Index for finding jobs & roles used in a Zuul based CI system



Project description


The Zuul Building Blocks Index (aka Zubbi) makes it easy to search for available jobs and roles ("Building Blocks") within a Zuul based CI system - even if they are spread over multiple tenants or repositories.
Contents: Architecture | Quickstart | Development | Scraper usage | Configuration Examples | Available Connections |
Architecture
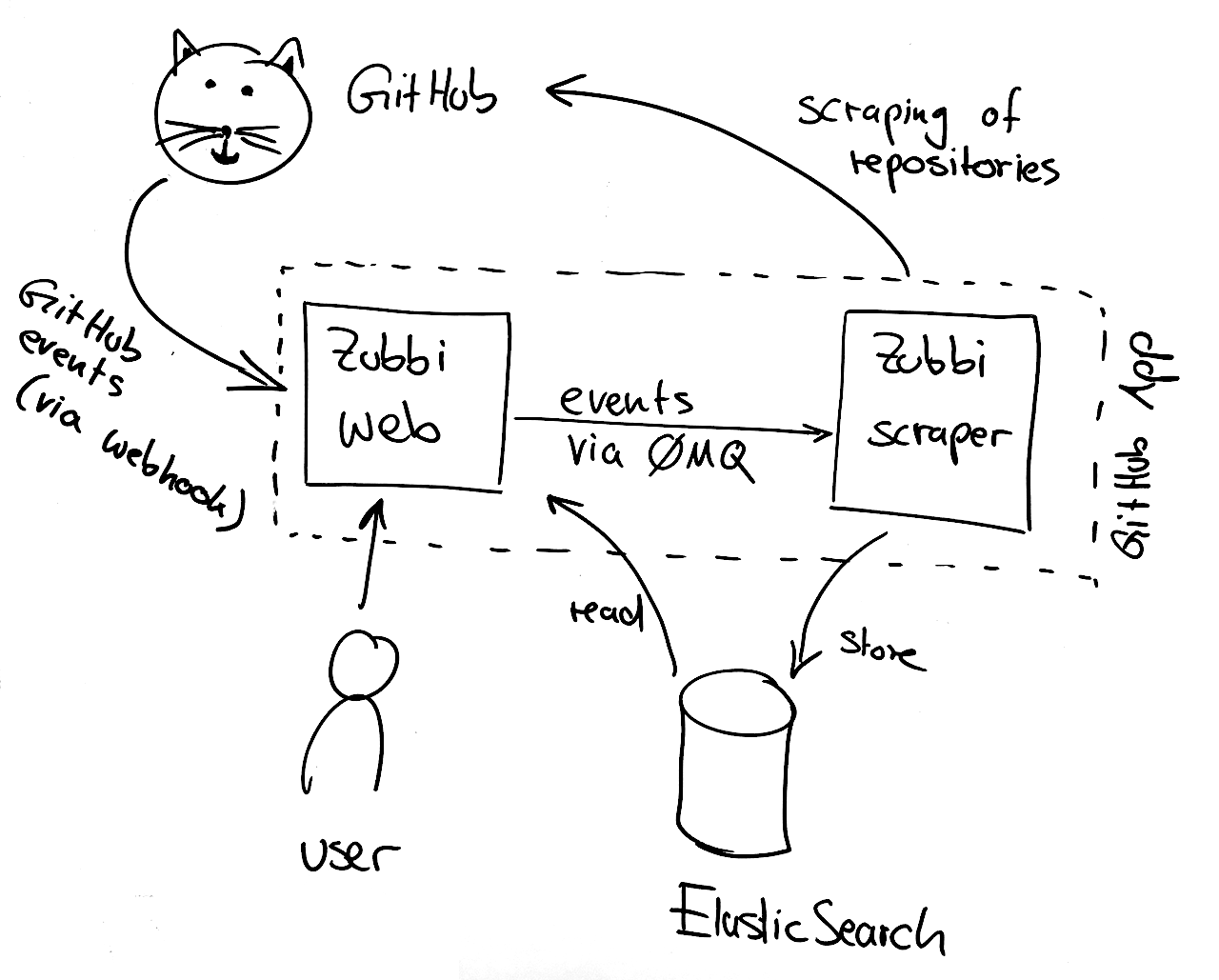
Zubbi consists of two parts, zubbi web and zubbi scraper. It uses Elasticsearch as storage backend and needs Git repositories as source for job and role definitions.
Zubbi web
A web frontend based on Flask that reads the data from Elasticsearch. It allows searching for roles and jobs used within the CI system and shows the results including their documentation, last updates, changelog and some additional meta data.
Zubbi scraper
A Python application that scrapes Git repositories, searches for job and role definitions in specific files and stores them in Elasticsearch.
Quickstart
Prerequisites: Docker Compose
Zubbi can simply be started by using the provided docker-compose.yaml file.
