Generate SQL queries from natural language

Project description
| GitHub | PyPI | Documentation | Gurubase |
|---|---|---|---|
 |
 |
 |
 |
Vanna
Vanna is an MIT-licensed open-source Python RAG (Retrieval-Augmented Generation) framework for SQL generation and related functionality.
https://github.com/vanna-ai/vanna/assets/7146154/1901f47a-515d-4982-af50-f12761a3b2ce
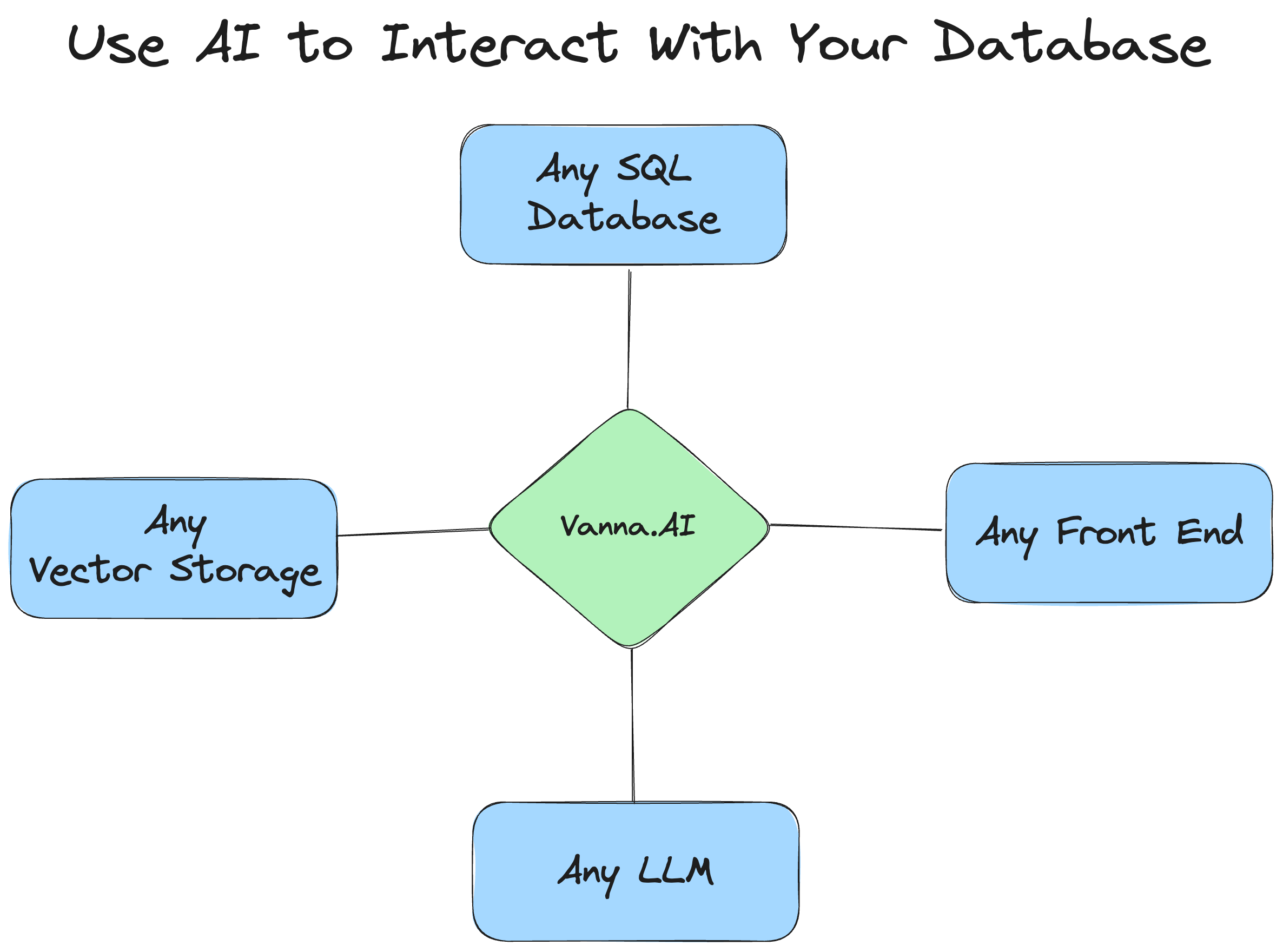
How Vanna works
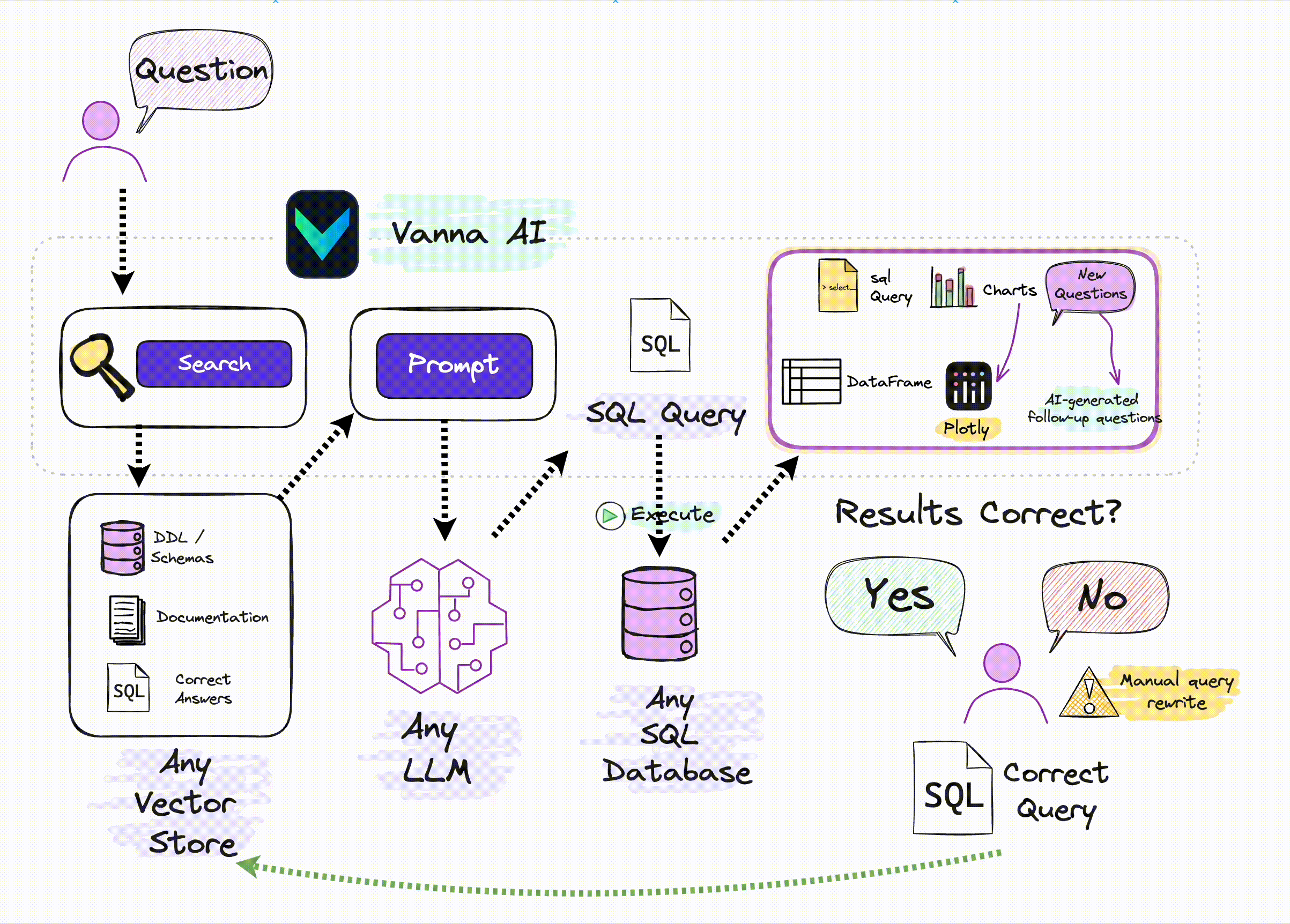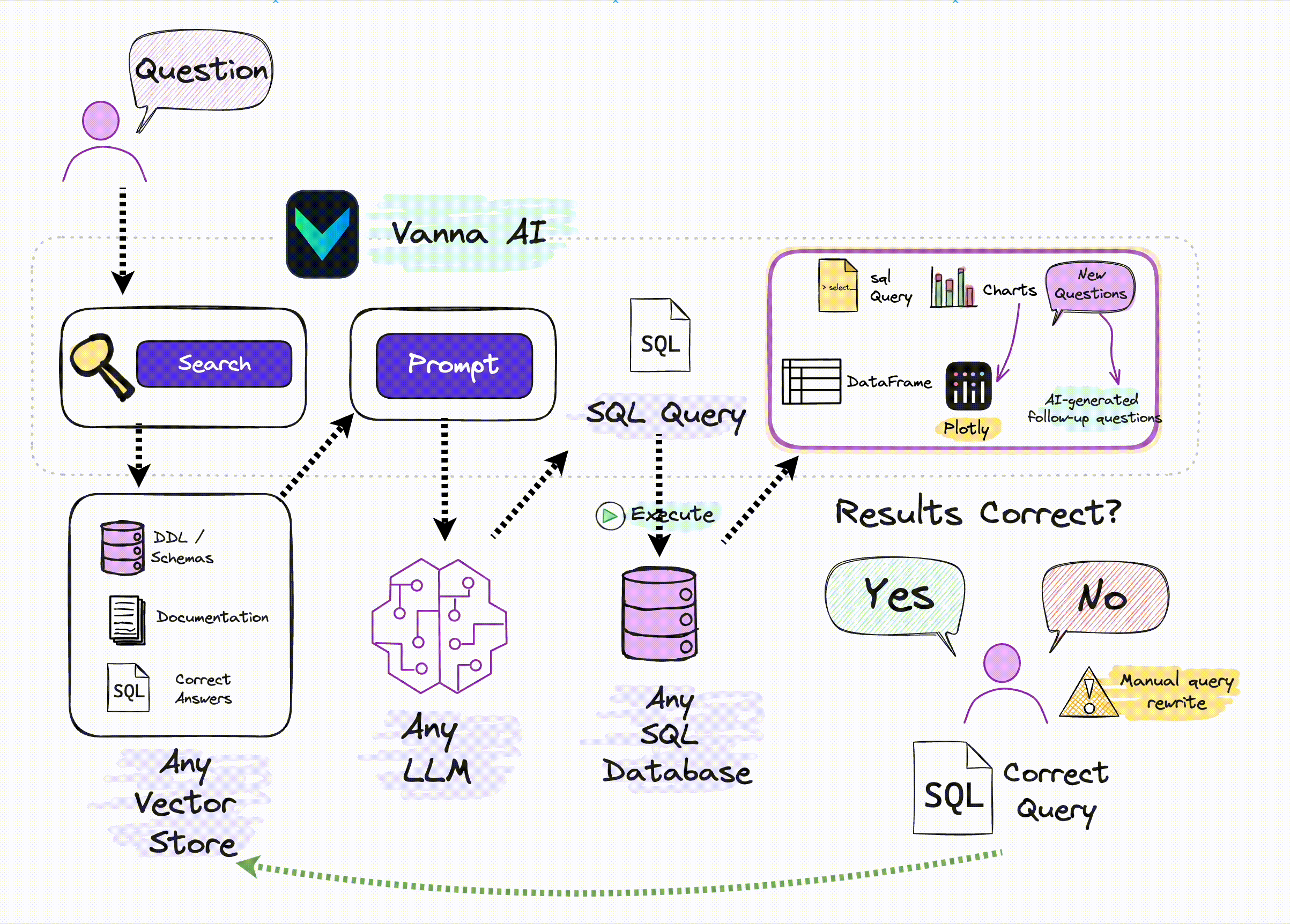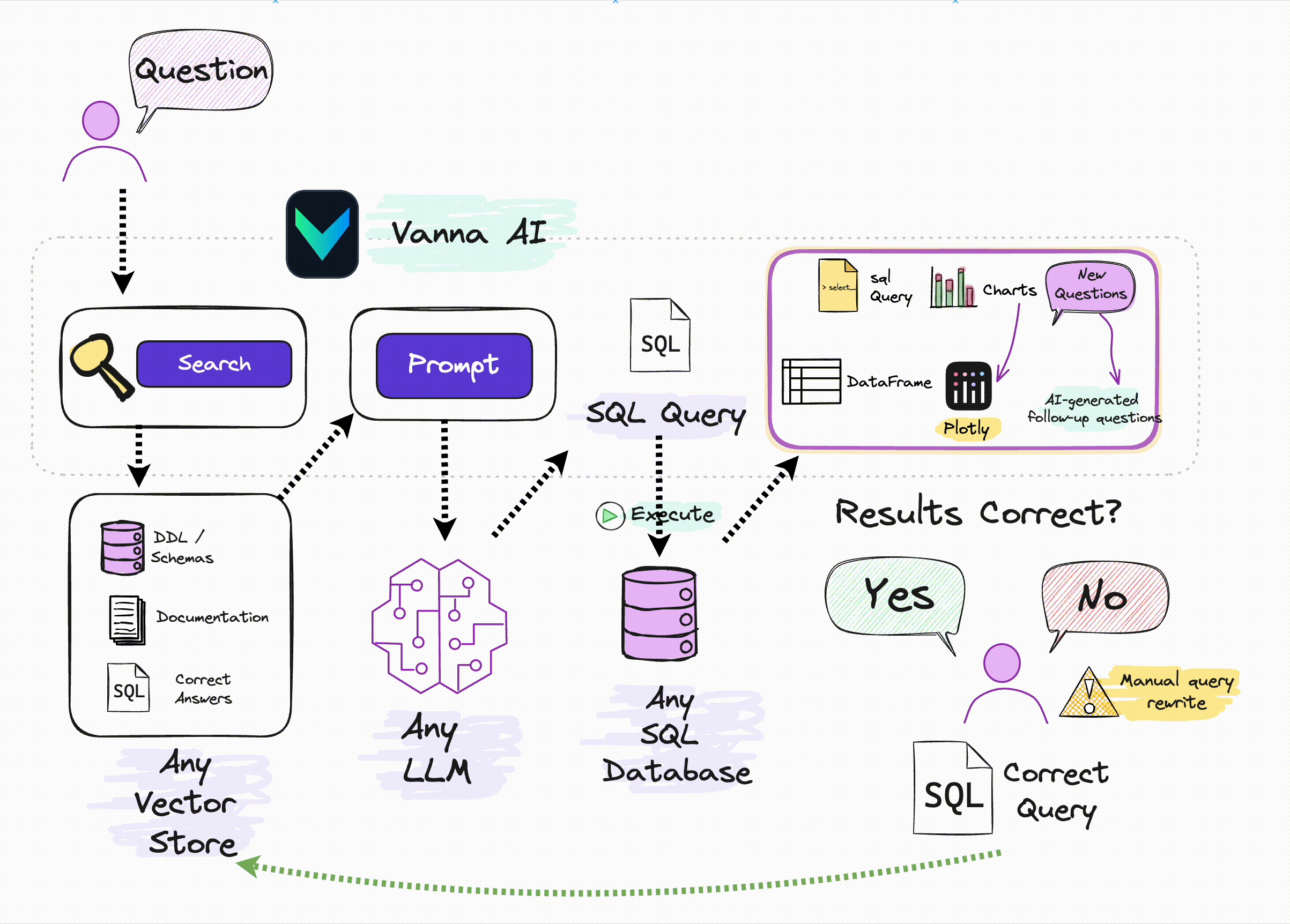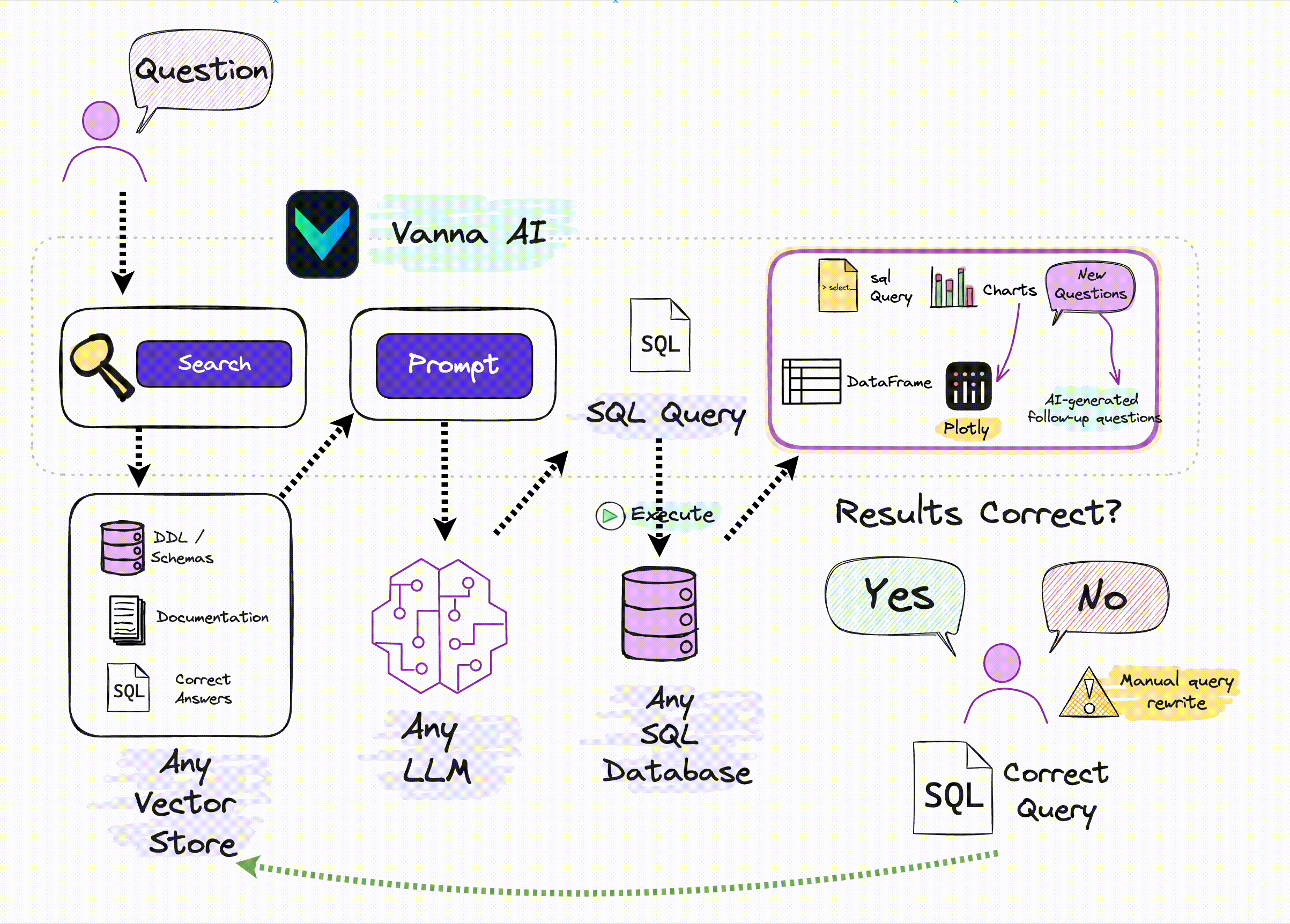
