Simple Job Queues using SQL

Project description
raquel


Simple and elegant Job Queues for Python using SQL.
Tired of complex job queues for distributed computing or event-based systems? Do you want full visibility and complete reliability of your job queue? Raquel is a perfect solution for a distributed task queue and background workers.
- Simple: Use any existing or standalone SQL database. Requires a single table!
- Flexible: Schedule whatever you want however you want. No frameworks, no restrictions.
- Reliable: Uses SQL transactions and handles exceptions, retries, and "at least once" execution. SQL guarantees persistent jobs.
- Transparent: Full visibility into which jobs are running, which failed and why, which are pending, etc. Query anything using SQL.
Table of contents
Installation
pip install raquel
To install with async support, specify the asyncio extra. This simply
adds the greenlet package as a dependency.
pip install raquel[asyncio]
Usage
Schedule jobs
In order for the job to be scheduled it needs to be added to the jobs table
in the database. As long as it has the right status and timestamp, it will be
picked up by the workers.
Jobs can be scheduled using the library or by inserting a row into the jobs
table directly.
Using enqueue()
The easiest way to schedule a job is using the enqueue() method. By default,
the job is scheduled for immediate execution.
from raquel import Raquel
# Raquel uses SQLAlchemy to connect to most SQL databases. You can pass
# a connection string or a SQLAlchemy engine.
rq = Raquel("postgresql+psycopg2://postgres:postgres@localhost/postgres")
# Enqueing a job is as simple as this
rq.enqueue(queue="messages", payload="Hello, World!")
rq.enqueue(queue="tasks", payload={"data": [1, 2]})
Payload can be any JSON-serializable object or simply a string. It can even be empty. In database, the payload is stored as UTF-8 encoded text for maximum compatibility with all SQL databases, so anything that can be serialized to text can be used as a payload.
By default, jobs end up in the "default" queue. Use the queue parameter
to place jobs into different queues.
Using SQL insert
We can also schedule jobs using plain SQL by simply inserting a row into the
jobs table. For example, in PostgreSQL:
-- Schedule 3 jobs in the "my-jobs" queue for immediate processing
INSERT INTO jobs
(id, queue, status, payload)
VALUES
(uuid_generate_v4(), 'my-jobs', 'queued', '{"my": "payload"}'),
(uuid_generate_v4(), 'my-jobs', 'queued', '101'),
(uuid_generate_v4(), 'my-jobs', 'queued', 'Is this the real life?');
Pick up jobs
While you can manually claim, process, and update the job, you'd also need to handle exceptions, retries and other edge cases. The library provides convenient ways to do this.
Using dequeue()
The dequeue() method is a context manager that yields a Job object for you
to work with. If there is no job to process, it will yield None instead.
while True:
with rq.dequeue("tasks") as job:
if job:
do_work(job.payload)
else:
time.sleep(1)
The dequeue() will find the next job and claim it. It will also handle
the job status, exceptions, retries and everything else automatically.
Failed jobs
Jobs are retried when they fail. When an exception is caught by the
dequeue() context manager, the job is rescheduled with an exponential
backoff delay.
By default, the job will be retried indefinitely. You can set the
max_retry_count or max_age fields to limit the number of retries or the
maximum age of the job.
with rq.dequeue("my-queue") as job:
# Let the context manager handle the exception for you.
# The exception will be caught and the job will be retried.
# Under the hood, context manager will call `job.fail()` for you.
raise Exception("Oh no")
do_work(job.payload)
You can always handle the exception manually:
with rq.dequeue("my-queue") as job:
# Catch an exception manually
try:
do_work(job.payload)
except Exception as e:
# If you mark the job as failed, it will be retried.
job.fail(str(e))
Whenever job fails, the error and the traceback are stored in the error and
error_trace columns. The job status is set to failed and the job will
be retried. The attempt number is incremented.
Reschedule jobs
The reschedule() method is used to reprocess the job at a later time.
The job will remain in the queue with a new scheduled execution time, and the
current attempt won't count towards the maximum number of retries.
This method should only be called inside the dequeue() context manager.
with rq.dequeue("my-queue") as job:
# Check if we have everything ready to process the job, and if not,
# reschedule the job to run 10 minutes from now
if not is_everything_ready_to_process(job.payload):
job.reschedule(delay=timedelta(minutes=10))
else:
# Otherwise, process the job
do_work(job.payload)
When you reschedule a job, its scheduled_at field is either updated with
the new at and delay values or left unchanged. And the finished_at field
is cleared. If the Job object had any error or error_trace values, they
are saved to the database. The attempts field is incremented.
Here are some fancy ways to reschedule a job using reschedule():
# Run when the next day starts
with rq.dequeue("my-queue") as job:
job.reschedule(
at=datetime.now().replace(
hour=0, minute=0, second=0, microsecond=0,
) + timedelta(days=1)
)
# Same but using the `delay` parameter
with rq.dequeue("my-queue") as job:
job.reschedule(
at=datetime.now().replace(hour=0, minute=0, second=0, microsecond=0),
delta=timedelta(days=1),
)
# Run in 500 milliseconds
with rq.dequeue("my-queue") as job:
job.reschedule(delay=500)
# Run in `min_retry_delay` milliseconds, as configured for this job
# (default is 1 second)
with rq.dequeue("my-queue") as job:
job.reschedule()
Reject jobs
In case your worker can't process the job for some reason, you can reject it, allowing it to be immediately claimed by another worker.
This method should only be called inside the dequeue() context manager.
It is very similar to rescheduling the job to run immediately. When you reject
the job, the scheduled_at field is left unchanged, but the claimed_at and
claimed_by fields are cleared. The job status is set to queued. And the
attempts field is incremented.
with rq.dequeue("my-queue") as job:
if job.payload.get("requires_admin"):
# Reject the job if the worker can't process it.
job.reject()
else:
# Otherwise, process the job
do_work(job.payload)
Async support
Everything in Raquel is designed to work with both sync and async code.
You can use the AsyncRaquel class to enqueue and dequeue jobs in an async
manner.
Just don't forget the asyncio extra when installing the package:
raquel[asyncio].
import asyncio
from raquel import AsyncRaquel
rq = AsyncRaquel("postgresql+asyncpg://postgres:postgres@localhost/postgres")
async def main():
await rq.enqueue("tasks", {'my': {'name_is': 'Slim Shady'}})
asyncio.run(main())
In async mode, the dequeue() context manager works the same way:
async def main():
async with rq.dequeue("tasks") as job:
if job:
await do_work(job.payload)
else:
await asyncio.sleep(1)
asyncio.run(main())
Stats
-
List of queues
>>> rq.queues() ['default', 'tasks']
SELECT queue FROM jobs GROUP BY queue
-
Number of jobs per queue
>>> rq.count("default") 10
SELECT queue, COUNT(*) FROM jobs WHERE queue = 'default' GROUP BY queue
-
Number of jobs per status
>>> rq.stats() {'default': QueueStats(name='default', total=10, queued=10, claimed=0, success=0, failed=0, expired=0, exhausted=0, cancelled=0)}
SELECT queue, status, COUNT(*) FROM jobs GROUP BY queue, status
-
Failed jobs
Note that the
failedjobs are still going to be picked up and reprocessed until they are marked assuccess,exhausted,expired, orcancelled.>>> rq.count("default", rq.FAILED) 5
SELECT * FROM jobs WHERE queue = 'default' AND status = 'failed'
-
Pending jobs, ready to be picked up by a worker
>>> rq.count("default", [rq.QUEUED, rq.FAILED]) 5
SELECT * FROM jobs WHERE queue = 'default' AND status IN ('queued', 'failed')
-
Claimed jobs that are currently being processed by a worker
>>> rq.count("default", rq.CLAIMED) 5
SELECT * FROM jobs WHERE queue = 'default' AND status = 'claimed'
-
Rescheduled jobs
You can find all rescheduled jobs using SQL by filtering for those that are queued, but have attempts and were claimed before.
SELECT * FROM jobs WHERE status = 'queued' AND attempts > 0 AND claimed_at IS NOT NULL
-
Rejected jobs
SELECT * FROM jobs WHERE status = 'queued' AND attempts > 0 AND claimed_at IS NULL
How it works
Jobs table
Raquel uses a single database table called jobs.
This is all it needs. Can you believe it?
