A Wordle solver with pluggable strategies and a strategy-comparison benchmark suite.

Project description



wordlesmith
A Wordle solver with pluggable strategies and a benchmark suite for comparing them.
Considers every valid word a possible answer, so it never dead-ends on a real puzzle (entropy averages 4.52 guesses over all 14,855 valid words, and 3.60 on the classic 2,315-answer set). The core is pure standard library.

Contents
- What it does
- Install
- Quickstart
- Benchmark
- How it works
- Strategies (in-depth)
- Development
- License & contact
What it does
wordlesmith is a command-line and library Wordle solver. It ships:
- A Wordle scoring engine that handles duplicate letters correctly, which is where most solvers have subtle bugs.
- Five strategies behind one interface: positional frequency, entropy, expected remaining size, minimax, and a random control.
- A benchmark framework that plays every valid word and reports the full guess distribution.
- The full 14,855-word valid-guess list (the default answer pool, so it never dead-ends on a real puzzle) and the original 2,315-word answer set, packaged with a precomputed opening-guess table so the first move is instant.
The core has no third-party dependencies. Plotting is the only extra.
Install
# From GitHub
pip install "git+https://github.com/adityakmehrotra/wordlesmith"
# For development (tests, lint, plots)
git clone https://github.com/adityakmehrotra/wordlesmith
cd wordlesmith
pip install -e ".[dev,bench]"
Requires Python 3.10+.
Quickstart
Command line
Auto-solve a known word:

(maven is a real NYT answer that isn't in the original 2,315-word list, so a solver built only
on that list would never find it. The default pool is every valid word, so this just works.)
Play along with a real puzzle: it suggests a guess, you type the colors back
(g=green, y=yellow, x=gray):
$ wordlesmith play --strategy entropy
Turn 1 suggestion: TARES (14855 candidates)
Enter feedback: xgxgx
Turn 2 suggestion: LADEN (150 candidates)
Enter feedback: ...
Benchmark one strategy, or compare several:
$ wordlesmith benchmark --strategy entropy --sample 300
$ wordlesmith compare --strategies frequency,entropy,minimax --markdown
$ wordlesmith compare --curated --markdown # the classic 2,315-answer set
Run wordlesmith --help (or wordlesmith <command> --help) for all options,
including --curated, --guess-pool all, --jobs for parallel benchmarks, and
--answers/--allowed for custom word lists.
Python API
from wordlesmith import get_strategy, simulate, feedback, pattern_to_string
# Score a guess against a target (base-3 pattern; g/y/x string for humans)
print(pattern_to_string(feedback("speed", "abide"))) # -> xxyxy
# Auto-play a word
result = simulate("maven", get_strategy("entropy"))
print(result.turns, result.guesses) # -> 3 ['tares', 'laden', 'maven']
Benchmark
Lower average is better; max is the worst game; fail% is games not solved within six
guesses.
Primary: every valid word (the default)
Each strategy plays all 14,855 valid words, guessing from the words still consistent with the feedback. This is how the solver actually runs, so it never dead-ends on a real puzzle:
| strategy | pool | avg | max | fail% |
|---|---|---|---|---|
| random | answers | 5.061 | >6 | 16.68 |
| frequency | answers | 4.922 | >6 | 14.57 |
| minimax | answers | 4.658 | >6 | 11.29 |
| expected-size | answers | 4.585 | >6 | 10.57 |
| entropy | answers | 4.523 | >6 | 9.47 |
The averages are higher and the failure rate is non-trivial (about 9% even for entropy) because the
full valid list is packed with near-identical clusters (match/batch/catch/hatch/..., the
-ound and -ight families, plus many obscure words) that simply cannot be separated in six
guesses. Those hard words are almost never real NYT answers, so for actual daily play the curated
number below is the realistic one; this table is the pessimistic "solve literally any valid word"
figure.
