A bioinformatics tool for viral genome analysis and characterization.

Project description

A pipeline for viral diversity analysis
Introduction
ViralQuest is a Python-based bioinformatics pipeline designed to detect, identify, and characterize viral sequences from assembled contig datasets. It streamlines the analysis of metagenomic or transcriptomic data by integrating multiple steps—such as sequence alignment, taxonomic classification, and annotation—into a cohesive and automated workflow. ViralQuest is particularly useful for virome studies, enabling researchers to uncover viral diversity, assess potential host-virus interactions, and explore the ecological or clinical significance of detected viruses.
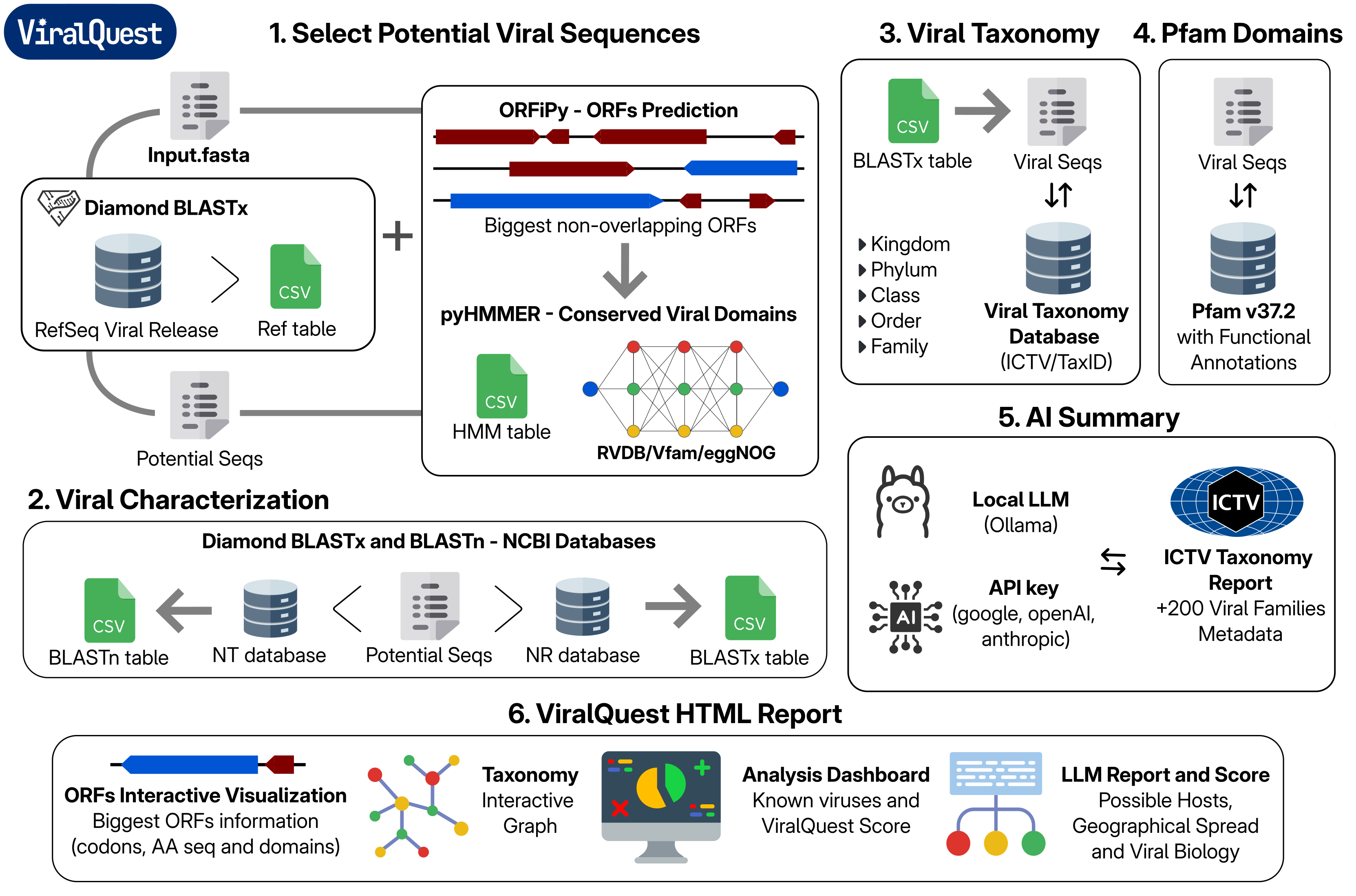
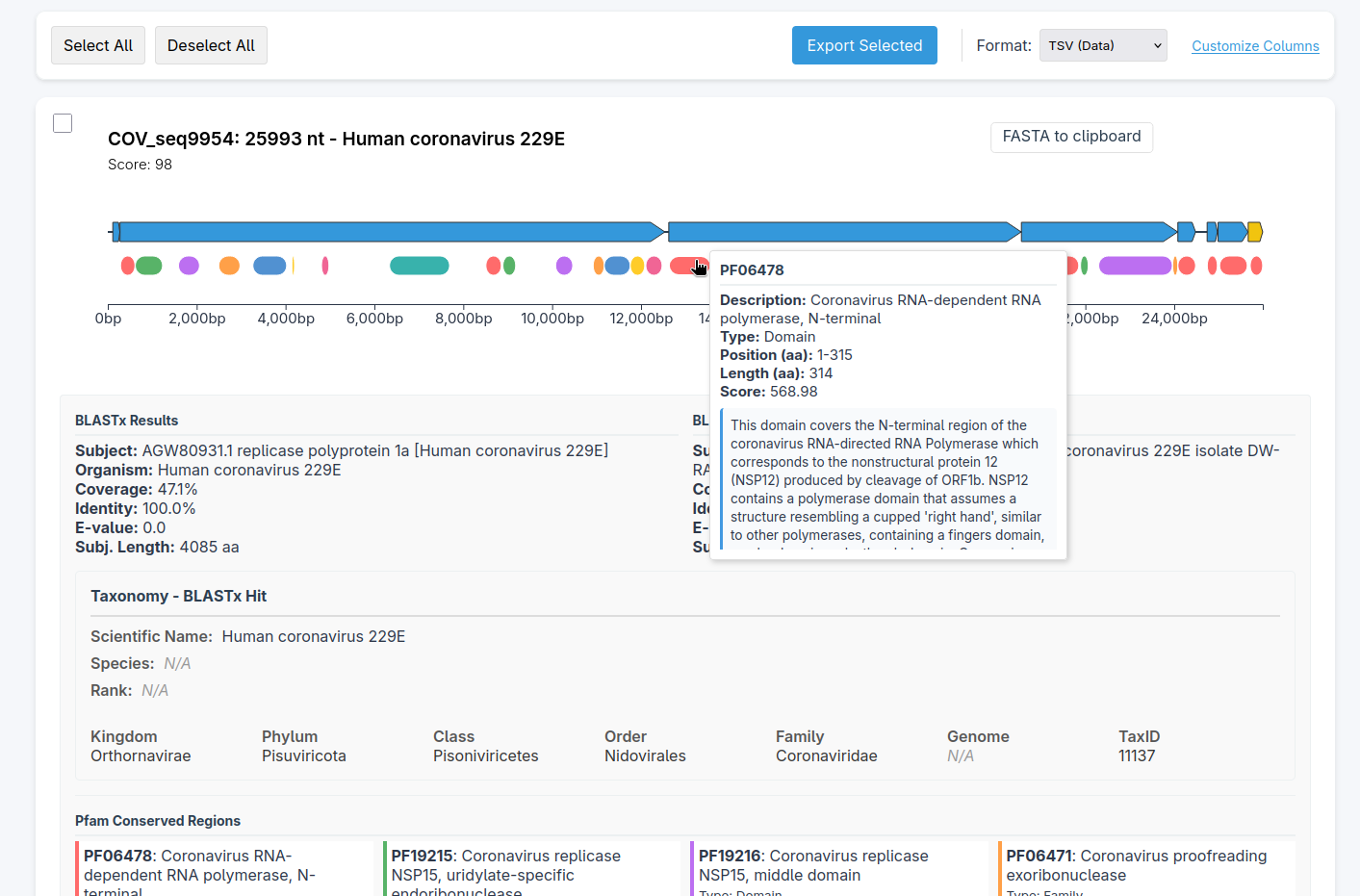
HTML Output
Example of HTML Viral Report Output (Click Here)
⚠️ Warning: The HTML file may have some bugs in resolutions below 1920x1080p.
