A fast GPU-accelerated Gradient Boosted Decision Tree library with PyTorch + CUDA

Project description

WarpGBM ⚡
Neural-speed gradient boosting. GPU-native. Distribution-aware. Production-ready.
WarpGBM is a high-performance, GPU-accelerated Gradient Boosted Decision Tree (GBDT) library engineered from silicon up with PyTorch and custom CUDA kernels. Built for speed demons and researchers who refuse to compromise.
🎯 What Sets WarpGBM Apart
Regression + Classification Unified
Train on continuous targets or multiclass labels with the same blazing-fast infrastructure.
Invariant Learning (DES Algorithm)
The only open-source GBDT that natively learns signals stable across shifting distributions. Powered by Directional Era-Splitting — because your data doesn't live in a vacuum.
GPU-Accelerated Everything
Custom CUDA kernels for binning, histograms, splits, and inference. No compromises, no CPU bottlenecks.
Scikit-Learn Compatible
Drop-in replacement. Same API you know, 10x the speed you need.
🚀 Quick Start
Installation
# Latest from GitHub (recommended)
pip install git+https://github.com/jefferythewind/warpgbm.git
# Stable from PyPI
pip install warpgbm
Prerequisites: PyTorch with CUDA support (install guide)
Regression in 5 Lines
from warpgbm import WarpGBM
import numpy as np
model = WarpGBM(objective='regression', max_depth=5, n_estimators=100)
model.fit(X_train, y_train)
predictions = model.predict(X_test)
Classification in 5 Lines
from warpgbm import WarpGBM
model = WarpGBM(objective='multiclass', max_depth=5, n_estimators=50)
model.fit(X_train, y_train) # y can be integers, strings, whatever
probabilities = model.predict_proba(X_test)
labels = model.predict(X_test)
🎮 Features
Core Engine
- ⚡ GPU-native CUDA kernels for histogram building, split finding, binning, and prediction
- 🎯 Multi-objective support: regression, binary, multiclass classification
- 📊 Pre-binned data optimization — skip binning if your data's already quantized
- 🔥 Mixed precision support —
float32orint8inputs - 🎲 Stochastic features —
colsample_bytreefor regularization
Intelligence
- 🧠 Invariant learning via DES — identifies signals that generalize across time/regimes/environments
- 📈 Smart initialization — class priors for classification, mean for regression
- 🎯 Automatic label encoding — handles strings, integers, whatever you throw at it
- 🔍 Feature importance — gain-based importance with unique per-era tracking
Training Utilities
- ✅ Early stopping with validation sets
- 📊 Rich metrics: MSE, RMSLE, correlation, log loss, accuracy
- 🔍 Progress tracking with loss curves
- 🎚️ Regularization — L2 leaf penalties, min split gain, min child weight
- 💾 Warm start & checkpointing — save/load models, incremental training
⚔️ Benchmarks
Synthetic Data: 1M Rows × 1K Features (Google Colab L4 GPU)
WarpGBM: corr = 0.8882, train = 17.4s, infer = 3.2s ⚡
XGBoost: corr = 0.8877, train = 33.2s, infer = 8.0s
LightGBM: corr = 0.8604, train = 29.8s, infer = 1.6s
CatBoost: corr = 0.8935, train = 392.1s, infer = 379.2s
2× faster than XGBoost. 23× faster than CatBoost.
Multiclass Classification: 3.5K Samples, 3 Classes, 50 Rounds
Training: 2.13s
Inference: 0.37s
Accuracy: 75.3%
Production-ready multiclass at neural network speeds.
📖 Examples
Regression: Beat LightGBM on Your Laptop
import numpy as np
from sklearn.datasets import make_regression
from warpgbm import WarpGBM
# Generate data
X, y = make_regression(n_samples=100_000, n_features=500, random_state=42)
X, y = X.astype(np.float32), y.astype(np.float32)
# Train
model = WarpGBM(
objective='regression',
max_depth=5,
n_estimators=100,
learning_rate=0.01,
num_bins=32
)
model.fit(X, y)
# Predict
preds = model.predict(X)
print(f"Correlation: {np.corrcoef(preds, y)[0,1]:.4f}")
Classification: Multiclass with Early Stopping
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from warpgbm import WarpGBM
# 5-class problem
X, y = make_classification(
n_samples=10_000,
n_features=50,
n_classes=5,
n_informative=30
)
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2)
model = WarpGBM(
objective='multiclass',
max_depth=6,
n_estimators=200,
learning_rate=0.1,
num_bins=32
)
model.fit(
X_train, y_train,
X_eval=X_val, y_eval=y_val,
eval_every_n_trees=10,
early_stopping_rounds=5,
eval_metric='logloss'
)
# Get probabilities or class predictions
probs = model.predict_proba(X_val) # shape: (n_samples, n_classes)
labels = model.predict(X_val) # class labels
Invariant Learning: Distribution-Robust Signals
# Your data spans multiple time periods/regimes/environments
# Pass era_id to learn only signals that work across ALL eras
model = WarpGBM(
objective='regression',
max_depth=8,
n_estimators=100
)
model.fit(
X, y,
era_id=era_labels # Array marking which era each sample belongs to
)
# Now your model ignores spurious correlations that don't generalize!
Feature Importance: Understand Your Model
from warpgbm import WarpGBM
from sklearn.datasets import load_iris
# Train a model
iris = load_iris()
X, y = iris.data, iris.target
model = WarpGBM(objective='multiclass', max_depth=5, n_estimators=100)
model.fit(X, y)
# Get feature importance (normalized)
importances = model.get_feature_importance()
for name, imp in zip(iris.feature_names, importances):
print(f"{name}: {imp:.4f}")
# Output:
# sepal length (cm): 0.0002
# sepal width (cm): 0.0007
# petal length (cm): 0.1997
# petal width (cm): 0.7994
Per-Era Feature Importance (Unique to WarpGBM!)
When training with era_id, see which features are stable across environments:
# Train with eras
model.fit(X, y, era_id=era_labels)
# Get per-era importance: shape (n_eras, n_features)
per_era_imp = model.get_per_era_feature_importance()
# Identify invariant features (high importance across ALL eras)
invariant_features = per_era_imp.min(axis=0) > threshold
Warm Start: Incremental Training & Checkpointing
Train a model in stages, save checkpoints, and resume training later:
from warpgbm import WarpGBM
import numpy as np
# Train 50 trees
model = WarpGBM(
objective='regression',
n_estimators=50,
max_depth=5,
learning_rate=0.1,
warm_start=True # Enable incremental training
)
model.fit(X, y)
predictions_50 = model.predict(X_test)
# Save checkpoint
model.save_model('checkpoint_50.pkl')
# Continue training for 50 more trees (total: 100)
model.n_estimators = 100
model.fit(X, y) # Adds 50 trees on top of existing 50
predictions_100 = model.predict(X_test)
# Or load and continue training later
model_loaded = WarpGBM()
model_loaded.load_model('checkpoint_50.pkl')
model_loaded.warm_start = True
model_loaded.n_estimators = 100
model_loaded.fit(X, y) # Resumes from 50 → 100 trees
Use Cases:
- Hyperparameter tuning: Train to 50 trees, evaluate, decide if you need 100 or 200
- Checkpointing: Save progress during long training runs
- Iterative development: Add more trees without retraining from scratch
- Production updates: Retrain models incrementally as new data arrives
Pre-binned Data: Maximum Speed (Numerai Example)
import pandas as pd
from numerapi import NumerAPI
from warpgbm import WarpGBM
# Download Numerai data (already quantized to integers)
napi = NumerAPI()
napi.download_dataset('v5.0/train.parquet', 'train.parquet')
train = pd.read_parquet('train.parquet')
features = [f for f in train.columns if 'feature' in f]
X = train[features].astype('int8').values
y = train['target'].values
# WarpGBM detects pre-binned data and skips binning
model = WarpGBM(max_depth=5, n_estimators=100, num_bins=20)
model.fit(X, y) # Blazing fast!
Result: 13× faster than LightGBM on Numerai data (49s vs 643s)
🧠 Invariant Learning: Why It Matters
Most ML models assume your training and test data come from the same distribution. Reality check: they don't.
- Stock prices shift with market regimes
- User behavior changes over time
- Experimental data varies by batch/site/condition
Traditional GBDT: Learns any signal that correlates with the target, including fragile patterns that break OOD.
WarpGBM with DES: Explicitly tests if each split generalizes across ALL environments (eras). Only keeps robust signals.
The Algorithm
For each potential split, compute gain separately in each era. Only accept splits where:
- Gain is positive in ALL eras
- Split direction is consistent across eras
This prevents overfitting to spurious correlations that only work in some time periods or environments.
Visual Intuition
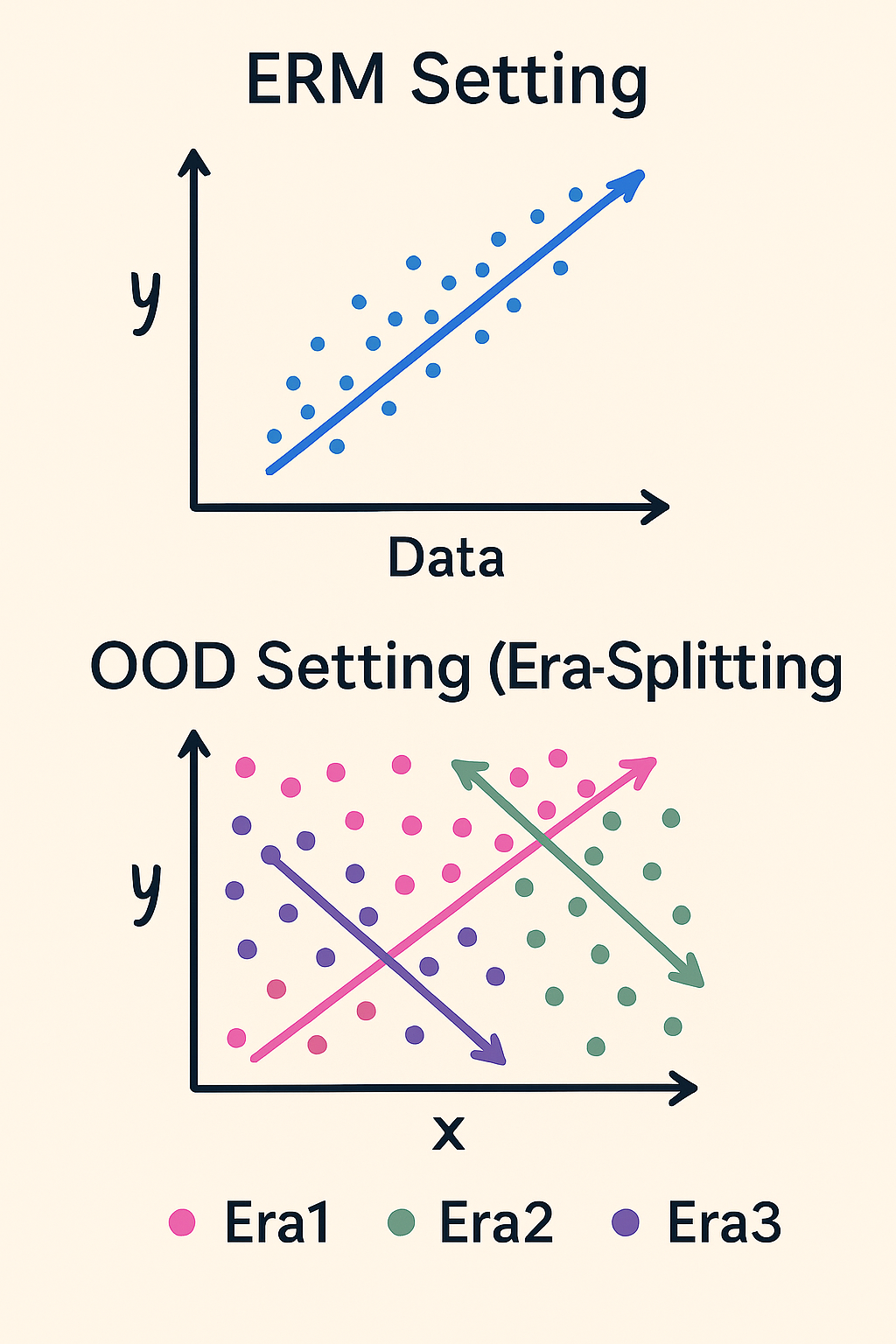
Left: Standard training pools all data together — learns any signal that correlates.
Right: Era-aware training demands signals work across all periods — learns robust features only.
Research Foundation
- Invariant Risk Minimization: Arjovsky et al., 2019
- Hard-to-Vary Explanations: Parascandolo et al., 2020
- Era Splitting for Trees: DeLise, 2023
📚 API Reference
Constructor Parameters
WarpGBM(
objective='regression', # 'regression', 'binary', or 'multiclass'
num_bins=10, # Histogram bins for feature quantization
max_depth=3, # Maximum tree depth
learning_rate=0.1, # Shrinkage rate (aka eta)
n_estimators=100, # Number of boosting rounds
min_child_weight=20, # Min sum of instance weights in child node
min_split_gain=0.0, # Min loss reduction to split
L2_reg=1e-6, # L2 leaf regularization
colsample_bytree=1.0, # Feature subsample ratio per tree
random_state=None, # Random seed for reproducibility
warm_start=False, # If True, continue training from existing trees
threads_per_block=64, # CUDA block size (tune for your GPU)
rows_per_thread=4, # Rows processed per thread
device='cuda' # 'cuda' or 'cpu' (GPU strongly recommended)
)
Training Methods
model.fit(
X, # Features: np.array shape (n_samples, n_features)
y, # Target: np.array shape (n_samples,)
era_id=None, # Optional: era labels for invariant learning
X_eval=None, # Optional: validation features
y_eval=None, # Optional: validation targets
eval_every_n_trees=None, # Eval frequency (in rounds)
early_stopping_rounds=None, # Stop if no improvement for N evals
eval_metric='mse' # 'mse', 'rmsle', 'corr', 'logloss', 'accuracy'
)
Prediction & Utility Methods
# Regression: returns predicted values
predictions = model.predict(X)
# Classification: returns class labels (decoded)
labels = model.predict(X)
# Classification: returns class probabilities
probabilities = model.predict_proba(X) # shape: (n_samples, n_classes)
# Feature importance: gain-based (like LightGBM/XGBoost)
importances = model.get_feature_importance(normalize=True) # sums to 1.0
raw_gains = model.get_feature_importance(normalize=False) # raw gain values
# Per-era importance (when era_id was used in training)
per_era_imp = model.get_per_era_feature_importance(normalize=True) # shape: (n_eras, n_features)
# Save and load models
model.save_model('checkpoint.pkl') # Saves all model state
model_loaded = WarpGBM()
model_loaded.load_model('checkpoint.pkl') # Restores everything
Attributes
model.classes_ # Unique class labels (classification only)
model.num_classes # Number of classes (classification only)
model.forest # Trained tree structures
model.training_loss # Training loss history
model.eval_loss # Validation loss history (if eval set provided)
model.feature_importance_ # Feature importance (sum across eras)
model.per_era_feature_importance_ # Per-era feature importance (when era_id used)
🔧 Installation Details
Linux / macOS (Recommended)
pip install git+https://github.com/jefferythewind/warpgbm.git
Compiles CUDA extensions using your local PyTorch + CUDA setup.
Colab / Mismatched CUDA Versions
pip install warpgbm --no-build-isolation
Windows
git clone https://github.com/jefferythewind/warpgbm.git
cd warpgbm
python setup.py bdist_wheel
pip install dist/warpgbm-*.whl
🎯 Use Cases
Financial ML: Learn signals that work across market regimes
Time Series: Robust forecasting across distribution shifts
Scientific Research: Models that generalize across experimental batches
High-Speed Inference: Production systems with millisecond SLAs
Kaggle/Competitions: GPU-accelerated hyperparameter tuning
Multiclass Problems: Image classification fallback, text categorization, fraud detection
🚧 Roadmap
- Multi-GPU training support
- SHAP value computation on GPU
- Feature interaction constraints
- Monotonic constraints
- Custom loss functions
- Distributed training
- ONNX export for deployment
🙏 Acknowledgements
Built on the shoulders of PyTorch, scikit-learn, LightGBM, XGBoost, and the CUDA ecosystem. Special thanks to the GBDT research community and all contributors.
📝 Version History
v2.2.0 (Current)
- 💾 Warm start support for incremental training (closes #14)
- 📦
save_model()andload_model()methods for checkpointing - 🔄 Resume training from saved models with
warm_start=True - ✅ Comprehensive test suite for warm start and save/load functionality
- 📚 Updated documentation with warm start examples
v2.1.1
- 🎲 random_state parameter for reproducible results (closes #12)
- 🔧 Controls randomness in feature subsampling (
colsample_bytree) - ✅ Comprehensive reproducibility tests
v2.1.0
- 🔍 Feature importance with gain-based tracking and unique per-era analysis
- 📊
get_feature_importance()andget_per_era_feature_importance()methods - ✅ Comprehensive test suite comparing with LightGBM
- 📚 Updated documentation with feature importance examples
v2.0.0
- ✨ Multiclass classification support via softmax objective
- 🎯 Binary classification mode
- 📊 New metrics: log loss, accuracy
- 🏷️ Automatic label encoding (supports strings)
- 🔮
predict_proba()for probability outputs - ✅ Comprehensive test suite for classification
- 🔒 Full backward compatibility with regression
- 🐛 Fixed unused variable issue (#8)
- 🧹 Removed unimplemented L1_reg parameter
- 📚 Major documentation overhaul with AGENT_GUIDE.md
v1.0.0
- 🧠 Invariant learning via Directional Era-Splitting (DES)
- 🚀 VRAM optimizations
- 📈 Era-aware histogram computation
v0.1.26
- 🐛 Memory bug fixes in prediction
- 📊 Added correlation eval metric
v0.1.25
- 🎲 Feature subsampling (
colsample_bytree)
v0.1.23
- ⏹️ Early stopping support
- ✅ Validation set evaluation
v0.1.21
- ⚡ CUDA prediction kernel (replaced vectorized Python)
📄 License
MIT License - see LICENSE file
🤝 Contributing
Pull requests welcome! See AGENT_GUIDE.md for architecture details and development guidelines.
Built with 🔥 by @jefferythewind
"Train smarter. Predict faster. Generalize better."
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file warpgbm-2.2.0.tar.gz.
File metadata
- Download URL: warpgbm-2.2.0.tar.gz
- Upload date:
- Size: 75.2 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
33bb47b1bbd3fd4c894f8f911335df4cfc0a6f4fbf0b0c53973d081e9e1f359e
|
|
| MD5 |
b63d8c8a09c436cf7a4061cdbb66192b
|
|
| BLAKE2b-256 |
0d816be2b15b2b56aed8dfd73cc9c402218eae0ad0c90fab9e6e39ff43a99a6c
|
Provenance
The following attestation bundles were made for warpgbm-2.2.0.tar.gz:
Publisher:
release.yml on jefferythewind/warpgbm
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
warpgbm-2.2.0.tar.gz -
Subject digest:
33bb47b1bbd3fd4c894f8f911335df4cfc0a6f4fbf0b0c53973d081e9e1f359e - Sigstore transparency entry: 605223687
- Sigstore integration time:
-
Permalink:
jefferythewind/warpgbm@15aa526429d85cfc100e3c47819b8b921efb400f -
Branch / Tag:
refs/tags/v2.2.0 - Owner: https://github.com/jefferythewind
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release.yml@15aa526429d85cfc100e3c47819b8b921efb400f -
Trigger Event:
push
-
Statement type:







