No project description provided

Project description
AFragmenter
AFragmenter is a schema-free, tunable protein domain segmentation tool for AlphaFold structures based on network analysis.
Key features
-
Schema free: AFragmenter only uses the PAE values from AlphaFold structures. No domain-segmentation scheme is learned or used for evaluation.
-
Tunable segmentation: The 'resolution' parameter gives control over the coarseness of clustering, and thus the number of clusers / domains.
- Higher resolution: Yields more, smaller clusters
- Lower resolution: Yields fewer, larger clusters
| Resolution = 0.8 | Resolution = 1.1 | Resolution = 0.3 |
|---|---|---|
 |
 |
 |
protein: P15807
How it works
-
Network representation: Each protein residue is treated as a node within a fully connected network
-
Edge weighting: The edges between the nodes are weighted using transformed Predicted Aligned Error (PAE) values from AlphaFold, reflecting relative positional confidence between residues.
Details on the use of PAE values
- PAE values show differences when looking between inter- versus intra-domain residue pairs.
- Intra-domain residue paris are expected to have lower PAE values compared to inter-domain residue pair.
- This difference is used to distinguish well-structured regions within a protein structure from other well-structured regions and from poorly structured regions.
- This enables us to cluster protein residue pairs of well-structured regions together.
-
Clustering with Leiden algorithm: Utilizes the Leiden clustering algorithm to group residues into domains, with adjustable resolution parameters to control cluster granularity.
Table of contents
Try it
The recommended way to use AFragmenter is through jupyter notebooks, where visualization and fine-tuning of parameters is most easily done. The easiest way to begin is by using our Google colab notebook.
- Note: While colab notebooks offers convenience, it can experience slower performance due to shared resources.
An alternative way to get started is by using the [webtool] (coming soon)
Installation
System Requirements
- Python Version: Python 3.9 or higher
- Operating Systems: Linux, macOS, or Windows.
Installation
AFragmenter is available through PyPI and bioconda.
pip install afragmenter
or
conda install -c conda-forge -c bioconda afragmenter
Optional Dependencies:
-
py3Dmol: Required for protein structure visualization.
pip install py3Dmol
Or
conda install -c conda-forge py3Dmol
Quick Tutorial
In this short tutorial, we will walk through the process of using AFragmenter to segment protein domains based on AlphaFold structures. We will use the example protein P15807 (PDB: 1KYQ) to demonstrate the steps involved. This protein is classified differently by various protein domain databases, making it an interesting case for domain segmentation.
P15807 is classified as a three-domain protein in both CATH and ECOD, a two-domain protein in SCOPe and InterPro, and a single-domain protein in SCOP.
Since AFragmenter is dependent on the PAE values of AlphaFold, it is a good idea to first have a look at the PAE plot.
from afragmenter import AFragmenter, fetch_afdb_data
pae, structure = fetch_afdb_data('P15807')
p15807 = AFragmenter(pae) # Or bring your own files: a = AFragmenter('filename.json')
p15807.plot_pae()
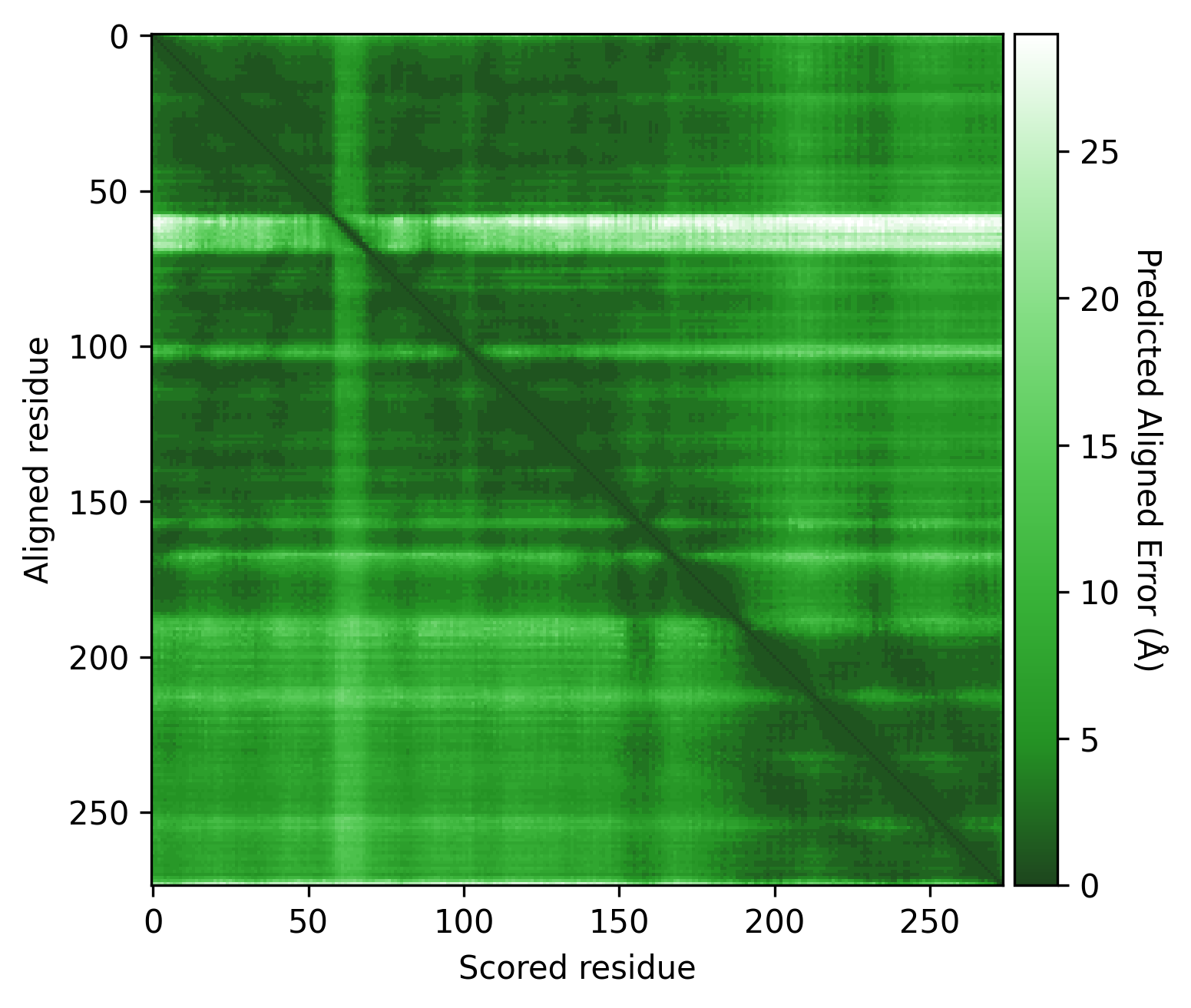
Here we see some regions of very low PAE values (dark green) on the PAE matrix, which could indicate different domains. However, there are still many green (low PAE) datapoints visible around these potential domains. Therefore, it is important to consider the PAE contrast threshold used.
These PAE values are transformed into edge weights to increase the contrast between high and low PAE values. The PAE contrast threshold can be adjusted to control this contrast. Below, we can see the effect of different thresholds on the weights of the graph.
Show code
from afragmenter.plotting import plot_matrix
p15807 = AFragmenter(pae)
fig, ax = plt.subplots(2, 2, figsize=(10, 10))
p15807.plot_pae(ax=ax[0, 0])
plot_matrix(p15807.edge_weights_matrix, ax=ax[0, 1])
p15807 = AFragmenter(pae, threshold=3)
plot_matrix(p15807.edge_weights_matrix, ax=ax[1, 0])
p15807 = AFragmenter(pae, threshold=1)
plot_matrix(p15807.edge_weights_matrix, ax=ax[1, 1])
ax[0, 0].set_title('PAE matrix')
ax[0, 1].set_title('Edge weights matrix (threshold=5)\n[default]')
ax[1, 0].set_title('Edge weights matrix (threshold=3)')
ax[1, 1].set_title('Edge weights matrix (threshold=1)')
plt.tight_layout()
plt.show()
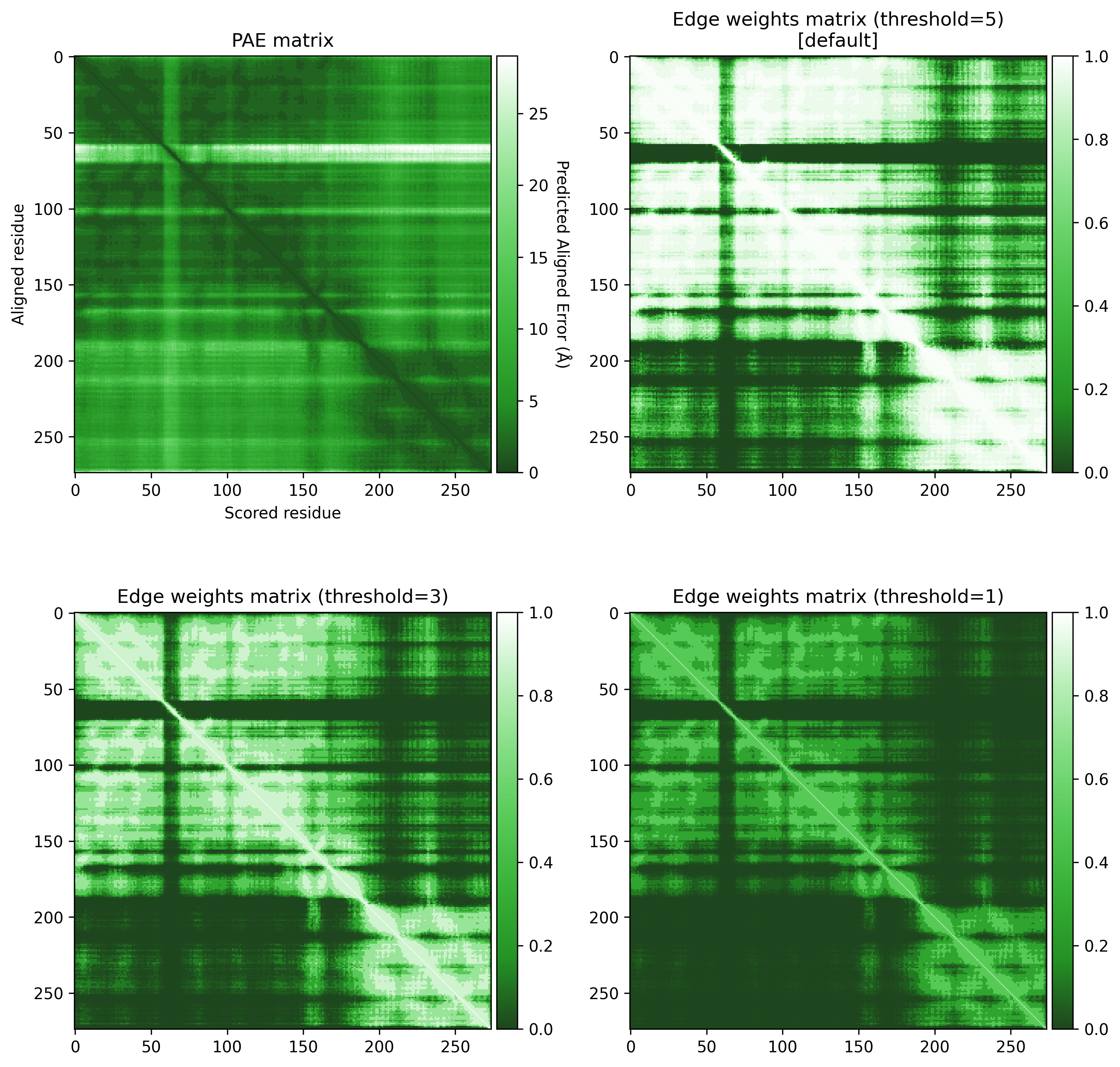
A threshold of 3 seems to give a good contrast between the higher and lower PAE values.
Next, we cluster the residues into domains using the Leiden clustering algorithm. We get a result, but the resolution parameter can be changed to explore multiple potential solutions.
p15807 = AFragmenter(pae, threshold=3)
result = p15807.cluster() # default resolution = 0.8
result.plot_result()
result.py3Dmol(structure)

p15807.cluster(resolution=1.1)

p15807.cluster(resolution=0.3)

