A simple, educational package for fine-tuning Vision Transformers
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
vit-trainer




A simple, educational package for fine-tuning Vision Transformer (ViT) models using PyTorch. Achieves 97.65% accuracy on CIFAR-10 with modern training techniques.
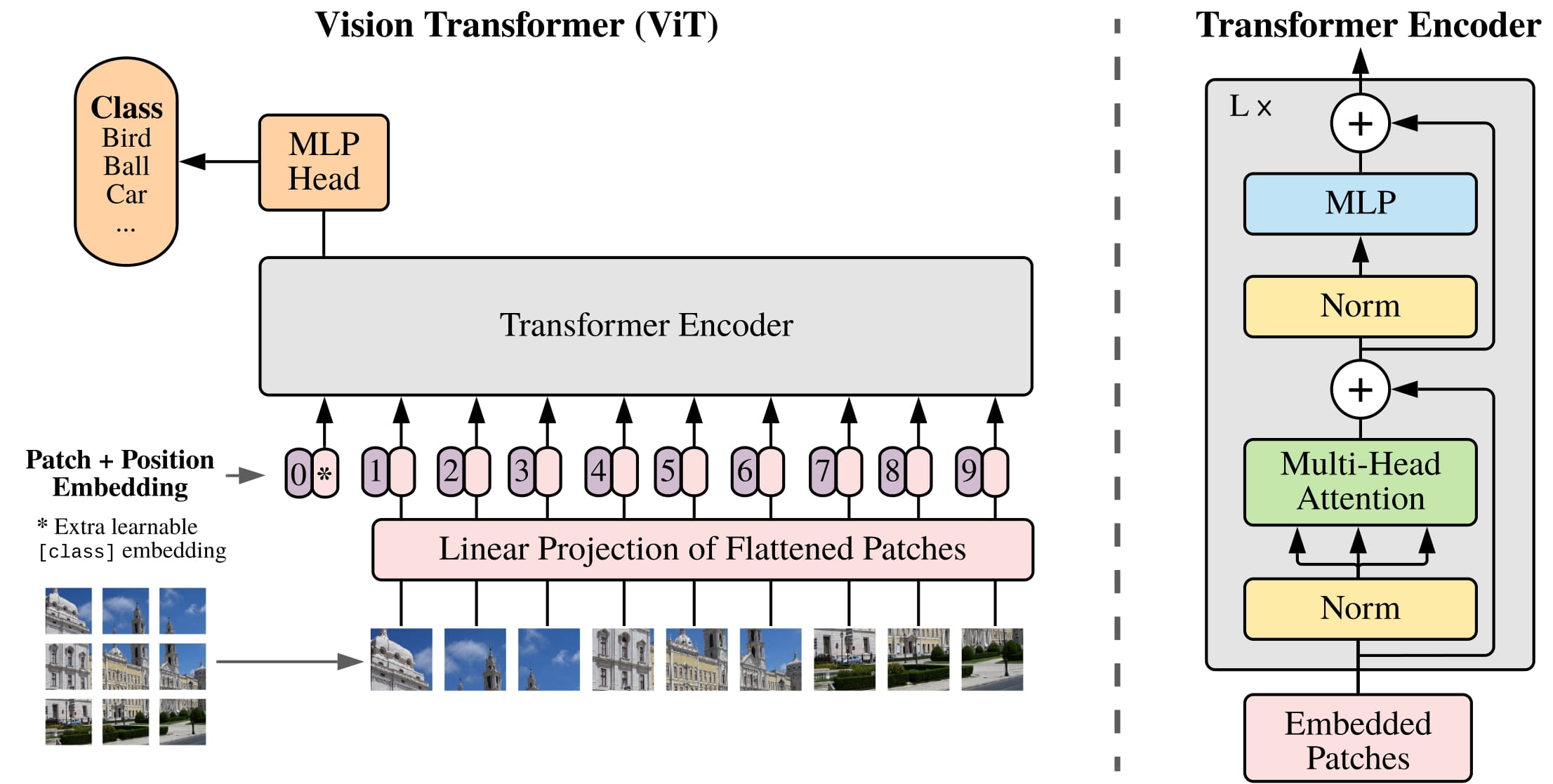
Why vit-trainer?
| vs. timm/transformers | vit-trainer |
|---|---|
| 1000+ model architectures | Focused on ViT fine-tuning |
| Complex APIs | Simple, readable code |
| Research-oriented | Educational + Production ready |
Features:
- Mixed precision training (AMP) for 2-3x speedup
- AdamW optimizer with cosine annealing + warmup
- Attention visualization for interpretability
- ONNX export for deployment
- CLI and Python API
Installation
# Install from source
git clone https://github.com/jman4162/PyTorch-Vision-Transformers-ViT.git
cd PyTorch-Vision-Transformers-ViT
pip install -e .