Setup
Install via PyPI
Use pip to install ViralQuest
pip install viralquest
Install via conda (Manually)
You can install conda here
Create conda enviroment
conda create -n viralquest python=3.12
Activate conda enviroment
conda activate viralquest
Clone the repository from GitHub:
git clone https://github.com/gabrielvpina/viralquest.git
Go to directory:
cd viralquest
Execute the install.py script:
python install.py
Check if ViralQuest is installed:
viralquest.py --help
Install via Docker
Clone the repository from GitHub:
git clone https://github.com/gabrielvpina/viralquest.git
cd viralquest
Build the Dockerfile:
docker build -t viralquest .
Create an alias to use viralquest:
alias viralquest.py='docker run --rm -it -v $(pwd):/workspace -v /run/media:/run/media -v /home:/home --user $(id -u):$(id -g) -w /workspace -e TERM=$TERM -e FORCE_COLOR=1 viralquest conda run -n viralquest python -u /app/viralquest.py'
OR save the alias, if is necessary log out the session:
echo "alias viralquest.py='docker run --rm -it -v $(pwd):/workspace -v /run/media:/run/media -v /home:/home --user $(id -u):$(id -g) -w /workspace -e TERM=$TERM -e FORCE_COLOR=1 viralquest conda run -n viralquest python -u /app/viralquest.py'" >> ~/.bashrc
Verify if it works:
viralquest.py --help
Note: Docker instalation is still under development, some of the debugs and responses of CLI interface are unavailable.
Install Databases
RefSeq Viral release
The RefSeq viral release is a curated collection of viral genome and protein sequences provided by the NCBI Reference Sequence (RefSeq) database. It includes high-quality, non-redundant, and well-annotated reference sequences for viruses, maintained and updated regularly by NCBI. The required file is viral.1.protein.faa.gz, download via this link.
- Convert the fasta file to a Diamond Database (.dmnd):
diamond makedb --in viral.1.protein.faa --db viralDB.dmnd
BLAST nr/nt Databases
The BLAST nr (non-redundant protein) and nt (nucleotide) databases are essential resources for viral identification. The nt database is useful for identifying viral genomes or transcripts using nucleotide similarity, while nr is especially powerful for detecting and annotating viral proteins, even in divergent or novel viruses, through translated searches like blastx. Download the nr/nt databases in fasta format via this link
nr database
- The file
nr.gzis the nr database in FASTA
wget https://ftp.ncbi.nlm.nih.gov/blast/db/FASTA/nr.gz
-
Decompress the file with
gunzip nr.gzcommand. -
Convert the fasta file to a Diamond Database (.dmnd):
diamond makedb --in nr --db nr.dmnd
⚠️ Warning: Check the version of diamond, make sure that is the same version or higher then the used to build the RefSeq Viral Release
.dmndfile.
nt database
- The
nt.gzfile correspond to nt.fasta
wget https://ftp.ncbi.nlm.nih.gov/blast/db/FASTA/nt.gz
- Decompress the file with
gunzip nt.gzcommand.
Viral HMM Models
Important note
Hidden Markov Model (HMM) models are essential for identifying divergent viral sequences and refining sequence selection.
For this task, three models are available:
- RVDB (Reference Viral DataBase) Protein
- Vfam
- eggNOG
At least one of these models is necessary to run the pipeline. However, it's recommended to use all three concurrently.
The Vfam and eggNOG models are spliced in small models, we must join them in unified models.
Vfam HMM
The VFam HMM models are profile Hidden Markov Models (HMMs) specifically designed for the identification of viral proteins.
Steps to Install
- Download
vfam.hmm.tar.gzvia this link:
wget https://fileshare.lisc.univie.ac.at/vog/vog228/vfam.hmm.tar.gz
- Extract the file:
tar -xzvf vfam.hmm.tar.gz
- Unify all
.hmmmodels in one model:
cat hmm/*.hmm >> vfam228.hmm
Now it's possible to use the vfam228.hmm file in the ViralQuest pipeline!
eggNOG Viral HMM
The eggNOG viral OGs HMM models are part of the eggNOG (evolutionary genealogy of genes: Non-supervised Orthologous Groups) resource and are designed to identify and annotate viral genes and proteins based on orthologous groups (OGs).