Once a solution has been found that is satisfactory to the user, we can print the result and the FASTA file for each domain, or save them to files for further analysis.
p15807 = AFragmenter(pae, threshold=3)
result = p15807.cluster(resolution=1.1)
result.print_result()
┏━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━┓
┃ Domain ┃ Number of Residues ┃ Chopping ┃
┡━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━┩
│ 1 │ 137 │ 10-146 │
│ 2 │ 47 │ 147-193 │
│ 3 │ 81 │ 194-274 │
└────────┴────────────────────┴──────────┘
result.print_fasta(structure)
>P15807_1 10-146
QLKDKKILLIGGGEVGLTRLYKLIPTGCKLTLVSPDLHKSIIPKFGKFIQNEDQPDYRED
AKRFINPNWDPTKNEIYEYIRSDFKDEYLDLEDENDAWYIIMTCIPDHPESARIYHLCKE
RFGKQQLVNVADKPDLC
>P15807_2 147-193
DFYFGANLEIGDRLQILISTNGLSPRFGALVRDEIRNLFTQMGDLAL
>P15807_3 194-274
EDAVVKLGELRRGIRLLAPDDKDVKYRMDWARRCTDLFGIQHCHNIDVKRLLDLFKVMFQ
EQNCSLQFPPRERLLSEYCSS
# Or save it
result.save_result('result.csv')
result.save_fasta(structure, 'result.fasta')
Usage
Python
Docs coming soon...
Command line

Options
Threshold