Vanna works in two easy steps - train a RAG "model" on your data, and then ask questions which will return SQL queries that can be set up to automatically run on your database.
- Train a RAG "model" on your data.
- Ask questions.

If you don't know what RAG is, don't worry -- you don't need to know how this works under the hood to use it. You just need to know that you "train" a model, which stores some metadata and then use it to "ask" questions.
See the base class for more details on how this works under the hood.
User Interfaces
These are some of the user interfaces that we've built using Vanna. You can use these as-is or as a starting point for your own custom interface.
Supported LLMs
Supported VectorStores
Supported Databases
- PostgreSQL
- MySQL
- PrestoDB
- Apache Hive
- ClickHouse
- Snowflake
- Oracle
- Microsoft SQL Server
- BigQuery
- SQLite
- DuckDB
Getting started
See the documentation for specifics on your desired database, LLM, etc.
If you want to get a feel for how it works after training, you can try this Colab notebook.
Install
pip install vanna
There are a number of optional packages that can be installed so see the documentation for more details.
Import
See the documentation if you're customizing the LLM or vector database.
# The import statement will vary depending on your LLM and vector database. This is an example for OpenAI + ChromaDB
from vanna.openai.openai_chat import OpenAI_Chat
from vanna.chromadb.chromadb_vector import ChromaDB_VectorStore
class MyVanna(ChromaDB_VectorStore, OpenAI_Chat):
def __init__(self, config=None):
ChromaDB_VectorStore.__init__(self, config=config)
OpenAI_Chat.__init__(self, config=config)
vn = MyVanna(config={'api_key': 'sk-...', 'model': 'gpt-4-...'})
# See the documentation for other options
Training
You may or may not need to run these vn.train commands depending on your use case. See the documentation for more details.
These statements are shown to give you a feel for how it works.
Train with DDL Statements
DDL statements contain information about the table names, columns, data types, and relationships in your database.
vn.train(ddl="""
CREATE TABLE IF NOT EXISTS my-table (
id INT PRIMARY KEY,
name VARCHAR(100),
age INT
)
""")
Train with Documentation
Sometimes you may want to add documentation about your business terminology or definitions.
vn.train(documentation="Our business defines XYZ as ...")
