An Async Online Multi-Agent RL library for training reasoning models on TextArena games.

Project description
UnstableBaselines
An Async, Online, Multi-Turn, Multi-Agent RL library for training reasoning models on TextArena games.



Work in progress — interfaces will change.
Updates
- 15/07/2025: v0.2.0 A2C, runtime object, environment scheduling
- 23/06/2025: Early release of the pip package (
pip install unstable-rl) - 22/06/2025: Early release of the code base
Introduction
UnstableBaselines is an Async-, Online-, Multi-Agent RL library focused on simplicity and hackability. Since multiple recent papers showed the sufficiency of LoRA for reasoning tuning, and the fact that opponent sampling for self-play strategies beyond mirror self-play work best when using LoRA weights (since vLLM allows for hot-swapping), we built UnstableBaselines as a LoRA first RL library. We tried to keep the code as straight forward as possible. It is currently around 1.2K lines long and semi-readable. The main focus of unstable-baselines is to enable fast prototyping/research. For something a bit more production ready we recommend to use oat or verifiers.
Lines of Code per Release
-------------------------
0.1.0 | ###################### 1,144 -> initial release
0.2.0 | ######################## 1,269 -> added A2C, runtime object, environment scheduling
Key Features
- Asynchronous collection & learning – actors generate data while learners train.
- Multi‑agent, multi‑turn focus with self‑play or fixed opponents.
- LoRA‑first fine‑tuning workflow for fast, lightweight updates.
- Composable reward transforms at step, game, and sampling stages.
Structure
┌─────────┐ ┌─────────┐ ┌────────────┐
│ Env │ │ Model │ Get Models │ Model │
│ Sampler │ │ Sampler │◀─────────── │ Registry │
└─────────┘ └─────────┘ └────────────┘
│ │ ▲
│Sample │Sample │Push
│Env │Opponent │Checkpoint
▼ ▼ │
┌───────────────┐ ┌───────────────┐
│ │ │ │
│ GameScheduler │ │ Learner │
│ │ │ │
└───────────────┘ └───────────────┘
▲ │ ▲ │
│ │ Sample If enough │ │ Check if enough
Update │ │ GameSpec data, pull │ │ data for training
│ │ the next batch │ │ is available
│ ▼ │ ▼
┌───────────────┐ ┌────────────┐
│ │ Send │ │
│ Collector │──────────────▶│ Buffer │
│ │ Trajectories │ │
└───────────────┘ └────────────┘
▲ │
│ │ Maintain
return │ │ Pool of
Trajectory │ │ n parallel
│ │ workers
│ ▼
┌─────────────┐
│ run_game() │
│ train/eval │
└─────────────┘
Installation
install UnstableBaselines
pip3 install unstable-rl
Example
To get you started, in this short example we will run you through the process of training Qwen3-1.7B-Base via mirror self-play on SimpleTak and evaluating it against google/gemini-2.0-flash-lite-001 on SimpleTak and KuhnPoker. We will be running the experiments on 3xRTX6000 ada. If you are limited to 24gb of vRam, you can reduce the MAX_TRAIN_SEQ_LEN to around 2500; this means that the model will only be trained on the first 2500 prompt+answer tokens, but can still generate answer that are longer than that. Since (in our experience) models tend to shorten their reasoning throughout training, this works very well.