The 'contrast threshold' serves as a soft cut-off to increase the distinction between low and high PAE values. Used in calculating the edge weights of the network and will thus have a large impact on the clustering and segmentation results. It is important to consider this threshold in the context of the AlphaFold results for the protein of interest.
Examples:
Q5VSL9
Overall good structure with high pLDDt and low PAE scores for the majority of the protein, and lower pLDDT and high PAE scores for the disordered regions / loops, like is expected. Default threshold should be good (default PAE threshold = 5).
| AlphaFold structure | PAE plot | Edge weights |
|---|---|---|
 |
 |
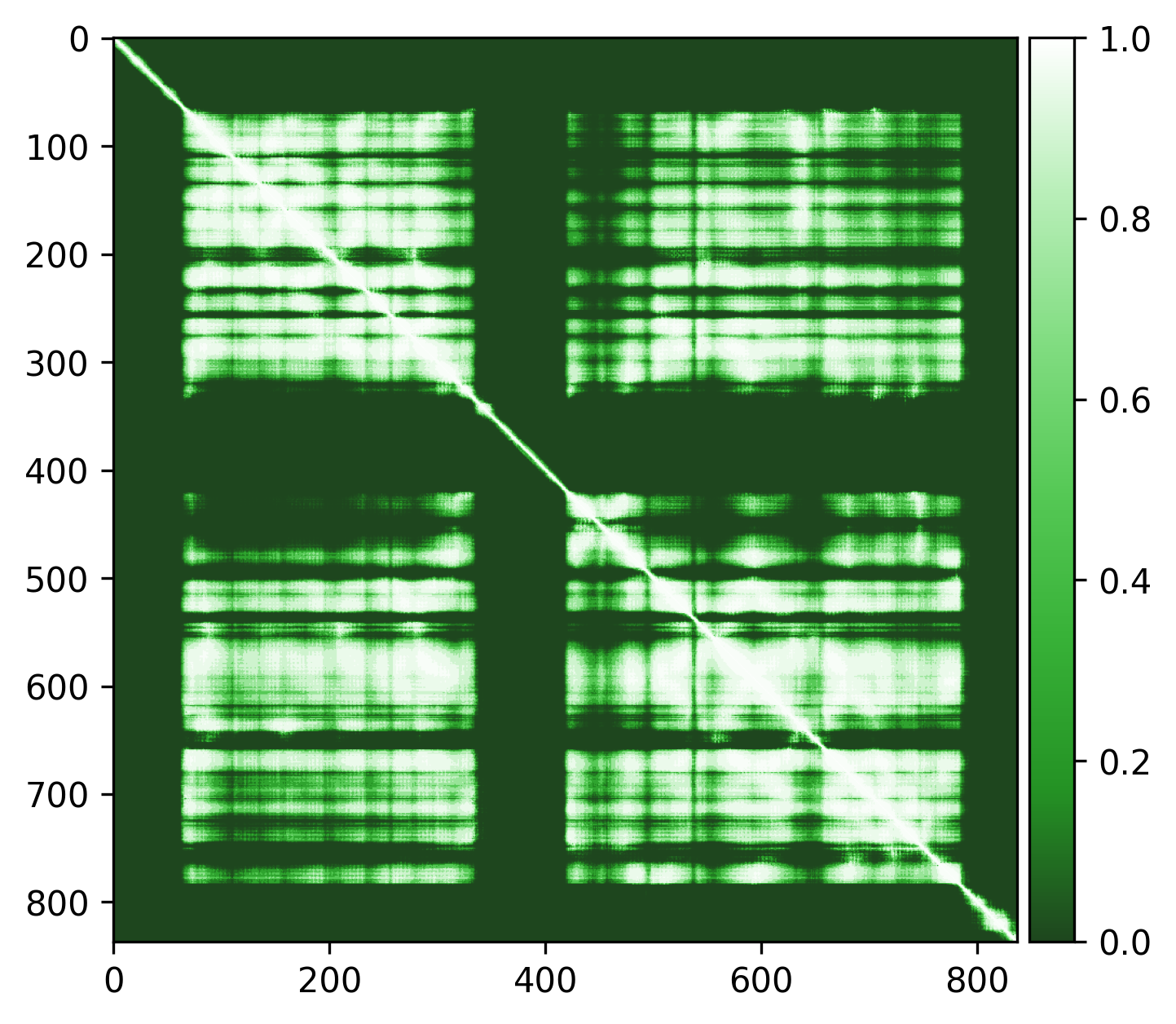 |
P15807
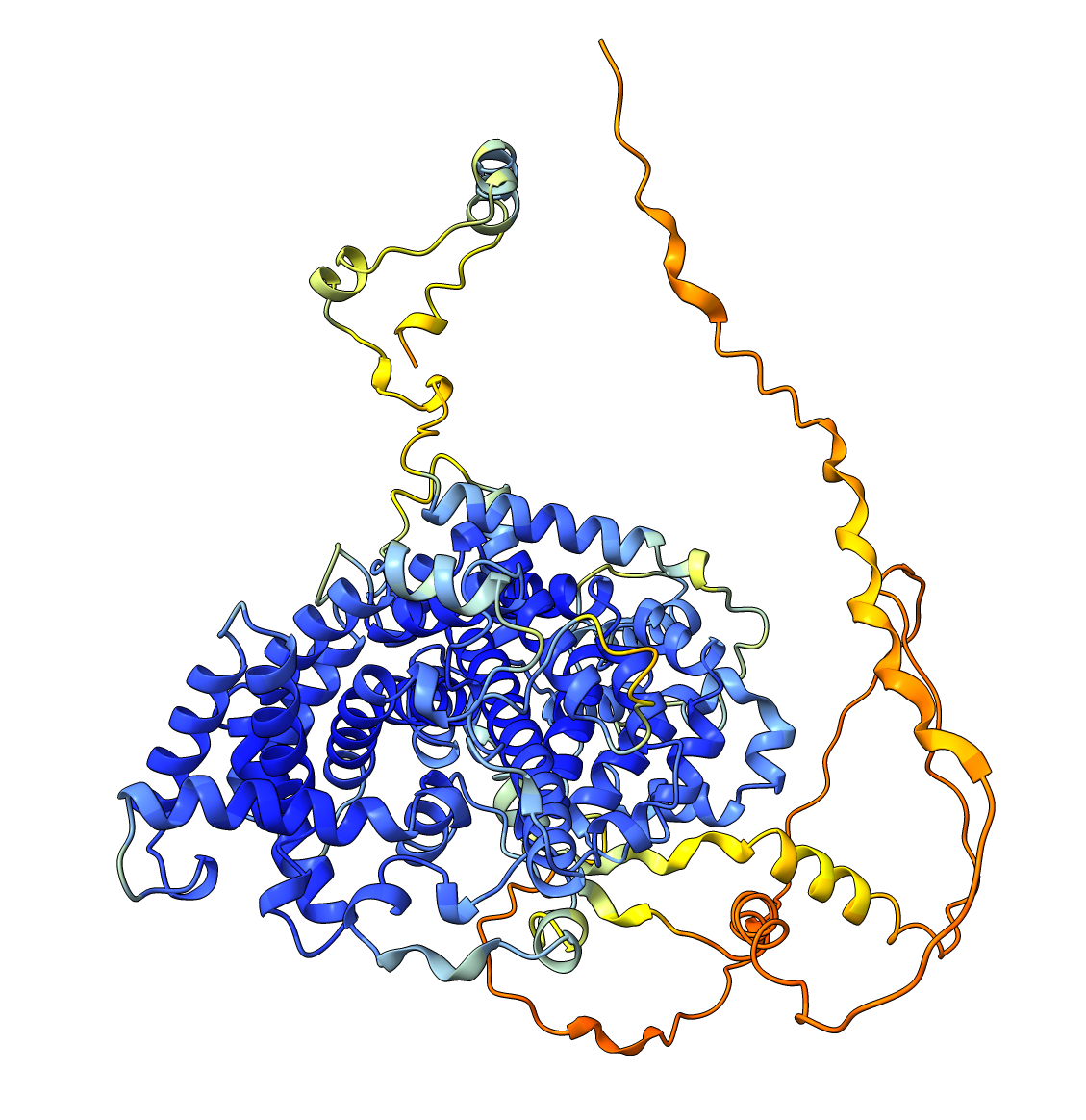
Very high pLDDT scores and low PAE scores for the AlphaFold structure indicating strong confidence, with one loop as exception. Several linkers, including the disordered N-terminal region, also show unexpectedly high pLDDT scores and low PAE scores, contrary to what would be expected for such regions. This apparent overconfidence is likely due to the inclusion of the crystal structure (1KYQ) in the AlphaFold training dataset.
