A python implementation of OpenNMT



Project description
OpenNMT-py: Open-Source Neural Machine Translation




OpenNMT-py is the PyTorch version of the OpenNMT project, an open-source (MIT) neural machine translation framework. It is designed to be research friendly to try out new ideas in translation, summary, morphology, and many other domains. Some companies have proven the code to be production ready.
We love contributions! Please look at issues marked with the contributions welcome tag.
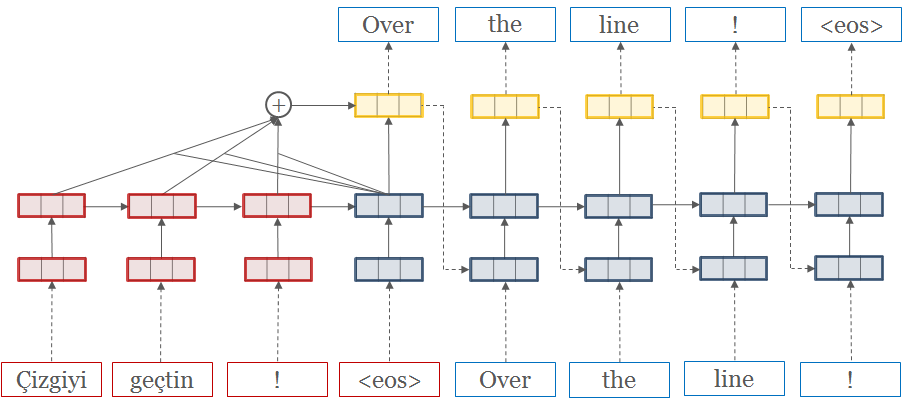 Before raising an issue, make sure you read the requirements and the documentation examples.
Before raising an issue, make sure you read the requirements and the documentation examples.
Unless there is a bug, please use the forum or Gitter to ask questions.
OpenNMT-py 3.0
We're happy to announce the release v3.0 of OpenNMT-py.
This new version does not rely on Torchtext anymore. The checkpoint structure is slightly changed but we provide a tool to convert v2 to v3 models (cf tools/convertv2_v3.py)
We use the same 'dynamic' paradigm as in v2, allowing to apply on-the-fly transforms to the data.
This has a few advantages, amongst which:
- remove or drastically reduce the preprocessing required to train a model;
- increase the possibilities of data augmentation and manipulation through on-the fly transforms.
These transforms can be specific tokenization methods, filters, noising, or any custom transform users may want to implement. Custom transform implementation is quite straightforward thanks to the existing base class and example implementations.
You can check out how to use this new data loading pipeline in the updated docs.
All the readily available transforms are described here.
Performance tips
Given sufficient CPU resources according to GPU computing power, most of the transforms should not slow the training down. (Note: for now, one producer process per GPU is spawned -- meaning you would ideally need 2N CPU threads for N GPUs). If you want to optimize the training performance:
-
use fp16
-
use batch_size_multiple 8
-
use vocab_size_multiple 8
-
Depending on the number of GPU use num_workers 4 (for 1 GPU) or 2 (for multiple GPU)
-
To avoid averaging checkpoints you can use the "during training" average decay system.
-
If you train a transformer we support max_relative_positions (use 20) instead of position_encoding.
-
for very fast inference convert your model to CTranslate2 format.
Breaking changes
Changes between v2 and v3:
Options removed:
queue_size, pool_factor are no longer needed. Only adjust the bucket_size to the number of examples to be loaded by each num_workers of the pytorch Dataloader.
New options:
num_workers: number of workers for each process. If you run on one GPU the recommended value is 4. If you run on more than 1 GPU, the recommended value is 2
add_qkvbias: default is false. However old model trained with v2 will be set at true. The original transformer paper used no bias for the Q/K/V nn.Linear of the multihead attention module.
Options renamed:
rnn_size => hidden_size
enc_rnn_size => enc_hid_size
dec_rnn_size => dec_hid_size
Note: tools/convertv2_v3.py will modify these options stored in the checkpoint to make things compatible with v3.0
Inference:
The translator will use the same dynamic_iterator as the trainer.
