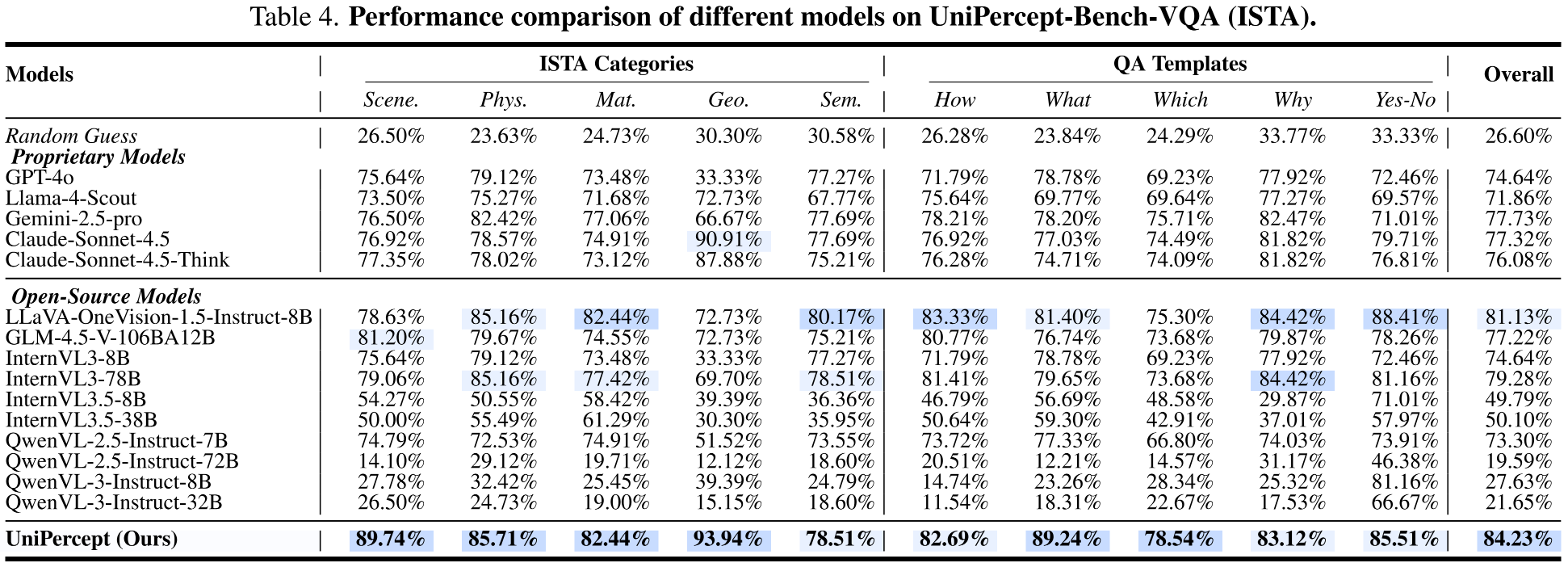
🎨 Applications
UniPercept As Reward
UniPercept can be used as a powerful reward model for post-training Text-to-Image (T2I) models. By integrating UniPercept rewards into the training of FLUX.1-dev, we observe significant improvements in aesthetic quality, structural richness, and prompt adherence.

UniPercept As Metrics
UniPercept can serve as an perceptual-level metric that assesses the quality of outputs from any model producing images, covering three complementary dimensions: IAA, IQA, and ISTA.
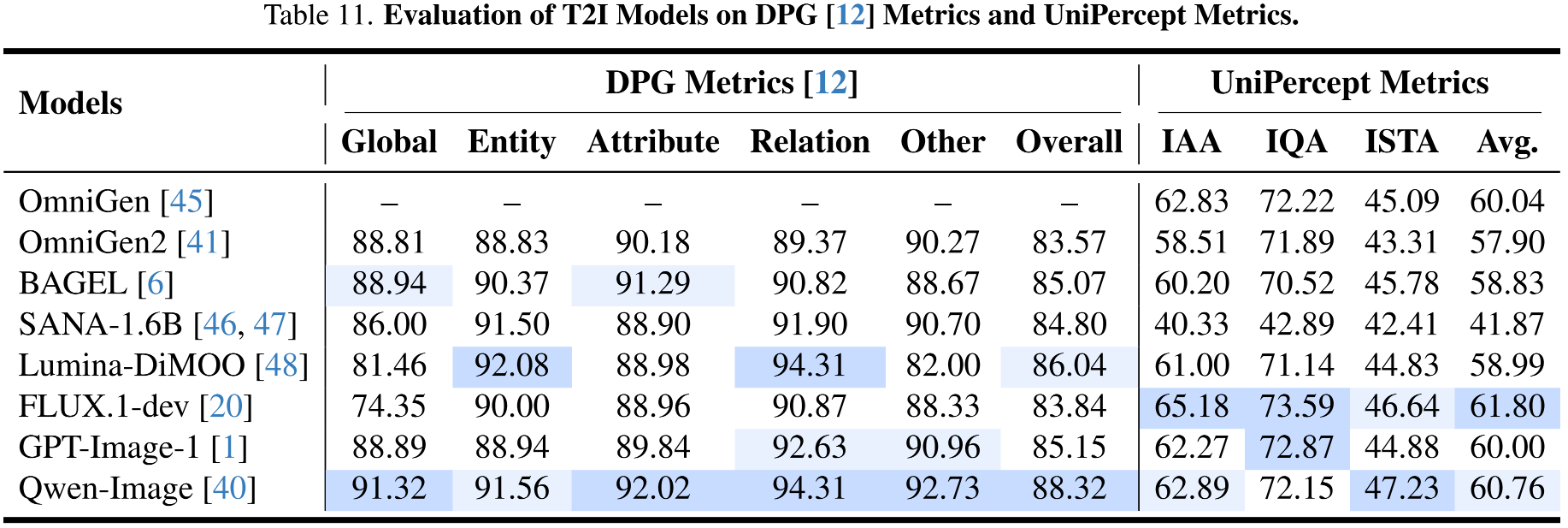
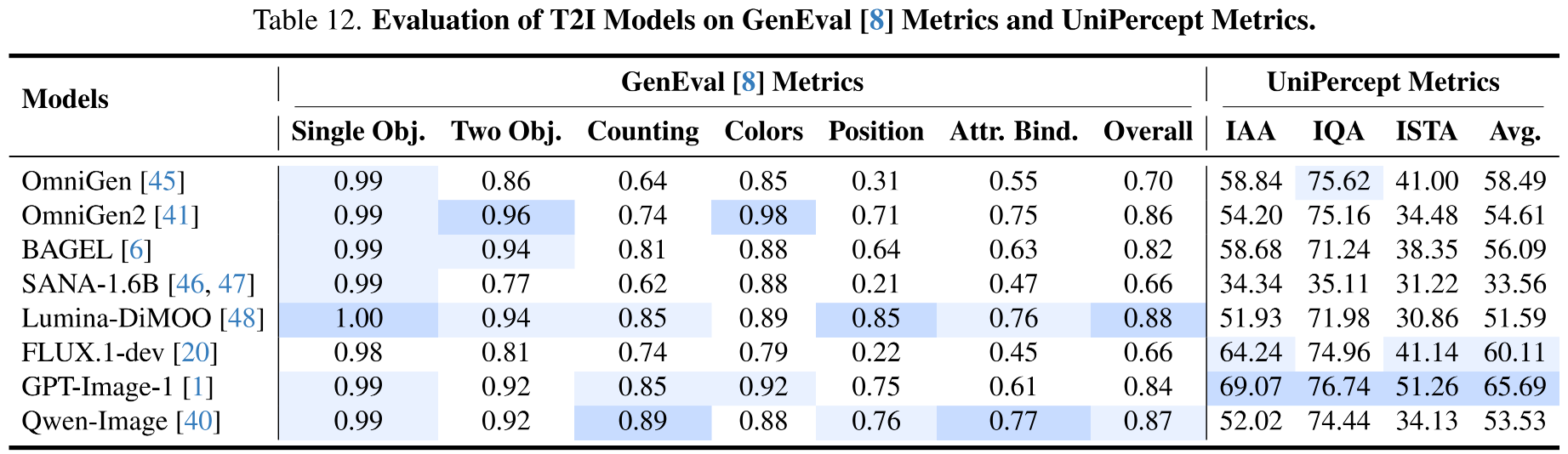
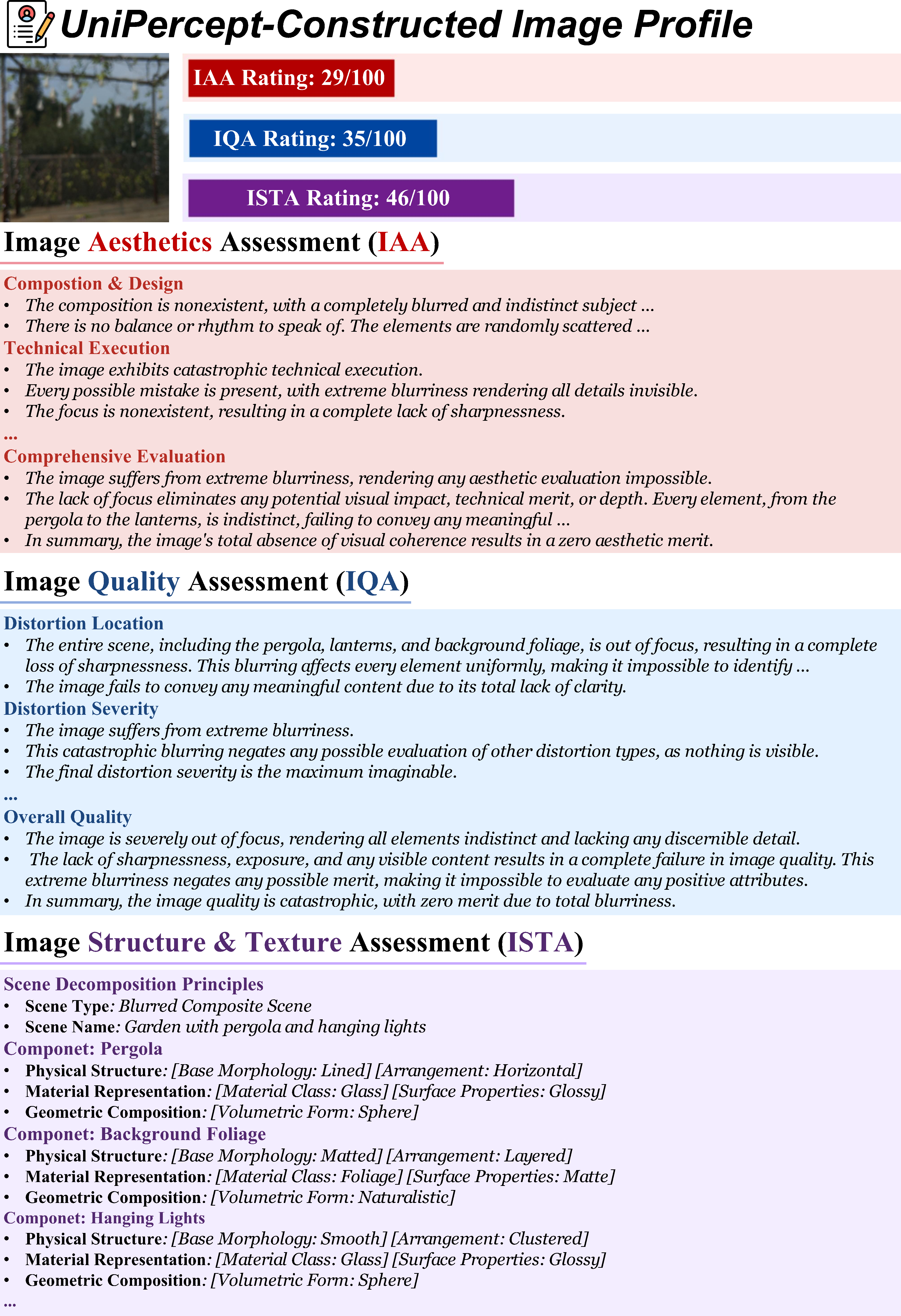
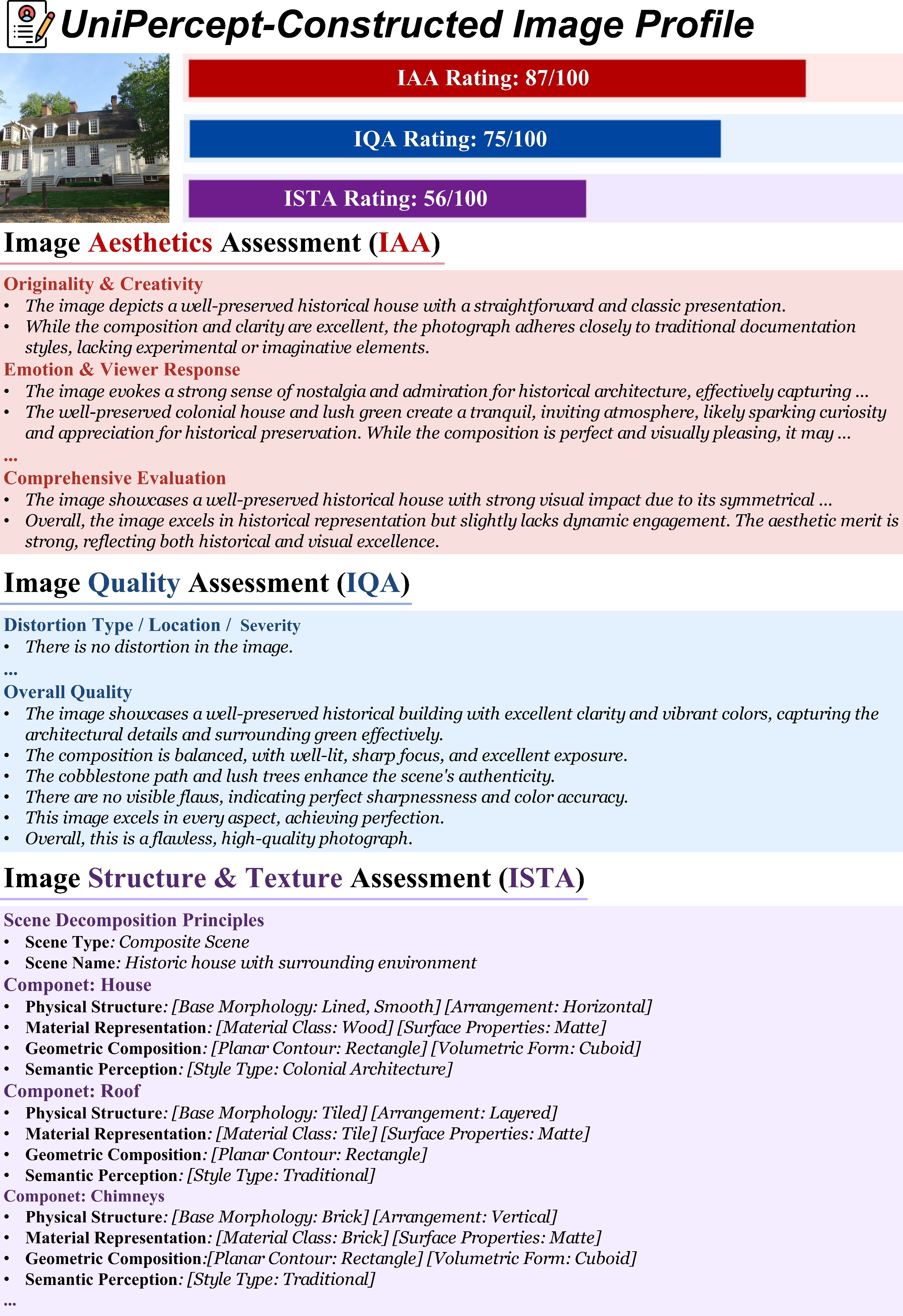
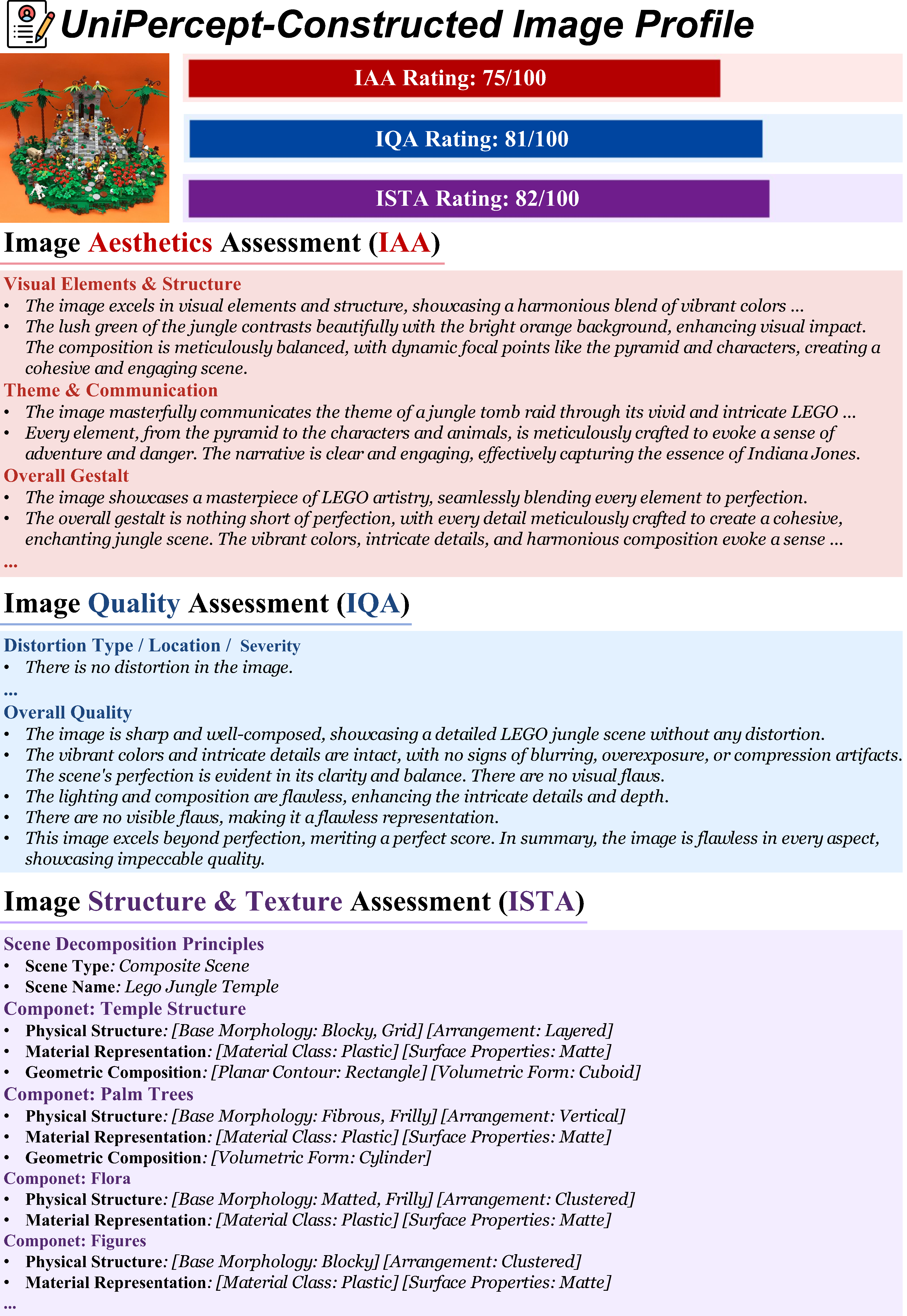
🖼️ UniPercept-Constructed Image Profiles
UniPercept performs comprehensive perceptual-level image analysis, delivering accurate visual ratings across the IAA, IQA, and ISTA dimensions, along with fine-grained multi-dimensional analytical outputs that together form a detailed image profile.
✏️ Citation
If you find UniPercept useful for your research, please consider citing our work:
@misc{cao2025uniperceptunifiedperceptuallevelimage,
title={UniPercept: Towards Unified Perceptual-Level Image Understanding across Aesthetics, Quality, Structure, and Texture},
author={Shuo Cao and Jiayang Li and Xiaohui Li and Yuandong Pu and Kaiwen Zhu and Yuanting Gao and Siqi Luo and Yi Xin and Qi Qin and Yu Zhou and Xiangyu Chen and Wenlong Zhang and Bin Fu and Yu Qiao and Yihao Liu},
year={2025},
eprint={2512.21675},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2512.21675},
}
@misc{cao2025artimusefinegrainedimageaesthetics,
title={ArtiMuse: Fine-Grained Image Aesthetics Assessment with Joint Scoring and Expert-Level Understanding},
author={Shuo Cao and Nan Ma and Jiayang Li and Xiaohui Li and Lihao Shao and Kaiwen Zhu and Yu Zhou and Yuandong Pu and Jiarui Wu and Jiaquan Wang and Bo Qu and Wenhai Wang and Yu Qiao and Dajuin Yao and Yihao Liu},
year={2025},
eprint={2507.14533},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2507.14533},
}


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file unipercept_reward-1.0.2.tar.gz.
File metadata
- Download URL: unipercept_reward-1.0.2.tar.gz
- Upload date:
- Size: 31.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.10.19
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9bc8f492b713c018cce451b34bf20be63668f446fb94150a36b72c9a025bd9f6
|
|
| MD5 |
d4cdc9d8417f35dee04551d491ecdaec
|
|
| BLAKE2b-256 |
a4cbbdbfc50fa74ee5b75f320d635a29f8e72c83523c938bd20d129675726c8c
|
File details
Details for the file unipercept_reward-1.0.2-py3-none-any.whl.
File metadata
- Download URL: unipercept_reward-1.0.2-py3-none-any.whl
- Upload date:
- Size: 30.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.10.19
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
403fe584b25d29bd8f12dc0761b9cc6b122321a860d9111aa1fb36674eb8a5a2
|
|
| MD5 |
2b3a0f3606d0242e3421645c47e4cca0
|
|
| BLAKE2b-256 |
ef551815ca366dcb02eae13993e39d52bcdf34410448be962f01147dbb4fc86f
|







