Deterministic, token-minimal, reproducible memory for Claude and agents: wikilink-graph retrieval, then compaction, then a Claude reader.

Project description
WikiMoth

Connects the dots. The same way, every time.
wikimoth.com · pip install wikimoth
Deterministic, token-minimal, auditable memory for Claude and agents. Point WikiMoth at a
folder of [[wikilink]] notes (an Obsidian vault, or Claude's own memory folder) and it
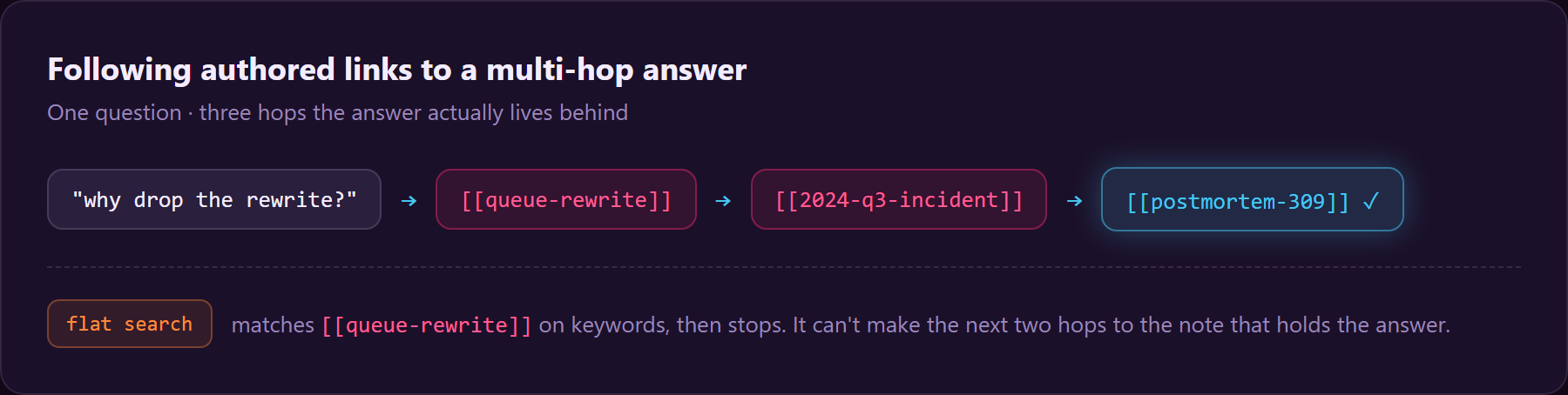
follows the authored links to the answer flat search can't reach, shows you the exact note-chain
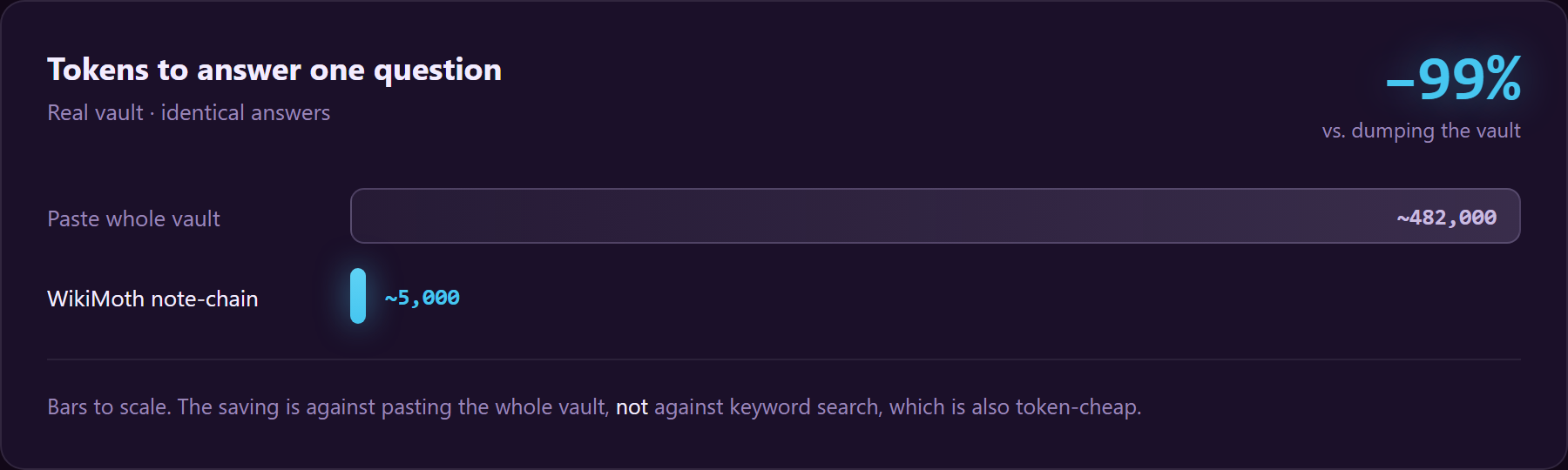
behind it, and feeds the reader ~99% fewer tokens than pasting the whole vault. Pure markdown,
no GPU, no vector DB, no LLM in the retrieval loop.
pip install wikimoth
wikimoth install # capture: turn your Claude Code sessions into a [[wikilink]] vault
wikimoth serve # browse the vault + see "what memory fed this answer"
Why WikiMoth
Most agent memory is either paste the whole notes folder into context (expensive, and the model
gets lost in the middle) or LLM-summarised similarity search (lossy, and non-deterministic:
the same question can return different memory next week). WikiMoth takes a different bet: your notes
are the store (plain markdown), the graph is authored (your [[wikilinks]], no embeddings
to train or drift), and retrieval is code, not a model, so it's reproducible and you can read
exactly why each note was chosen.
| WikiMoth | BM25 | Vector RAG | claude-mem | LLM Wiki (Karpathy) | |
|---|---|---|---|---|---|
Connects the dots (multi-hop over authored [[links]]) |
✅ | ❌ | ❌ | ❌ | ✅ (agentic) |
| Deterministic retrieval (same query → same result) | ✅ | ✅ | ✅ | ❌ | ❌ |
| No LLM call to retrieve | ✅ | ✅ | ✅ | ~ | ❌ |
| Auditable note-chain (which notes produced the answer) | ✅ | ~ | ❌ | ❌ | ~ |
| Direct-lookup recall@8 (real vault) | 1.00 | 1.00 | 1.00 | ~ | ~ |
| No GPU / no vector DB / no index build | ✅ | ✅ | ❌ | ~ | ✅ |
| Plain-markdown store (open in any editor) | ✅ | ~ | ❌ | ❌ | ✅ |
| Token-minimal vs dumping the vault | ✅ −99% | ✅ −99% | ✅ −99% | ✅ | ~ |
| Deterministic, API-free auto-capture | ✅ | ❌ | ❌ | ❌ | ❌ |
LLM Wiki follows links and skips the vector DB like WikiMoth, but an LLM writes and reads the wiki, so retrieval is agentic (an LLM call per recall, not reproducible), while its curated pages are richer. ~ = partial / not independently benchmarked.
The edge is the combination, not higher recall: WikiMoth matches flat search on the basics and adds connect-the-dots + determinism + an audit trail + a plain-markdown store. See Honest limits for exactly where it ties and where it wins.
Compared to Karpathy's LLM Wiki
WikiMoth shares the substrate Andrej Karpathy's LLM Wiki pattern popularised: plain-markdown
[[wikilink]] notes, no vector DB, but flips the engine. In the LLM-Wiki pattern an LLM
writes and reads the wiki: rich, source-cited pages, but recall is agentic (it costs an LLM
call and the path isn't reproducible). WikiMoth computes the edges in code and retrieves with a
fixed algorithm, no LLM in the loop → the same note-chain every time, reproducible and
auditable. They're complementary, not competing: point WikiMoth at a Karpathy-style wiki and you get
deterministic multi-hop retrieval over it. (We don't claim to be "better" than the LLM Wiki: it
curates richer pages; we retrieve deterministically.)
Quickstart (read)
from wikimoth import MemoryRAG, EchoReader
rag = MemoryRAG(reader=EchoReader()) # API-free default reader
rag.index("path/to/your/wikilink/vault") # notes → ~400-token chunks, graph built
chunks, tokens = rag.retrieve("a connect-the-dots question?", top_k=8)
print(f"{len(chunks)} chunks, {tokens} tokens to feed the reader")
print(rag.answer("a connect-the-dots question?")) # retrieve → compact → read
Swap in a real Claude answer (only touches the API when constructed):
from wikimoth import MemoryRAG, ClaudeReader
rag = MemoryRAG(reader=ClaudeReader(model="claude-sonnet-4-6")) # needs ANTHROPIC_API_KEY
See what memory fed an answer: wikimoth serve
wikimoth serve # serves http://127.0.0.1:8765 (local-only)
wikimoth serve --vault PATH --port 8080
A zero-dependency local web viewer (pure stdlib, no Flask, no JS framework, no network):
- browse + search your notes,
- the authored
[[wikilink]]graph (the same edges the retriever walks), - and the one that matters, "what memory fed this answer": type a question and see the exact
note-chain WikiMoth would feed a reader, with per-chunk hop distance, token counts, and the
−N%vs dumping the whole vault. Retrieval only: no LLM call, no API key, deterministic.
Because the store is plain markdown, you can equally open the same vault in Obsidian or VS Code; the viewer is a convenience, not a lock-in.
Capture: sessions → notes (the write half)
Retrieval needs a [[wikilink]] vault; hand-authoring one is the friction. wikimoth.capture builds
it automatically by installing Claude Code lifecycle hooks that turn each session into one
deterministic markdown note.
The invariant that matters: a note's [[wikilinks]] (the graph edges) are computed by code
(string/path matching), never by a model. An LLM may optionally draft the summary prose
(WIKIMOTH_LLM_PROSE=1), but any [[...]] it emits is stripped, never parsed as an edge. So the
graph is reproducible (same session + vault → same edges) and auditable. Default capture is fully
deterministic and makes zero API calls.
wikimoth install # writes 5 hooks into ./.claude/settings.json (absolute interpreter path)
wikimoth install --user # ~/.claude/settings.json instead
wikimoth install --vault PATH # choose where notes go (sets WIKIMOTH_VAULT)
wikimoth status # vault, note/session/buffer counts, hook state
wikimoth uninstall # remove the hooks again
Lifecycle: SessionStart recalls recent sessions into context · UserPromptSubmit / PostToolUse buffer the session · Stop / SessionEnd write one note. The captured notes are exactly what the read pipeline indexes; capture and retrieval close the loop.
Install

WikiMoth's core is pure stdlib (dependencies = []): the retrieval engine, chunker, wikilink
graph, pipeline and capture are all vendored under wikimoth/: nothing extra to install, no GPU, no
vector DB.
pip install wikimoth
# before the PyPI release, install from source:
pip install "git+https://github.com/juliangeymonat-jpg/wikimoth"
# optional extras:
pip install "wikimoth[hybrid]" # BM25-seeded HybridRetriever (best direct-lookup + multi-hop)
pip install "wikimoth[claude,tokens]" # real Claude reader + exact tiktoken counts
Extras: hybrid = BM25-seeded retriever (rank_bm25) · claude = the anthropic reader ·
tokens = exact token counts (tiktoken) · dense = the dense benchmark baseline · headroom =
reversible CCR compaction.