Lowering the treshold can help reduce this apparent confidence, making it easier to differentiate between genuinely well-structured regions ans those that are more likely to be flexible or disordered.
| AlphaFold structure | PAE plot |
|---|---|
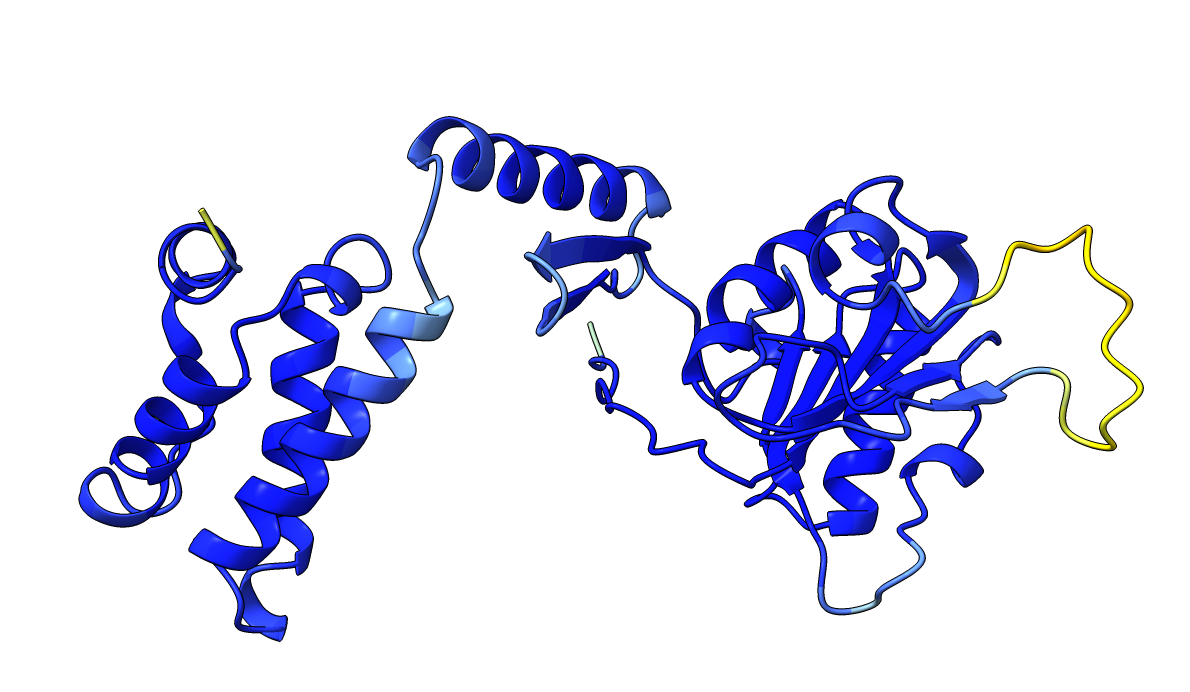 |
|
| Edge weights (default threshold = 5) | Edge weights (treshold = 3) |
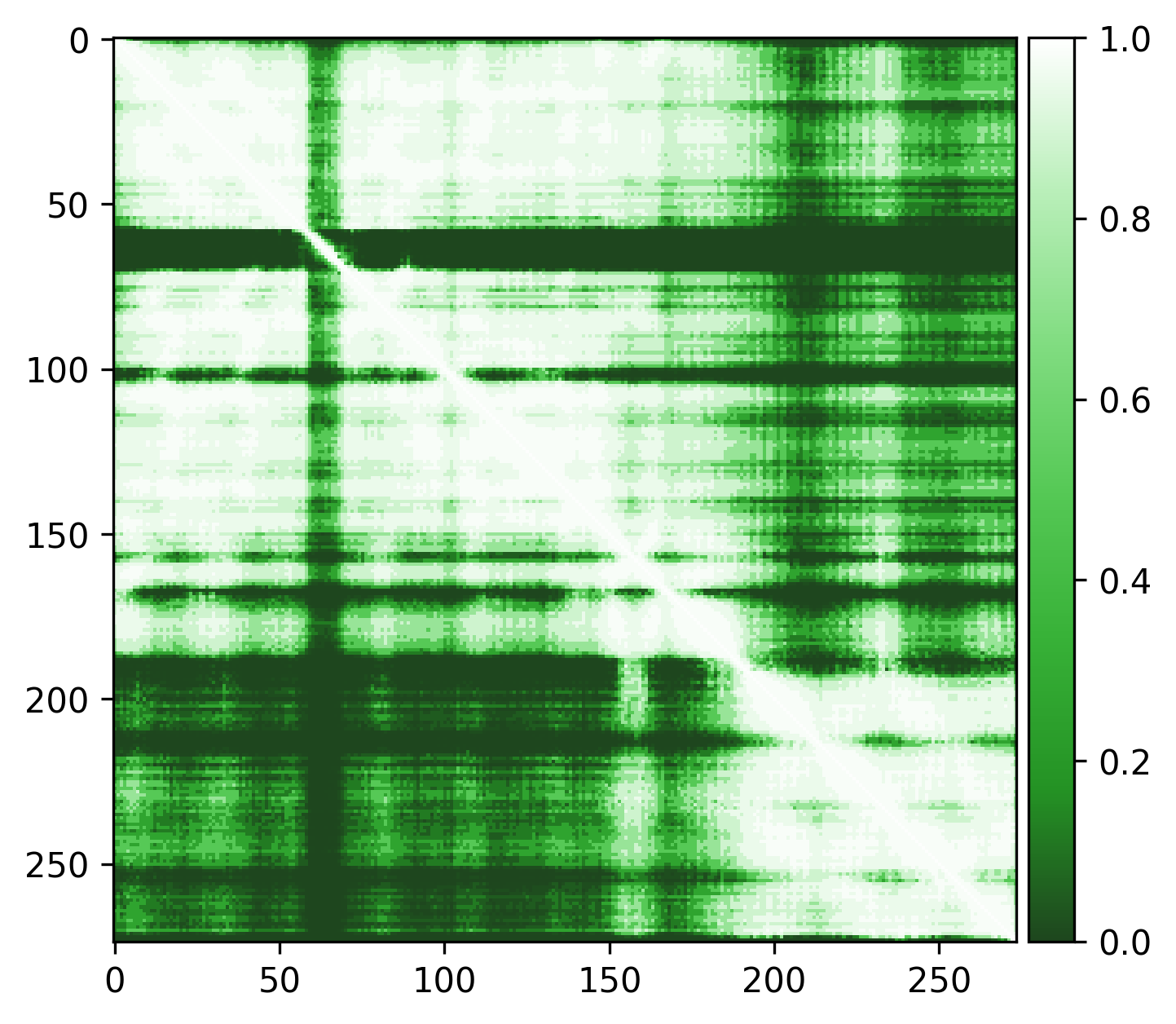 |
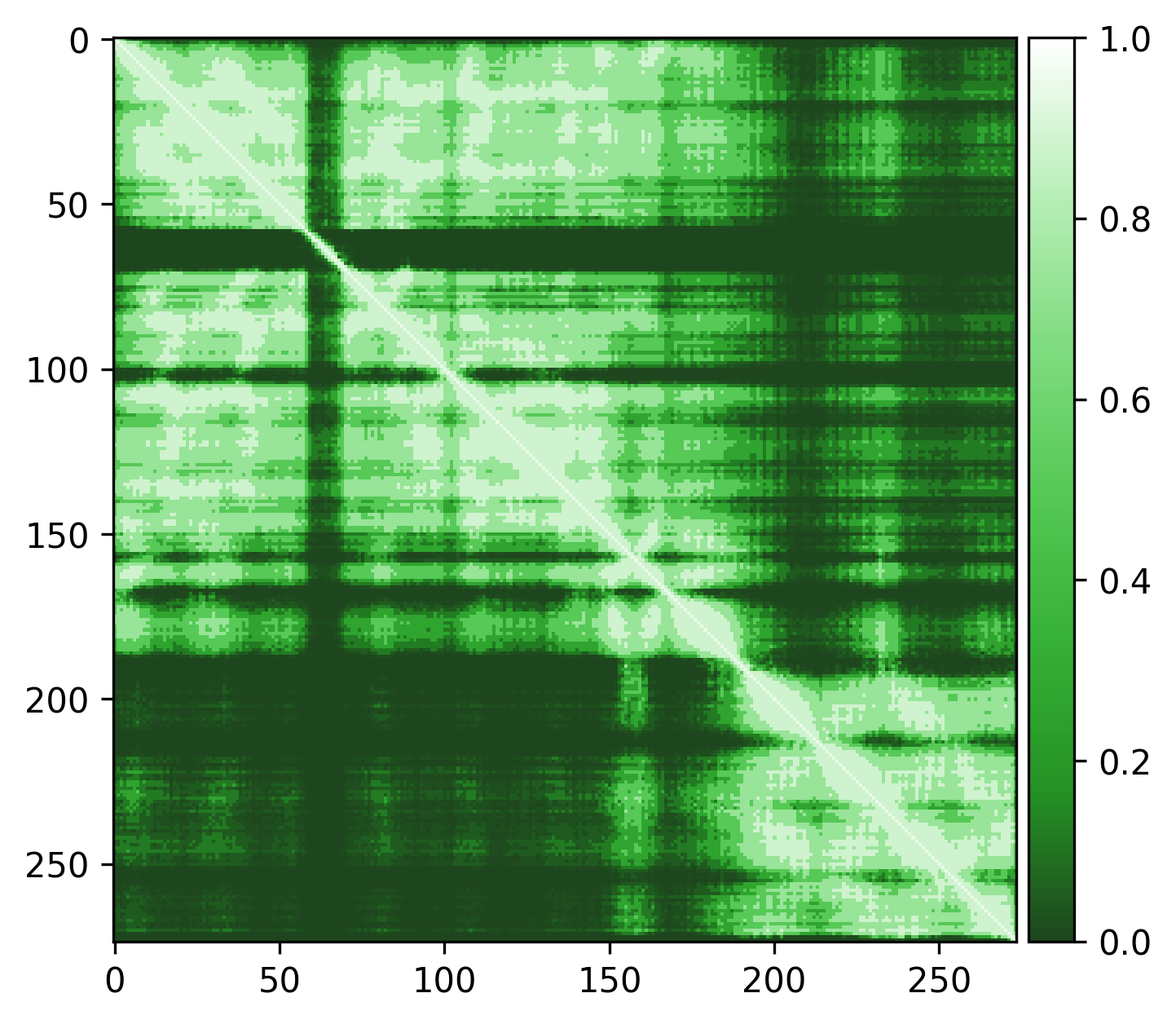 |
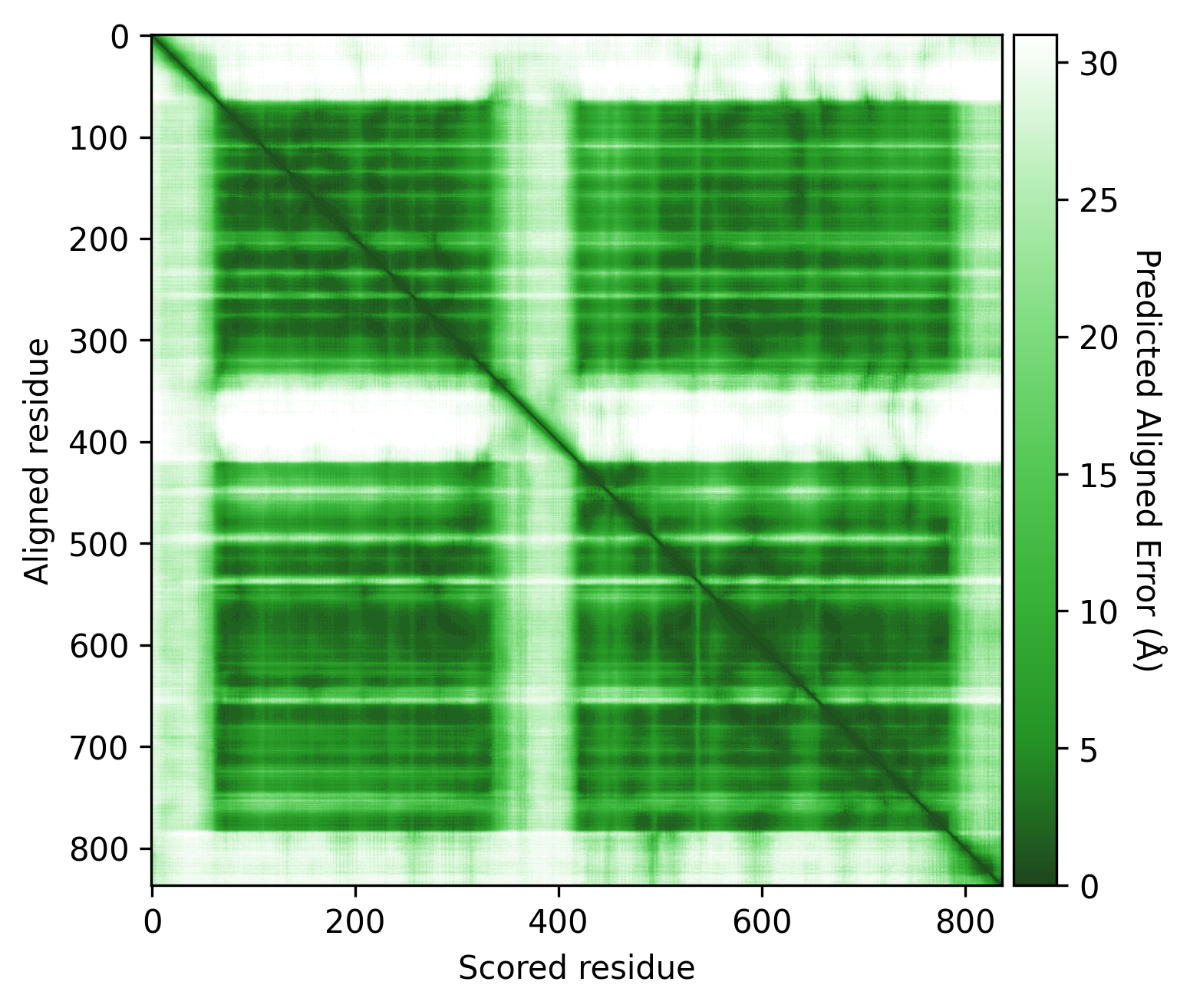
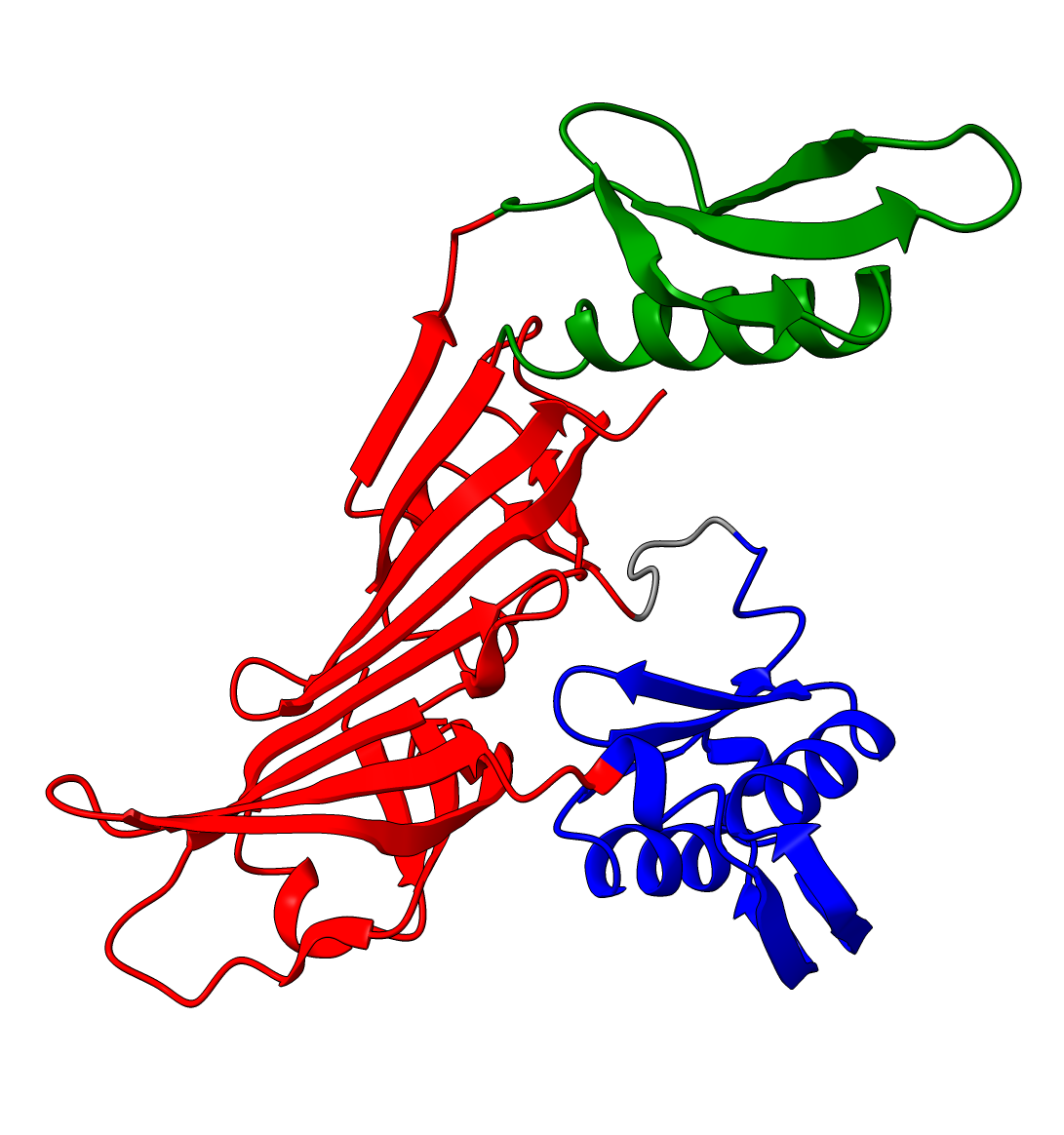
Q9YFU8
Q9YFU8 is a great example to remind us again that the PAE scores are not primarily intended to be used for domain segmentation, but instead are a measure of how confident AlphaFold is in the relative position of two residues.
The PAE plot for Q9YFU8 shows two distinct parts of the protein seperated with hight PAE values, indicating uncertainty in their relative positions. Going of off the previous examples, it would not be uncommon to assume there to be two distince domains in this protein, but this isn't necessarily the case. Q9YFU8 has two crystal structures in the PDB: 1W5S and 1W5T. Superpositioning of these crystal structures reveals that a