Train with SQL
You can also add SQL queries to your training data. This is useful if you have some queries already laying around. You can just copy and paste those from your editor to begin generating new SQL.
vn.train(sql="SELECT name, age FROM my-table WHERE name = 'John Doe'")
Asking questions
vn.ask("What are the top 10 customers by sales?")
You'll get SQL
SELECT c.c_name as customer_name,
sum(l.l_extendedprice * (1 - l.l_discount)) as total_sales
FROM snowflake_sample_data.tpch_sf1.lineitem l join snowflake_sample_data.tpch_sf1.orders o
ON l.l_orderkey = o.o_orderkey join snowflake_sample_data.tpch_sf1.customer c
ON o.o_custkey = c.c_custkey
GROUP BY customer_name
ORDER BY total_sales desc limit 10;
If you've connected to a database, you'll get the table:
| CUSTOMER_NAME | TOTAL_SALES | |
|---|---|---|
| 0 | Customer#000143500 | 6757566.0218 |
| 1 | Customer#000095257 | 6294115.3340 |
| 2 | Customer#000087115 | 6184649.5176 |
| 3 | Customer#000131113 | 6080943.8305 |
| 4 | Customer#000134380 | 6075141.9635 |
| 5 | Customer#000103834 | 6059770.3232 |
| 6 | Customer#000069682 | 6057779.0348 |
| 7 | Customer#000102022 | 6039653.6335 |
| 8 | Customer#000098587 | 6027021.5855 |
| 9 | Customer#000064660 | 5905659.6159 |
You'll also get an automated Plotly chart:

RAG vs. Fine-Tuning
RAG
- Portable across LLMs
- Easy to remove training data if any of it becomes obsolete
- Much cheaper to run than fine-tuning
- More future-proof -- if a better LLM comes out, you can just swap it out
Fine-Tuning
- Good if you need to minimize tokens in the prompt
- Slow to get started
- Expensive to train and run (generally)
Why Vanna?
- High accuracy on complex datasets.
- Vanna’s capabilities are tied to the training data you give it
- More training data means better accuracy for large and complex datasets
- Secure and private.
- Your database contents are never sent to the LLM or the vector database
- SQL execution happens in your local environment
- Self learning.
- If using via Jupyter, you can choose to "auto-train" it on the queries that were successfully executed
- If using via other interfaces, you can have the interface prompt the user to provide feedback on the results
- Correct question to SQL pairs are stored for future reference and make the future results more accurate
- Supports any SQL database.
- The package allows you to connect to any SQL database that you can otherwise connect to with Python
- Choose your front end.
- Most people start in a Jupyter Notebook.
- Expose to your end users via Slackbot, web app, Streamlit app, or a custom front end.
Extending Vanna
Vanna is designed to connect to any database, LLM, and vector database. There's a VannaBase abstract base class that defines some basic functionality. The package provides implementations for use with OpenAI and ChromaDB. You can easily extend Vanna to use your own LLM or vector database. See the documentation for more details.
Vanna in 100 Seconds
https://github.com/vanna-ai/vanna/assets/7146154/eb90ee1e-aa05-4740-891a-4fc10e611cab
More resources
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file vanna_danish-0.7.9.2.tar.gz.
File metadata
- Download URL: vanna_danish-0.7.9.2.tar.gz
- Upload date:
- Size: 193.4 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.11.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6889c7d56046a5e2a81b01c65cb126689aff15fb18cc7142c8fa0d776ef6a5b2
|
|
| MD5 |
c9834173ef282559b11d9e753f4540f5
|
|
| BLAKE2b-256 |
a53b34aaea4978ba301a927d806274eca0ce49ccd3c24a043fcd3d4bf3e10e8d
|
File details
Details for the file vanna_danish-0.7.9.2-py3-none-any.whl.
File metadata
- Download URL: vanna_danish-0.7.9.2-py3-none-any.whl
- Upload date:
- Size: 213.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.11.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
fb0b4197df47c334e62bac99381b8eb5311870a30ed925db8af8141d8583367f
|
|
| MD5 |
427f6cfc53e6f7933577d004b294a22f
|
|
| BLAKE2b-256 |
6383a904f8ffadc9d3e6529f49652d7cdc98f849322ceffd9b57692c291d82dc
|