Steps to Install
-
Download each viral OGs in the eggNOG Database via this link. The HMM models download are in the last column.
-
Or download the data via this BASH script:
#!/bin/bash
mkdir eggNOG
cd eggNOG
wget http://eggnogdb.embl.de/download/eggnog_4.5/data/viruses/ssRNA/ssRNA.hmm.tar.gz
wget http://eggnogdb.embl.de/download/eggnog_4.5/data/viruses/Retrotranscribing/Retrotranscribing.hmm.tar.gz
wget http://eggnogdb.embl.de/download/eggnog_4.5/data/viruses/dsDNA/dsDNA.hmm.tar.gz
wget http://eggnogdb.embl.de/download/eggnog_4.5/data/viruses/Viruses/Viruses.hmm.tar.gz
wget http://eggnogdb.embl.de/download/eggnog_4.5/data/viruses/Herpesvirales/Herpesvirales.hmm.tar.gz
wget http://eggnogdb.embl.de/download/eggnog_4.5/data/viruses/ssDNA/ssDNA.hmm.tar.gz
wget http://eggnogdb.embl.de/download/eggnog_4.5/data/viruses/ssRNA_positive/ssRNA_positive.hmm.tar.gz
wget http://eggnogdb.embl.de/download/eggnog_4.5/data/viruses/Retroviridae/Retroviridae.hmm.tar.gz
wget http://eggnogdb.embl.de/download/eggnog_4.5/data/viruses/Ligamenvirales/Ligamenvirales.hmm.tar.gz
wget http://eggnogdb.embl.de/download/eggnog_4.5/data/viruses/Caudovirales/Caudovirales.hmm.tar.gz
wget http://eggnogdb.embl.de/download/eggnog_4.5/data/viruses/Mononegavirales/Mononegavirales.hmm.tar.gz
wget http://eggnogdb.embl.de/download/eggnog_4.5/data/viruses/Tymovirales/Tymovirales.hmm.tar.gz
wget http://eggnogdb.embl.de/download/eggnog_4.5/data/viruses/Nidovirales/Nidovirales.hmm.tar.gz
wget http://eggnogdb.embl.de/download/eggnog_4.5/data/viruses/Picornavirales/Picornavirales.hmm.tar.gz
wget http://eggnogdb.embl.de/download/eggnog_4.5/data/viruses/dsRNA/dsRNA.hmm.tar.gz
wget http://eggnogdb.embl.de/download/eggnog_4.5/data/viruses/ssRNA_negative/ssRNA_negative.hmm.tar.gz
for i in *.tar.gz; do tar -zxvf "$i" ;done
Save as download_eggNOG.sh. Now let's execute:
chmod +x download_eggNOG.sh && ./download_eggNOG.sh
- Now join all result files:
cat eggNOG/hmm_files/*.hmm >> eggNOG.hmm
Now it's possible to use the eggNOG.hmm file in the ViralQuest pipeline!
RVDB Viral HMM
The Reference Viral Database (RVDB) is a curated collection of viral sequences, and its protein HMM models—RVDB-prot and RVDB-prot-HMM—are designed to enhance the detection and annotation of viral proteins.
Download RVDB hmm model
- Visit the RVDB Protein database via this link and download the hmm model version 29.0.
- Or download directly via linux termnial:
wget https://rvdb-prot.pasteur.fr/files/U-RVDBv29.0-prot.hmm.xz
- Decompress the model:
unxz -v U-RVDBv29.0-prot.hmm.xz
Now it's possible to use the U-RVDBv29.0-prot.hmm file in the ViralQuest pipeline!
Install Pfam Model
Pfam is a widely used database of protein families, each represented by a profile Hidden Markov Model (HMM). These models are built from curated multiple sequence alignments and represent conserved domains or full-length protein families. Download the version 37.2.
- Download the
Pfam-A.hmm.gzvia this link.
- Or download via Terminal:
wget https://ftp.ebi.ac.uk/pub/databases/Pfam/releases/Pfam37.2/Pfam-A.hmm.gz
- Decompress the file:
gunzip Pfam-A.hmm.gz
Now it's possible to use the Pfam-A.hmm file in the ViralQuest pipeline!