NOTE
The provided Dockerfile should only be used for demonstration purposes and not
in a production system. Flask is running in development mode and listens on all
public IPs to make it reachable from outside the docker container.
To get the whole stack up and running, do the following:
cd docker
docker-compose build
docker-compose up
This will build the docker container with the newest Zubbi version, start all
necessary services (Elasticsearch, zubbi-scraper, zubbi-web) and does a full
scrape of the openstack-infra/zuul-jobs repository to get an initial set of
data.
When everything is up, you can visit http://localhost:5000 and explore the jobs
and roles from the openstack-infra/zuul-jobs repo.
Development
Prerequisites: Python 3.10, and uv installed.
To install necessary dependencies for development, run:
uv sync
We are using ruff to ensure well-formatted Python code. To automatically ensure this on each commit, you can use the included pre-commit hook. To install the hook, simply run:
pre-commit install
Before submitting pull requests, run tests and static code checks using make:
make lint
make test
Installing & updating dependencies
New dependencies should be added via uv:
uv add <dependency>
Test dependencies should be installed as development dependencies:
uv add --dev <dependency>
To update the dependencies to the latest version run
uv lock --upgrade
and commit the changed uv.lock file.
Afterwards it's usually a good idea to run the following command to update the local environment accordingly:
uv sync
Release a new version
- Prepare the
CHANGELOG.mdfile for the next release version, push the change and merge it. - Create a git tag with the release version and push it to master, e.g.
git tag v2.8.0 git push --tags
- Create the source distribution and wheel files via
uv/make:make dist - Upload the release to PyPI:
twine upload --repository zubbi dist/*
Configuring and starting Zubbi
If you followed the Development guide so far, you should already have a virtual environment with all required packages to run Zubbi. What's left, are a few configuration files and a local Elasticsearch instance for testing.
Elasticsearch
Zubbi is currently depending on Elasticsearch as data backend. If you have
Docker Compose installed, you can use
the provided docker-compose.yaml file to start Elasticsearch locally.
cd docker
docker-compose up elasticsearch
If not, we recommend to use the latest available Elasticsearch Docker image, to get a local instance up and running for development.
Configuration
Both - Zubbi scraper and Zubbi web - read their configuration from the file path
given via the ZUBBI_SETTINGS environment variable:
export ZUBBI_SETTINGS=$(pwd)/settings.cfg
In order to show jobs and roles in Zubbi, we need to provide a minimal
tenant configuration
containing at least a single repository (which is used as source).
Therefore, put the following in a tenant-config.yaml file:
- tenant:
name: openstack
source:
openstack-gerrit:
untrusted-projects:
- openstack-infra/zuul-jobs
Put the following in your settings.cfg to allow scraping based on the tenant
configuration above and store the results in the local Elasticsearch instance.
Please note, that the key in the CONNECTIONS dictionary must go in hand with
the source names in the tenant configuration.
ELASTICSEARCH = {
'host': 'http://localhost:9200',
}
TENANT_SOURCES_FILE = 'tenant-config.yaml'
CONNECTIONS = {
'openstack-gerrit': {
'provider': 'git',
'git_host_url': 'https://git.openstack.org',
},
}
Running Zubbi
Now we can scrape the openstack-infra/zuul-jobs repository to get a first set
of jobs and roles into Elasticsearch and show them in Zubbi:
zubbi-scraper scrape --full
When the scraper run was successful, we can start Zubbi web to take a look at our data:
export FLASK_APP=zubbi
export FLASK_DEBUG=true
flask run
Building the syntax highlighting stylesheet with pygments
We are using a pre-build pygments stylesheet to highlight the code examples in job and roles documentations. In case you want to rebuild this syntax highlighting stylesheet (e.g. to try out another highlighting style) you can run the following command:
pygmentize -S default -f html -a .highlight > zubbi/static/pygments.css
Scraper usage
The Zubbi scraper supports two different modes: periodic (default) and immediate.
To start the scraper in periodic mode, simply run:
zubbi-scraper scrape
This should also scrape all repositories specified in the tenant configuration for the first time.
To immediately scrape one or more repositories, you can use the following command:
# Scrape one or more repositories
zubbi-scraper scrape --repo 'orga1/repo1' --repo 'orga1/repo2'
# Scrape all repositories
zubbi-scraper scrape --full
Additionally, the scraper provides a list-repos command to list all
available repositories together with some additional information like the
last scraping timestamp and the git provider (connection type):
zubbi-scraper list-repos
Configuration examples
Examples for all available settings can be found in settings.cfg.example.
Tenant Configuration
Zubbi needs to know which projects contain the job and role definitions that
are used inside the CI system. To achieve this, it uses Zuul's
tenant configuration.
Usually, this tenant configuration is stored in a file that must be specified
in the settings.cfg, but it could also come from a repository.
# Use only one of the following, not both
TENANT_SOURCES_FILE = '<path_to_the_yaml_file>'
TENANT_SOURCES_REPO = '<orga>/<repo>'
Elasticsearch Connection
The Elasticsearch connection can be configured in the settings.cfg like
the following:
ELASTICSEARCH = {
'host': 'http(s)://<elasticsearch_host>:<port>',
'user': '<user>',
'password': '<password>',
# Optional, to enable SSL for the Elasticsearch connection.
# You must at least set 'enabled' to True and provide other parameters if the default
# values are not sufficient.
'tls': {
'enabled': False, # default
'check_hostname': True, # default
'verify_mode': 'CERT_REQUIRED', # default
},
}
To avoid name clashes with existing indices in Elasticsearch, one could specify
an index prefix via the ZUBBI_INDEX_PREFIX environment variable. This prefix
will be applied to all indices that are used by Zubbi.
Available Connections
Currently, Zubbi supports the following connection types: GitHub, Gerrit and Git. The latter one can be used for repositories that are not hosted on either GitHub or Gerrit.
GitHub
The GitHub connection uses GitHub's REST API to scrape the repositories. To be able to use this connection, you need to create a GitHub App with the following permissions:
Repository contents: Read-only
Repository metadata: Read-only
If you are unsure about how to set up a GitHub App, take a look at the official guide.
Once you have successfully created your GitHub App, you can define the connection
with the following parameters in your settings.cfg accordingly:
CONNECTIONS = {
'<name>': {
'provider': 'github',
'url': '<github_url>',
'app_id': <your_github_app_id>,
'app_key': '<path_to_keyfile>',
},
...
}
Using GitHub Webhooks
GitHub webhooks can be used to keep your Zubbi data up to date.
To activate GitHub webhooks, you have to provide a weebhook URL pointing to
the /api/webhook endpoint of your Zubbi web installation. The generated webhook
secret must be specified in the GITHUB_WEBHOOK_SECRET setting in your settings.cfg:
NOTE: As of now, GitHub webhooks are not supported on a per-connection base. You can only have one webhook active in zubbi.
GITHUB_WEBHOOK_SECRET = '<secret>'
Zubbi web receives webhook events from GitHub, validates the secret and publishes
relevant events to the scraper via ZMQ.
The Zubbi scraper on the other hand subscribes to the ZMQ socket and scrapes
necessary repositories whenever a event is received. In order to make this
communication work, you need to specify the following parameters in your settings.cfg:
# Zubbi web (publish)
ZMQ_PUB_SOCKET_ADDRESS = 'tcp://*:5556'
# Zubbi scraper (subscribe)
ZMQ_SUB_SOCKET_ADDRESS = 'tcp://localhost:5556'
Gerrit
In contrary to GitHub, the Gerrit connection is based on
GitPython as the Gerrit REST API
does not support all use cases. To use this connection, you have
to provide the following parameters in your settings.cfg:
CONNECTIONS = {
'<name>': {
'provider': 'gerrit',
'url': '<git_remote_url>',
# Only necessary if different from the git_remote_url
'web_url': '<gerrit_url>',
# The web_type is necessary to build the correct URLs for Gerrit.
# Currently supported types are 'cgit' (default) and 'gitweb'.
'web_type': 'cgit|gitweb',
# Optional, if authentication is required
'user': '<username>',
'password': '<password>',
},
...
}
Git
The Git connection is also based on
GitPython and can be used for Git
repositories that are not hosted on either GitHub or Gerrit. To use this connection,
put the following in your settings.cfg:
CONNECTIONS = {
'<name>': {
'provider': 'git',
'url': '<git_host_url>',
# Optional, if authentication is required
'user': '<username>',
'password': '<password',
},
...
}
Happy coding!
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file zubbi-3.0.0.tar.gz.
File metadata
- Download URL: zubbi-3.0.0.tar.gz
- Upload date:
- Size: 1.7 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.7.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
79409492a2830b3a9160770acd8a24941d41b179971e37a88295319dfa72dfd9
|
|
| MD5 |
c1269958711e5454024b7dc12d290e5f
|
|
| BLAKE2b-256 |
ec341368d9222c56cee477e1f814c9f532ede038a48251b14ba72bccb5265025
|
File details
Details for the file zubbi-3.0.0-py3-none-any.whl.
File metadata
- Download URL: zubbi-3.0.0-py3-none-any.whl
- Upload date:
- Size: 1.7 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.7.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
710c6d83271fbaba4afa1049ede490255bbbad3de516ea206a2a4d59542703bf
|
|
| MD5 |
5e11d8599d5b16c21b4b6c2dd73f3f14
|
|
| BLAKE2b-256 |
d41fc9d35a5e718890d37db55cda1e4a91453a8ddfadc28725eedf1e5878ccc1
|







