Fast fitting of 2D- and 3D-Spectra with established routines

Project description







SpectraFit
Data Analysis Tool for All Kinds of Spectra
Warning SpectraFit v2.0 is currently in development. SpectraFit v1.x is in end-of-life maintenance mode and will receive only critical hotfixes.
SpectraFit is a Python tool for quick data fitting based on the regular
expression of distribution and linear functions via the command line (CMD) or
Jupyter Notebook It is designed to be easy to use and
supports all common ASCII data formats. SpectraFit runs on Linux,
Windows, and MacOS.
Scope
- Fitting of 2D data, also with multiple columns as global fitting
- Using established and advanced solver methods
- Extensibility of the fitting function
- Guarantee traceability of the fitting results
- Saving all results in a SQL-like-format (
CSV) for publications - Saving all results in a NoSQL-like-format (
JSON) for project management - Having an API interface for Graph-databases
SpectraFit is a tool designed for researchers and scientists who require
immediate data fitting to a model. It proves to be especially beneficial for
individuals working with vast datasets or who need to conduct numerous fits
within a limited time frame. SpectraFit's adaptability to various platforms
and data formats makes it a versatile tool that caters to a broad spectrum of
scientific applications.
Installation
via pip:
pip install SpectraFit
# with support for Jupyter Notebook
pip install SpectraFit[jupyter]
# with support for the dashboard in the Jupyter Notebook
pip install SpectraFit[jupyter-dash]
# with support to visualize pkl-files as graph
pip install SpectraFit[graph]
# with all upcomming features
pip install SpectraFit[all]
# Upgrade
pip install SpectraFit --upgrade
via conda, see also conda-forge:
conda install -c conda-forge spectrafit
# with support for Jupyter Notebook
conda install -c conda-forge spectrafit-jupyter
# with all upcomming features
conda install -c conda-forge spectrafit-all
Usage
SpectraFit needs as command line tool only two things:
- The reference data, which should be fitted.
- The input file, which contains the initial model.
As model files json,
toml, and
yaml are supported. By making use of the
python **kwargs feature, the input file can call most of the following
functions of LMFIT. LMFIT is the
workhorse for the fit optimization, which is macro wrapper based on:
In case of SpectraFit, we have further extend the package by:
- Pandas
- statsmodels
- numdifftools
- Matplotlib in combination with Seaborn
spectrafit data_file.txt -i input_file.json
usage: spectrafit [-h] [-o OUTFILE] [-i INPUT] [-ov] [-e0 ENERGY_START]
[-e1 ENERGY_STOP] [-s SMOOTH] [-sh SHIFT] [-c COLUMN COLUMN]
[-sep { ,,,;,:,|, ,s+}] [-dec {.,,}] [-hd HEADER]
[-g {0,1,2}] [-auto] [-np] [-v] [-vb {0,1,2}]
infile
Fast Fitting Program for ascii txt files.
positional arguments:
infile Filename of the spectra data
optional arguments:
-h, --help show this help message and exit
-o OUTFILE, --outfile OUTFILE
Filename for the export, default to set to
'spectrafit_results'.
-i INPUT, --input INPUT
Filename for the input parameter, default to set to
'fitting_input.toml'.Supported fileformats are:
'*.json', '*.yml', '*.yaml', and '*.toml'
-ov, --oversampling Oversampling the spectra by using factor of 5;
default to False.
-e0 ENERGY_START, --energy_start ENERGY_START
Starting energy in eV; default to start of energy.
-e1 ENERGY_STOP, --energy_stop ENERGY_STOP
Ending energy in eV; default to end of energy.
-s SMOOTH, --smooth SMOOTH
Number of smooth points for lmfit; default to 0.
-sh SHIFT, --shift SHIFT
Constant applied energy shift; default to 0.0.
-c COLUMN COLUMN, --column COLUMN COLUMN
Selected columns for the energy- and intensity-values;
default to '0' for energy (x-axis) and '1' for intensity