The new default for inference is length_penalty=avg which will provide better BLEU scores in most cases (and comparable to other toolkits defaults)
Reminder: a few features were dropped between v1 and v2:
- audio, image and video inputs;
For any user that still need these features, the previous codebase will be retained as legacy in a separate branch. It will no longer receive extensive development from the core team but PRs may still be accepted.
Feel free to check it out and let us know what you think of the new paradigm!
Table of Contents
Setup
OpenNMT-py requires:
- Python >= 3.7
- PyTorch >= 1.9.0
Install OpenNMT-py from pip:
pip install OpenNMT-py
or from the sources:
git clone https://github.com/OpenNMT/OpenNMT-py.git
cd OpenNMT-py
pip install -e .
Note: if you encounter a MemoryError during installation, try to use pip with --no-cache-dir.
(Optional) Some advanced features (e.g. working pretrained models or specific transforms) require extra packages, you can install them with:
pip install -r requirements.opt.txt
Features
- On the fly data processing
- Encoder-decoder models with multiple RNN cells (LSTM, GRU) and attention types (Luong, Bahdanau)
- Transformer models
- Copy and Coverage Attention
- Pretrained Embeddings
- Source word features
- TensorBoard logging
- Multi-GPU training
- Inference (translation) with batching and beam search
- Inference time loss functions
- Conv2Conv convolution model
- SRU "RNNs faster than CNN" paper
- Mixed-precision training with APEX, optimized on Tensor Cores
- Model export to CTranslate2, a fast and efficient inference engine
Quickstart
Step 1: Prepare the data
To get started, we propose to download a toy English-German dataset for machine translation containing 10k tokenized sentences:
wget https://s3.amazonaws.com/opennmt-trainingdata/toy-ende.tar.gz
tar xf toy-ende.tar.gz
cd toy-ende
The data consists of parallel source (src) and target (tgt) data containing one sentence per line with tokens separated by a space:
src-train.txttgt-train.txtsrc-val.txttgt-val.txt
Validation files are used to evaluate the convergence of the training. It usually contains no more than 5k sentences.
$ head -n 2 toy-ende/src-train.txt
It is not acceptable that , with the help of the national bureaucracies , Parliament 's legislative prerogative should be made null and void by means of implementing provisions whose content , purpose and extent are not laid down in advance .
Federal Master Trainer and Senior Instructor of the Italian Federation of Aerobic Fitness , Group Fitness , Postural Gym , Stretching and Pilates; from 2004 , he has been collaborating with Antiche Terme as personal Trainer and Instructor of Stretching , Pilates and Postural Gym .
We need to build a YAML configuration file to specify the data that will be used:
# toy_en_de.yaml
## Where the samples will be written
save_data: toy-ende/run/example
## Where the vocab(s) will be written
src_vocab: toy-ende/run/example.vocab.src
tgt_vocab: toy-ende/run/example.vocab.tgt
# Prevent overwriting existing files in the folder
overwrite: False
# Corpus opts:
data:
corpus_1:
path_src: toy-ende/src-train.txt
path_tgt: toy-ende/tgt-train.txt
valid:
path_src: toy-ende/src-val.txt
path_tgt: toy-ende/tgt-val.txt
...
From this configuration, we can build the vocab(s) that will be necessary to train the model:
onmt_build_vocab -config toy_en_de.yaml -n_sample 10000
Notes:
-n_sampleis required here -- it represents the number of lines sampled from each corpus to build the vocab.- This configuration is the simplest possible, without any tokenization or other transforms. See other example configurations for more complex pipelines.
Step 2: Train the model
To train a model, we need to add the following to the YAML configuration file:
- the vocabulary path(s) that will be used: can be that generated by onmt_build_vocab;
- training specific parameters.
# toy_en_de.yaml
...
# Vocabulary files that were just created
src_vocab: toy-ende/run/example.vocab.src
tgt_vocab: toy-ende/run/example.vocab.tgt
# Train on a single GPU
world_size: 1
gpu_ranks: [0]
# Where to save the checkpoints
save_model: toy-ende/run/model
save_checkpoint_steps: 500
train_steps: 1000
valid_steps: 500
Then you can simply run:
onmt_train -config toy_en_de.yaml
This configuration will run the default model, which consists of a 2-layer LSTM with 500 hidden units on both the encoder and decoder. It will run on a single GPU (world_size 1 & gpu_ranks [0]).
Before the training process actually starts, the *.vocab.pt together with *.transforms.pt will be dumpped to -save_data with configurations specified in -config yaml file. We'll also generate transformed samples to simplify any potentially required visual inspection. The number of sample lines to dump per corpus is set with the -n_sample flag.
For more advanded models and parameters, see other example configurations or the FAQ.
Step 3: Translate
onmt_translate -model toy-ende/run/model_step_1000.pt -src toy-ende/src-test.txt -output toy-ende/pred_1000.txt -gpu 0 -verbose
Now you have a model which you can use to predict on new data. We do this by running beam search. This will output predictions into toy-ende/pred_1000.txt.
Note:
The predictions are going to be quite terrible, as the demo dataset is small. Try running on some larger datasets! For example you can download millions of parallel sentences for translation or summarization.
(Optional) Step 4: Release
When you are satisfied with your trained model, you can release it for inference. The release process will remove training-only parameters from the checkpoint:
onmt_release_model -model toy-ende/run/model_step_1000.pt -output toy-ende/run/model_step_1000_release.pt
The release script can also export checkpoints to CTranslate2, a fast inference engine for Transformer models. See the -format command line option.
Pretrained embeddings (e.g. GloVe)
Please see the FAQ: How to use GloVe pre-trained embeddings in OpenNMT-py
Pretrained models
Several pretrained models can be downloaded and used with onmt_translate:
Acknowledgements
OpenNMT-py is run as a collaborative open-source project. The original code was written by Adam Lerer (NYC) to reproduce OpenNMT-Lua using PyTorch.
Current maintainers: Ubiqus Team: François Hernandez and Team. Vincent Nguyen (Seedfall)
Project incubators:
- Sasha Rush (Cambridge, MA)
- Guillaume Klein (Systran)
Early contributors
- Ben Peters (Lisbon)
- Sebastian Gehrmann (PhD Harvard NLP)
- Yuntian Deng (PhD Harvard NLP)
- Paul Tardy (PhD Ubiqus / Lium)
- Linxiao Zeng (Ubiqus)
- Jianyu Zhan (Shanghai)
- Dylan Flaute (University of Dayton)
- ... and more!
OpenNMT-py is part of the OpenNMT project.
Citation
If you are using OpenNMT-py for academic work, please cite the initial system demonstration paper published in ACL 2017:
@inproceedings{klein-etal-2017-opennmt,
title = "{O}pen{NMT}: Open-Source Toolkit for Neural Machine Translation",
author = "Klein, Guillaume and
Kim, Yoon and
Deng, Yuntian and
Senellart, Jean and
Rush, Alexander",
booktitle = "Proceedings of {ACL} 2017, System Demonstrations",
month = jul,
year = "2017",
address = "Vancouver, Canada",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/P17-4012",
pages = "67--72",
}
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file OpenNMT-py-3.0.0.tar.gz.
File metadata
- Download URL: OpenNMT-py-3.0.0.tar.gz
- Upload date:
- Size: 168.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.8.15
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9354f5a2a3d6e4dcf494496cbdc124e8c79b79fa7b37fc55a25280f64e8712d0
|
|
| MD5 |
6d9da2abba9efeb84d758af2b520d826
|
|
| BLAKE2b-256 |
82deef8df977b1bb74199af7514701bfe5743101d3dada5f94408c87b36c419a
|
File details
Details for the file OpenNMT_py-3.0.0-py3-none-any.whl.
File metadata
- Download URL: OpenNMT_py-3.0.0-py3-none-any.whl
- Upload date:
- Size: 208.4 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.8.15
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
dc82cd976bf76731b16bf6f597accaa5b92e3d71c23042917c5aab61aaf79840
|
|
| MD5 |
34640b551d8ead4129032c887edbe2ce
|
|
| BLAKE2b-256 |
e7fe9f0cae8c27aed91641c980c368771022c543684fc3ebbf431b1ca35efd83
|