How it works
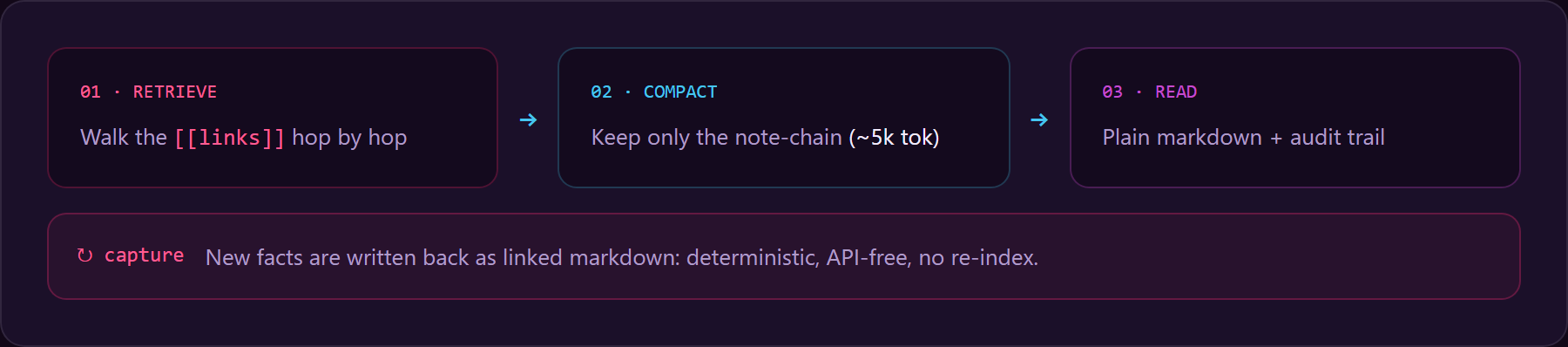
retrieve → compact → read. index() splits each note into ~400-token chunks (~50 overlap),
keeping per-chunk note identity so the [[wikilink]] graph still connects across chunks (multi-hop
at chunk granularity). GraphRetriever(source="wikilinks") seeds lexically, then walks the authored
links, so a passage not lexically similar to the question but reachable by a link still gets
pulled. An optional compaction stage (reversible CCR via
chopratejas/headroom) shrinks passages further before
the (paid) reader; it degrades to a no-op if headroom isn't installed.
A pure-navigation hub (a table-of-contents like MEMORY.md) can be indexed as graph edges only
(exclude_content, default ("MEMORY.md",)): its [[links]] build edges and it stays a BFS
waypoint, but its own chunks never reach the reader.
Every stage is constructor-injectable via MemoryRAG(retriever=…, compactor=…, reader=…), so you can
swap the retriever (e.g. the BM25-seeded HybridRetriever), the compactor, or the reader.
Benchmark: tokens fed to the reader
wikimoth.benchmark.harness measures tokens fed to the reader (what you actually pay for) across
arms over the same vault and questions:
| arm | feeds the reader | status |
|---|---|---|
dump |
the whole vault | baseline |
deterministic |
wikilink-graph retrieval | implemented |
deterministic_compacted |
retrieval + Headroom | implemented |
agentic |
an LLM browses and prunes its own context | implemented (Claude tool-use) |
No paid API calls run by default; every arm's reader defaults to the API-free EchoReader.
Honest limits
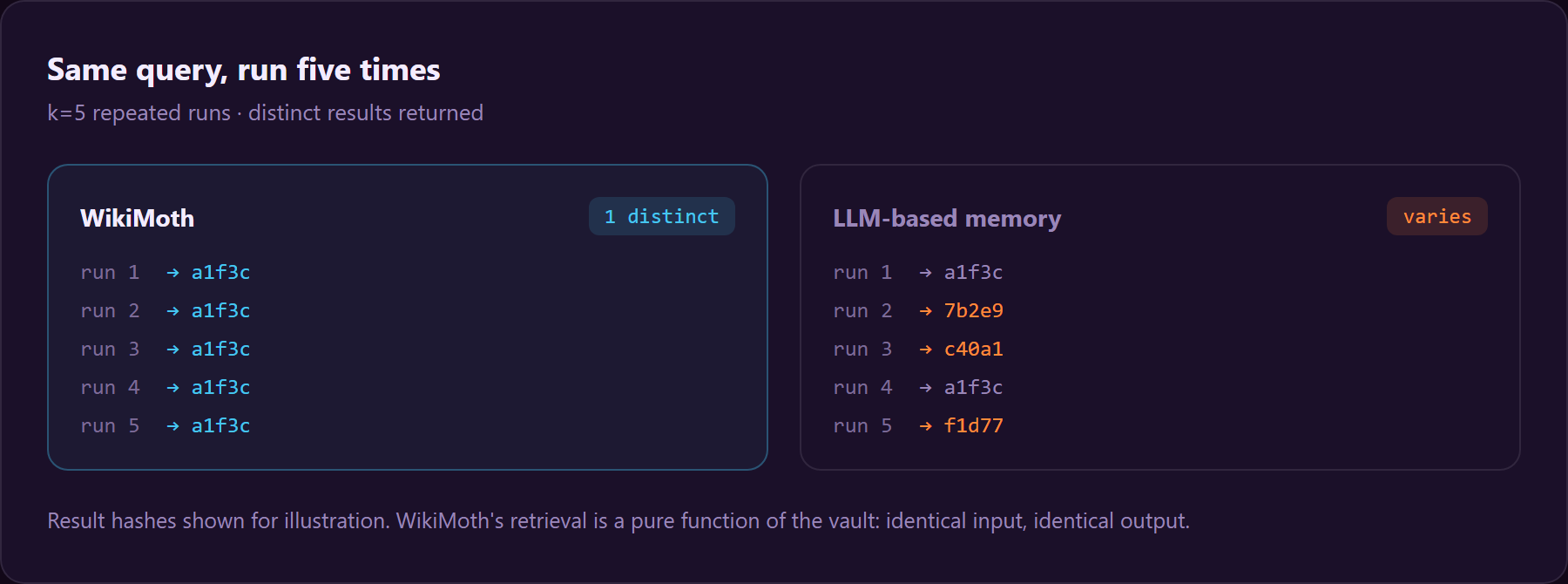
WikiMoth's value is deterministic, auditable, token-minimal, plain-markdown memory with a real multi-hop capability, not "better retrieval than BM25". Specifically:
- The −99% is vs dumping the vault (≈5k vs ~482k tokens on a real 356-note vault), not vs BM25: a tuned BM25-RAG also feeds ~5k. The win is against the realistic status quo (paste everything / naive whole-note RAG), and it's deterministic.
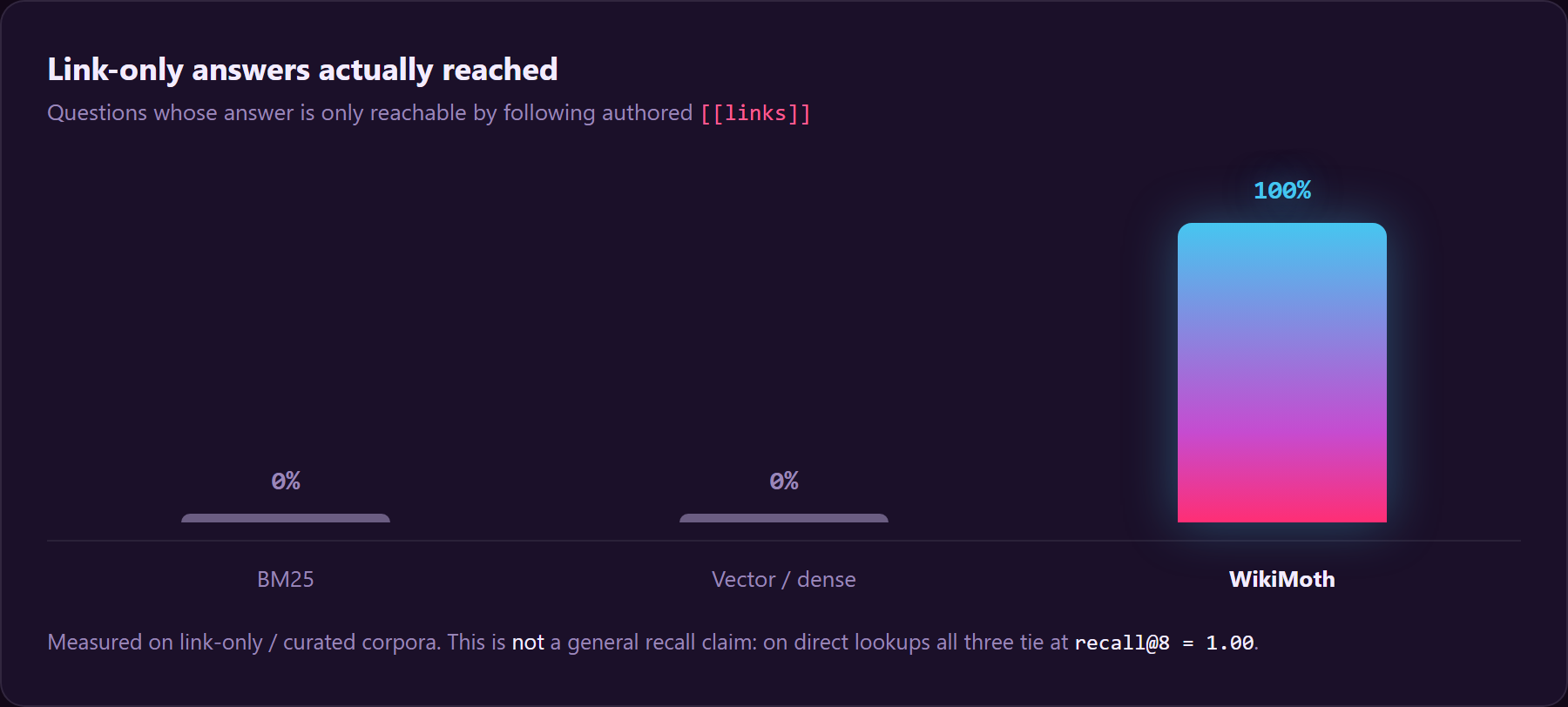
- On a typical real vault, retrieval ≈ BM25. Direct-lookup recall@8 ties at 1.00. The multi-hop / connect-the-dots win (0% → up to 100% where flat search scores zero) shows up on curated, link-heavy corpora; on an average vault, hybrid is never worse than BM25, not strictly better on recall.
- Determinism is inherent to any static retriever (BM25/dense too); WikiMoth's determinism win is specifically vs LLM-summarised memory (which varies run to run).
- vs letting the model prune its own context (the
agenticarm, real run against Claude Sonnet 4.6): an agent that browses the notes folder itself reaches the same answers, multi-hop included (12/12 exact match, recall 1.00). So it is not crippled, and it actually pulls slightly fewer note-body content tokens than WikiMoth does (mean 118 vs 198), because it opens only the exact chain notes rather than a top-k feed. For context, WikiMoth's ~97% token saving is measured against dumping the whole vault into the reader (5,736 tokens fed drops to ~198), not against the agent's content reads. The catch with the agent is what you pay for: every browse step re-sends the growing transcript, so across 4 to 6 paid round-trips per question the agent billed a mean of ~4,353 input tokens, roughly 22x the ~198 tokens one deterministic pass feeds, with zero model calls inside the deterministic retrieval loop. That is where the real edge sits: cost, round-trips, and a no-model-in-the-loop pass you can audit, not fewer content tokens. On this clean single-path corpus the agent's read-set was also stable across repeats, so determinism was NOT shown to differ here (the determinism edge vs LLM-summarised memory is a separate point and is not claimed from this run). Two honesty notes: the 22x compares the agent's full billed loop against WikiMoth's retrieval payload only (a production WikiMoth answer also pays a reader, which narrows the real gap to roughly 10x), and the multiple is corpus-specific (1-sentence notes, chains of depth no more than 3), not a law. Run it yourself:python scripts/run_agentic_benchmark.py(needs an API key). A published large-scale capture dogfood is still pending.
Pluggable + License
MemoryRAG(retriever=…, compactor=…, reader=…); defaults GraphRetriever(source="wikilinks") /
NoOpCompactor / EchoReader. Anything satisfying the small Protocols drops in.
Apache-2.0; see LICENSE. © 2026 Julian Geymonat.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file wikimoth-0.1.1.tar.gz.
File metadata
- Download URL: wikimoth-0.1.1.tar.gz
- Upload date:
- Size: 96.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c89d77e7c472aa4b3d4d7269e76ba913f26271cd4b7b9d2e1c175fc35e75367a
|
|
| MD5 |
ad3e1a0420e9054d3f969e682202fca8
|
|
| BLAKE2b-256 |
08d78c0a6e670c21f4be46bc82a2af4e278c6efd284ab3405d24509ff5f6a0a1
|
File details
Details for the file wikimoth-0.1.1-py3-none-any.whl.
File metadata
- Download URL: wikimoth-0.1.1-py3-none-any.whl
- Upload date:
- Size: 81.4 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6de0e1493ee8111680a4797cb4f15b6cebbf3c3f9a16c4f96bd3f2b3e75d75a9
|
|
| MD5 |
655124bd8e5dd6906f3e78e7274c31b7
|
|
| BLAKE2b-256 |
d430a939ffd4eb22299c9ea5214de065239e7745d4fdf45b707ef48e09a9ecd2
|