Here is the schema of the jobs table:
| Column | Type | Description | Default | Nullable |
|---|---|---|---|---|
| id | UUID | Unique identifier of the job. | No | |
| queue | TEXT | Name of the queue. | "default" |
No |
| payload | TEXT | Payload of the job. It can be anything. Just needs to be serializable to text. | Null | Yes |
| status | TEXT | Status of the job. | "queued" |
No |
| max_age | INTEGER | Maximum age of the job in milliseconds. | Null | Yes |
| max_retry_count | INTEGER | Maximum number of retries. | Null | Yes |
| min_retry_delay | INTEGER | Minimum delay between retries in milliseconds. | 1000 |
Yes |
| max_retry_delay | INTEGER | Maximum delay between retries in milliseconds. | 12 * 3600 * 1000 |
Yes |
| backoff_base | INTEGER | Base in milliseconds for exponential retry backoff. | 1000 |
Yes |
| enqueued_at | BIGINT | Time when the job was enqueued in milliseconds since epoch (UTC). | now |
No |
| scheduled_at | BIGINT | Time when the job is scheduled to run in milliseconds since epoch (UTC). | now |
No |
| attempts | INTEGER | Number of attempts to execute the job. | 0 |
No |
| error | TEXT | Error message if the job failed. | Null | Yes |
| error_trace | TEXT | Error traceback if the job failed. | Null | Yes |
| claimed_by | TEXT | ID or name of the worker that claimed the job. | Null | Yes |
| claimed_at | BIGINT | Time when the job was claimed in milliseconds since epoch (UTC). | Null | Yes |
| finished_at | BIGINT | Time when the job was finished in milliseconds since epoch (UTC). | Null | Yes |
Check out all ways to create the jobs table in the
Create jobs table section.
Job status
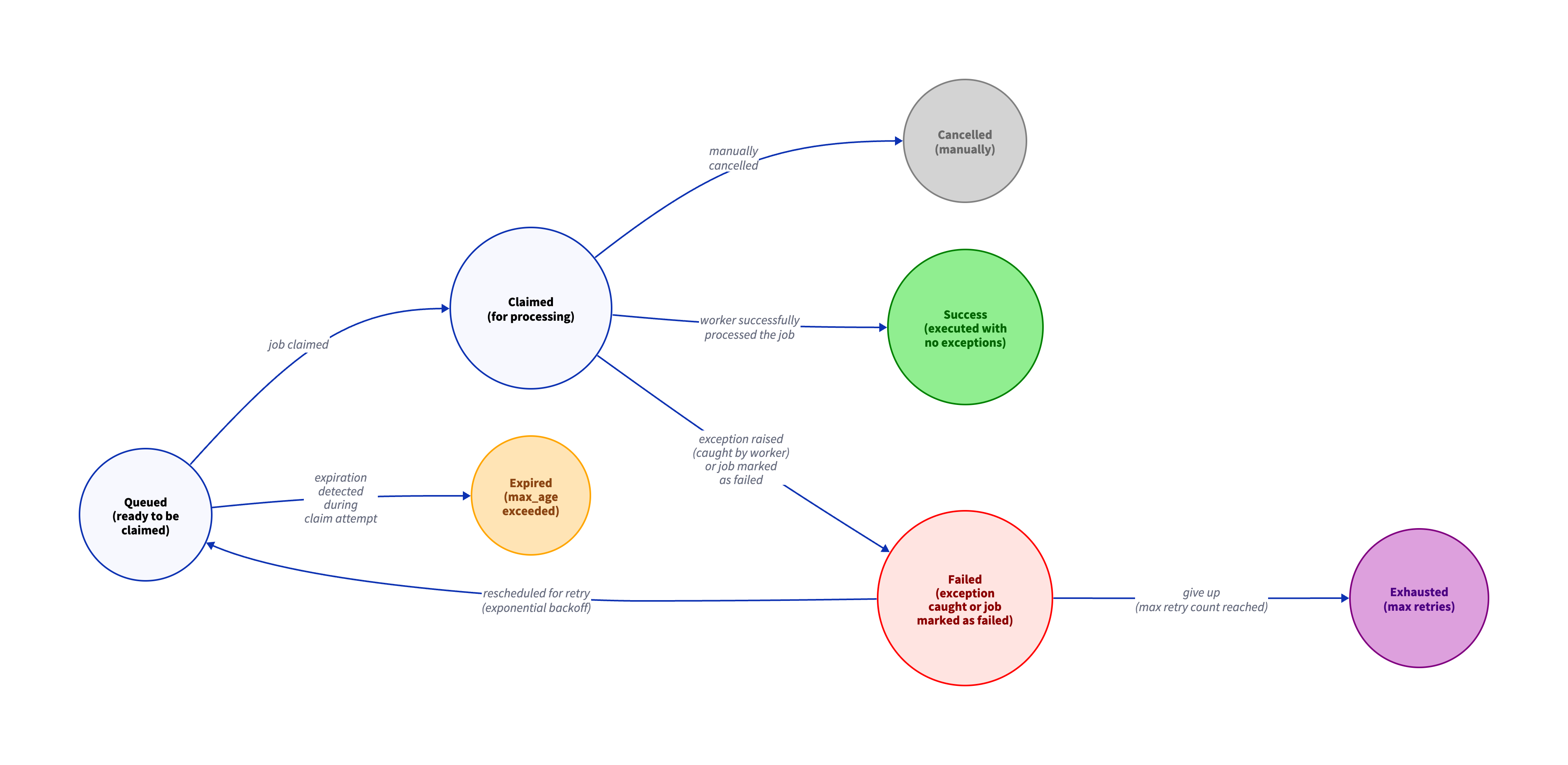
Jobs can have the following statuses:
queued- Job is waiting to be picked up by a worker.claimed- Job is currently locked and is being processed by a worker (in databases such as PostgreSQL, MySQL, etc., once the job is claimed, its row is locked until the worker is done with it).success- Job was successfully executed.failed- Job failed to execute. This happens when an exception was caught by thedequeue()context manager. The last error message and traceback are stored in theerroranderror_tracecolumns. Job will be retried again, meaning it will be rescheduled with an exponential backoff delay.cancelled- Job was manually cancelled.expired- Job was not picked up by a worker in time (whenmax_ageis set).exhausted- Job has reached the maximum number of retries (whenmax_retry_countis set).
The job can be picked up by a worker in either of the following three states:
queued, failed, or claimed.
The first two are most common. The job will be picked up if:
- Job status is
queued(scheduled or rejected) orfailed(failed to be processed and is being retried); - And its
scheduled_attime is in the past; - And its
max_ageis not set or itsscheduled_at + max_ageis in the future.
The job in claimed state is a special case and happens when some worker
marked the job as claimed but failed to process it. In this case the row,
representing the job, is not locked in the database. If more than a minute
passed since the job was claimed (claimed_at + 1 minute) and the row is
not locked (meaning the worker that claimed it is dead), any worker can
reclaim it for itself.
One job per worker
How do we guarantee that the same job is not picked up by multiple workers?
Short answer: by locking the row and using the claimed status.
In PostgreSQL, the SELECT FOR UPDATE SKIP LOCKED statement is used when
selecting the job. This statement locks the row for the duration of the
transaction and allows other workers to see that the row is locked.
In other databases that support this (such as Oracle, MySQL) a similar
approach is used.
In extremely simple databases, such as SQLite, the fact that the whole
database is locked during a write operation guarantees that no other worker
will be able to set the job status to claimed at the same time.
Database transactions
The dequeue() context manager works by making three consecutive and
independent SQL transactions:
-
Transaction 1: Expire old jobs: Looks for jobs whose
max_ageis not null and whosescheduled_at + max_ageis in the past and updates their status toexpired. -
Transaction 2: Claim a job: Selects the next job from the queue and sets its status to
claimed, all in one go. It either succeeds in claiming the job or not. -
Transaction 3: Process a job: Places a database lock on that "claimed" row with the job details for the entire duration of the processing and then updates the job with an appropriate status value:
successif the job is processed successfully and we are done with it.failedif an exception was caught by the context manager or the job was manually marked as failed. The job will be rescheduled for a retry.queuedif the job was manually rejected or manually rescheduled for a later time.cancelledif the job is manually cancelled.exhaustedif the job has reached the maximum number of retries.
All of that happens inside the context manager itself.
Sudden shutdown
If a worker dies while attempting to claim a job, the transaction opened by the worker is rolled back and the row is unlocked by the database. Another worker can claim it and process it.
If a worker dies while processing a job, the row is unlocked by the database
but remains in the claimed status. Another worker can pick it up and
process it.
Retry delay
The next retry time after a failed job is calculated as follows:
- Take the current
scheduled_attime. - Add the time it took to process the job (aka duration).
- Add the retry delay.
The retry delay itself is calculated as follows:
backoff_base * 2 ^ attempt
But this is just a planned retry delay. The actual retry delay is capped
between the min_retry_delay and max_retry_delay values. The min_retry_delay
defaults to 1 second and the max_retry_delay defaults to 12 hours. The
backoff_base defaults to 1 second.
In other words, here is how your job will be retried (assuming there is always a worker available and the job takes almost no time to process):
| Retry | delay |
|---|---|
| 1 | 1 second after 1st attempt |
| 2 | 2 seconds after 2nd attempt |
| 3 | after 4 seconds |
| ... | ... |
| 6 | after ~2 minutes |
| ... | ... |
| 10 | after ~30 minutes |
| ... | ... |
| 14 | after ~9 hours |
| ... | ... |
and so on with the maximum delay of 12 hours, or based on the maximum value
you set for this job using the max_retry_delay setting.
For certain types of jobs, it makes sense to chill out for a bit before
retrying. For example, an API might have a rate limit you've just hit or
some data might not be ready yet. In such cases, you can set the
min_retry_delay to a higher value, such as 10 or 30 seconds.