AI Summary
You can use either a local LLM (via Ollama) or an API key to process and integrate viral data — such as BLAST results and HMM characterizations — with the internal ViralQuest database, which includes viral family information from ICTV (International Committee on Taxonomy of Viruses) and ViralZone. This database contains information on over 200 viral families, including details such as host range, geographic distribution, viral vectors, and more. The LLM can summarize this information to provide a broader and more insightful perspective on the viral data.
Install necessary pip modules
pip install ollama langchain langchain-core langchain-ollama langchain-openai langchain-anthropic langchain-google-genai
Install this modules in the existent viralquest conda enviroment.
Local LLM (via Ollama)
You can run a local LLM on your machine using Ollama. However, it is important to select a model that is well-suited for processing the data. In our tests, the smallest model that provided acceptable performance was qwen3:4b. Therefore, we recommend using this model as a minimum requirement for running this type of analysis.
LLM Assistance via API
ViralQuest supports API-based LLMs from Google, OpenAI, and Anthropic, corresponding to the Gemini, ChatGPT, and Claude models, respectively. Please review the usage terms of each service, as a high number of requests in a short period (e.g., 3 to 15 requests per minute, depending on the number of viral sequences) may be subject to rate limits or usage restrictions.
LLM in ViralQuest
The arguments available to use local or API LLMs are:
--model-type
Type of model to use for analysis (ollama, openai, anthropic, google).
--model-name
Name of the model (e.g., "qwen3:4b" for ollama, "gpt-3.5-turbo" for OpenAI).
--api-key
API key for cloud models (required for OpenAI, Anthropic, Google).
This is a use of the arguments with a Local LLM (Ollama):
--model-type ollama --model-name "qwen3:8b"
Now using an API key:
--model-type google --model-name "gemini-2.0-flash" --api-key "12345-My-API-Key_HERE67890"
A tutorial to install a local LLM via ollama or Google Gemini free API is available in the wiki page.
Usage
Query example
This is a structure of viralquest query (without AI summary resource):
python viralquest.py -in SAMPLE.fasta \
-ref viral/release/viralDB.dmnd \
-N path/to/nt/database/nt.fasta \
-dX path/to/nr/diamond/database/nr.dmnd \
-rvdb /path/to/RVDB/hmm/U-RVDBv29.0-prot.hmm \
-eggnog /path/to/eggNOG/hmm/eggNOG.hmm \
-vfam /path/to/Vfam/hmm/Vfam228.hmm \
-pfam /path/to/Pfam/hmm/Pfam-A.hmm \
-cpu 4 -maxORFs 4 \
-out SAMPLE
⚠️ Warning: Check the version of Diamond aligner with
diamond --versionto ensure that the databases use the same version of the diamond blastx executable. The argumentdmnd_pathcan be used to select a specific version of a diamond binary to be used in the pipeline.
Output Files
This is the output directory structure:
INPUT: SAMPLE.fasta
OUTPUT_sample/
├── fasta-files
│ ├── SAMPLE_all_ORFs.fasta
│ ├── SAMPLE_biggest_ORFs.fasta
│ ├── SAMPLE_filtered.fasta
│ ├── SAMPLE_orig.fasta
│ ├── SAMPLE_pfam_ORFs.fasta
│ ├── SAMPLE_viralHMM.fasta
│ ├── SAMPLE_viralSeq.fasta
│ └── SAMPLE_vq.fasta
├── hit_tables
│ ├── SAMPLE_all-BLAST.csv
│ ├── SAMPLE_blastn.tsv
│ ├── SAMPLE_blastx.tsv
│ ├── SAMPLE_EggNOG.csv
│ ├── SAMPLE_hmm.csv
│ └── SAMPLE_ref.csv
├── SAMPLE_bestSeqs.json # JSON with BLAST, HMM and ORFs information
├── SAMPLE.log # Some parameters used in the execution of the pipeline
├── SAMPLE_viral-BLAST.csv # BLAST result of viral sequences found
├── SAMPLE_viral.fa # FASTA of viral sequences found
└── SAMPLE_visualization.html # HTML report
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters