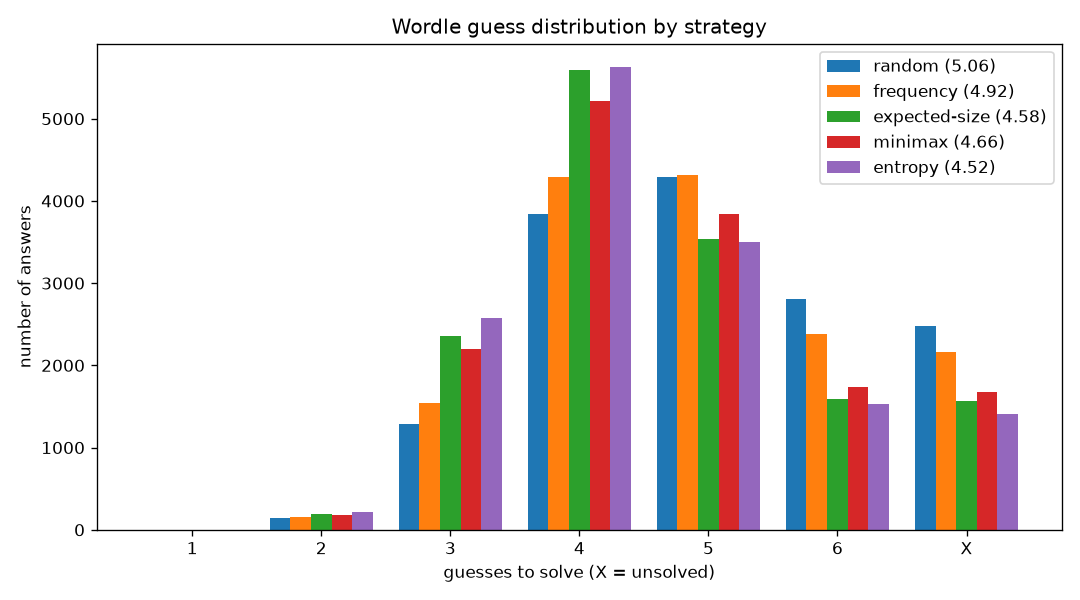
Secondary: the classic 2,315-answer set (--curated)
Restricted to the original Wordle solution set, the problem is easier and the numbers are
comparable to published solvers. The all pool (guessing any word for information) gets close
to the known optimum of about 3.421:
| strategy | pool | avg | max | fail% |
|---|---|---|---|---|
| random | answers | 4.039 | >6 | 0.82 |
| frequency | answers | 3.640 | >6 | 0.60 |
| expected-size | answers | 3.623 | >6 | 0.60 |
| minimax | answers | 3.677 | >6 | 0.65 |
| entropy | answers | 3.598 | >6 | 0.48 |
| entropy | all | 3.465 | 6 | 0.00 |
| expected-size | all | 3.481 | 5 | 0.00 |
| minimax | all | 3.573 | 6 | 0.00 |
A concrete example of what the smart strategies buy you: solving mound on the curated set, the
frequency baseline burns turns cycling through lookalikes (slate, crony, bound, found,
hound, mound) while entropy picks a splitting guess and finishes in three (raise, mulch,
mound).
Methodology: a game is a failure if unsolved in 6 guesses (counted as 7 in the mean).
Deterministic strategies are reproducible; random uses a fixed seed. Full results and per-word
data are in benchmarks/results/official/; regenerate the primary
with python scripts/run_official_benchmark.py. The primary answers-pool run takes about 10
minutes per strategy on 9 cores; the curated all-pool run scores every valid word each turn and
takes far longer, which is why it stays on the smaller curated set. Use --sample N for a quick
estimate.
How it works
Scoring: Wordle feedback is computed in two passes. Greens are assigned first and each
consumes its letter in the target; yellows are then assigned left to right, each consuming
a remaining occurrence. A guess letter with no occurrence left is gray. This is why the
second E in SPEED is gray against ABIDE, which has only one E.
Filtering: after each guess the solver keeps a word w only if feedback(guess, w)
equals the pattern actually observed. This single rule handles every duplicate-letter case
correctly, so there is no separate (and bug-prone) tracking of which letters are "in" or
"out".
Word lists: by default every valid Wordle word is treated as a possible answer. The original
Wordle solution set was only 2,315 words, but the NYT has revised it over time, so a solver
built on that list can dead-end on a legitimate answer it never considered (maven, for
instance). Using the full valid list avoids that, at the cost of a somewhat higher average
since there are more words to tell apart. Pass --curated to fall back to the original
2,315-answer set (faster, and the numbers become comparable to published solvers).
Strategies
| name | idea | good for |
|---|---|---|
frequency |
Sum of per-position letter frequencies among candidates (the original baseline). | A strong, cheap heuristic. |
entropy |
Maximize expected information (Shannon entropy of the feedback-bucket distribution). | Best average guess count. |
expected-size |
Minimize the expected number of remaining candidates. | Simple, nearly as strong as entropy. |
minimax |
Minimize the largest feedback bucket (worst case). | Smallest worst case. |
random |
Guess a random consistent word. | A control / lower bound. |
The entropy, expected-size, and minimax strategies accept a --guess-pool of answers
(guess from remaining candidates) or all (guess from the full allowed list).
See docs/strategies.md for an in-depth explanation of each strategy:
the scoring formulas, the bucket-splitting idea the information-theoretic strategies share
(with a worked example), the guess-pool trade-off, and how to add your own strategy.
Limitations
- Pure Python is slow for the
allguess pool. Scoring every valid word each turn takes minutes per benchmark, which is why the committedall-pool numbers stay on the curated set. For a single interactivesolve/playit's fine (the opening is precomputed). - The word list is a snapshot.
valid_words.txtis the NYT valid-guess list as of mid-2025. If the NYT adds words later, refresh it and regenerate the opening table. - Six-guess failures are expected. Over the full valid list even entropy fails about 9% of
games, because clusters like
match/batch/catch/hatchor the-ound/-ightfamilies can't be separated in six turns. Those words are rarely real answers, so--curatedis the realistic daily-play figure. - The strategies are greedy. They optimize the current guess, not the whole game tree, so even the best is a step behind the known optimal decision tree (about 3.421 on the curated set).
- English five-letter Wordle only. No hard mode and no other word lengths (the engine assumes
five letters), though
--answers/--allowedaccept custom five-letter word lists.
Development
pip install -e ".[dev,bench]"
pytest --cov=wordlesmith # tests + coverage
ruff check . && ruff format --check .
mypy src/
python -m build && twine check dist/*
Contributions welcome. A natural extension is adding a new strategy: implement Strategy,
register it, and it shows up in compare automatically. Please open an
issue or PR.
License & contact
Distributed under the MIT License. See LICENSE.txt.
Aditya Mehrotra. Reach me at adi1.mehrotra@gmail.com or on
LinkedIn.
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file wordlesmith-0.1.0.tar.gz.
File metadata
- Download URL: wordlesmith-0.1.0.tar.gz
- Upload date:
- Size: 416.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
eb127111190a07c094f95b0db62ca553b892419d3255a3faaf31009365668253
|
|
| MD5 |
d08058d92a495374e9b18e2b87571007
|
|
| BLAKE2b-256 |
4df4f62b8c4c12cc27b31c17e947abc0beeb06b5a829332a805df07f279feb4b
|
File details
Details for the file wordlesmith-0.1.0-py3-none-any.whl.
File metadata
- Download URL: wordlesmith-0.1.0-py3-none-any.whl
- Upload date:
- Size: 67.2 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
49d74f5dba91be0c1e440cbcfe4de1df848892cc67193e348bd7e180089bd7d8
|
|
| MD5 |
c51692eb2b2455795c9848c5c6ecd191
|
|
| BLAKE2b-256 |
8277d0cd34a909a794555f2727411b0a3e8c4ff4ce6f5b63fdbb17942cd2c07b
|







