Python 作文生成器

Project description
CPM作文生成器
项目描述
在线体验地址:https://zuowen.wufan.fun/ (在这个人的基础上加以改进,做出的新版CPM模型,适用于新手) CPM(Chinese Pretrained Models)模型是北京智源人工智能研究院和清华大学发布的中文大规模预训练模型。官方发布了三种规模的模型,参数量分别为109M、334M、2.6B,用户需申请与通过审核,方可下载。 由于原项目需要考虑大模型的训练和使用,需要安装较为复杂的环境依赖,使用上也较为复杂。 本项目采用了109M的CPM模型(若资源允许也可以考虑334M的模型),并且简化了模型的训练和使用。
本项目是基于CPM模型的中文文本生成项目,可用于作文、小说、新闻、古诗等中文生成任务,并且训练和分享了中文作文生成模型,取得了不错的生成效果。 本项目提供了数据预处理、模型训练、文本生成、Http服务等代码模块。 详情可参考CPM模型论文, CPM官网, 项目源码 。
运行环境
python>=3.6、transformers==4.6.0、sentencepiece==0.1.94、torch==1.7.0、jieba == 0.42.1、streamlit == 1.10.0、tqdm == 4.64.0
模型参数与训练细节
由于GPU资源有限,本项目使用cpm-small.json中的模型参数,若资源充足,可尝试cpm-medium.json中的参数配置。
本项目的部分模型参数如下:
- n_ctx: 1024
- n_embd: 768
- n_head: 12
- n_layer: 12
- n_positions: 1024
- vocab_size: 30000
对26w篇作文进行预处理之后,得到60w+长度为200的训练数据。显卡为三张GTX 1080Ti,batch_size=50,三张卡显存满载,一轮训练大约需要3个小时。训练40轮之后,loss降到2.1左右,单词预测准确率大约为54%。
快速启动
使用pip进行安装:
pip install zuowen
使用请转到 使用 篇。
使用源码安装(已废弃)
git clone https://github.com/WindowsRegedit/zuowen
cd zuowen
python setup.py install
使用同 Pip 篇。
使用
本模块提供一下入口点:
入口点zuowen
生成作文的命令行接口。
完整介绍如下:
PS D:> zuowen --help
usage: zuowen [-h] [--device DEVICE] [--temperature TEMPERATURE] [--topk TOPK] [--topp TOPP] [--repetition_penalty REPETITION_PENALTY]
[--context_len CONTEXT_LEN] [--max_len MAX_LEN] [--log_path LOG_PATH] [--no_cuda] [--model_path MODEL_PATH] [--title TITLE]
[--context CONTEXT]
optional arguments:
-h, --help show this help message and exit
--device DEVICE 生成设备
--temperature TEMPERATURE
生成温度
--topk TOPK 最高几选一
--topp TOPP 最高积累概率
--repetition_penalty REPETITION_PENALTY
重复惩罚参数
--context_len CONTEXT_LEN
每一步生成时,参考的上文的长度
--max_len MAX_LEN 生成的最长长度
--log_path LOG_PATH 日志存放位置
--no_cuda 不使用GPU进行预测
--model_path MODEL_PATH
模型存放位置
--title TITLE 作文标题
--context CONTEXT 作文上文
入口点zuowen-ui
此程序没有参数。
调用后会在本地启动作文生成的服务。
使用Streamlit打造而成。
应用截图:
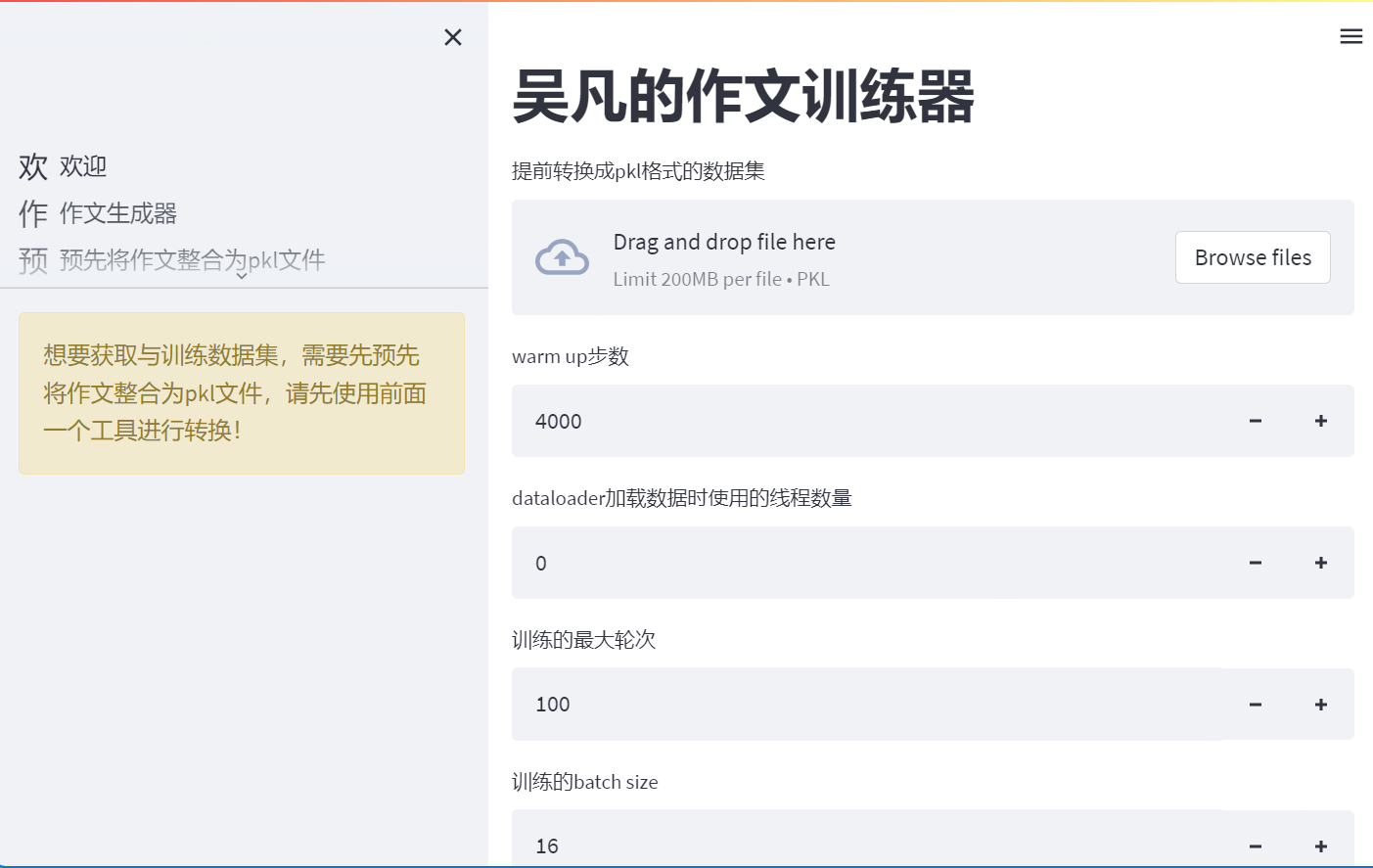
入口点zuowen-preprocess
(对于开发者) 每篇作文对应一个txt文件,txt内容格式如下:
---
标题:xxx
日期:xxxx-xx-xx xx:xx:xx
作者:xxx
---
内容
对于每个txt文件,首先取出标题与内容,将标题与内容按照"title[sep]content[eod]"的方式拼接起来,然后对其进行tokenize,最后使用滑动窗口对内容进行截断,得到训练数据。 运行如下命令,进行数据预处理。注:预处理之后的数据保存为train.pkl,这是一个list,list中每个元素表示一条训练数据。
zuowen-preoprocess --data_path data/zuowen --save_path data/train.pkl --win_size 200 --step 200
完整参数如下:
PS D:> zuowen-preprocess --help
usage: zuowen-preprocess [-h] [--vocab_file VOCAB_FILE] [--log_path LOG_PATH] [--data_path DATA_PATH] [--save_path SAVE_PATH]
[--win_size WIN_SIZE] [--step STEP]
optional arguments:
-h, --help show this help message and exit
--vocab_file VOCAB_FILE
词表路径
--log_path LOG_PATH 日志存放位置
--data_path DATA_PATH
数据集存放位置
--save_path SAVE_PATH
对训练数据集进行tokenize之后的数据存放位置
--win_size WIN_SIZE 滑动窗口的大小,相当于每条数据的最大长度
--step STEP 滑动窗口的滑动步幅
入口点zuowen-trainer
运行如下命令,使用预处理后的数据训练模型。
zuowen-trainer --epochs 100 --batch_size 16 --device 0,1 --gpu0_bsz 5 --train_path data/train.pkl
超参数说明:
- device:设置使用哪些GPU
- no_cuda:设为True时,不使用GPU
- vocab_path:sentencepiece模型路径,用于tokenize
- model_config:需要从头训练一个模型时,模型参数的配置文件
- train_path:经过预处理之后的数据存放路径
- max_len:训练时,输入数据的最大长度。
- log_path:训练日志存放位置
- ignore_index:对于该token_id,不计算loss,默认为-100
- epochs:训练的最大轮次
- batch_size:训练的batch size
- gpu0_bsz:pytorch使用多GPU并行训练时,存在负载不均衡的问题,即0号卡满载了,其他卡还存在很多空间,抛出OOM异常。该参数可以设置分配到0号卡上的数据数量。
- lr:学习率
- eps:AdamW优化器的衰减率
- log_step:多少步汇报一次loss
- gradient_accumulation_steps:梯度累计的步数。当显存空间不足,batch_size无法设置为较大时,通过梯度累计,缓解batch_size较小的问题。
- save_model_path:模型输出路径
- pretrained_model:预训练的模型的路径
- num_workers:dataloader加载数据时使用的线程数量
- warmup_steps:训练时的warm up步数
所有参数意思如下:
PS D:> zuowen-trainer --help
usage: zuowen-trainer [-h] [--device DEVICE] [--no_cuda] [--vocab_path VOCAB_PATH] [--model_config MODEL_CONFIG] [--train_path TRAIN_PATH]
