VPTQ (Vector Post-Training Quantization) is a novel Post-Training Quantization method.

Project description
VPTQ: Extreme Low-bit Vector Post-Training Quantization for Large Language Models



Efficient, Flexible and Compressing LLM in less than 2bits
- TL;DR
- News
- Installation
- Evaluation
- Algorithm
- Tech Report
- Road Map
- Project main members:
- Acknowledgement
- Publication
- Star History
- Limitation of VPTQ
- Contributing
- Trademarks
TL;DR
Vector Post-Training Quantization (VPTQ) is a novel Post-Training Quantization method that leverages Vector Quantization to high accuracy on LLMs at an extremely low bit-width (<2-bit). VPTQ can compress 70B, even the 405B model, to 1-2 bits without retraining and maintain high accuracy.
- Better Accuracy on 1-2 bits, (405B @ <2bit, 70B @ 2bit)
- Lightweight Quantization Algorithm: only cost ~17 hours to quantize 405B Llama-3.1
- Agile Quantization Inference: low decode overhead, best throughput, and TTFT
News
- [2025-01-13] VPTQ is formly support by Transformers in its wheel package release since v4.48.0.
- [2024-12-20] 🚀 VPTQ ❤️ Huggingface Transformers VPTQ support has been merged into Huggingface Transformers main branch! Check out the commit and our Colab example:
- [2024-12-15] 🌐 Open source community contributes Meta Llama 3.3 70B @ 1-4 bits models
- [2024-11-01] 📦 VPTQ is now available on PyPI! You can install it easily using the command:
pip install vptq. - [2024-10-28] ✨ VPTQ algorithm early-released at algorithm branch, and checkout the tutorial.
- [2024-10-22] 🌐 Open source community contributes Meta Llama 3.1 Nemotron 70B models, check how VPTQ counts 'r' on local GPU. We are continuing to work on quantizing the 4-6 bit versions. Please stay tuned!
- [2024-10-21] 🌐 Open source community contributes Meta Llama 3.1 405B @ 3/4 bits models
- [2024-10-18] 🌐 Open source community contributes Mistral Large Instruct 2407 (123B) models
- [2024-10-14] 🚀 Add early ROCm support.
- [2024-10-06] 🚀 Try VPTQ on Google Colab.
- [2024-10-05] 🚀 Add free Huggingface Demo: Huggingface Demo
- [2024-10-04] ✏️ Updated the VPTQ tech report and fixed typos.
- [2024-09-20] 🌐 Inference code is now open-sourced on GitHub—join us and contribute!
- [2024-09-20] 🎉 VPTQ paper has been accepted for the main track at EMNLP 2024.

Installation
Dependencies
- CUDA toolkit
- python 3.10+
- torch >= 2.2.0
- transformers >= 4.44.0
- Accelerate >= 0.33.0
- flash_attn >= 2.5.0
- latest datasets
- cmake >= 3.18.0
Install VPTQ on Your Machine
Recommendation: To save time on building the package, please install VPTQ directly from the latest release on PyPI:
pip install vptq
or from:
https://github.com/microsoft/VPTQ/releases
Install from PyPI
To install from PyPI, run:
pip install git+https://github.com/microsoft/VPTQ.git --no-build-isolation
Build from Source
If a release package is not available, you can build the package from the source code:
NOTE: Ensure Python dependencies and the CUDA toolkit are installed, and that
nvccis available in yourPATH.
-
Build the wheel:
python setup.py build bdist_wheel # Install the built wheel pip install dist/vptq-xxx.whl # Replace xxx with the version number
-
Clean the build:
python setup.py clean
Example: Run Llama 3.1 70b on RTX4090 (24G @ ~2bits) in real time
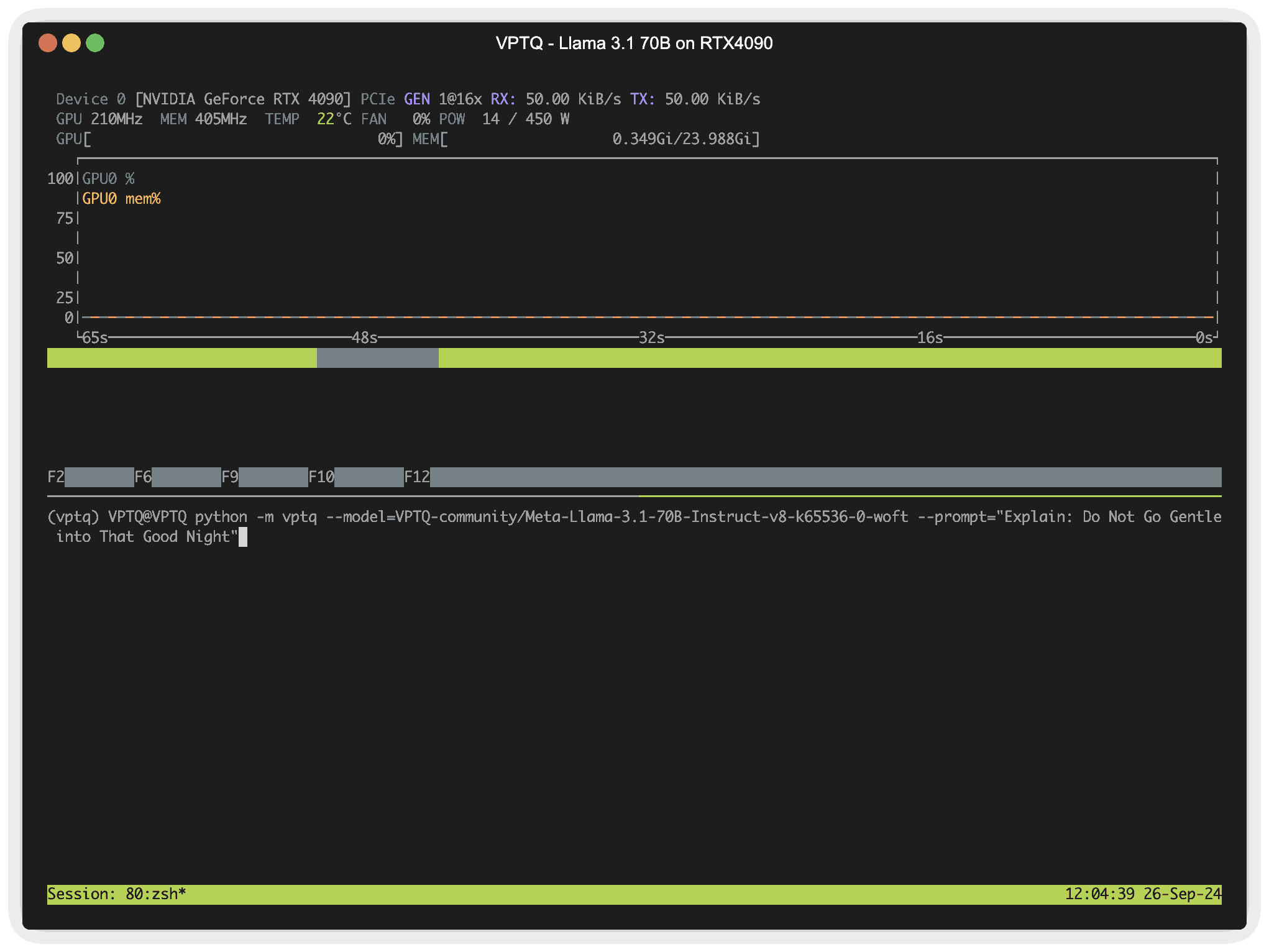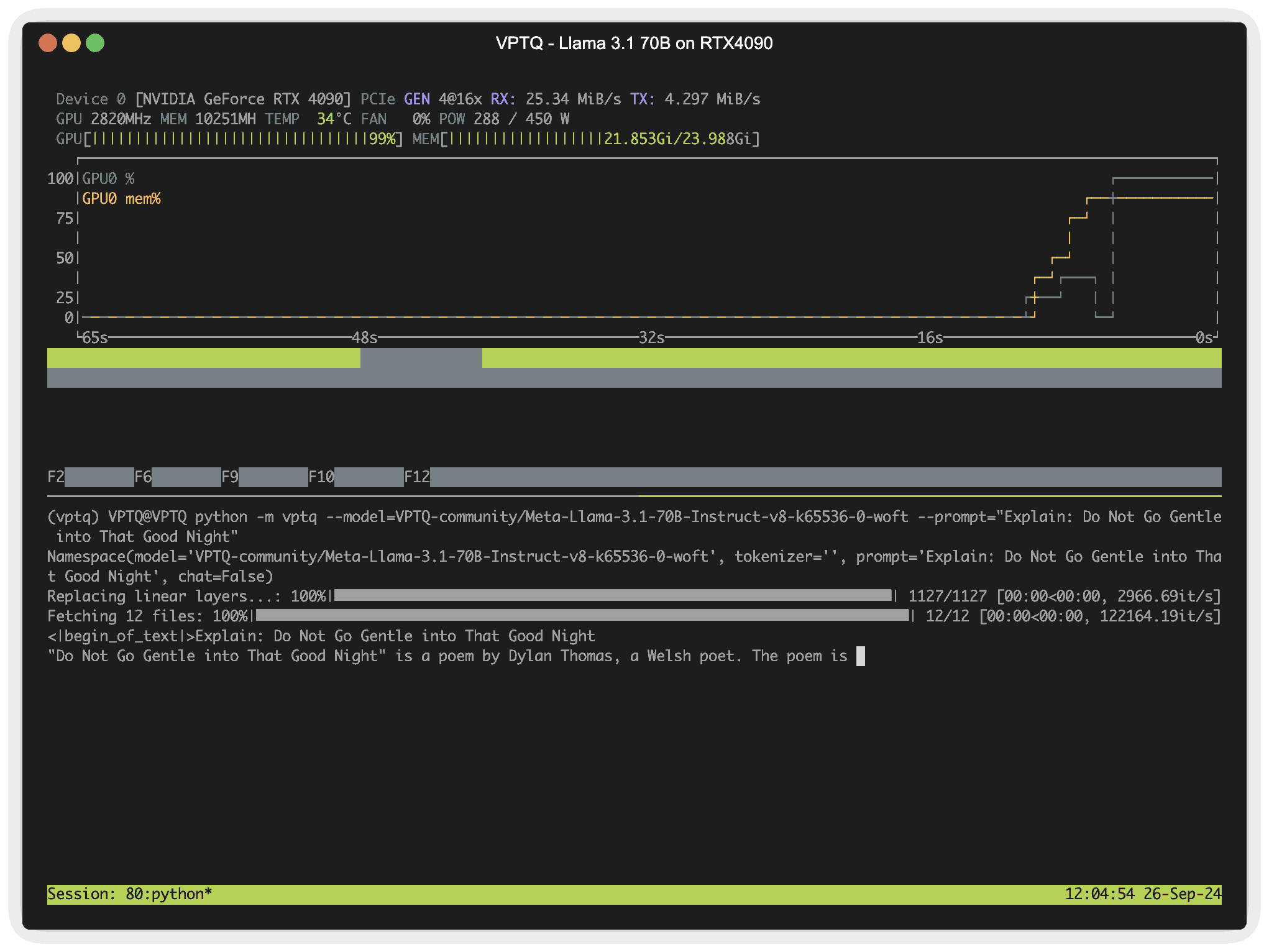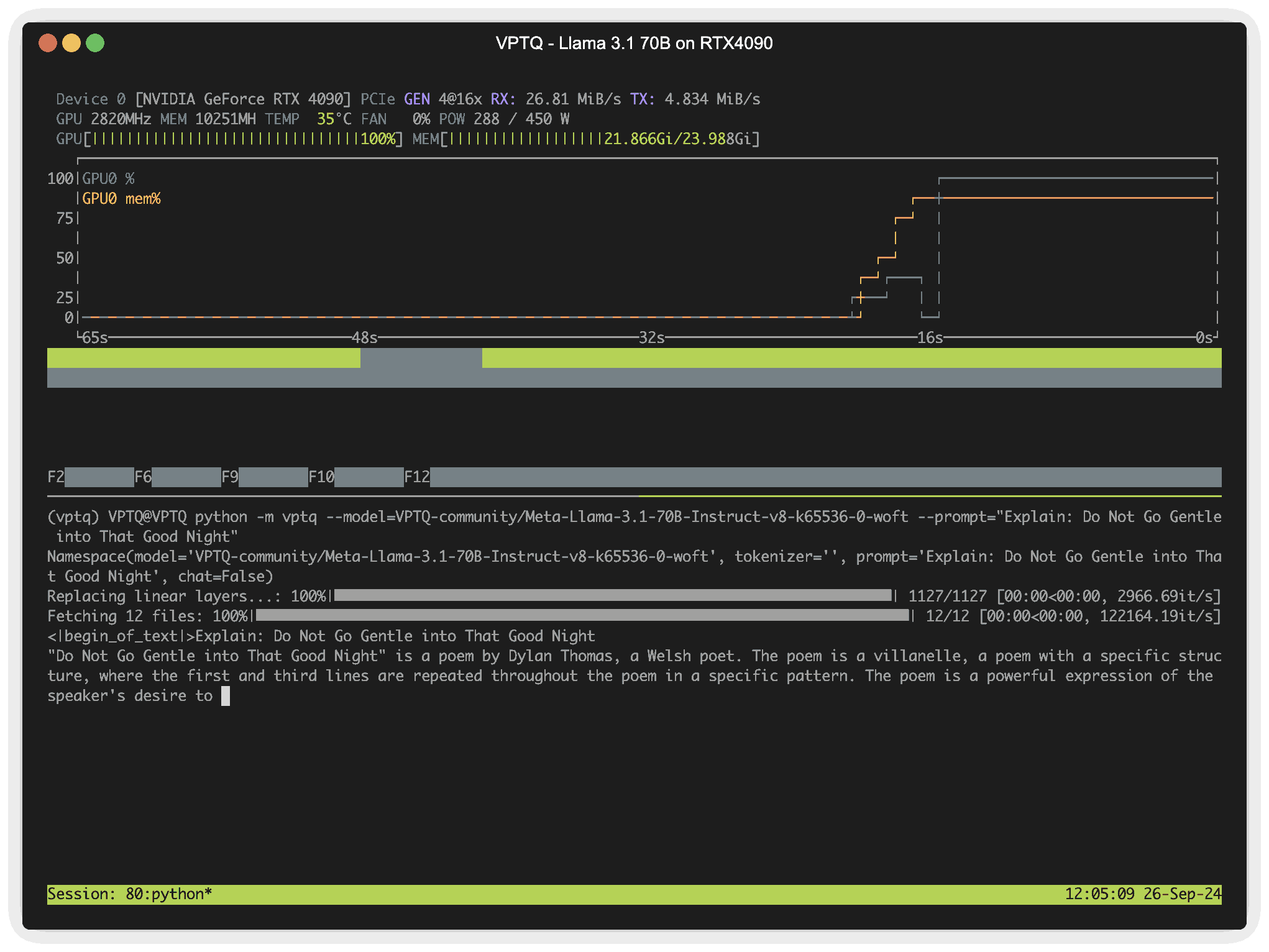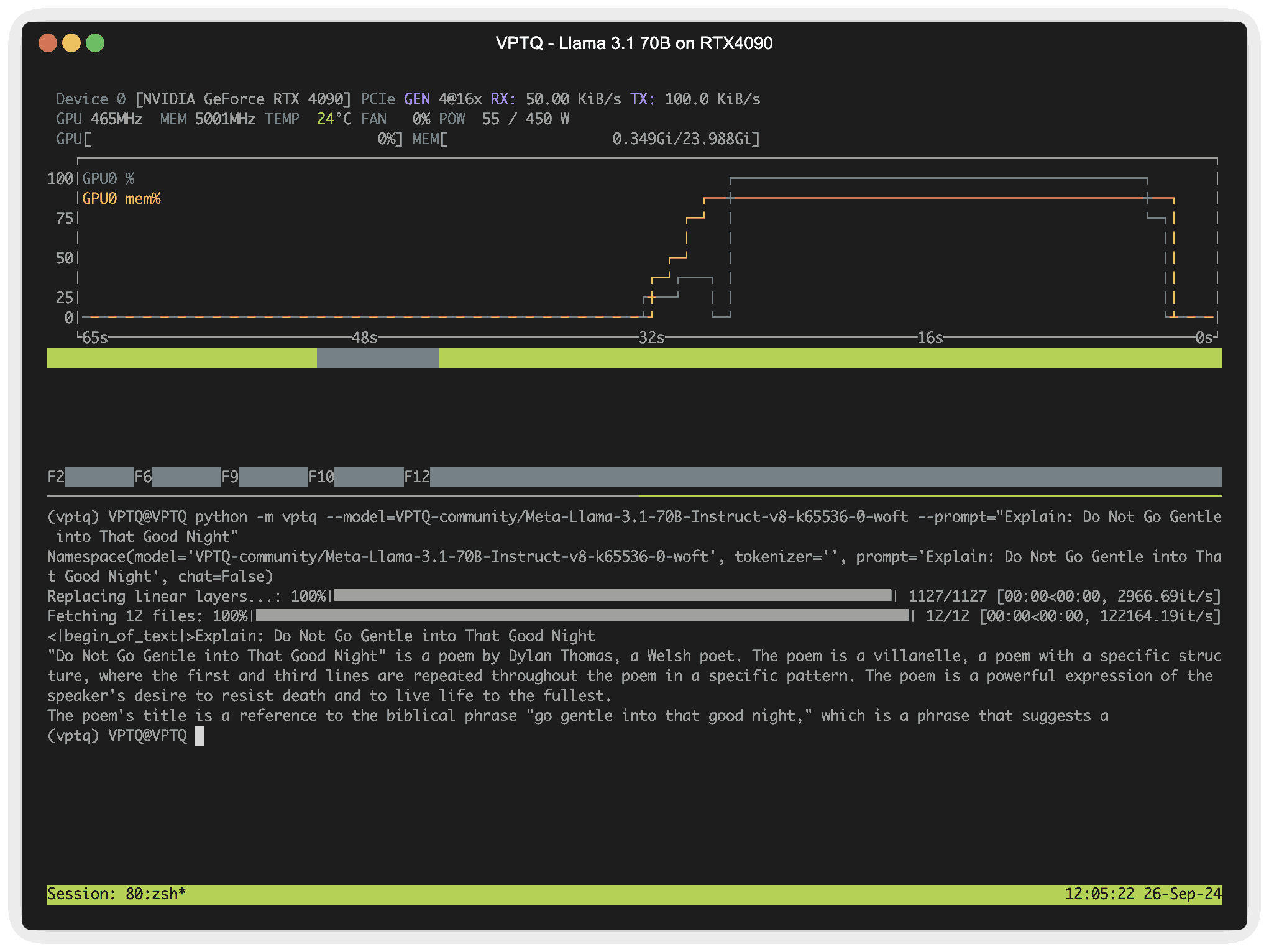
VPTQ is an ongoing project. If the open-source community is interested in optimizing and expanding VPTQ, please feel free to submit an issue or DM.
Evaluation
Models from Open Source Community
⚠️ The repository only provides a method of model quantization algorithm.
⚠️ The open-source community VPTQ-community provides models based on the technical report and quantization algorithm.
⚠️ The repository cannot guarantee the performance of those models.
Quick Estimation of Model Bitwidth (Excluding Codebook Overhead):
-
Model Naming Convention: The model's name includes the vector length $v$, codebook (lookup table) size, and residual codebook size. For example, "Meta-Llama-3.1-70B-Instruct-v8-k65536-256-woft" is "Meta-Llama-3.1-70B-Instruct", where:
- Vector Length: 8
- Number of Centroids: 65536 (2^16)
- Number of Residual Centroids: 256 (2^8)
-
Equivalent Bitwidth Calculation:
- Index: log2(65536) = 16 / 8 = 2 bits
- Residual Index: log2(256) = 8 / 8 = 1 bit
- Total Bitwidth: 2 + 1 = 3 bits
-
Model Size Estimation: 70B * 3 bits / 8 bits per Byte = 26.25 GB
-
Note: This estimate does not include the size of the codebook (lookup table), other parameter overheads, and the padding overhead for storing indices. For the detailed calculation method, please refer to Tech Report Appendix C.2.
Language Generation Example
To generate text using the pre-trained model, you can use the following code snippet:
The model VPTQ-community/Meta-Llama-3.1-70B-Instruct-v8-k65536-0-woft (~2 bit) is provided by open source community. The repository cannot guarantee the performance of those models.
python -m vptq --model=VPTQ-community/Meta-Llama-3.1-70B-Instruct-v8-k65536-0-woft --prompt="Explain: Do Not Go Gentle into That Good Night"
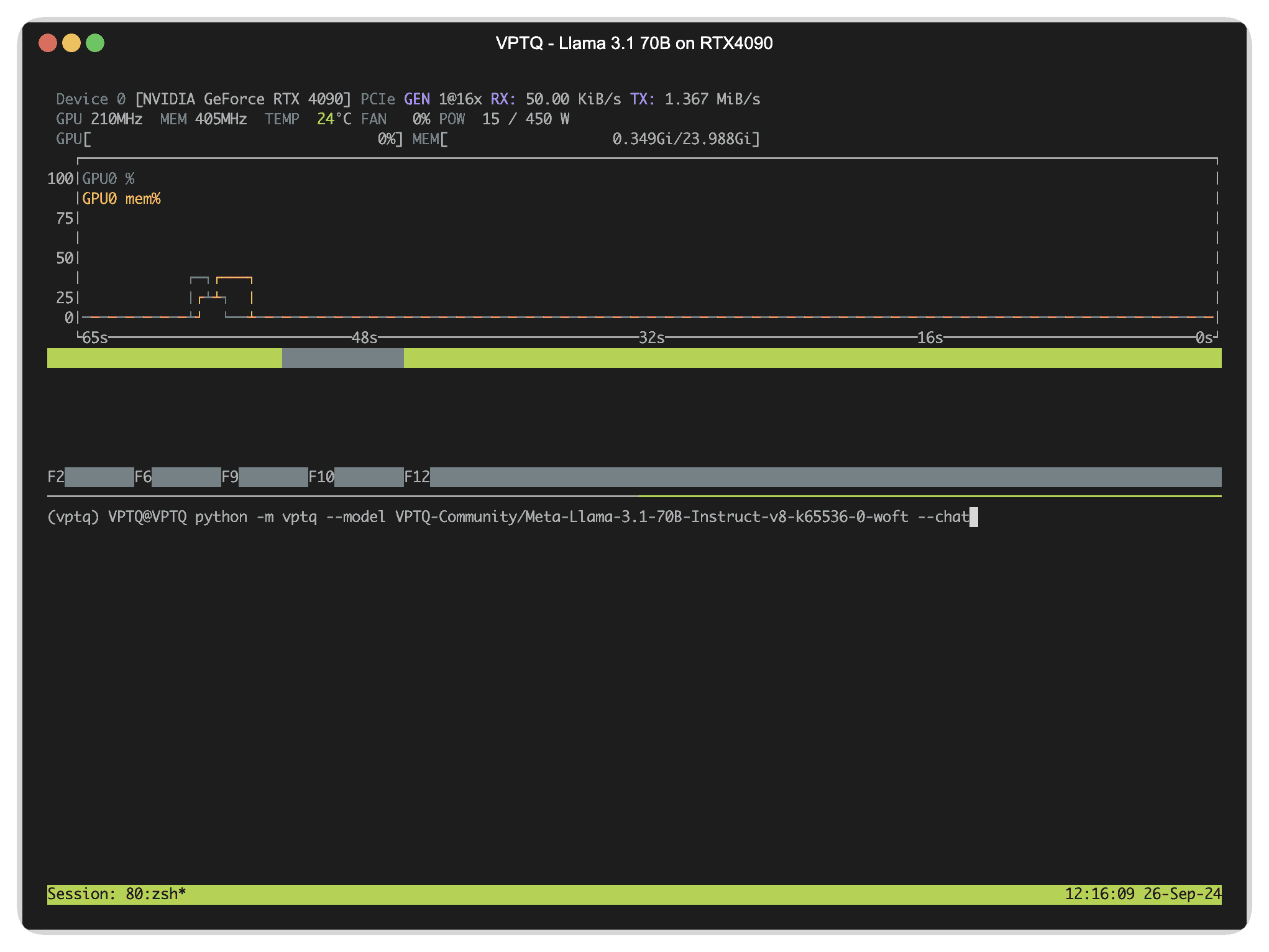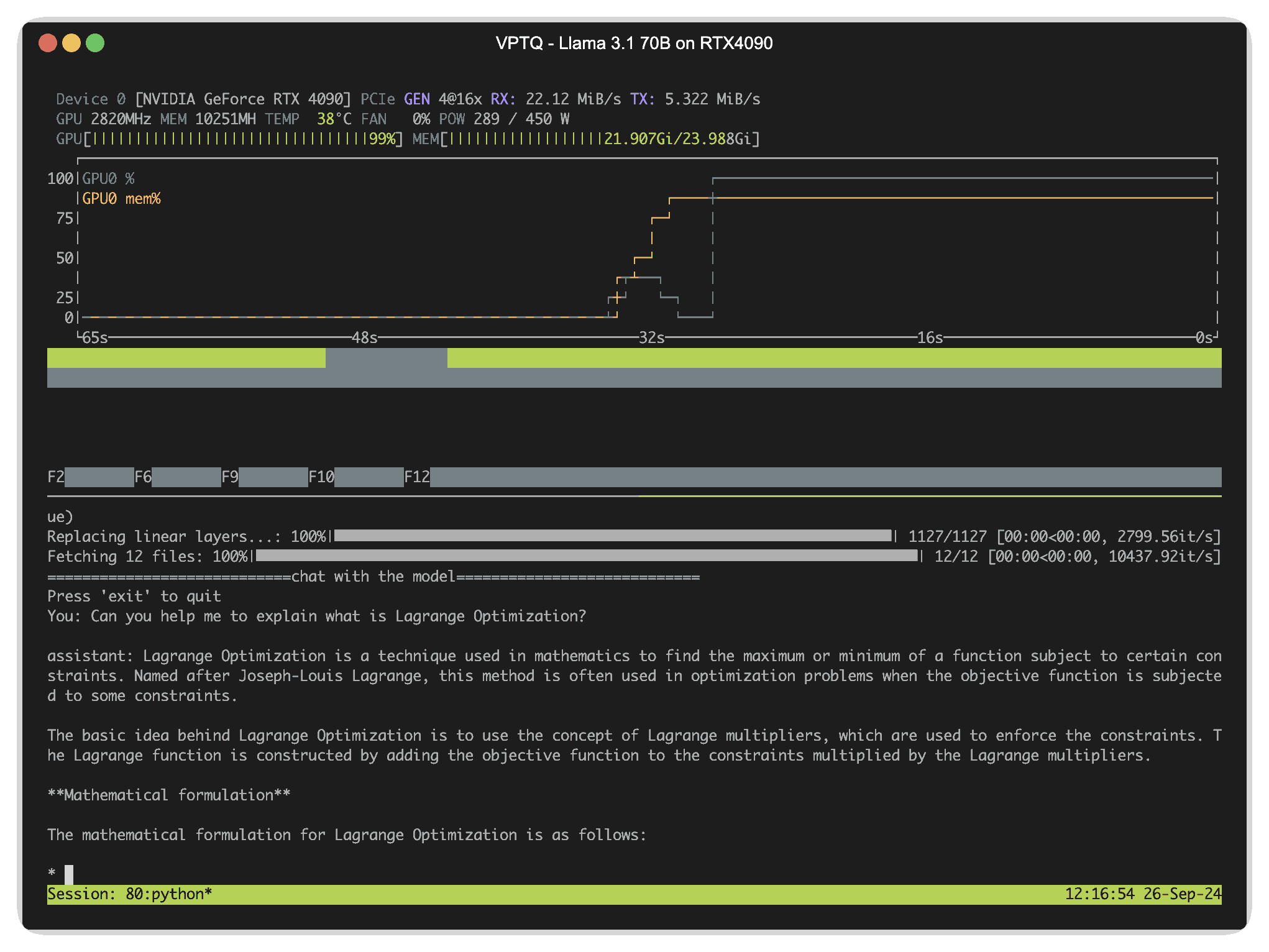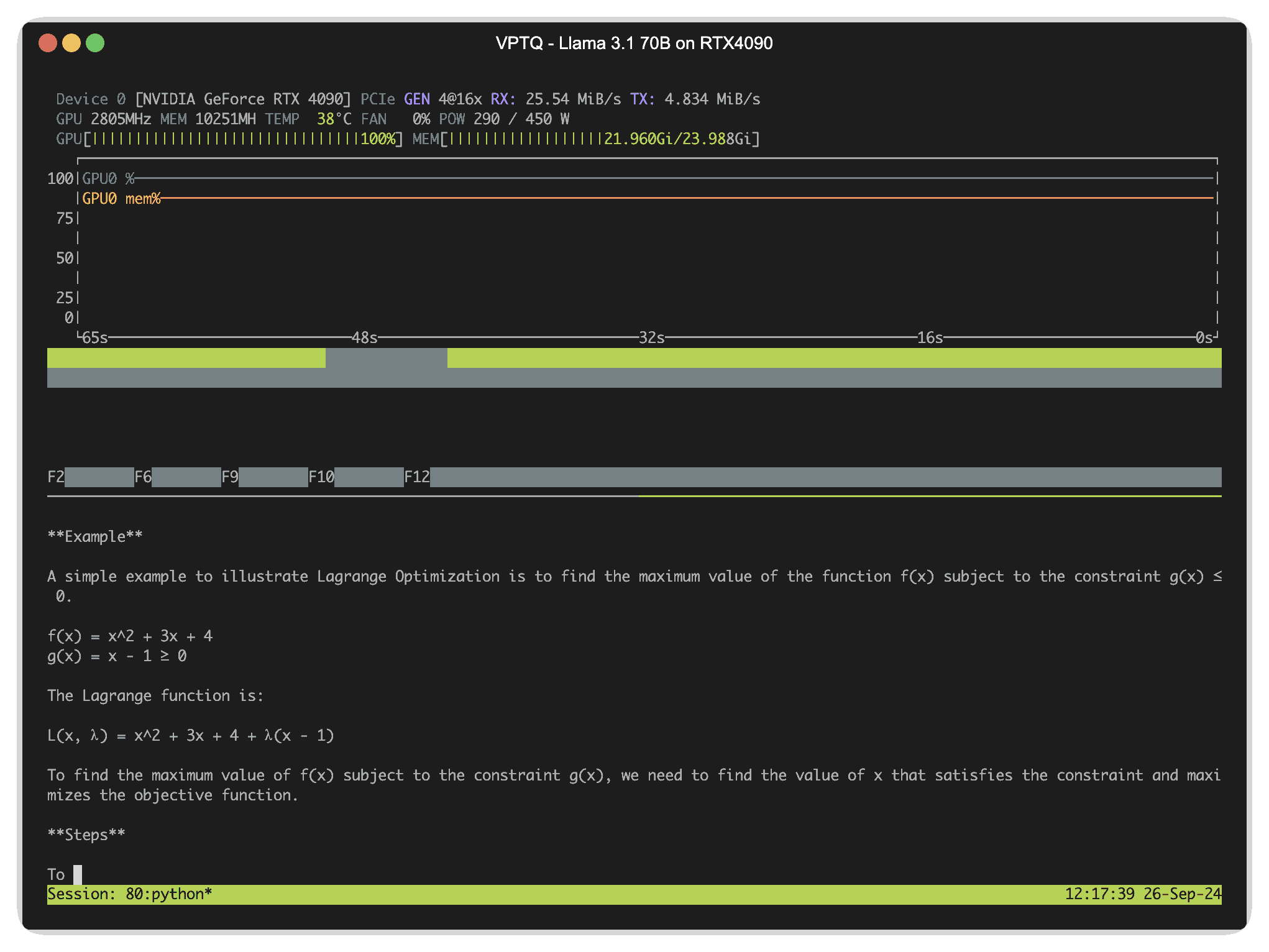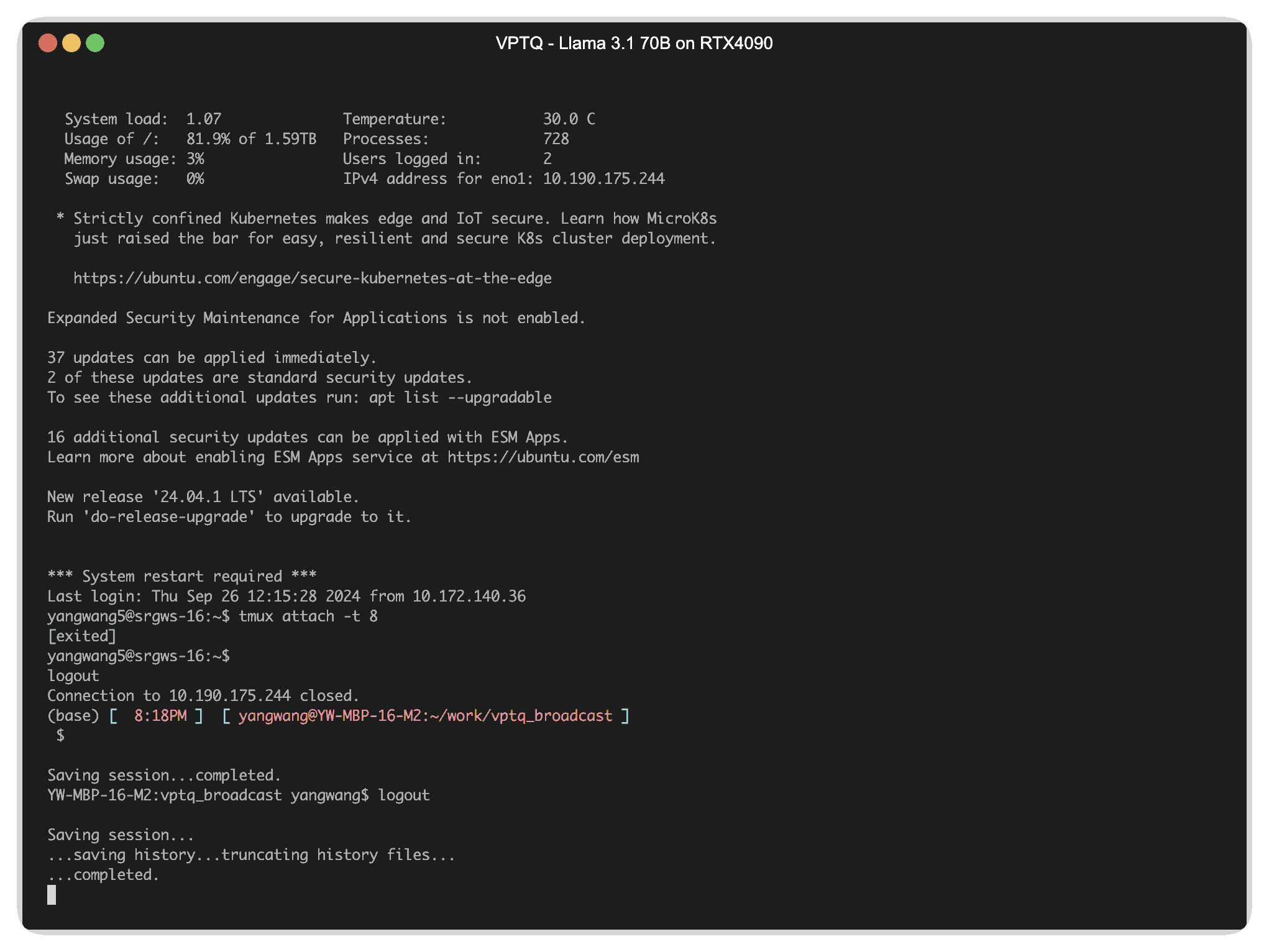
Terminal Chatbot Example
Launching a chatbot: Note that you must use a chat model for this to work
python -m vptq --model=VPTQ-community/Meta-Llama-3.1-70B-Instruct-v8-k65536-0-woft --chat
Huggingface Transformers API Example:
Now, huggingface transformers main branch supports VPTQ:
#! pip install git+https://github.com/huggingface/transformers.git -U
#! pip install vptq -U
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "VPTQ-community/Meta-Llama-3.3-70B-Instruct-v16-k65536-65536-woft"
# Load VPTQ-quantized model directly from HuggingFace Hub
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Simple inference
prompt = "Explain: Do not go gentle into that good night."
output = model.generate(
**tokenizer(prompt, return_tensors="pt").to(model.device)
)
print(tokenizer.decode(output[0], skip_special_tokens=True))
Python API Example from VPTQ package:
Using the Python API from VPTQ package:
import vptq
import transformers
model_name = "VPTQ-community/Meta-Llama-3.1-70B-Instruct-v8-k65536-0-woft"
tokenizer = transformers.AutoTokenizer.from_pretrained(model_name)
m = vptq.AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
prompt = "Explain: Do Not Go Gentle into That Good Night"
out = m.generate(
**tokenizer(prompt, return_tensors="pt").to("cuda"),
max_new_tokens=100,
pad_token_id=2
)
print(tokenizer.decode(out[0], skip_special_tokens=True))
Gradio Web App Example
An environment variable is available to control share link or not.
export SHARE_LINK=1
python -m vptq.app
VPTQ Algorithm Early-released
VPTQ algorithm early-released at algorithm branch, and checkout the tutorial.
Tech Report
Scaling model size significantly challenges the deployment and inference of Large Language Models (LLMs). Due to the redundancy in LLM weights, recent research has focused on pushing weight-only quantization to extremely low-bit (even down to 2 bits). It reduces memory requirements, optimizes storage costs, and decreases memory bandwidth needs during inference. However, due to numerical representation limitations, traditional scalar-based weight quantization struggles to achieve such extreme low-bit. Recent research on Vector Quantization (VQ) for LLMs has demonstrated the potential for extremely low-bit model quantization by compressing vectors into indices using lookup tables.
Read tech report at Tech Report and arXiv Paper
Early Results from Tech Report
VPTQ achieves better accuracy and higher throughput with lower quantization overhead across models of different sizes. The following experimental results are for reference only; VPTQ can achieve better outcomes under reasonable parameters, especially in terms of model accuracy and inference speed.

| Model | bitwidth | W2↓ | C4↓ | AvgQA↑ | tok/s↑ | mem(GB) | cost/h↓ |
|---|---|---|---|---|---|---|---|
| LLaMA-2 7B | 2.02 | 6.13 | 8.07 | 58.2 | 39.9 | 2.28 | 2 |
| 2.26 | 5.95 | 7.87 | 59.4 | 35.7 | 2.48 | 3.1 | |
| LLaMA-2 13B | 2.02 | 5.32 | 7.15 | 62.4 | 26.9 | 4.03 | 3.2 |
| 2.18 | 5.28 | 7.04 | 63.1 | 18.5 | 4.31 | 3.6 | |
| LLaMA-2 70B | 2.07 | 3.93 | 5.72 | 68.6 | 9.7 | 19.54 | 19 |
| 2.11 | 3.92 | 5.71 | 68.7 | 9.7 | 20.01 | 19 |
Road Map
- Merge the quantization algorithm into the public repository.
- Release on Pypi
- Improve the implementation of the inference kernel (e.g., CUDA, ROCm, Triton) and apply kernel fusion by combining dequantization (lookup) and Linear (GEMM) to enhance inference performance.
- Support VLM models @YangWang92
- Contribute VPTQ to Huggingface Transformers commit
- Contribute VPTQ to vLLM, LLM Compressor
- Contribute VPTQ to llama.cpp/exllama.
- Contribute VPTQ to Edge devices deployment.
- TBC
Project main members:
- Yifei Liu (@lyf-00)
- Jicheng Wen (@wejoncy)
- Ying Cao (@lcy-seso)
- Yang Wang (@YangWang92)
Acknowledgement
- We thank for James Hensman for his crucial insights into the error analysis related to Vector Quantization (VQ), and his comments on LLMs evaluation are invaluable to this research.
- We are deeply grateful for the inspiration provided by the papers QUIP, QUIP#, GPTVQ, AQLM, WoodFisher, GPTQ, and OBC.
Publication
EMNLP 2024 Main
@inproceedings{
vptq,
title={VPTQ: Extreme Low-bit Vector Post-Training Quantization for Large Language Models},
author={Yifei Liu and
Jicheng Wen and
Yang Wang and
Shengyu Ye and
Li Lyna Zhang and
Ting Cao and
Cheng Li and
Mao Yang},
booktitle={The 2024 Conference on Empirical Methods in Natural Language Processing},
year={2024},
}
Star History

Limitation of VPTQ
- ⚠️ VPTQ should only be used for research and experimental purposes. Further testing and validation are needed before you use it.
- ⚠️ The repository only provides a method of model quantization algorithm. The open-source community may provide models based on the technical report and quantization algorithm by themselves, but the repository cannot guarantee the performance of those models.
- ⚠️ VPTQ is not capable of testing all potential applications and domains, and VPTQ cannot guarantee the accuracy and effectiveness of VPTQ across other tasks or scenarios.
- ⚠️ Our tests are all based on English texts; other languages are not included in the current testing.
Contributing
This project welcomes contributions and suggestions. Most contributions require you to agree to a Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us the rights to use your contribution. For details, visit https://cla.opensource.microsoft.com.
When you submit a pull request, a CLA bot will automatically determine whether you need to provide a CLA and decorate the PR appropriately (e.g., status check, comment). Simply follow the instructions provided by the bot. You will only need to do this once across all repos using our CLA.
This project has adopted the Microsoft Open Source Code of Conduct. For more information see the Code of Conduct FAQ or contact opencode@microsoft.com with any additional questions or comments.
Trademarks
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow Microsoft's Trademark & Brand Guidelines. Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party's policies.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distributions
Built Distributions
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file vptq-0.0.5-cp312-cp312-manylinux1_x86_64.whl.
File metadata
- Download URL: vptq-0.0.5-cp312-cp312-manylinux1_x86_64.whl
- Upload date:
- Size: 3.2 MB
- Tags: CPython 3.12
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.0.1 CPython/3.11.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a4f5703d25e92009d3205b8ed1b68fdc8f32363d392f5b16b43419f9804aa2aa
|
|
| MD5 |
22766ac9656974f4cdffdfe260945448
|
|
| BLAKE2b-256 |
0e3c6ea8526bb4c054bb5dc0637518b5bec815f51edd4661af4833fb5afc112e
|
File details
Details for the file vptq-0.0.5-cp311-cp311-manylinux1_x86_64.whl.
File metadata
- Download URL: vptq-0.0.5-cp311-cp311-manylinux1_x86_64.whl
- Upload date:
- Size: 3.2 MB
- Tags: CPython 3.11
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.0.1 CPython/3.11.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b7aed4145bc29e0d1314455cb241d6974af0f747f217e1f5b0381e07f49b41e3
|
|
| MD5 |
2f5e55ccf821bd205fa4ef2300ac6f4b
|
|
| BLAKE2b-256 |
3305bee72cd1b1143c7104bc59d34756de0a1674fa54c5be6bc5eddb5540f339
|
File details
Details for the file vptq-0.0.5-cp310-cp310-manylinux1_x86_64.whl.
File metadata
- Download URL: vptq-0.0.5-cp310-cp310-manylinux1_x86_64.whl
- Upload date:
- Size: 3.2 MB
- Tags: CPython 3.10
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.0.1 CPython/3.11.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
5f32e437da99aeae2fe82d3b6d0159e51bd681a1aa97929fc4dc508df8930417
|
|
| MD5 |
4b0afefb360ca22e423a38ec46df8344
|
|
| BLAKE2b-256 |
a40e9846f8b046233afe4bd3f8fb52a1eedfe2e9b36870569e652bf731fe3016
|
File details
Details for the file vptq-0.0.5-cp39-cp39-manylinux1_x86_64.whl.
File metadata
- Download URL: vptq-0.0.5-cp39-cp39-manylinux1_x86_64.whl
- Upload date:
- Size: 3.2 MB
- Tags: CPython 3.9
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.0.1 CPython/3.11.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c7175202ee7d033c50e48c6699b5d19a816823380573ee97f0d1e49669677a9d
|
|
| MD5 |
54311e6b63a1bfef4103b87e9f9eb5bd
|
|
| BLAKE2b-256 |
88439c18a0862189f93cae4511be715de74a7fbb235d64749fbb6c083f0227ba
|
File details
Details for the file vptq-0.0.5-cp38-cp38-manylinux1_x86_64.whl.
File metadata
- Download URL: vptq-0.0.5-cp38-cp38-manylinux1_x86_64.whl
- Upload date:
- Size: 3.2 MB
- Tags: CPython 3.8
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.0.1 CPython/3.11.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b59ff74d19459fcbe4f4fd33dc3e6cd17932e8efffbbc1a078ab820936f0071b
|
|
| MD5 |
442a52ce8ef28b240e9f03c5049aaa14
|
|
| BLAKE2b-256 |
37dd01560727ba75b44cf0917ddae08eee5172e7db4173643401b7676ecde43c
|







