World Bank Open Data helpers — Python library + CLI mirroring the Stata wbopendata surface (discovery, data, country-context, multilingual, linewrap).
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
wb-api-tools





Python library + CLI for the World Bank Open Data API — the Stata wbopendata surface, packaged for modern Python.
pip install wb-api-tools
wb-api-tools wraps the World Bank's WDI / IBRD APIs in two thin, well-tested
interfaces: a Python library you import (import wb_api_tools as wb) and a
console script (wb-api-tools <subcommand>). It mirrors the surface of the
Stata wbopendata package (v18.x
lineage) so workflows port cleanly between the two ecosystems.
Quick start
After pip install wb-api-tools, populate the offline metadata cache once
(~30 s; downloads three small YAML files to ~/.cache/wbopendata/):
wb-api-tools sync
Then any of the five examples below works. Full runnable notebook:
examples/readme_examples.ipynb — GitHub
renders it inline (DataFrame tables + figures), or open in Jupyter / Colab to
re-execute.
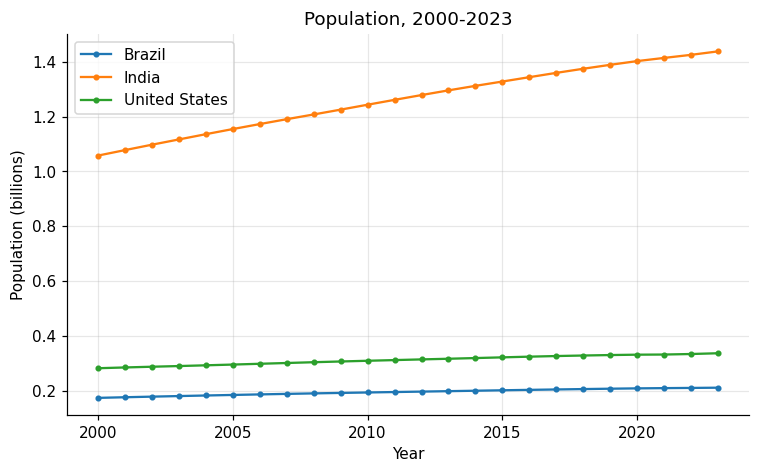
1. Population time-series (multiple countries)
import wb_api_tools as wb
df = wb.get_data(
["SP.POP.TOTL"], "BRA;USA;IND",
date="2000:2023", long=True, no_basic=True,
)
df["pop_billions"] = df["value"] / 1e9
print(df.head(3)[["country", "date", "pop_billions"]].to_string(index=False))
# country date pop_billions
# Brazil 2000 0.174018
# Brazil 2001 0.176301
# Brazil 2002 0.178503
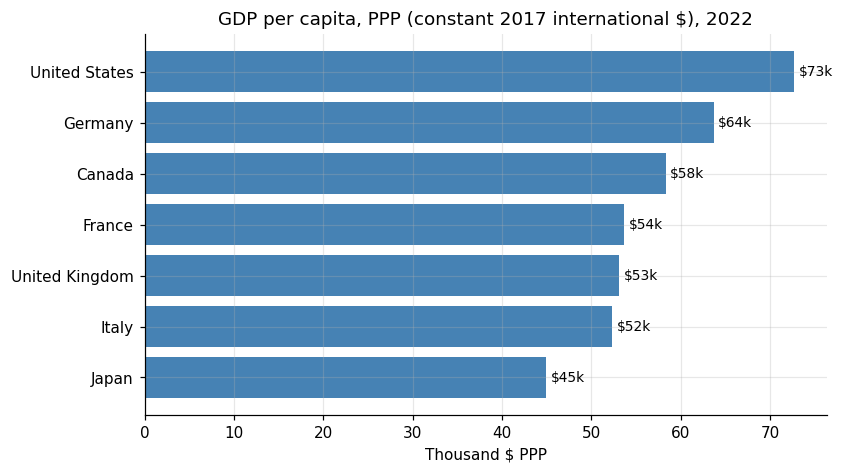
2. Cross-country bar chart (G7, latest year)
df = wb.get_data(
["NY.GDP.PCAP.PP.KD"],
"CAN;DEU;FRA;GBR;ITA;JPN;USA",
date="2022", long=True, no_basic=True,
)
df["gdp_pcap_k"] = df["value"] / 1000
print(df.sort_values("gdp_pcap_k")[["country", "gdp_pcap_k"]].to_string(index=False))
# country gdp_pcap_k
# Japan 44.972344
# Italy 52.333327
# United Kingdom 53.139151
# France 53.673814
# Canada 58.321061
# Germany 63.676088
# United States 72.679258
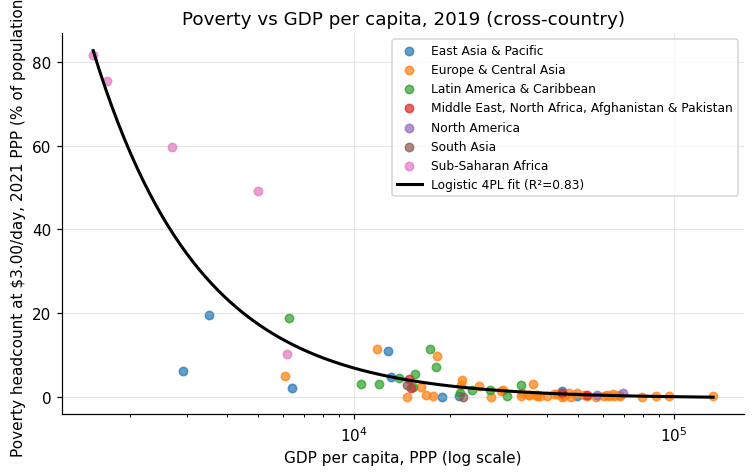
3. Bivariate scatter — poverty vs GDP per capita
Two indicators, all countries, single year (mirrors Stata
wbopendata_examples.ado example 04). We fit three candidate functional forms
and overlay the one with the highest R²:
import numpy as np
from scipy.optimize import curve_fit
df = wb.get_data(
["SI.POV.DDAY", "NY.GDP.PCAP.PP.KD"], "all",
date="2019",
)
df = df.dropna(subset=["SI.POV.DDAY", "NY.GDP.PCAP.PP.KD"])
df = df[df["region"].notna() & (df["region"] != "NA")]
print(f"countries with both indicators in 2019: {len(df)}")
# countries with both indicators in 2019: 78
x = df["NY.GDP.PCAP.PP.KD"].to_numpy()
y = df["SI.POV.DDAY"].to_numpy()
# Logistic 4PL is the principled choice — y is bounded in [0, 100%], so a
# sigmoid that respects both asymptotes is the right family.
def logistic_4pl(x, a, b, c, d):
return d + (a - d) / (1.0 + (x / c) ** b)
popt, _ = curve_fit(logistic_4pl, x, y,
p0=[100.0, 1.0, float(np.median(x)), 0.0], maxfev=20000)
# R^2 against linear (log) and quadratic (log) baselines:
# Linear (log GDP): R^2 = 0.503
# Quadratic (log GDP): R^2 = 0.775
# Logistic 4PL: R^2 = 0.834 <-- best fit, plotted in black
4. Discovery workflow: search → info → fetch
res = wb.search("education spending", limit=3)
print(f"matches: {res['total']:,}")
# matches: 19
wb.info("SE.XPD.TOTL.GD.ZS")
# {'code': 'SE.XPD.TOTL.GD.ZS',
# 'name': 'Government expenditure on education, total (% of GDP)',
# 'source_name': 'World Development Indicators',
# 'topic_names': ['Education'],
# ...}
5. Enrich a user DataFrame with country context
Mirrors Stata wbopendata, match(varname) [basic geo]:
import pandas as pd
user_df = pd.DataFrame({
"iso3": ["BRA", "USA", "IND", "DEU", "JPN"],
"my_metric": [1.2, 3.4, 5.6, 7.8, 9.0],
})
wb.enrich_country_context(user_df, iso_col="iso3", geo=True)
# iso3 my_metric region ... capital latitude longitude
# BRA 1.2 LCN ... Brasilia -15.7801 -47.9292
# USA 3.4 NAC ... Washington D.C. 38.8895 -77.032
# ...
What's new in v0.3.0
MINOR release. New CLI capabilities + a README/docs refresh for the PyPI landing page:
- CLI:
--out -streams the full CSV to stdout (Unix convention; pipeable intojq,csvkit, etc. without a disk round-trip). - CLI:
.json/.jsonl/.ndjsonoutput formats via the same--outdispatcher (records orient for.json, line-delimited for the others). Web-friendly + streaming-friendly. - CLI: status lines routed to stderr so
--out -produces a clean, parseable CSV stream on stdout. - README restructured for PyPI-first audience: 5 worked examples with figures, Common Indicators starter table, Troubleshooting, Citation.
examples/readme_examples.{py,ipynb}— runnable script + paired Jupyter notebook (GitHub renders inline, no clone required).- Example 3 demonstrates a 3-way functional-form comparison (linear-log / quadratic-log / logistic 4PL); logistic wins at R² = 0.834.
See CHANGELOG.md for the full per-release log.
Common indicators
A starter set of high-traffic World Bank indicator codes. The full universe
is 29,511 indicators; use wb.search(...) or
Data Catalog to discover more.
| Category | Code | Indicator |
|---|---|---|
| Population | SP.POP.TOTL |
Population, total |
| Population | SP.URB.TOTL.IN.ZS |
Urban population (% of total) |
| Economy | NY.GDP.MKTP.CD |
GDP (current US$) |
| Economy | NY.GDP.PCAP.PP.KD |
GDP per capita, PPP (constant 2017 international $) |
| Economy | NE.TRD.GNFS.ZS |
Trade (% of GDP) |
| Poverty | SI.POV.DDAY |
Poverty headcount at $3.00/day (2021 PPP) |
| Poverty | SI.POV.GINI |
Gini index |
| Education | SE.XPD.TOTL.GD.ZS |
Government expenditure on education (% of GDP) |
| Education | SE.PRM.ENRR |
Gross primary enrollment ratio |
| Education | SE.SEC.CMPT.LO.ZS |
Lower secondary completion rate |
| Health | SP.DYN.LE00.IN |
Life expectancy at birth |
| Health | SH.DYN.MORT |
Under-5 mortality rate |
| Health | SH.STA.MMRT |
Maternal mortality ratio |
| Environment | EN.ATM.CO2E.PC |
CO2 emissions per capita (metric tons) |
| Environment | AG.LND.FRST.ZS |
Forest area (% of land area) |
Project surfaces
wb-api-tools is the Python distribution of a dual Stata + Python repo
(jpazvd/wb-api-repo) on a parallel
v0.x track to the upstream Stata
wbopendata (Stata Journal v18.x).
| Surface | Entry point | Reference |
|---|---|---|
| Python library | wb_api_tools.{discovery,data,text} (re-exported at the package root) |
docs/PYTHON_USER_GUIDE.md |
| Python CLI | wb-api-tools <subcmd> (after install) or python -m wb_api_tools <subcmd> |
--help on every subcommand |
| Stata package | src/w/wbopendata.ado in the GitHub repo (v17.4.0) |
help wbopendata in Stata, or src/w/wbopendata.sthlp |
| YAML metadata cache | ~/.cache/wbopendata/_wbopendata_{indicators,sources,topics}.yaml (XDG-aware) |
populated by wb-api-tools sync |
Python CLI
After pip install, use the wb-api-tools console script (or
python -m wb_api_tools if PATH doesn't include scripts). Each subcommand has
--help for full flag descriptions.
| Subcommand | Purpose |
|---|---|
countries |
Fetch country metadata |
indicators |
Fetch indicator metadata (legacy CSV/parquet/yaml dump) |
data |
Fetch indicator data; --no-basic skips country-context auto-merge, --geo adds capital/lat/lon, --language es switches the API path |
sources |
List WB data sources (--all for the full set) |
alltopics |
List all WB topic categories |
info <id> |
Show full metadata for one indicator (from YAML cache) |
describe <id> |
Fetch fresh metadata for one indicator (live API; --language supported) |
search [term] |
Paginated indicator search; --source, --topic, --field, --exact |
sync |
Populate / refresh the YAML metadata cache from the live WB API |
Example:
wb-api-tools data \
--indicators SP.POP.TOTL,NY.GDP.MKTP.CD \
--countries "BRA;USA;IND" \
--date 2010:2020 \
--geo --long --out _data/wb/pop_gdp_long.csv
Output is written to --out — six file formats supported by extension:
| Extension | Format | Notes |
|---|---|---|
.csv |
Comma-separated | Default fallback for unknown extensions too |
.parquet |
Apache Parquet | Columnar; small + fast for analytics |
.json |
JSON records, pretty-printed | [{...}, {...}] indent=2 |
.jsonl / .ndjson |
Line-delimited JSON | Streaming-friendly for jq, Spark, BigQuery |
.yaml / .yml |
YAML records | Stata-friendly |
Plus two stdout modes:
--out -→ full CSV streamed to stdout (pipeable into other tools)--outomitted → 20-row preview to stdout (head only, not parseable)
Stata package
src/w/wbopendata.ado (in the GitHub repo, not on PyPI) is the v17.4.0
dispatcher; current surface mirrors the Python library:
wbopendata, sources / allsources / alltopics / info / search / describediscovery commandswbopendata, indicator(X) cleardata fetch withnoBASIC,geo,language(es),cache(days),synclinewrap(W) maxlength(N) linewrapformat(stack|newline|lines|smcl)for graph-title and SMCL formatting
Open src/w/wbopendata.sthlp in Stata's viewer or run help wbopendata once
the package is on the adopath. The Python-side
docs/PYTHON_USER_GUIDE.md §5 has a row-by-row
Stata ↔ Python parity table.
YAML metadata cache
The offline metadata cache lives in a per-user XDG-aware directory (typically
~/.cache/wbopendata/ on POSIX or ~/AppData/Local/wbopendata/ on Windows;
override with $WBOPENDATA_YAML_DIR):
_wbopendata_indicators.yaml— 29,511 indicators (~18 MB)_wbopendata_sources.yaml— 71 sources_wbopendata_topics.yaml— 21 topics
Discovery commands (info, search, sources, alltopics) read from this
cache for microsecond lookups. After pip install, populate it once:
wb-api-tools sync # download + write all three YAMLs (~30 s first time)
wb-api-tools sync --commit --tag # git-commit + tag (dev mode only)
A semi-monthly GitHub Action (.github/workflows/wb_metadata_nightly.yml —
file name is historical; cron runs on the 1st and 15th of every month at 02:17
UTC) keeps the repo-committed cache fresh. Manually triggerable via
workflow_dispatch.
Documentation
- docs/PYTHON_USER_GUIDE.md — Python library + CLI reference (Stata
.sthlpequivalent) - docs/PYTHON_DEMO.md — captured live-API transcript from the 7-section walkthrough
- docs/EXAMPLES.md — end-to-end workflows (API, Stata, Python)
- docs/AGE_BANDS.md — standard 5-year age band codes for population indicators
- examples/readme_examples.ipynb — runnable Jupyter notebook for the Quick-start examples above
- examples/readme_examples.py — paired Python script (regenerates the figures in
docs/figures/) - CHANGELOG.md — per-release change log
- doc/VERSIONING_POLICY.md — semver policy + component-level
.adoversion headers
Troubleshooting
YAML metadata not found in cache — run wb-api-tools sync once. The
package ships without a YAML cache (would push the wheel size up needlessly);
sync downloads + writes the three files to ~/.cache/wbopendata/ in ~30 s.
Cache lives somewhere unexpected — the resolution order is OS-specific
(see src/wb_api_tools/cache.py):
$WBOPENDATA_YAML_DIRwins on every platform when set.- POSIX (Linux / macOS): otherwise
$XDG_CACHE_HOME/wbopendata/if set, else~/.cache/wbopendata/. - Windows: otherwise
$LOCALAPPDATA/wbopendata/if set, else~/AppData/Local/wbopendata/.
Set the env var to point at a shared directory if working across machines.
Corporate proxy blocks api.worldbank.org — the WB API responds to plain
HTTPS over port 443 with no auth. If wb-api-tools sync hangs, check your
proxy whitelist or set HTTPS_PROXY in your environment.
UnicodeEncodeError on Windows — country names contain accented characters
that Windows' default cp1252 can't represent. Set
PYTHONIOENCODING=utf-8 in your environment before running, or use a
Unicode-aware terminal (Windows Terminal, modern PowerShell).
wb-api-tools sync takes ~30 s — is it stuck? — that's normal first-run
behaviour: it fetches 29,511 indicators in batches of 10,000 from the
/v2/indicator endpoint. Subsequent reads come from the local YAML cache
(microseconds).
Citation
If wb-api-tools supports a published paper or working paper, please cite
both the package and the underlying Stata implementation:
@misc{azevedo_wbapitools_2026,
author = {Azevedo, Jo{\~a}o Pedro},
title = {{wb-api-tools}: World Bank Open Data helpers for Python},
year = {2026},
publisher = {PyPI},
url = {https://pypi.org/project/wb-api-tools/}
}
@misc{azevedo_wbopendata_2011,
author = {Azevedo, Jo{\~a}o Pedro},
title = {{wbopendata}: Stata module to access World Bank databases},
year = {2011},
publisher = {Statistical Software Components, Boston College},
number = {S457234},
url = {https://ideas.repec.org/c/boc/bocode/s457234.html}
}
Source data: World Bank Open Data — https://data.worldbank.org/.
Development
git clone https://github.com/jpazvd/wb-api-repo.git
cd wb-api-repo
pip install -e ".[test]"
PYTHONIOENCODING=utf-8 python -m pytest tests/ # 71 cases across discovery, wb_text, wb_api_tools, cli
Useful Makefile targets:
make wb-update-metadata # refresh YAML cache (v0.1.0 pipeline)
make wb-metadata # legacy YAML builder (pre-Phase-0)
make wb-metadata-csv # legacy CSV builder
make wb-config # batch data pulls from config.yaml
To regenerate the Quick-start figures from live API data, install the
[examples] extras group first (pulls in matplotlib + scipy + nbformat +
jupyter + nbconvert — none of these are runtime deps of wb-api-tools):
pip install -e ".[examples]"
WBOPENDATA_YAML_DIR=src/_ python examples/readme_examples.py # PNG + SVG to docs/figures/
WBOPENDATA_YAML_DIR=src/_ python examples/_build_readme_notebook.py # rebuild + execute the .ipynb
Branch model: feature work on develop; releases tag from main.
Integration
The Python CLI and library plug into:
- Makefiles / pipelines (
make wb-update-metadata, cron, GitHub Actions) - Stata workflows (export CSV →
import delimited, or use the Stata package directly) - R workflows (
readr::read_csvorarrow::read_parquet) - Jupyter notebooks for ad-hoc analysis
License
See LICENSE.md. Developed to bridge Stata wbopendata
workflows with modern Python pipelines for reproducible UNICEF / World
Bank style analytics.
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file wb_api_tools-0.3.0.tar.gz.
File metadata
- Download URL: wb_api_tools-0.3.0.tar.gz
- Upload date:
- Size: 61.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
08039a0df8f8a4d8efce9d0d544ffac6ee01cb1a62a323cefd886a83feaac170
|
|
| MD5 |
6987594b84c3f817afef2a364f521260
|
|
| BLAKE2b-256 |
f1bb74385d9fd0300027bff8a8621c13eb8f98e3e4e6858af784eb64610ec205
|
Provenance
The following attestation bundles were made for wb_api_tools-0.3.0.tar.gz:
Publisher:
publish.yml on jpazvd/wb-api-repo
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
wb_api_tools-0.3.0.tar.gz -
Subject digest:
08039a0df8f8a4d8efce9d0d544ffac6ee01cb1a62a323cefd886a83feaac170 - Sigstore transparency entry: 1623452076
- Sigstore integration time:
-
Permalink:
jpazvd/wb-api-repo@ca790d3d80d53cc33c6cb70d351863c7c476ac7b -
Branch / Tag:
refs/tags/v0.3.0 - Owner: https://github.com/jpazvd
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@ca790d3d80d53cc33c6cb70d351863c7c476ac7b -
Trigger Event:
push
-
Statement type:
File details
Details for the file wb_api_tools-0.3.0-py3-none-any.whl.
File metadata
- Download URL: wb_api_tools-0.3.0-py3-none-any.whl
- Upload date:
- Size: 48.8 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
7044c23a6a05c267625350d61f03d70b2d65214e3f2d1a8f31a7345f98208fc6
|
|
| MD5 |
4f671c79d09ace9400797cdc157597ba
|
|
| BLAKE2b-256 |
7d1b636fbe47ff820752af7081f7359445a9cad49dcf1bcd3458a31f619bc57a
|
Provenance
The following attestation bundles were made for wb_api_tools-0.3.0-py3-none-any.whl:
Publisher:
publish.yml on jpazvd/wb-api-repo
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
wb_api_tools-0.3.0-py3-none-any.whl -
Subject digest:
7044c23a6a05c267625350d61f03d70b2d65214e3f2d1a8f31a7345f98208fc6 - Sigstore transparency entry: 1623452205
- Sigstore integration time:
-
Permalink:
jpazvd/wb-api-repo@ca790d3d80d53cc33c6cb70d351863c7c476ac7b -
Branch / Tag:
refs/tags/v0.3.0 - Owner: https://github.com/jpazvd
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@ca790d3d80d53cc33c6cb70d351863c7c476ac7b -
Trigger Event:
push
-
Statement type:







