VANPY – Voice Analysis framework in Python

Project description
VANPY
VANPY (Voice Analysis framework in Python) is a flexible and extensible framework for voice analysis, feature extraction, and model inference. It provides a modular pipeline architecture for processing audio segments with near- and state-of-the-art deep learning models.
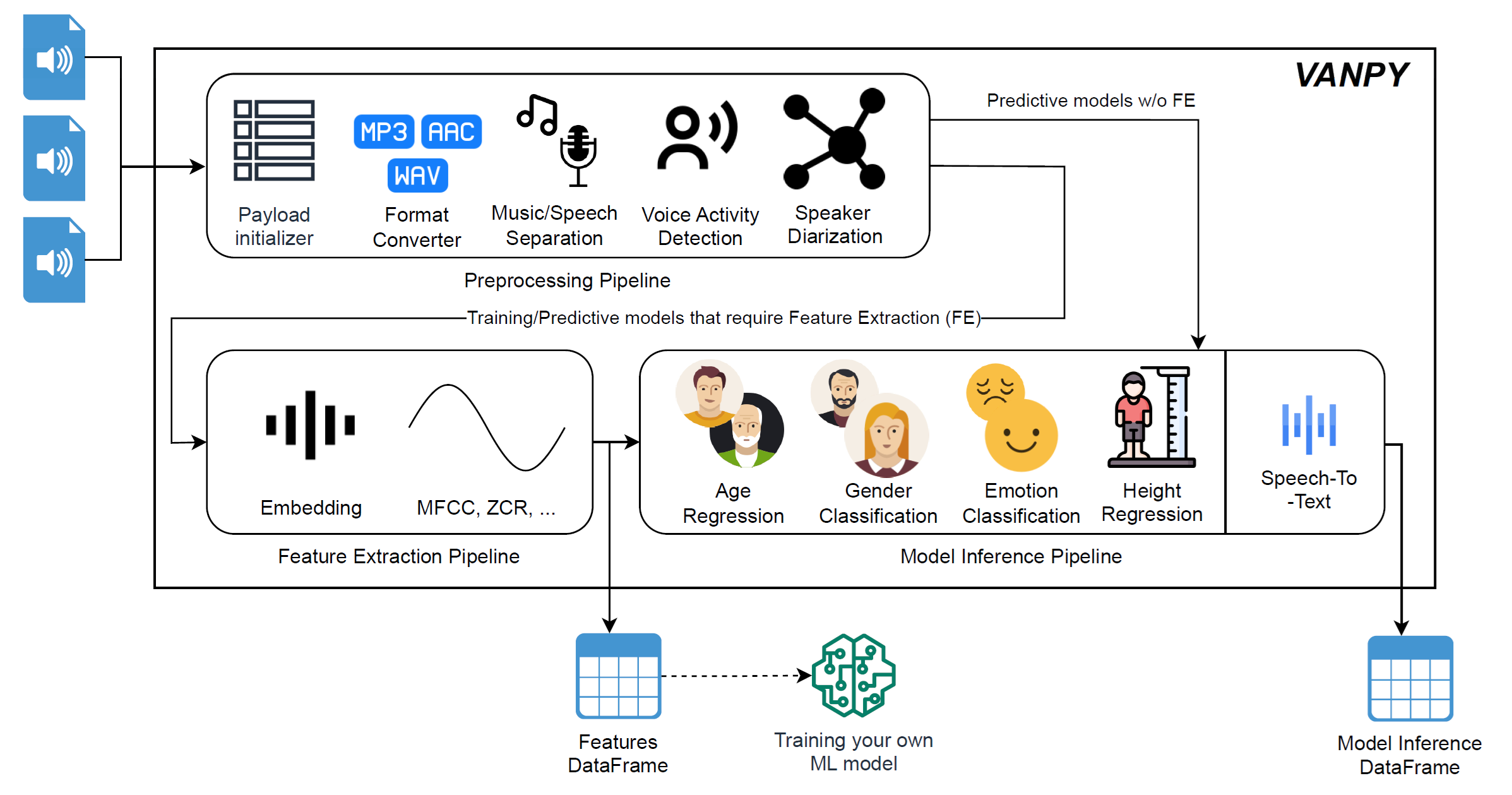
Architecture
VANPY consists of three optional pipelines that can be used independently or in combination:
- Preprocessing Pipeline: Handles audio format conversion and voice segment extraction
- Feature Extraction Pipeline: Generates feature/latent vectors from voice segments
- Model Inference Pipeline
You can use these pipelines flexibly based on your needs:
- Use only preprocessing for voice separation
- Combine preprocessing and classification for direct audio analysis
- Use all pipelines for complete feature extraction and classification
Models Trained as part of the VANPY project
| Task | Dataset | Performance |
|---|---|---|
| Gender Identification (Accuracy) | VoxCeleb2 | 98.9% |
| Mozilla Common Voice v10.0 | 92.3% | |
| TIMIT | 99.6% | |
| Emotion Recognition (Accuracy) | RAVDESS (8-class) | 84.71% |
| RAVDESS (7-class) | 86.24% | |
| Age Estimation (MAE in years) | VoxCeleb2 | 7.88 |
| TIMIT | 4.95 | |
| Combined VoxCeleb2-TIMIT | 6.93 | |
| Height Estimation (MAE in cm) | VoxCeleb2 | 6.01 |
| TIMIT | 6.02 |
All of the models can be used as a part of the VANPY pipeline or separately and are available on 🤗HuggingFace
Configuration
Environment Setup
- Create a
pipeline.yamlconfiguration file. You can use thesrc/pipeline.yamlas a template. - For HuggingFace models (Pyannote components), create a
.envfile:
huggingface_ACCESS_TOKEN=<your_token>
- Pipelines examples are available in
src/run.py.