significant portion of the protein overlays well, however another part shows a large deviation in orientation. AlphaFold likely learned this similarity and difference, resulting in low PAE scores for the overlapping regions and high PAE scores between the differently oriented parts. These structures might explain the resulting PAE scores, but this means we still need to pay attention choosing the threshold to properly segment the remaining parts of the protein structure.
| AlphaFold structure | PAE plot | Crystal structures: 1W5S (green) and 1W5T (red) |
|---|---|---|
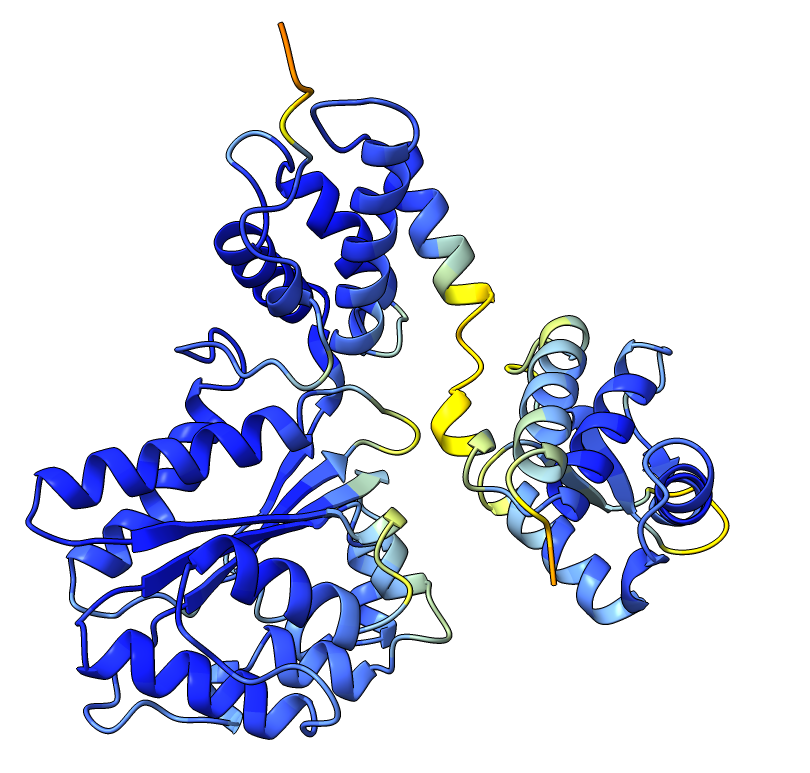 |
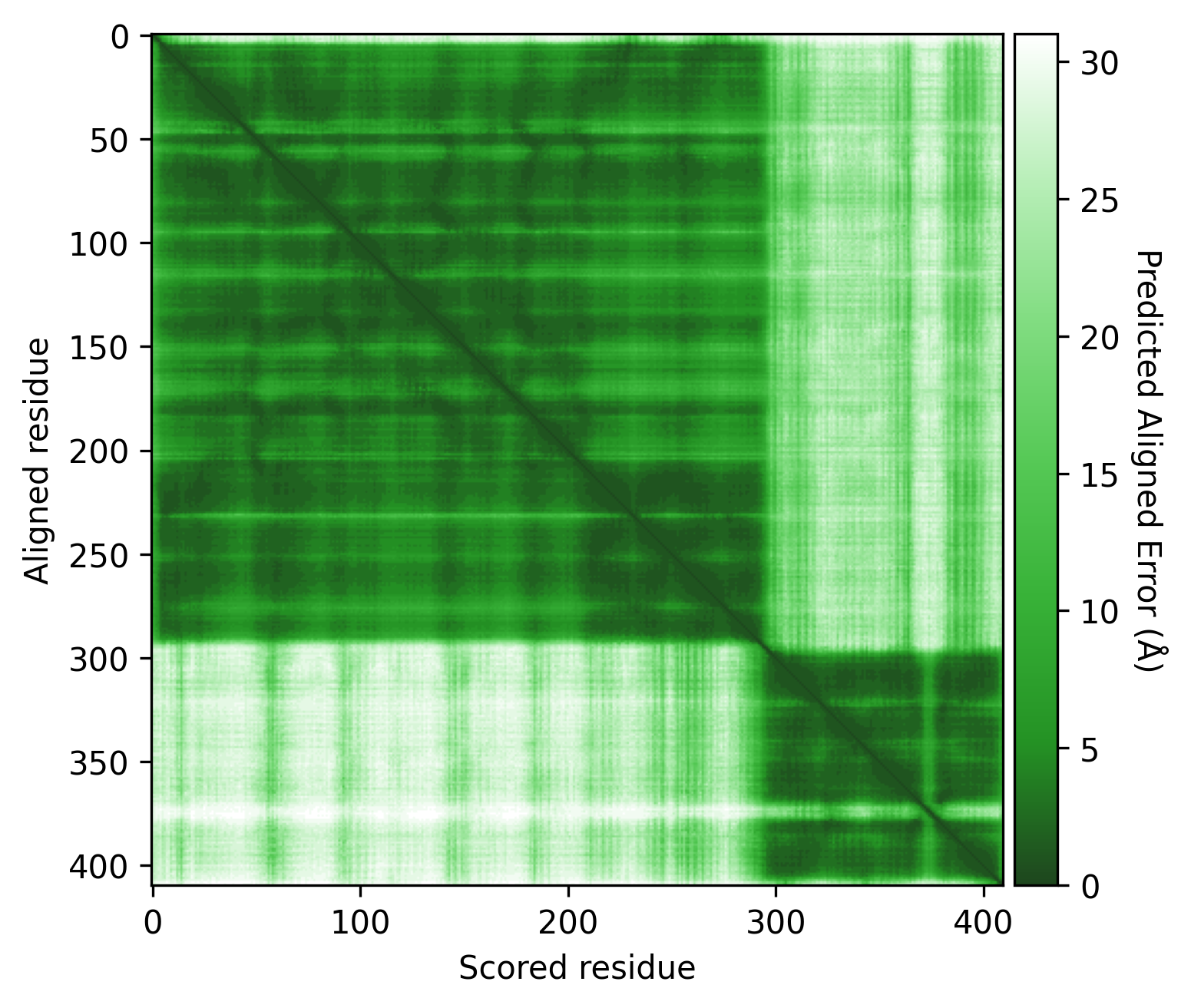 |
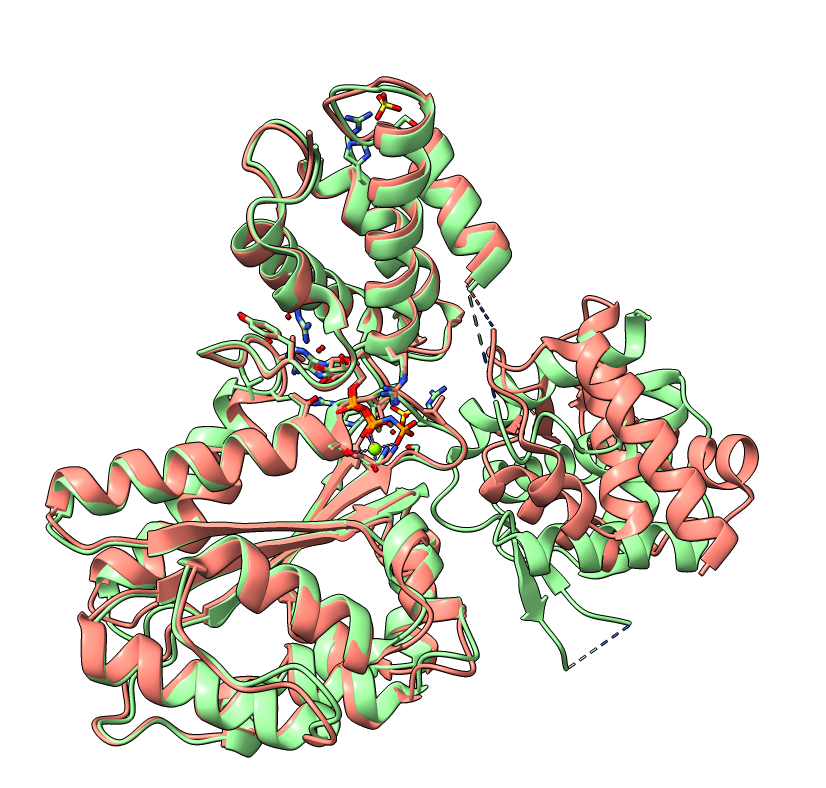 |
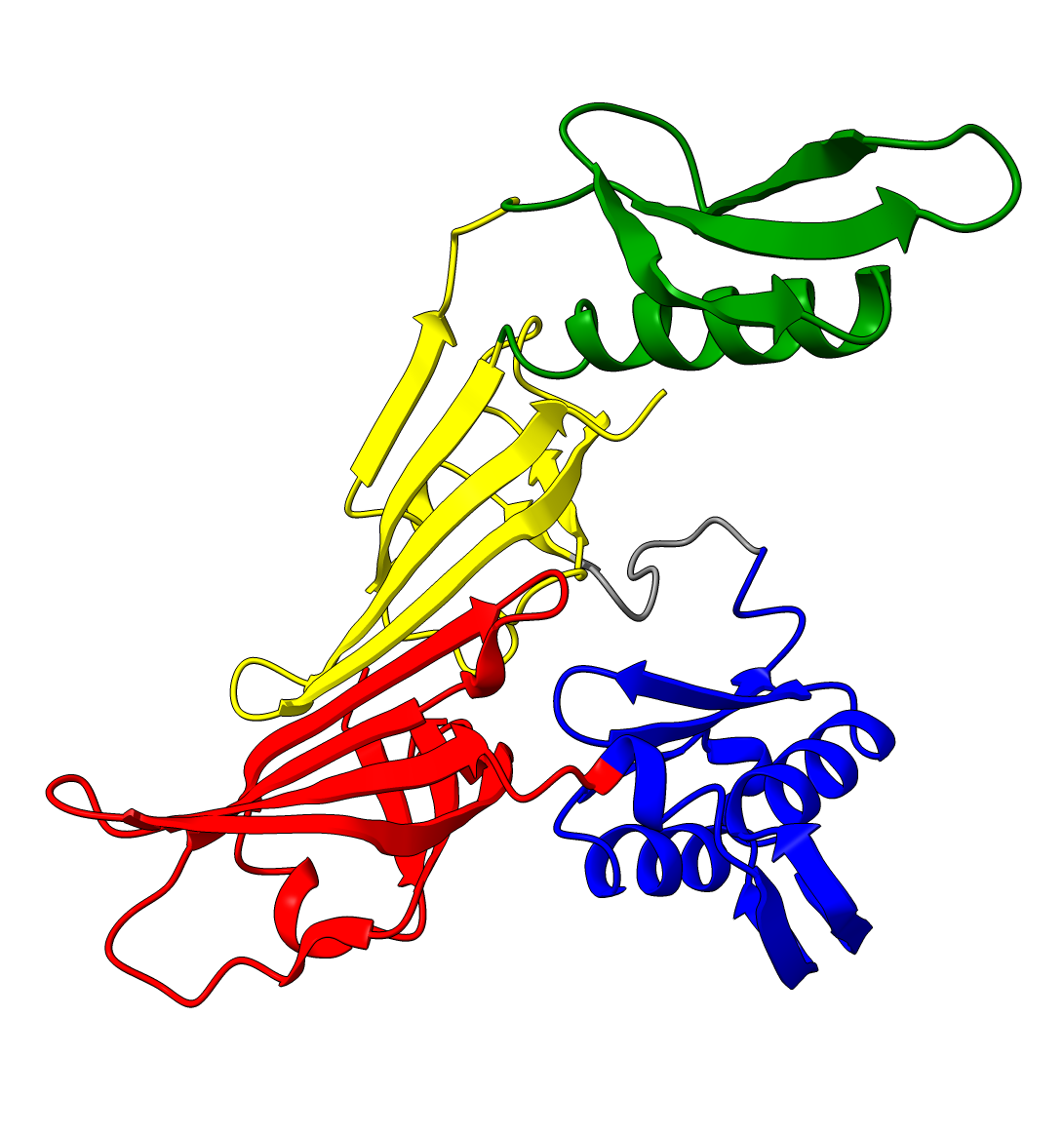
Lowering the treshold even if initial inspection deems it not necessary can still change the results. Without changing the threshold we see two domains, consistent with the results from SCOP and SCOPe. While lowering the threshold results in 3 domains, consistent with ECOD, CATH, Interpro and SCOP. (SCOP can contain multiple solutions)
| Threshold = 5 | Threshold = 3 |
|---|---|
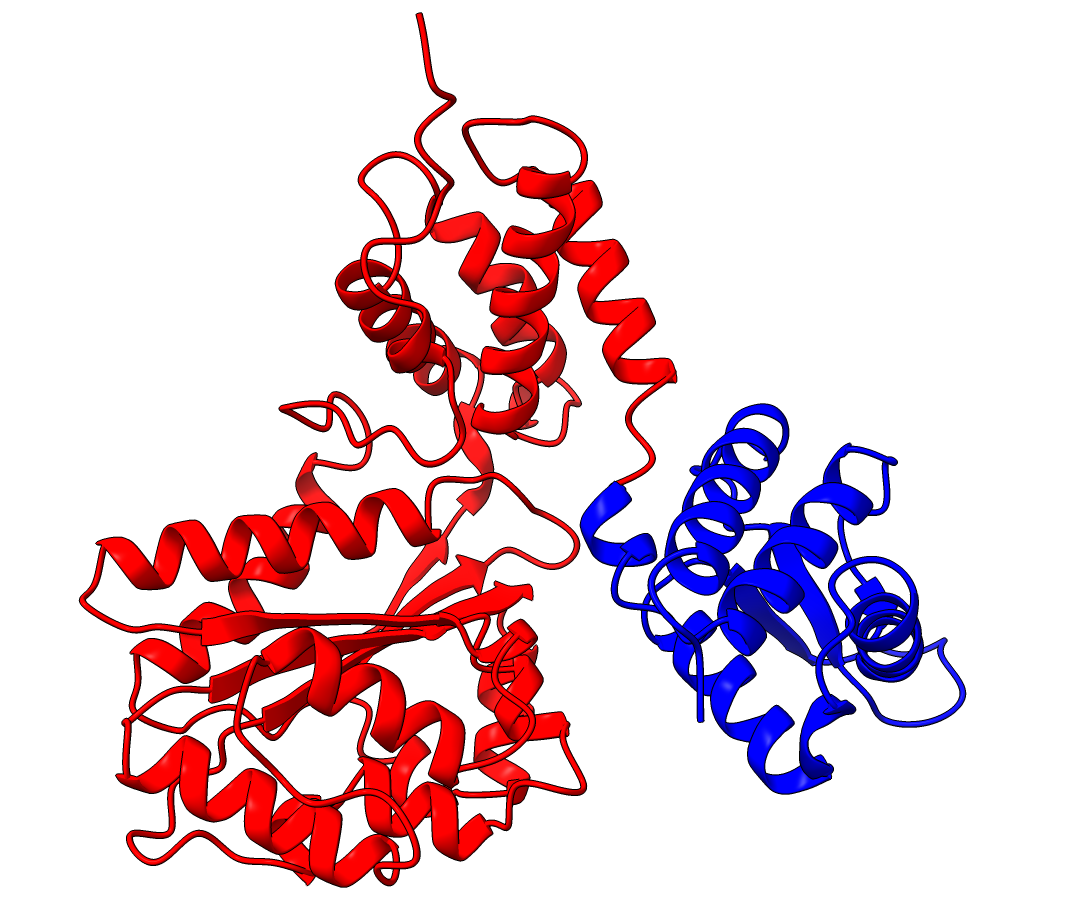 |
