常用函数工具包

Project description
安装
pip install zyf
或者
pip install zyf -i https://pypi.python.org/simple
使用
函数计时
示例1:timeit
from zyf.timer import timeit
@timeit
def sleep(seconds: int):
time.sleep(seconds)
sleep()
运行
>> sleep(1)
Function sleep -> takes 1.001 seconds
示例2:Timeit
from zyf.timer import timeit, Timeit
@Timeit(prefix='跑步')
def run():
time.sleep(3)
run()
运行
跑步 -> takes 3.000 seconds
示例3:repeat_timeit
from zyf.timer import repeat_timeit
@repeat_timeit(number=5)
def list_insert_time_test():
l = []
for i in range(10000):
l.insert(0, i)
@repeat_timeit(repeat=3, number=5)
def list_append_time_test():
l = []
for i in range(1000000):
l.append(i)
return l
@repeat_timeit(number=5, print_detail=True)
def list_gen_time_test():
l = [i for i in range(1000000)]
return l
@repeat_timeit(repeat=3, number=5, print_detail=True)
def list_extend_time_test():
l = []
for i in range(1000000):
l.extend([i])
@repeat_timeit(repeat=3, number=5, print_detail=True, print_table=True)
def list_range_time_test():
l = list(range(1000000))
运行
>> list_insert_time_test()
Function list_insert_time_test -> 5 function calls: average takes 0.097 seconds
>> list_append_time_test()
Function list_append_time_test -> 3 trials with 5 function calls per trial: average trial 3.269 seconds. average function call 0.654 seconds
>> list_gen_time_test()
Time Spend of 5 function calls:
Function -> list_gen_time_test: total 1.550 seconds, average 0.310 seconds
Average: 0.310 seconds
>> list_extend_time_test()
Time Spend of 3 trials with 5 function calls per trial:
Function -> list_extend_time_test:
best: 3.289 seconds, worst: 3.626 seconds, average: 3.442 seconds
Average trial: 3.442 seconds. Average function call: 0.688 seconds
>> list_range_time_test()
Time Spend of 3 trials with 5 function calls per trial:
+----------------------+---------------+---------------+---------------+-----------------------+
| Function | Best trial | Worst trial | Average trial | Average function call |
+----------------------+---------------+---------------+---------------+-----------------------+
| list_range_time_test | 0.640 seconds | 0.714 seconds | 0.677 seconds | 0.135 seconds |
+----------------------+---------------+---------------+---------------+-----------------------+
示例4:构建列表效率对比
from zyf.timer import repeat_timeit
@repeat_timeit(number=3)
def list_insert_time_test():
l = []
for i in range(100000):
l.insert(0, i)
@repeat_timeit(number=5)
def list_extend_time_test():
l = []
for i in range(100000):
l.extend([i])
@repeat_timeit(number=5)
def list_append_time_test():
l = []
for i in range(100000):
l.append(i)
return l
@repeat_timeit(number=5)
def list_gen_time_test():
l = [i for i in range(100000)]
return l
@repeat_timeit(number=5)
def list_range_time_test():
l = list(range(100000))
if __name__ == '__main__':
list_range_time_test()
list_gen_time_test()
list_append_time_test()
list_extend_time_test()
list_insert_time_test()
运行结果
Function list_range_time_test -> 5 function calls: average takes 0.012 seconds
Function list_gen_time_test -> 5 function calls: average takes 0.017 seconds
Function list_append_time_test -> 5 function calls: average takes 0.038 seconds
Function list_extend_time_test -> 5 function calls: average takes 0.067 seconds
Function list_insert_time_test -> 3 function calls: average takes 13.747 seconds
请求头
user_agent
功能说明
支持获取各类请求头,包含移动端和PC端浏览器,可以指定获取某类请求头,也可以随机获取。
使用示例
from zyf.user_agent import UserAgent
ua = UserAgent()
print(ua.random)
print(ua.chrome)
print(ua.firefox)
print(ua.opera)
print(ua.uc)
print(ua.mobile)
输出
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3
Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6
Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10
Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; en) Opera 9.50
Openwave/ UCWEB7.0.2.37/28/999
Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5
文件操作
scan_directory_contents
功能说明
扫描指定文件夹内所有文件,输出文件路径
使用示例
from zyf.file import scan_directory_contents
for file in scan_directory_contents('D:/python/data'):
print(file)
# 可以指定后缀
for file in scan_directory_contents('D:/python/data', suffix='.csv'):
print(file)
count_word_freq
功能说明
对
文献.xlsx中关键词列的进行词频统计,可指定单词分隔符,默认为`; ',也可指定输出词频统计列名,默认为freq和word。
使用示例
from zyf.file import count_word_freq
count_word_freq('文献.xlsx', col_name='关键词', sep='; ', to_col_freq='频数', to_col_word='单词', to_file='文献_关键词_统计.xlsx')
颜色相关
color
功能说明
打印功能扩展,添加颜色输出
使用示例
from zyf.color import print_color, Foreground
print_color("这是什么颜色", foreground=Foreground.Red)
print_color("这是什么颜色", foreground=Foreground.White)
print_color("这是什么颜色", foreground=Foreground.Green)
print_color("这是什么颜色", foreground=Foreground.Black)
print_color("这是什么颜色", foreground=Foreground.Blue)
print_color("这是什么颜色", foreground=Foreground.Cyan)
print_color("这是什么颜色", foreground=Foreground.Purplish_red)
print_color("这是什么颜色", foreground=Foreground.Yellow)
数据下载
政策数据下载
根据关键词对政策数据库进行搜索,并将搜索到的政策数据进行下载及字段解析,存储到文件中。
使用说明
国务院政策文件库
1. 设置settings中的请求参数 -> gov_policy_params
2. 运行代码
北大法宝
1. 网页登陆之后将cookie复制,修改settings中的cookie信息
2. 根据你的检索词和检索时间修改settings中的QueryBased64Request和Year
3. 运行代码
律商网
1. 网页登陆之后将cookie复制,修改settings中的cookie信息
2. 根据你的检索信息修改settings中的keyword/start/end/page_size
3. 运行代码
注:北大法宝和律商网需要有会员账号才能全部完整政策信息, 所以需要设置cookie信息。
使用示例
-
国务院政策数据下载
def gov_policy_demo(): from zyf.crawler.policy.goverment_policy import GovPolicyCrawler spider = GovPolicyCrawler() spider.run(keyword='疫情', issue_depart=['国务院', '国务院部门', '国务院公报'], page_size=50)
-
北大法宝政策数据下载
def pkulaw_policy_demo(): from zyf.crawler.policy.pkulaw_policy import PkulawdCrawler pkulaw_request_params = { 'cookie': None, 'query_base64_request': { '疫情': 'eyJGaWVsZE5hbWUiOm51bGwsIlZhbHVlIjpudWxsLCJSdWxlVHlwZSI6NCwiTWFueVZhbHVlU3BsaXQiOiJcdTAwMDAiLCJXb3JkTWF0Y2hUeXBlIjowLCJXb3JkUmF0ZSI6MCwiQ29tYmluYXRpb25UeXBlIjoyLCJDaGlsZE5vZGVzIjpbeyJGaWVsZE5hbWUiOiJLZXl3b3JkU2VhcmNoVHJlZSIsIlZhbHVlIjpudWxsLCJSdWxlVHlwZSI6NCwiTWFueVZhbHVlU3BsaXQiOiJcdTAwMDAiLCJXb3JkTWF0Y2hUeXBlIjowLCJXb3JkUmF0ZSI6MCwiQ29tYmluYXRpb25UeXBlIjoxLCJDaGlsZE5vZGVzIjpbeyJGaWVsZE5hbWUiOiJDaGVja0Z1bGxUZXh0IiwiVmFsdWUiOiLnlqvmg4UiLCJSdWxlVHlwZSI6NCwiTWFueVZhbHVlU3BsaXQiOiJcdTAwMDAiLCJXb3JkTWF0Y2hUeXBlIjoxLCJXb3JkUmF0ZSI6MCwiQ29tYmluYXRpb25UeXBlIjoyLCJDaGlsZE5vZGVzIjpbXSwiQW5hbHl6ZXIiOiJpa19zbWFydCIsIkJvb3N0IjoiMC4xIiwiTWluaW11bV9zaG91bGRfbWF0Y2giOm51bGx9LHsiRmllbGROYW1lIjoiU291cmNlQ2hlY2tGdWxsVGV4dCIsIlZhbHVlIjoi55ar5oOFIiwiUnVsZVR5cGUiOjQsIk1hbnlWYWx1ZVNwbGl0IjoiXHUwMDAwIiwiV29yZE1hdGNoVHlwZSI6MSwiV29yZFJhdGUiOjAsIkNvbWJpbmF0aW9uVHlwZSI6MiwiQ2hpbGROb2RlcyI6W10sIkFuYWx5emVyIjpudWxsLCJCb29zdCI6bnVsbCwiTWluaW11bV9zaG91bGRfbWF0Y2giOm51bGx9XSwiQW5hbHl6ZXIiOm51bGwsIkJvb3N0IjpudWxsLCJNaW5pbXVtX3Nob3VsZF9tYXRjaCI6bnVsbH1dLCJBbmFseXplciI6bnVsbCwiQm9vc3QiOm51bGwsIk1pbmltdW1fc2hvdWxkX21hdGNoIjpudWxsfQ==', }, 'year': [2003, 2004], 'page_size': 100, } crawler = PkulawdCrawler(**pkulaw_request_params) crawler.run()
-
律商网政策数据下载
def lexis_policy_demo(): from zyf.crawler.policy.lexis_policy import LexisNexisCrawler lexis_request_params = { 'cookie': None, 'keywords': '疫情', 'start': '2020-01-01', 'end': '2020-12-31', 'page_size': 100, } crawler = LexisNexisCrawler(**lexis_request_params) crawler.run()
-
综合示例
配置文件:settings.py
# 国务院 gov_policy_params = { 'keyword': '医疗联合体', 'min_time': None, 'max_time': None, 'issue_depart': ['国务院', '国务院部门', '国务院公报'], 'searchfield': 'title:content:summary', 'sort': 'pubtime', 'page_size': 50, 'to_file': None } # 北大法宝 pkulaw_request_params = { 'cookie': None, 'query_base64_request': { '疫情': 'eyJGaWVsZE5hbWUiOm51bGwsIlZhbHVlIjpudWxsLCJSdWxlVHlwZSI6NCwiTWFueVZhbHVlU3BsaXQiOiJcdTAwMDAiLCJXb3JkTWF0Y2hUeXBlIjowLCJXb3JkUmF0ZSI6MCwiQ29tYmluYXRpb25UeXBlIjoyLCJDaGlsZE5vZGVzIjpbeyJGaWVsZE5hbWUiOiJLZXl3b3JkU2VhcmNoVHJlZSIsIlZhbHVlIjpudWxsLCJSdWxlVHlwZSI6NCwiTWFueVZhbHVlU3BsaXQiOiJcdTAwMDAiLCJXb3JkTWF0Y2hUeXBlIjowLCJXb3JkUmF0ZSI6MCwiQ29tYmluYXRpb25UeXBlIjoxLCJDaGlsZE5vZGVzIjpbeyJGaWVsZE5hbWUiOiJDaGVja0Z1bGxUZXh0IiwiVmFsdWUiOiLnlqvmg4UiLCJSdWxlVHlwZSI6NCwiTWFueVZhbHVlU3BsaXQiOiJcdTAwMDAiLCJXb3JkTWF0Y2hUeXBlIjoxLCJXb3JkUmF0ZSI6MCwiQ29tYmluYXRpb25UeXBlIjoyLCJDaGlsZE5vZGVzIjpbXSwiQW5hbHl6ZXIiOiJpa19zbWFydCIsIkJvb3N0IjoiMC4xIiwiTWluaW11bV9zaG91bGRfbWF0Y2giOm51bGx9LHsiRmllbGROYW1lIjoiU291cmNlQ2hlY2tGdWxsVGV4dCIsIlZhbHVlIjoi55ar5oOFIiwiUnVsZVR5cGUiOjQsIk1hbnlWYWx1ZVNwbGl0IjoiXHUwMDAwIiwiV29yZE1hdGNoVHlwZSI6MSwiV29yZFJhdGUiOjAsIkNvbWJpbmF0aW9uVHlwZSI6MiwiQ2hpbGROb2RlcyI6W10sIkFuYWx5emVyIjpudWxsLCJCb29zdCI6bnVsbCwiTWluaW11bV9zaG91bGRfbWF0Y2giOm51bGx9XSwiQW5hbHl6ZXIiOm51bGwsIkJvb3N0IjpudWxsLCJNaW5pbXVtX3Nob3VsZF9tYXRjaCI6bnVsbH1dLCJBbmFseXplciI6bnVsbCwiQm9vc3QiOm51bGwsIk1pbmltdW1fc2hvdWxkX21hdGNoIjpudWxsfQ==', }, 'year': [2003, 2004], 'page_size': 100, } # 律商网 lexis_request_params = { 'cookie': None, 'keywords': '疫情', 'start': '2020-01-01', 'end': '2020-12-31', 'page_size': 100, }
使用示例
import settings def policy_spider(): print('请选择政策来源: 1. 国务院政策文件库 2.北大法宝 3.律商网 4. 新冠疫情数据(卫健委)') choice = input('请选择政策来源(数字)>> ') if choice == '1': from zyf.crawler.policy.goverment_policy import GovPolicyCrawler crawler = GovPolicyCrawler() crawler.run(**settings.gov_policy_params) elif choice == '2': from zyf.crawler.policy.pkulaw_policy import PkulawdCrawler crawler = PkulawdCrawler(**settings.pkulaw_request_params) crawler.run() elif choice == '3': from zyf.crawler.policy.lexis_policy import LexisNexisCrawler crawler = LexisNexisCrawler(**settings.lexis_request_params) crawler.run() else: raise Exception('输入的政策来源不正确')
图片下载
使用说明
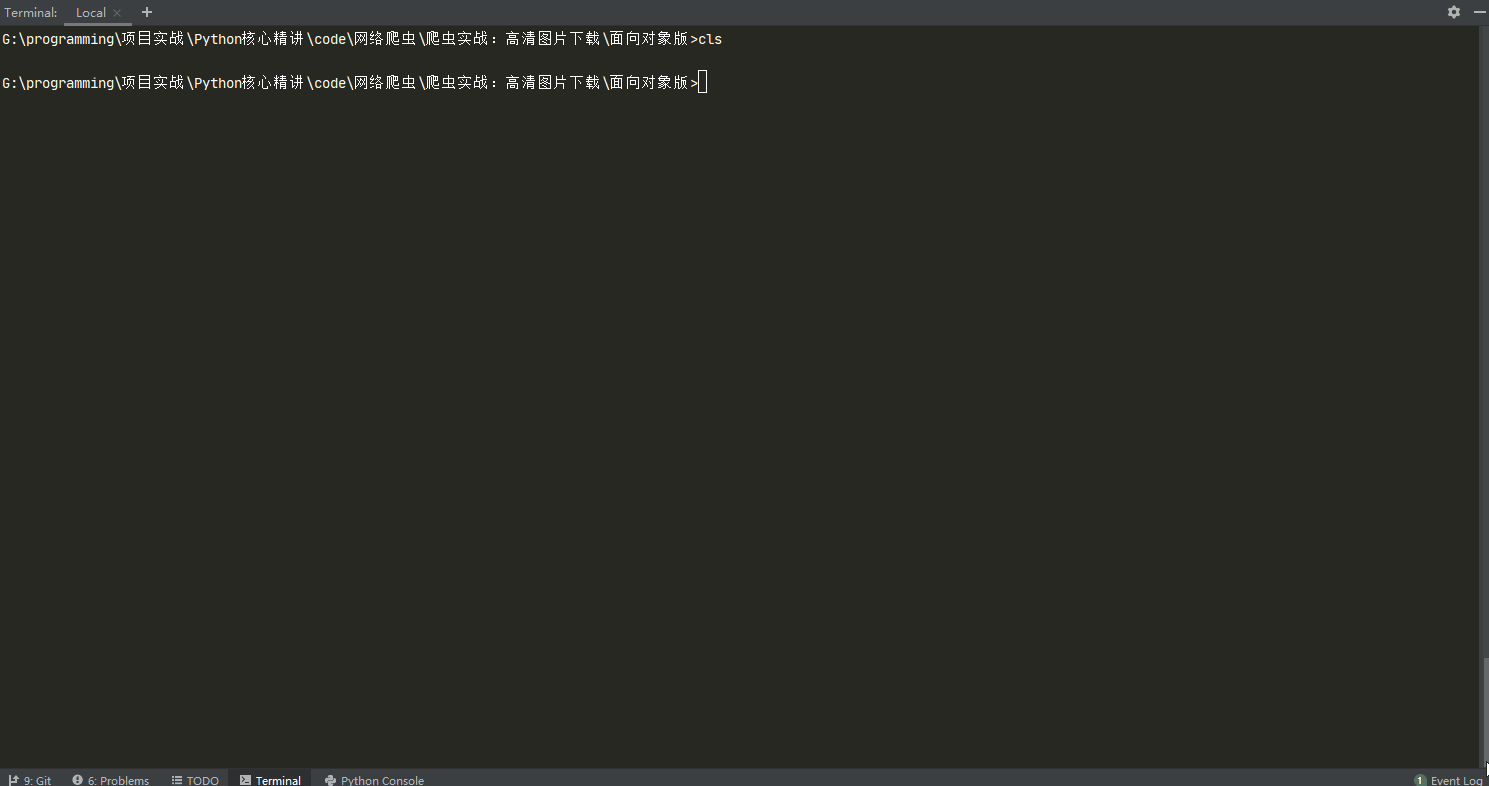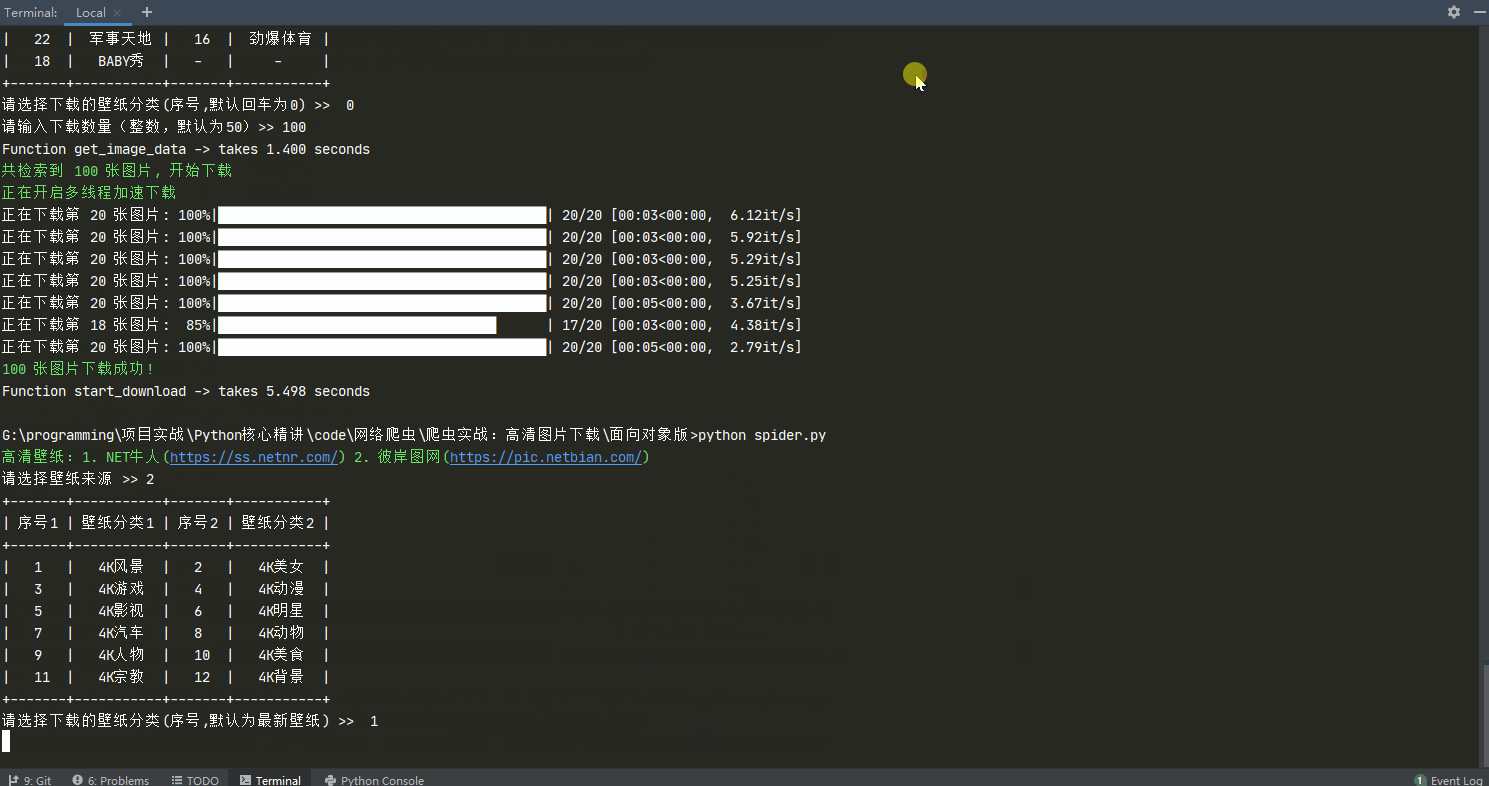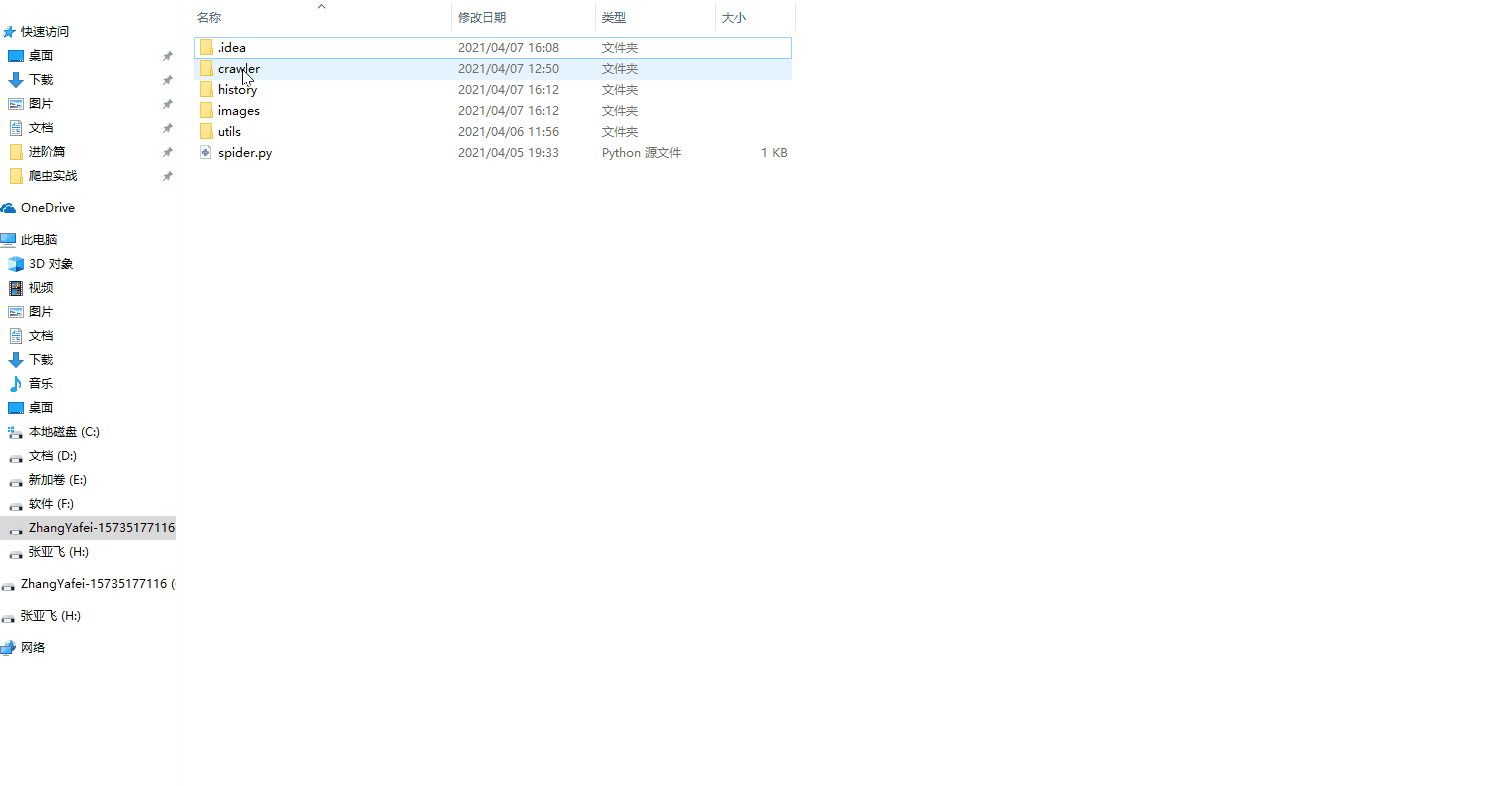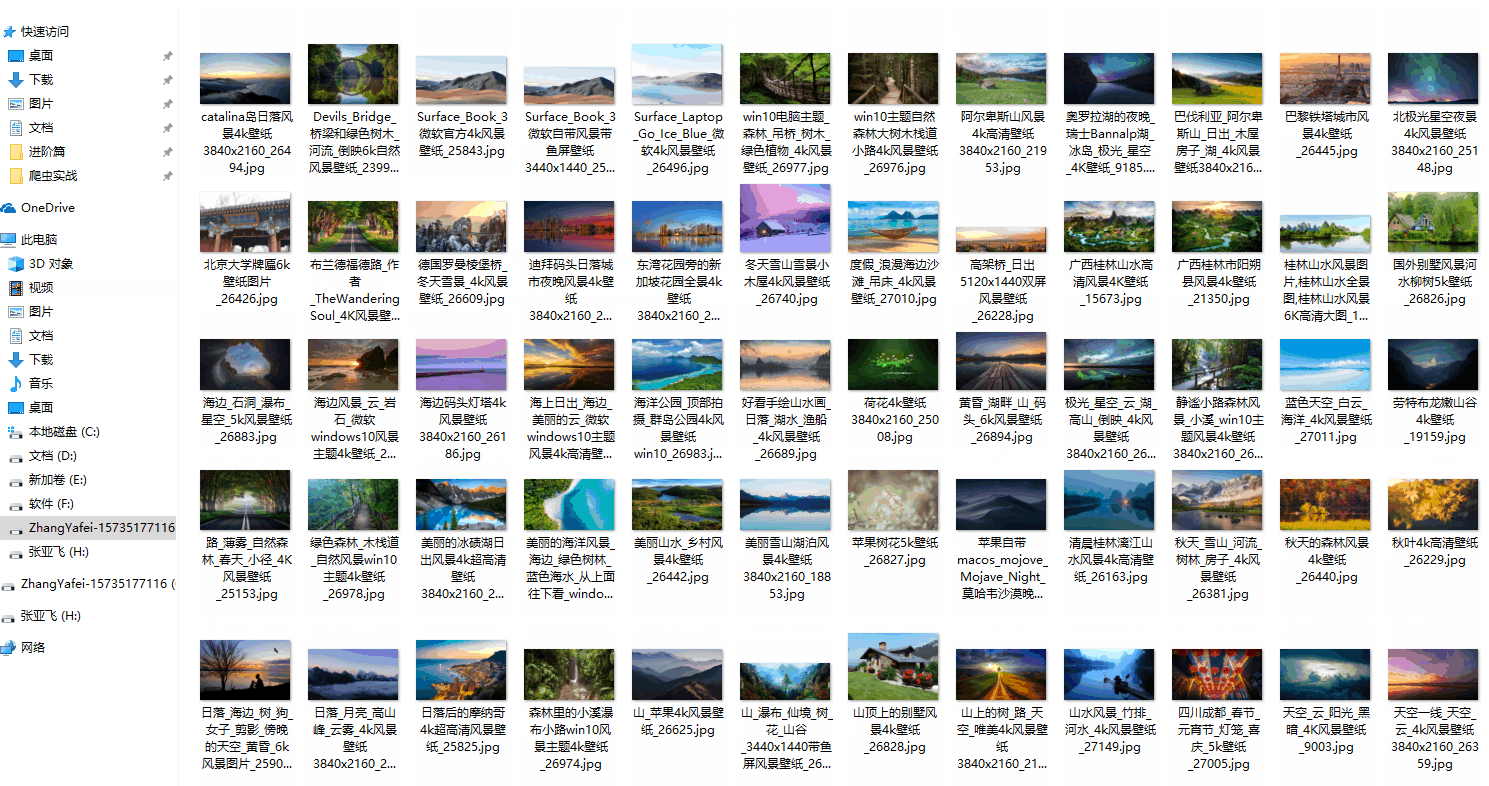
使用示例
from zyf.color import print_color
def start_spider():
print_color('高清壁纸:1. NET牛人(https://ss.netnr.com/) 2. 彼岸图网(https://pic.netbian.com/)')
choice = input('请选择壁纸来源 >> ')
if choice == '1':
from zyf.crawler.image.netnr import NetnrCrawler
crawler = NetnrCrawler(dir_path='images/netnr')
elif choice == '2':
from zyf.crawler.image.netbian import NetbianCrawler
crawler = NetbianCrawler(dir_path='images/netbian')
else:
raise Exception('输入的壁纸来源不正确')
crawler.run()
if __name__ == '__main__':
start_spider()
数据库连接
DBPoolHelper
使用说明
提供sqlite3、mysql、postgresql、sqkserver连接池,方便操作,该功能使用依赖于dbutils,需要提前安装,另外,需要安装对应数据库的第三方依赖
postgressql -> psycopg2
mysql -> pymysql
sqlite -> sqlite3
使用示例
from zyf.db import DBPoolHelper
db1 = DBPoolHelper(db_type='postgressql', dbname='student', user='postgres', password='0000', host='localhost', port=5432)
db2 = DBPoolHelper(db_type='mysql', dbname='student', user='root', password='0000', host='localhost', port=3306)
db3 = DBPoolHelper(db_type='sqlite3', dbname='student.db')
MongoHelper
使用说明
为mongodb操作提供便利,需要安装pymongo
使用示例
from zyf.db import MongoHelper
mongo = MongoHelper(mongo_db='flask', mongo_uri='localhost')
data = mongo.read('label')
print(data.head())
condition = {"药品ID": 509881}
data = mongo.dbFind('label', condition)
print(data)
for i in data:
print(i)
for item in mongo.findAll():
print(item)
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file zyf-1.1.tar.gz.
File metadata
- Download URL: zyf-1.1.tar.gz
- Upload date:
- Size: 30.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.8.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b9d1fd5b9ae38a9e19e884b985805bfce6042749d15467a1fd7ca9c460bf3e76
|
|
| MD5 |
cf237460d08080f1e8d9ceac933a98f3
|
|
| BLAKE2b-256 |
e2c0bdfd607771430779c25a026f3bc0e4d21ba60676effc7b612d8573285ba3
|
File details
Details for the file zyf-1.1-py3-none-any.whl.
File metadata
- Download URL: zyf-1.1-py3-none-any.whl
- Upload date:
- Size: 34.2 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.8.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6a6b649b4f21d5bd274b90e28d51cd70682662928409af90043112574381dc89
|
|
| MD5 |
28cacb952feef80c2081fdf2ac7ae360
|
|
| BLAKE2b-256 |
b1609bb8a78ae7a60a10ad0dfda55d59fd116f65e338897ccdd38a7facaddd8b
|