[--max_len MAX_LEN] [--log_path LOG_PATH] [--ignore_index IGNORE_INDEX] [--epochs EPOCHS] [--batch_size BATCH_SIZE]
[--gpu0_bsz GPU0_BSZ] [--lr LR] [--eps EPS] [--log_step LOG_STEP]
[--gradient_accumulation_steps GRADIENT_ACCUMULATION_STEPS] [--max_grad_norm MAX_GRAD_NORM]
[--save_model_path SAVE_MODEL_PATH] [--pretrained_model PRETRAINED_MODEL] [--seed SEED] [--num_workers NUM_WORKERS]
[--warmup_steps WARMUP_STEPS]
optional arguments:
-h, --help show this help message and exit
--device DEVICE 设置使用哪些显卡
--no_cuda 不使用GPU进行训练
--vocab_path VOCAB_PATH
sp模型路径
--model_config MODEL_CONFIG
需要从头训练一个模型时,模型参数的配置文件
--train_path TRAIN_PATH
经过预处理之后的数据存放路径
--max_len MAX_LEN 训练时,输入数据的最大长度
--log_path LOG_PATH 训练日志存放位置
--ignore_index IGNORE_INDEX
对于ignore_index的label token不计算梯度
--epochs EPOCHS 训练的最大轮次
--batch_size BATCH_SIZE
训练的batch size
--gpu0_bsz GPU0_BSZ 0号卡的batch size
--lr LR 学习率
--eps EPS AdamW优化器的衰减率
--log_step LOG_STEP 多少步汇报一次loss
--gradient_accumulation_steps GRADIENT_ACCUMULATION_STEPS
梯度积累的步数
--max_grad_norm MAX_GRAD_NORM
--save_model_path SAVE_MODEL_PATH
模型输出路径
--pretrained_model PRETRAINED_MODEL
预训练的模型的路径
--seed SEED 设置随机种子
--num_workers NUM_WORKERS
dataloader加载数据时使用的线程数量
--warmup_steps WARMUP_STEPS
warm up步数
更新记录
[2022.6.29] 使作文生成器在输入时需要等待的时间变短了很多。
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distributions
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file zuowen-2022.6.29.post2-py3-none-any.whl.
File metadata
- Download URL: zuowen-2022.6.29.post2-py3-none-any.whl
- Upload date:
- Size: 825.1 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.9.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
0b2f2360e636c95bc5317a4e48d4a3a0f1ec08af7f05f16fd86fc4c218b37871
|
|
| MD5 |
a511824c5995ecb1f68f37b28002c852
|
|
| BLAKE2b-256 |
673b0ac20ce40d5d32c3dda790da178dce48be1e1342ba82faecff4c9386f52d
|