(y-axis). In case of working with header, the column
should be set to the column names as 'str'; default
to 0 and 1.
-sep { ,,,;,:,|, ,s+}, --separator { ,,,;,:,|, ,s+}
Redefine the type of separator; default to ' '.
-dec {.,,}, --decimal {.,,}
Type of decimal separator; default to '.'.
-hd HEADER, --header HEADER
Selected the header for the dataframe; default to None.
-cm COMMENT, --comment COMMENT
Lines with comment characters like '#' should not be
parsed; default to None.
-g {0,1,2}, --global_ {0,1,2}
Perform a global fit over the complete dataframe. The
options are '0' for classic fit (default). The
option '1' for global fitting with auto-definition
of the peaks depending on the column size and '2'
for self-defined global fitting routines.
-auto, --autopeak Auto detection of peaks in the spectra based on `SciPy`.
The position, height, and width are used as estimation
for the `Gaussian` models.The default option is 'False'
for manual peak definition.
-np, --noplot No plotting the spectra and the fit of `SpectraFit`.
-v, --version Display the current version of `SpectraFit`.
-vb {0,1,2}, --verbose {0,1,2}
Display the initial configuration parameters and fit
results, as a table '1', as a dictionary '2', or not in
the terminal '0'. The default option is set to 1 for
table `printout`.
Jupyter Notebook
Open the Jupyter Notebook and run the following code:
spectrafit-jupyter
or via Docker Image for <cpu> with amd64 and arm64:
docker pull ghcr.io/anselmoo/spectrafit-<cpu>:latest
docker run -it -p 8888:8888 spectrafit-<cpu>:latest
or just:
docker run -p 8888:8888 ghcr.io/anselmoo/spectrafit-<cpu>:latest
Next define your initial model and the reference data:
from spectrafit.plugins.notebook import SpectraFitNotebook
import pandas as pd
df = pd.read_csv(
"https://raw.githubusercontent.com/Anselmoo/spectrafit/main/Examples/data.csv"
)
initial_model = [
{
"pseudovoigt": {
"amplitude": {"max": 2, "min": 0, "vary": True, "value": 1},
"center": {"max": 2, "min": -2, "vary": True, "value": 0},
"fwhmg": {"max": 0.4, "min": 0.1, "vary": True, "value": 0.21},
"fwhml": {"max": 0.4, "min": 0.1, "vary": True, "value": 0.21},
}
},
{
"pseudovoigt": {
"amplitude": {"max": 2, "min": 0, "vary": True, "value": 1},
"center": {"max": 2, "min": -2, "vary": True, "value": 1},
"fwhmg": {"max": 0.4, "min": 0.1, "vary": True, "value": 0.21},
"fwhml": {"max": 0.4, "min": 0.1, "vary": True, "value": 0.21},
}
},
{
"pseudovoigt": {
"amplitude": {"max": 2, "min": 0, "vary": True, "value": 1},
"center": {"max": 2, "min": -2, "vary": True, "value": 1},
"fwhmg": {"max": 0.4, "min": 0.1, "vary": True, "value": 0.21},
"fwhml": {"max": 0.4, "min": 0.1, "vary": True, "value": 0.21},
}
},
]
spf = SpectraFitNotebook(df=df, x_column="Energy", y_column="Noisy")
spf.solver_model(initial_model)
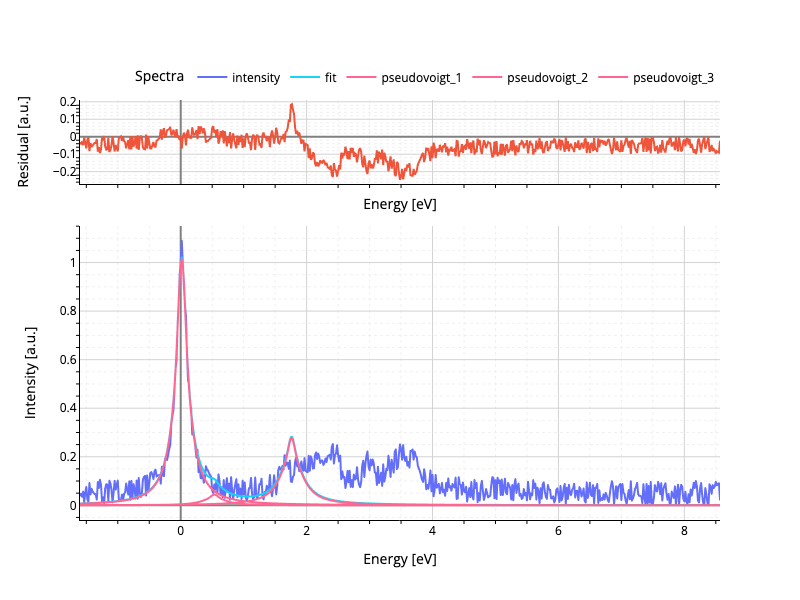
Which results in the following output:
Documentation
Please see the extended documentation
for the full usage of SpectraFit.
The documentation is generated by

Project details
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file spectrafit-1.5.1.tar.gz.
File metadata
- Download URL: spectrafit-1.5.1.tar.gz
- Upload date:
- Size: 98.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
453ca709ab1ee22e5fc83fea14cb5fb067d0e3bc9f4adc30f824b11a28cb89b5
|
|
| MD5 |
71f1e75733959a29f376049babdd4af1
|
|
| BLAKE2b-256 |
6066f7514f1c5bf8b678b5fada78505c710c79bcc8d421d4b45ac67dae3726c1
|
File details
Details for the file spectrafit-1.5.1-py3-none-any.whl.
File metadata
- Download URL: spectrafit-1.5.1-py3-none-any.whl
- Upload date:
- Size: 110.4 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
3b8860dcb9b4ed666bdaffb4451cb238caacd2e04f4a8db2a0557997e97499c0
|
|
| MD5 |
4e5ae8f79a5b1e6c351225ef132918b5
|
|
| BLAKE2b-256 |
9b01843efb88d19764e9801ee025eacf975c6f680e8752d2f493052e6ddcbf01
|