All durations and timestamps are in milliseconds. So 10 seconds is
10 * 1000 = 10000 milliseconds. 1 minute is 60 * 1000 = 60000
milliseconds.
Create jobs table
Using create_all()
You can configure the table using the create_all() method, which will
automatically use the supported syntax for the database you are using (it is
safe to run it multiple times, it only creates the table once.).
# Works for all databases
rq.create_all()
Using SQL create table
Alternatively, the jobs table can be created manually using SQL.
For Postgres you can use
this example.
Using Alembic migrations
Autogenerate migration
If you are using Alembic, the only thing you need to do is to import
Raquel's metadata object and add it as a target inside the
context.configure() calls in Alembic's env.py file.
# Alembic's env.py configuration file
# Import Raquel's base metadata object
from raquel.models.base_sql import BaseSQL as RaquelBaseSQL
# This code already exists in the Alembic configuration file
def run_migrations_offline() -> None:
# ...
context.configure(
# ...
target_metadata=[
target_metadata,
# Add Raquel's metadata
RaquelBaseSQL.metadata,
],
# ...
)
# Same for online migrations
def run_migrations_online() -> None:
# ...
context.configure(
# ...
target_metadata=[
target_metadata,
# Add Raquel's metadata
RaquelBaseSQL.metadata,
],
# ...
)
You only need to do this once. The first time you auto-generate a migration after that, Alembic will automatically create a proper migration for you.
alembic revision --autogenerate -m "raquel"
If Raquel is ever updated to add new columns or indexes, you can always upgrade the Raquel package and generate a follow-up migration that will add the new changes.
Currently, there are no plans to change the schema of the jobs table. Any
new changes are expected to be backward compatible.
Manual migration
If you are writing Alembic migrations manually, you can use the example of one written for the current version of Raquel.
Production ready
Can you trust Raquel with your production? Yes, you can! Here is why:
-
Raquel is dead simple.
You can rewrite the whole library in any programming language using plain SQL in about a day. We keep the code simple and maintainable.
-
It's reliable.
The jobs are stored in a relational database and exclusive row locks and rollbacks are handled through ACID transactions.
-
Already used in production by several companies.
-
Licensed under the Apache 2.0 license.
You can use it in any project or fork it and do whatever you want with it.
-
Actively maintained.
The library is actively maintained by Vagiz Duseev. who is also the author of some other popular Python packages such as opensearch-logger.
-
Platform and database agnostic.
Save yourself the pain of migrating between database vendors or versions. All timestamps are stored as milliseconds since epoch (UTC timezone). Payloads are stored as text. Job IDs are random UUIDs to allow migration between databases and HA setups.
Fun facts
- Raquel is named after the famous actress Raquel Welch. Many years ago, I used to attend a local gym, where there was a shrine dedicated to Arnold Schwarznegger. Posters, memorabilia, and a small statue of him. Apparently, Welch was once considered as Schwarznegger's costar for the movie "Conan the Barbarian". The gym owner liked this alternative casting so much that he hanged a poster from the "One Million Years B.C." with her right beside the statue of Arnold. I didn't watch either of these movies and only found out they were never in the same film together when I sat down to write this library.
- The name Raquel is also a play on the words "queue" and "SQL".
- The library exists because solutions like Celery and Dramatiq are too complex for small scale projects, too opinionated, unpredicatable, and opaque.
Contribute
Contributions are welcome 🎉! See CONTRIBUTING.md for details. We follow the Code of Conduct.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file raquel-0.3.2.tar.gz.
File metadata
- Download URL: raquel-0.3.2.tar.gz
- Upload date:
- Size: 393.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.7.8
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a7a86a56c27491d851ea7f98b4dea2756c1ee4b9ff31ee2f713eb73abb87f7e1
|
|
| MD5 |
12fe75196e2a1f70d0164c9cf0163e5a
|
|
| BLAKE2b-256 |
3f56833df45ee6ce0bfc732a11449c0475e1e36beeb4f3122004e76a77ecbe78
|
File details
Details for the file raquel-0.3.2-py3-none-any.whl.
File metadata
- Download URL: raquel-0.3.2-py3-none-any.whl
- Upload date:
- Size: 38.8 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.7.8
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
66762ad52f69cfbfd4b5839b4cc9ad075d3e7cf03db2a26a91e94247455f30e6
|
|
| MD5 |
3a71c127c845d8dad09be0a70bffbca3
|
|
| BLAKE2b-256 |
792ab7a334f9611b428d5c17974618a26e30bac0e9356791e4276e902ea3c657
|