Optional Dependencies
# Gradio web demo
pip install -e ".[demo]"
# ONNX export
pip install -e ".[export]"
# Development tools (pytest, ruff, black, mypy)
pip install -e ".[dev]"
# Everything
pip install -e ".[all]"
Quick Start
Python API
from vit_trainer import Trainer, load_model, get_cifar10_loaders
# Load data and model
train_loader, val_loader, test_loader = get_cifar10_loaders(batch_size=64)
model = load_model("vit_b_16", num_classes=10)
# Train
trainer = Trainer(model, lr=1e-4, use_amp=True)
history = trainer.fit(train_loader, val_loader, epochs=10)
# Evaluate
loss, accuracy = trainer.evaluate(test_loader)
print(f"Test Accuracy: {accuracy:.2f}%")
Command Line Interface
# Train a model
vit-train train --model vit_b_16 --dataset cifar10 --epochs 10
# Evaluate a trained model
vit-train eval --checkpoint best_model.pt --dataset cifar10 --plot-confusion
# Predict on a single image
vit-train predict --checkpoint best_model.pt --image cat.jpg --show-attention
# Export to ONNX
vit-train export --checkpoint best_model.pt --output model.onnx
Configuration Files
# Use YAML config
vit-train train --config configs/default.yaml
Usage Examples
Training with Custom Settings
from vit_trainer import Trainer, load_model, get_cifar10_loaders, TrainingConfig
# Create config
config = TrainingConfig(
model_variant="vit_b_16",
batch_size=64,
epochs=10,
lr=1e-4,
weight_decay=0.05,
warmup_epochs=2,
patience=3,
use_amp=True,
)
# Train
train_loader, val_loader, _ = get_cifar10_loaders(batch_size=config.batch_size)
model = load_model(config.model_variant, num_classes=10)
trainer = Trainer(
model,
lr=config.lr,
weight_decay=config.weight_decay,
warmup_epochs=config.warmup_epochs,
use_amp=config.use_amp,
)
trainer.fit(train_loader, val_loader, epochs=config.epochs, patience=config.patience)
Attention Visualization
from vit_trainer import visualize_samples_with_attention, CIFAR10_CLASSES
visualize_samples_with_attention(
model,
test_loader.dataset,
CIFAR10_CLASSES,
num_samples=4,
)
Evaluation Metrics
from vit_trainer import get_predictions, compute_metrics, plot_confusion_matrix
y_pred, y_true, probs = get_predictions(model, test_loader)
metrics = compute_metrics(y_true, y_pred, CIFAR10_CLASSES)
print(metrics["classification_report"])
plot_confusion_matrix(y_true, y_pred, CIFAR10_CLASSES)
Loading Trained Models
from vit_trainer import load_model
# Load from checkpoint
model = load_model(
"vit_b_16",
num_classes=10,
checkpoint_path="best_model.pt",
)
ONNX Export
from vit_trainer import load_model, ExportConfig
# Load trained model
model = load_model("vit_b_16", num_classes=10, checkpoint_path="best_model.pt")
# Export to ONNX
config = ExportConfig(output_path="model.onnx", opset_version=14)
config.export(model)
# Or use CLI
# vit-train export --checkpoint best_model.pt --output model.onnx
API Reference
from vit_trainer import (
# Configuration
TrainingConfig, # Training hyperparameters
ExportConfig, # ONNX export settings
# Models
load_model, # Load ViT with pretrained weights
VIT_VARIANTS, # Available model variants
# Data
get_cifar10_loaders, # CIFAR-10 data loaders
get_cifar100_loaders, # CIFAR-100 data loaders
CIFAR10_CLASSES, # Class names
# Training
Trainer, # Training loop with AMP
EarlyStopping, # Early stopping callback
ModelCheckpoint, # Save best model
# Evaluation
evaluate_model, # Loss and accuracy
compute_metrics, # Precision, recall, F1
plot_confusion_matrix, # Visualization
# Visualization
visualize_attention, # Attention heatmaps
)
Project Structure
vit-trainer/
├── vit_trainer/
│ ├── __init__.py # Public API
│ ├── config.py # TrainingConfig dataclass
│ ├── cli.py # Command-line interface
│ ├── data/ # Data loaders and transforms