Training script
import time, ray, unstable
import unstable.reward_transformations as retra
MODEL_NAME = "Qwen/Qwen3-1.7B-Base"
MAX_TRAIN_SEQ_LEN = None
MAX_GENERATION_LENGTH = 4096
lora_config = {
"lora_rank": 32, "lora_alpha": 32, "lora_dropout": 0.0,
"target_modules": ["q_proj","k_proj","v_proj","o_proj","gate_proj", "up_proj","down_proj"]
}
vllm_config = {
"model_name": MODEL_NAME, "temperature": 0.6, "max_tokens": MAX_GENERATION_LENGTH,
"max_parallel_seq": 128, "max_loras": 8, "lora_config": lora_config,
"max_model_len": 8192
}
# Ray init
ray.init(namespace="unstable")
# initialize environment scheduler
env_sampler = unstable.samplers.env_samplers.UniformRandomEnvSampler(
train_env_specs=[
unstable.TrainEnvSpec(env_id="SimpleTak-v0-train", num_players=2, num_actors=2, prompt_template="qwen3-zs"), # if num_players == num_actors, it's mirror self-play and no opponents will be sampled
],
eval_env_specs=[
unstable.EvalEnvSpec(env_id="SimpleTak-v0-train", num_players=2, prompt_template="qwen3-zs"),
unstable.EvalEnvSpec(env_id="KuhnPoker-v0-train", num_players=2, prompt_template="qwen3-zs"),
])
# Tracker
tracker = unstable.Tracker.options(name="Tracker").remote(
run_name=f"Test-{MODEL_NAME.split('/')[-1]}-{env_sampler.env_list()}-{int(time.time())}",
wandb_project="UnstableBaselines"
)
# initialize model registry
model_registry = unstable.ModelRegistry.options(name="ModelRegistry").remote(tracker=tracker)
ray.get(model_registry.add_checkpoint.remote(uid="base", path=None, iteration=0))
ray.get(model_registry.add_fixed.remote(name="google/gemini-2.0-flash-lite-001"))
# initialize model sampler
model_sampler = unstable.samplers.model_samplers.BaseModelSampler(model_registry=model_registry)
# build game scheduler
game_scheduler = unstable.GameScheduler.options(name="GameScheduler").remote(model_sampler=model_sampler, env_sampler=env_sampler, logging_dir=ray.get(tracker.get_log_dir.remote()))
# Data Buffer
step_buffer = unstable.StepBuffer.options(name="Buffer").remote(
max_buffer_size=384*2, tracker=tracker,
final_reward_transformation=retra.ComposeFinalRewardTransforms([retra.RoleAdvantageByEnvFormatter()]),
step_reward_transformation=retra.ComposeStepRewardTransforms([retra.RewardForFormat(1.5), retra.PenaltyForInvalidMove(1.0, -1.0)]),
sampling_reward_transformation=retra.ComposeSamplingRewardTransforms([retra.NormalizeRewardsByEnv(True)]),
)
# initialize the collector
collector = unstable.Collector.options(name="Collector").remote(
vllm_config=vllm_config, tracker=tracker, buffer=step_buffer, game_scheduler=game_scheduler,
)
# initialize the learner
learner = unstable.REINFORCELearner.options(num_gpus=1, name="Learner").remote(
model_name=MODEL_NAME,
lora_cfg=lora_config,
batch_size=384,
mini_batch_size=1,
learning_rate=1e-5,
grad_clip=0.2,
buffer=step_buffer,
tracker=tracker,
model_registry=model_registry,
activation_checkpointing=True,
gradient_checkpointing=True,
use_trainer_cache=False
)
ray.get(learner.initialize_algorithm.remote(max_train_len=MAX_TRAIN_SEQ_LEN, max_generation_len=MAX_GENERATION_LENGTH))
try:
collector.collect.remote(num_train_workers=384, num_eval_workers=16)
ray.get(learner.train.remote(200))
finally:
ray.kill(collector, no_restart=True)
ray.shutdown()
In a Nutshell, the Collector will maintain 384 and 16 in parallel running collection and evaluation games (respectively). Whenever a game finishes, the trajectory is passed to the StepBuffer and a new game is started. The StepBuffer splits each trajectory into steps and applies the specified reward transformations (on the game and step level first; and batch level once the Learner pulls the next batch).
The Learner will periodically (once every 0.2 seconds) check if the StepBuffer has accumulated enough data for training. If so, it'll request a full training batch from the StepBuffer, train on the data, and push the new set of LoRA weights to the ModelPool.
The Collector will keep collecting episodes until the Learner tells it to stop (in this case, after 200 update steps).
Monitoring Progress
If you want to monitor key metrics (in addition to logging them via W&B) during training you can run the following command in a seperate terminal:
unstable-terminal
The rendered interface will currently look something like this: (please not that it might change in the future as UnstableBaselines is very much still under development)

The .gif doesn't do it justice, looks nice when you run it yourself haha.
Results
Since we set num_eval_workers=16, throughout training there are always 16 eval games running in parallel (using the most recent lora checkpoint). Running 200 learner steps took a total of ~12h on the 3xRTX6000 ada setup we used.
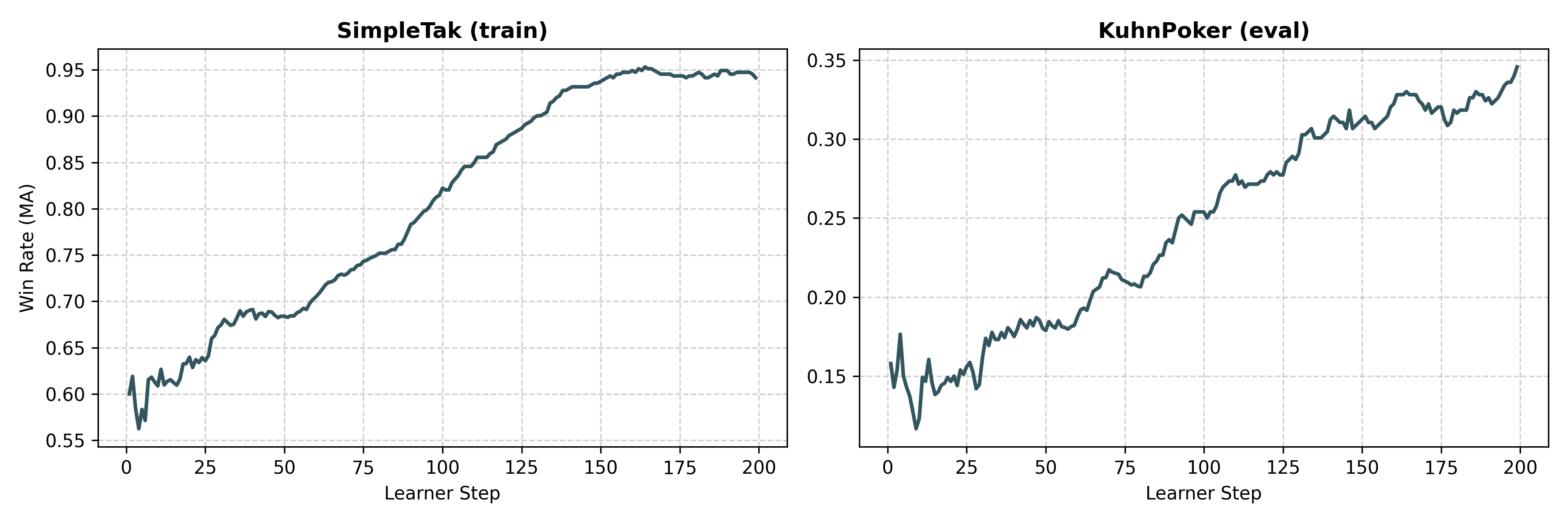
As can be seen in the plots the Win-Rate against a fixed opponent (in this case google/gemini-2.0-flash-lite-001) improves significantly for both the training and evaluation environment, showing that at least some of learned reasoning patterns generalize to other tasks and problems.
Collaboration
Developed in partnership with PlasticLabs.
Papers
We built this code-base as part of our research on self-play for reasoning models on text based games. We hope to finish and release both papers (one focused on the paradigm and one focused on the "scaling-laws" and analysis thereof) within the next couple of weeks!
Citation 
If you use UnstableBaselines in your research, please cite:
@software{guertler_leon_2025_15719271,
author={Guertler, Leon and Grams, Tim and Liu, Zichen and Cheng, Bobby},
title={{UnstableBaselines}},
month=jun,
year=2025,
publisher={Zenodo},
version={0.1.0},
doi={10.5281/zenodo.15719271},
url={https://doi.org/10.5281/zenodo.15719271}
}


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file unstable_rl-0.2.0.tar.gz.
File metadata
- Download URL: unstable_rl-0.2.0.tar.gz
- Upload date:
- Size: 37.2 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.10.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c303766b40ecd3dcf7273f15fd50725fd79aa08bcf21e7a137b383329089ec92
|
|
| MD5 |
b01f5a76e8538bd513c89056e46a6ba1
|
|
| BLAKE2b-256 |
81fc9aaf667c508df52c21410d9721c8df86fd19b2ffbeb6a4dfc93525089fa0
|
File details
Details for the file unstable_rl-0.2.0-py3-none-any.whl.
File metadata
- Download URL: unstable_rl-0.2.0-py3-none-any.whl
- Upload date:
- Size: 41.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.10.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
d5bce20eb9f4d45c2de86cc62ca501a056686b7190c0a89b1b4d7f5f2b29371e
|
|
| MD5 |
1823cabb5479af808b06c668305be286
|
|
| BLAKE2b-256 |
7c4486a9752f366f9c6dea3ff7b43f93279e289db5bf55f2a86c14830a495487
|