 |
(Other settings kept as default values)
Resolution
The resolution can be thought of as the coarseness of clustering. Increasing the resolution will result in more, smaller clusters (/domains). Decreasing the resolution will result in fewer but larger clusters.
- Default: dependent on objective_function
{"modularity": 0.7, "pm": 0.3}
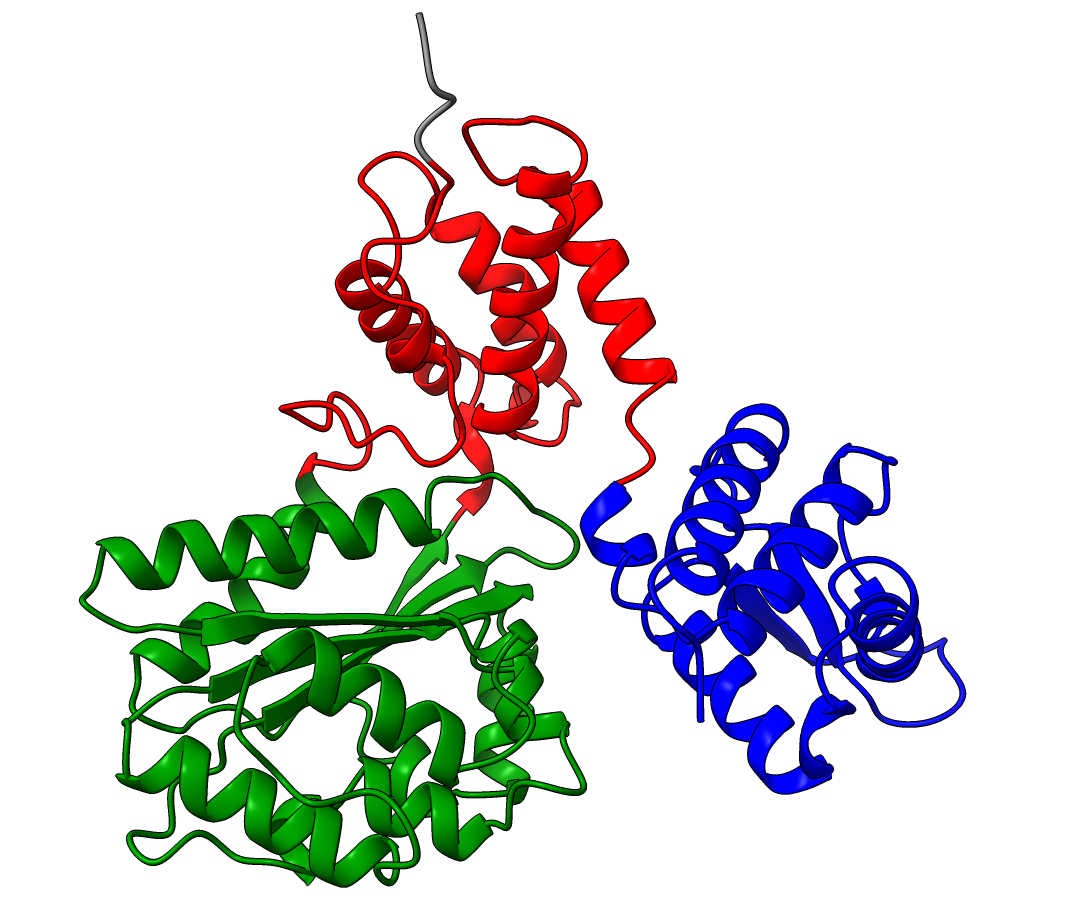
Examples:
P15807
| Resolution = 0.8 | Resolution = 1.1 | Resolution = 0.3 |
|---|---|---|
|
|
|
A0A098AQT8
| Resolution = 0.8 | Resolution = 1.4 |
|---|---|
 |
 |
Objective function
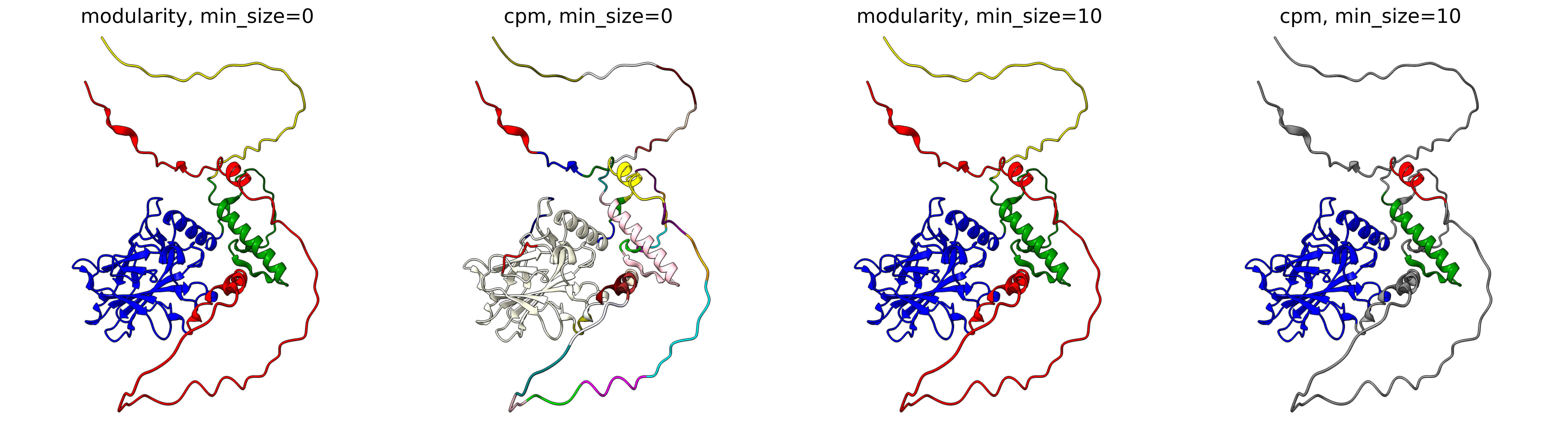
The objective function that is optimized during clustering, choices are either CPM (constant potts model) or Modularity. The contant potts model does not suffer from the resolution limit problem like modularity does, leading to more, smaller well-defined clusters. This means that 'CPM' will result in more smaller, tightly connected clusters that represent specific subgroups or communities within the data. On the other hand, 'Modularity' will tend to produce fewer, larger clusters that encompass broader groups within the data.
For AFragmenter, 'CPM' translates to a more sensitive approach where we see many more smaller clusters, especially for disordered regions. 'Modularity' is less sensitive to small shifts in PAE values, and will be better at clustering residues from disordered regions together.
- Default:
modularity - Options:
[modularity, cpm]
Examples:
P04637
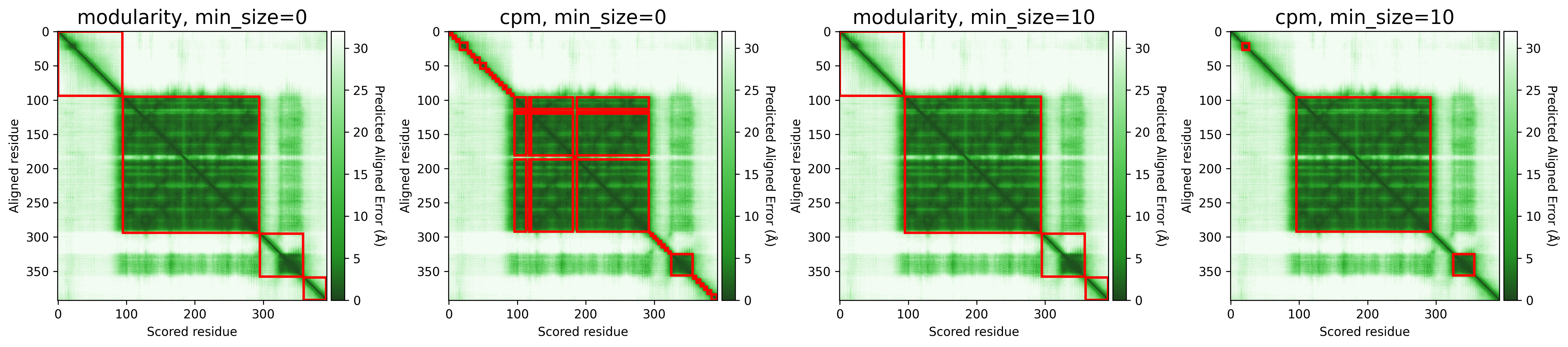
Q837X5
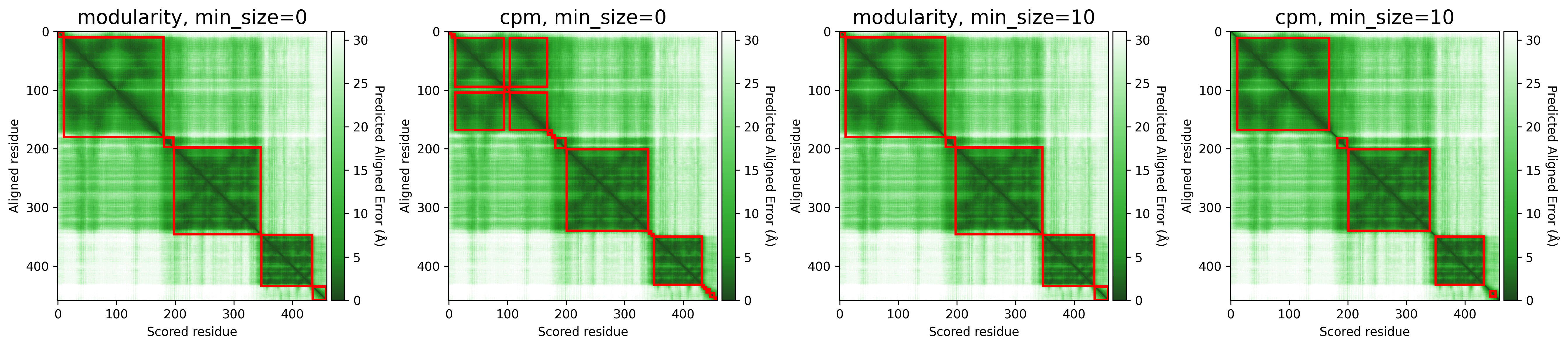
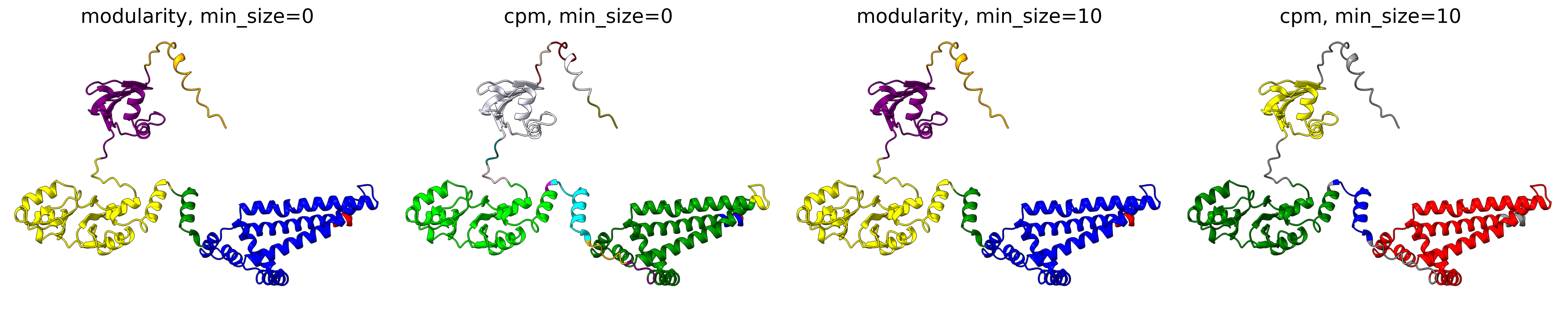
Minimum size (min_size)
The min_size parameter specifies the minimum number of residues required for a cluster / domain to be considered valid. Clusters below this threshold are filtered out during post-processing. This helps in reducing noise and focusing on significant structural or functional regions.
- Default value: 10
- Valid range: 0 ≤ min_size ≤ Number of Residues
A higher min_size is often used for larger proteins to focus on major domains, while a lower value allows capturing smaller but potentially important regions. Adjusting this parameter can impact the granularity of your clustering results.
For examples, refer to the examples in Objective function.
Merge
The merge parameter, also referred to as attempt_merge, plays a important role in refining the clustering process.
When enabled, it attempts to merge smaller clusters (= below min_size) with adjacent larger ones, ensuring that the resulting clusters are more meaningful and less fragmented. Resulting clusters below the min_size are first attempted to be merged with adjacent larger clusters. If merging is not possible, the small clusters are filtered out.
- Default value:
True


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file afragmenter-0.0.4.tar.gz.
File metadata
- Download URL: afragmenter-0.0.4.tar.gz
- Upload date:
- Size: 31.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/2.1.3 CPython/3.10.12 Linux/6.6.87.2-microsoft-standard-WSL2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8e843fc40460c703c17feeec15d160bc8929fd046133b3f8c47c2c586b01e1c7
|
|
| MD5 |
c29efbe9548544171f041b7cc48bcf75
|
|
| BLAKE2b-256 |
a37fdf3cf791b283a8640716e1124e39488d860cc45df6380ed36b975f390ed4
|
File details
Details for the file afragmenter-0.0.4-py3-none-any.whl.
File metadata
- Download URL: afragmenter-0.0.4-py3-none-any.whl
- Upload date:
- Size: 32.5 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/2.1.3 CPython/3.10.12 Linux/6.6.87.2-microsoft-standard-WSL2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
7656bc749ea5e0b07a8e0affad725c0b64f3d27cbd649fb1884ec3b643423630
|
|
| MD5 |
c73bedfd111e4e3508a0445966ba9071
|
|
| BLAKE2b-256 |
c8b26ce99b85d26e0d004ed1e66c2ab5839c66c8cc821a4040e85150766470e4
|