Installation with uv
VANPY now leverages the uv package manager for ultra-fast, reproducible dependency management.
The pyproject.toml already contains all dependency metadata, so no requirements.txt is needed.
Prerequisites
- Python 3.8+
- uv – install via
pip install uv/brew install uv/sudo snap install astral-uv --classic
1 · Create & activate a virtual environment (recommended)
uv venv .venv --python 3.11
# Linux/macOS
source .venv/bin/activate
# Windows PowerShell
.\.venv\Scripts\Activate.ps1
2 · Install the core (CPU) dependencies
uv sync
3 · Choose CPU or GPU build
cpu and gpu extras are mutually exclusive (this rule is enforced in pyproject.toml).
# Explicitly request CPU wheels (also default)
uv sync --extra cpu
# Install GPU wheels (CUDA 11.7)
uv sync --extra gpu
4 · Add optional component extras
Pass one or many --extra flags to pull in additional capabilities:
| Extra flag | Unlocks component(s) |
|---|---|
librosa |
LibrosaFeaturesExtractor |
speechbrain_embedding |
SpeechBrainEmbedding |
vanpy_models |
Pre-trained VANPY TensorFlow models |
pyannote |
Pyannote-based VAD / SD / Embedding |
wav2vec2 |
Wav2Vec2-based STT & emotion components |
whisper |
OpenAI Whisper STT component |
yamnet |
Google YAMNet audio classifier |
ina |
INA Voice Separator |
Example installations:
# Librosa + SpeechBrain on CPU
uv sync --extra librosa --extra speechbrain_embedding
# Everything + GPU
uv sync --extra gpu \
--extra librosa \
--extra speechbrain_embedding \
--extra vanpy_models \
--extra pyannote \
--extra wav2vec2 \
--extra whisper \
--extra yamnet \
--extra ina
Components
Each component expects as an input and returns as an output a ComponentPayload object.
Each component supports:
- Batch processing (if applicable)
- Progress tracking
- Performance monitoring and logging
- Incremental processing (skip already processed files)
- GPU acceleration where applicable
- Configurable parameters
Preprocessing Components
| Component | Description |
|---|---|
| Filelist-DataFrame Creator | Initializes data pipeline by creating a DataFrame of audio file paths. Supports both directory scanning and loading from existing CSV files. Manages path metadata for downstream components. |
| WAV Converter | Standardizes audio format to WAV with configurable parameters including bit rate (default: 256k), channels (default: mono), sample rate (default: 16kHz), and codec (default: PCM 16-bit). Uses FFMPEG for robust conversion. |
| WAV Splitter | Handles large audio files by splitting them into manageable segments based on either duration or file size limits. Maintains audio quality and creates properly labeled segments with original file references. |
| INA Voice Separator | Separates audio into voice and non-voice segments, distinguishing between male and female speakers. Filters out non-speech content while preserving speaker gender information. |
| Pyannote VAD | Performs Voice Activity Detection using Pyannote's state-of-the-art deep learning model. Identifies and extracts speech segments with configurable sensitivity. |
| Silero VAD | Alternative Voice Activity Detection using Silero's efficient model. Optimized for real-time performance with customizable parameters. |
| Pyannote SD | Speaker Diarization component that identifies and separates different speakers in audio. Creates individual segments for each speaker with timing information. Supports overlapping speech handling. |
| MetricGAN SE | Speech Enhancement using MetricGAN+ model from SpeechBrain. Reduces background noise and improves speech clarity. |
| SepFormer SE | Speech Enhancement using SepFormer model, specialized in separating speech from complex background noise. |
Feature Extraction Components
| Component | Description |
|---|---|
| Librosa Features Extractor | Comprehensive audio feature extraction using the Librosa library. Supports multiple feature types including: MFCC (Mel-frequency cepstral coefficients), Delta-MFCC, zero-crossing rate, spectral features (centroid, bandwidth, contrast, flatness), fundamental frequency (F0), and tonnetz. |
| Pyannote Embedding | Generates speaker embeddings using Pyannote's deep learning models. Uses sliding window analysis with configurable duration and step size. Outputs high-dimensional embeddings optimized for speaker differentiation. |
| SpeechBrain Embedding | Extracts neural embeddings using SpeechBrain's pretrained models, particularly the ECAPA-TDNN architecture (default: spkrec-ecapa-voxceleb). |
Model Inference Components
| Component | Description |
|---|---|
| VanpyGender Classifier | SVM-based binary gender classification using speech embeddings. Supports two models: ECAPA-TDNN (192-dim) and XVECT (512-dim) embeddings from SpeechBrain. Trained on VoxCeleb2 dataset with optimized hyperparameters. Provides both verbal ('female'/'male') and numeric label options. |
| VanpyAge Regressor | Multi-architecture age estimation supporting SVR and ANN models. Features multiple variants: pure SpeechBrain embeddings (192-dim), combined SpeechBrain and Librosa features (233-dim), and dataset-specific models (VoxCeleb2/TIMIT). |
| VanpyEmotion Classifier | 7-class SVM emotion classifier trained on RAVDESS dataset using SpeechBrain embeddings. Classifies emotions into: angry, disgust, fearful, happy, neutral/calm, sad, surprised. |
| IEMOCAP Emotion | SpeechBrain-based emotion classifier trained on the IEMOCAP dataset. Uses Wav2Vec2 for feature extraction. Supports four emotion classes: angry, happy, neutral, sad. |
| Wav2Vec2 ADV | Advanced emotion analysis using Wav2Vec2, providing continuous scores for arousal, dominance, and valence dimensions. |
| Wav2Vec2 STT | Speech-to-text transcription using Facebook's Wav2Vec2 model. |
| Whisper STT | OpenAI's Whisper model for robust speech recognition. Supports multiple model sizes and languages. Includes automatic language detection. |
| Cosine Distance Clusterer | a Clustering method that can be used for speaker diarization using cosine similarity metrics. Groups speech segments by speaker identity using embedding similarity. |
| GMM Clusterer | Gaussian Mixture Model-based speaker clustering. |
| Agglomerative Clusterer | Hierarchical clustering for speaker diarization. Uses distance-based merging with configurable threshold and maximum clusters. |
| YAMNet Classifier | Google's YAMNet model for general audio classification. Supports 521 audio classes from AudioSet ontology. |
ComponentPayload Structure
The ComponentPayload class manages data flow between pipeline components:
class ComponentPayload:
metadata: Dict # Pipeline metadata
df: pd.DataFrame # Processing results
Metadata fields
input_path: Path to the input directory (required forFilelistDataFrameCreatorif nodfis provided)paths_column: Column name for audio file pathsall_paths_columns: List of all path columnsfeature_columns: List of feature columnsmeta_columns: List of metadata columnsclassification_columns: List of classification columns
df fields
-
df: pd.DataFrameIncludes all the collected information through the preprocessing and classification
- each preprocessor adds a column of paths where the processed files are hold
- embedding/feature extraction components add the embedding/features columns
- each model adds a model-results column
Key Methods
get_features_df(): Extract features DataFrameget_classification_df(): Extract classification results DataFrame
Coming Soon
- Custom classifier integration guide
- Additional preprocessing components
- Extended model support
- Newer python and dependencies version support
Citing VANPY
Please, cite VANPY if you use it
@misc{koushnir2025vanpyvoiceanalysisframework,
title={VANPY: Voice Analysis Framework},
author={Gregory Koushnir and Michael Fire and Galit Fuhrmann Alpert and Dima Kagan},
year={2025},
eprint={2502.17579},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2502.17579},
}
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file vanpy-0.92.18.tar.gz.
File metadata
- Download URL: vanpy-0.92.18.tar.gz
- Upload date:
- Size: 76.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.9.21
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
56bda36eeb1582a3c17b348565be8ca8bbde2776a39d7cff88caf38b3d330a47
|
|
| MD5 |
645cc4db791d52ae603d91550b9d8308
|
|
| BLAKE2b-256 |
7c354b85db1529ba4bd35f7cf922fd7601c994705da28821c588d52ff114998f
|
File details
Details for the file vanpy-0.92.18-py3-none-any.whl.
File metadata
- Download URL: vanpy-0.92.18-py3-none-any.whl
- Upload date:
- Size: 102.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.9.21
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a3f07c834b4dcf4bcb8fd438d9020f8a6e192833df93dd9a2fe4d948bec1086e
|
|
| MD5 |
4565c1728503affa3254b36fc9e64447
|
|
| BLAKE2b-256 |
347c5fc54e223fed8e97132a696175beb152d8acda9c61f5a615ff76f7f37dae
|