│ ├── models/ # Model registry and factory
│ ├── training/ # Trainer and callbacks
│ ├── evaluation/ # Metrics and plotting
│ └── visualization/ # Attention maps
├── tests/ # Unit tests (44 tests)
├── configs/ # YAML configurations
├── notebooks/ # Tutorial notebooks
├── app.py # Gradio demo
└── pyproject.toml # Package configuration
ViT Variants
| Variant | Patch Size | Parameters | ImageNet Acc | Use Case |
|---|---|---|---|---|
vit_b_16 |
16x16 | 86M | 81.1% | Best accuracy/speed |
vit_b_32 |
32x32 | 88M | 75.9% | Faster inference |
vit_l_16 |
16x16 | 304M | 79.7% | Higher accuracy |
Training Results
| Metric | Value |
|---|---|
| Test Accuracy | 97.65% |
| Model | vit_b_16 |
| Training Time | ~11 min/epoch (GPU) |
Gradio Demo
# Launch interactive web interface
python app.py
# Opens at http://localhost:7860
Development
# Install dev dependencies
pip install -e ".[dev]"
# Run tests
pytest tests/
# Format code
black vit_trainer/
ruff check vit_trainer/
# Type check
mypy vit_trainer/
Troubleshooting
CUDA Out of Memory
- Reduce batch size:
--batch-size 32or16 - AMP is enabled by default
Slow Training on CPU
- Use Google Colab (free GPU)
- Training on CPU is very slow (~60 min/epoch)
Import Errors
- Make sure to install the package:
pip install -e .
Resources
Contributing
Contributions are welcome! Please feel free to submit a Pull Request.
License
Distributed under the MIT License. See LICENSE for more information.
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file vit_trainer-0.1.0.tar.gz.
File metadata
- Download URL: vit_trainer-0.1.0.tar.gz
- Upload date:
- Size: 30.7 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
82c603bbb2aaba6e1ef906d07e0d630e5d7d2e82ce5af90fa8837a034b14af00
|
|
| MD5 |
558cb7fbc5fa2f4b206a5550dcaa5cba
|
|
| BLAKE2b-256 |
b011ab6905951d64c992b55953417ec4a5a51ff85f406f582434ad35deb755a4
|
Provenance
The following attestation bundles were made for vit_trainer-0.1.0.tar.gz:
Publisher:
publish.yml on jman4162/PyTorch-Vision-Transformers-ViT
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
vit_trainer-0.1.0.tar.gz -
Subject digest:
82c603bbb2aaba6e1ef906d07e0d630e5d7d2e82ce5af90fa8837a034b14af00 - Sigstore transparency entry: 923415549
- Sigstore integration time:
-
Permalink:
jman4162/PyTorch-Vision-Transformers-ViT@88987557db1e2863e65dddd4a3502e5c9bfca567 -
Branch / Tag:
refs/tags/v0.1.0 - Owner: https://github.com/jman4162
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@88987557db1e2863e65dddd4a3502e5c9bfca567 -
Trigger Event:
release
-
Statement type:
File details
Details for the file vit_trainer-0.1.0-py3-none-any.whl.
File metadata
- Download URL: vit_trainer-0.1.0-py3-none-any.whl
- Upload date:
- Size: 27.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
5e515d6e932588392e23cd8ccb3327cfa637672e775839e528602bd986c9733c
|
|
| MD5 |
945a0c7342fb887c0c7254349fc01857
|
|
| BLAKE2b-256 |
2c3e68092b21c915dbcad25121af184842ab86886095272b87a01fcead3de89a
|
Provenance
The following attestation bundles were made for vit_trainer-0.1.0-py3-none-any.whl:
Publisher:
publish.yml on jman4162/PyTorch-Vision-Transformers-ViT
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
vit_trainer-0.1.0-py3-none-any.whl -
Subject digest:
5e515d6e932588392e23cd8ccb3327cfa637672e775839e528602bd986c9733c - Sigstore transparency entry: 923415551
- Sigstore integration time:
-
Permalink:
jman4162/PyTorch-Vision-Transformers-ViT@88987557db1e2863e65dddd4a3502e5c9bfca567 -
Branch / Tag:
refs/tags/v0.1.0 - Owner: https://github.com/jman4162
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@88987557db1e2863e65dddd4a3502e5c9bfca567 -
Trigger Event:
release
-
Statement type:







