The WFDB Python package: tools for reading, writing, and processing physiologic signals and annotations.





Project description
The WFDB Python Package
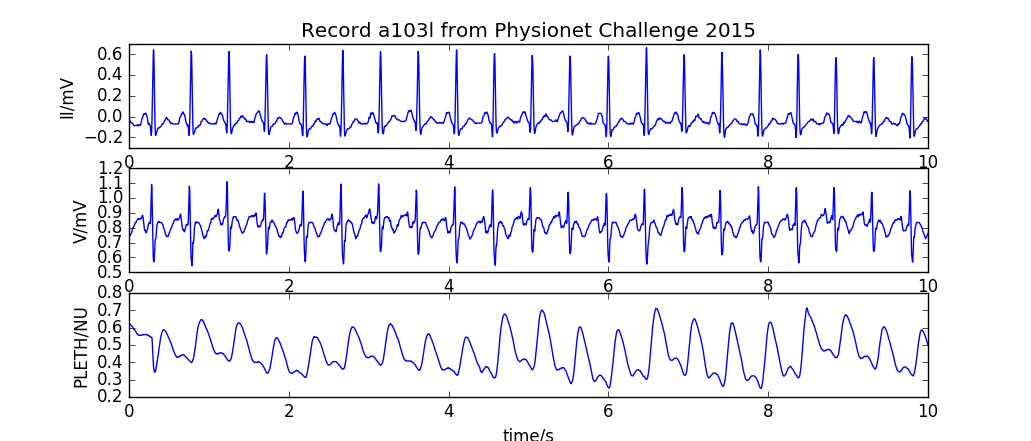




Introduction
A Python-native package for reading, writing, processing, and plotting physiologic signal and annotation data. The core I/O functionality is based on the Waveform Database (WFDB) specifications.
This package is heavily inspired by the original WFDB Software Package, and initially aimed to replicate many of its command-line APIs. However, the projects are independent, and there is no promise of consistency between the two, beyond each package adhering to the core specifications.
Documentation and Usage
See the documentation site for the public APIs.
See the demo.ipynb notebook file for example use cases.
Installation
The distribution is hosted on PyPI at: https://pypi.python.org/pypi/wfdb/. The package can be directly installed from PyPI using pip:
pip install wfdb
On some less-common systems, you may need to install libsndfile separately. See the soundfile installation notes for more information.
The development version is hosted at: https://github.com/MIT-LCP/wfdb-python. This repository also contains demo scripts and example data. To install the development version, clone or download the repository, navigate to the base directory, and run:
pip install .
If you intend to make changes to the repository, you can install additional packages that are useful for development by running:
pip install ".[dev]"
Developing
Please see the DEVELOPING.md document for contribution/development instructions.
Creating a new release
For guidance on creating a new release, see: https://github.com/MIT-LCP/wfdb-python/blob/main/DEVELOPING.md#creating-distributions
Citing
When using this resource, please cite the software publication on PhysioNet.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file wfdb-4.3.1.tar.gz.
File metadata
- Download URL: wfdb-4.3.1.tar.gz
- Upload date:
- Size: 163.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.9.28 {"installer":{"name":"uv","version":"0.9.28","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null}
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
d33e9b4674da6cf87bcfcdac640eea4fbe4f95e82a8b209bb6db05c345cd68df
|
|
| MD5 |
c9dcd50e26ea901b4b9628a2dc1d6594
|
|
| BLAKE2b-256 |
45af6fff8f3b2c23f58405fb790d0b60a3c61c5837356d9cda9646bcf0d6bf4f
|
File details
Details for the file wfdb-4.3.1-py3-none-any.whl.
File metadata
- Download URL: wfdb-4.3.1-py3-none-any.whl
- Upload date:
- Size: 163.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.9.28 {"installer":{"name":"uv","version":"0.9.28","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null}
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
aa1801cf835797b9051ab7955fb900ce6c5f1e1b6cd9cc9979e6c7304e157063
|
|
| MD5 |
bbcd1d4bbb4dfdd2d6640d9caf14b251
|
|
| BLAKE2b-256 |
d74505cc2ecbf61163bbbb18678dcdc7e7e7285f9f50f4dcf96a9ff07633ac52
|







