A static optimizing tensor compiler with a Python frontend…

Project description
🔢🥶 TensorFrost







A static optimizing tensor compiler with a Python frontend, autodifferentiation, and a more "shader-like" syntax.
Currently working platforms:
| Backend/OS | CodeGen Only | C++/OpenMP | GLSL/OpenGL | CUDA | GLSL/Vulkan | WGSL/WebGPU |
|---|---|---|---|---|---|---|
| Windows | ✅ | 🚧 | 🚧 | ⛔ | ⛔ | ⛔ |
| Linux | ✅ | 🚧 | 🚧 | ⛔ | ⛔ | ⛔ |
| MacOS | ✅ | ⛔ | ⛔ | ⛔ | ⛔ | ⛔ |
For more detail about this project, please read my blog post! Writing an optimizing tensor compiler from scratch
The current version of the library is still in early beta, and at this point I would strongly recommend not to use this for any serious projects. It is also very likely that there will be breaking updates in the future, as a lot of the code is not finalized.
Examples




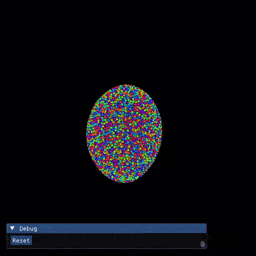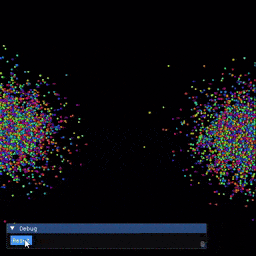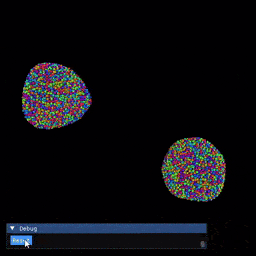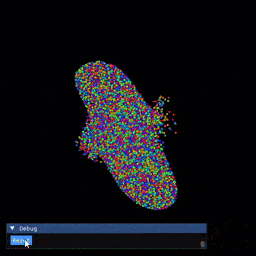
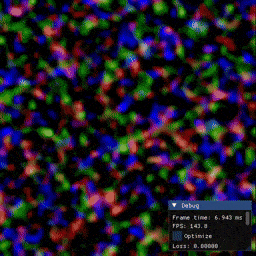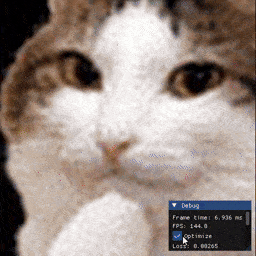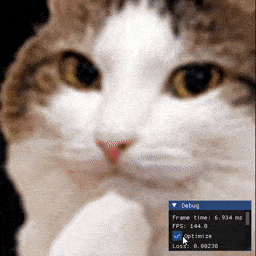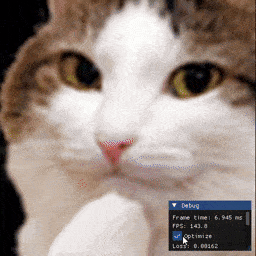
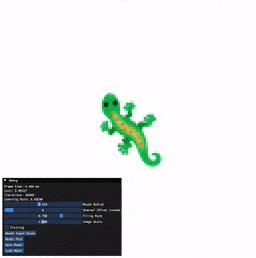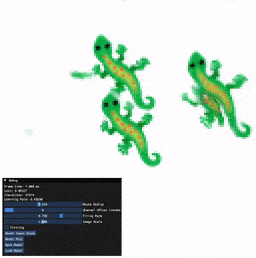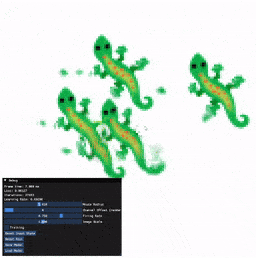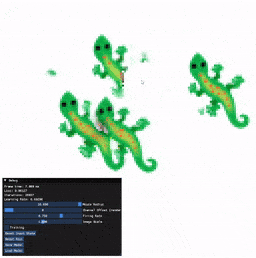
Installation
From PyPI
You can install the latest version of the library from PyPI:
pip install tensorfrost
From source
You need to have CMake installed to build the library.
First clone the repository:
git clone --recurse-submodules https://github.com/MichaelMoroz/TensorFrost.git
cd TensorFrost
Then you can either install the library for development.
py -$YOUR_PYTHON_VERSION$ -m pip install --upgrade pip setuptools wheel
py -$YOUR_PYTHON_VERSION$ -m pip install -e Python/ -v # install the library for development
This will link the build folder to Python, so any changes you make to the source code will be reflected in the installed library, in case of changed CPP code you need to rebuild the file library files using cmake --build . --config Release command, or by using any IDE.
You can also build a wheel file for distribution. This will create a wheel file in the dist folder.
py -$YOUR_PYTHON_VERSION$ -m pip wheel ./Python -w dist -v # build a wheel file
[!TIP] If you are using a Linux distribution that doesn't support installing packages through pip (e.g. Arch Linux), read Using a Virtual Environment.
Using a Virtual Environment
Certain Linux distributions (e.g. Arch Linux) want you to use their package manager to manage system-wide Python packages instead of pip. TensorFrost uses pip to install itself once built, so before running CMake you will need to activate a Virtual Environment.
-
From the TensorFrost directory, create a venv:
python -m venv ./venv
-
Activate the venv:
source venv/bin/activate
-
Now, you can use pip to install the library:
python -m pip install --upgrade pip setuptools wheel python -m pip install -e Python/ -v # install the library for development python -m pip wheel ./Python -w dist -v # build a wheel file
[!TIP] The newly-created venv is treated like a fresh Python installation, so you may need to reinstall any needed packages such as
numpy,matplotlib, andtqdmif you are trying out the examples.pipworks fine once the venv is active (e.g.pip install numpy).
Usage
Setup
For the library to work you need a C++ compiler that supports C++17 (Currently only Microsoft Visual Studio Compiler on Windows, and gcc on Linux)
First you need to import the library:
import TensorFrost as tf
Then you need to initialize the library with the device you want to use and the kernel compiler flags (different for each platform):
tf.initialize(tf.cpu) # or tf.opengl
TensorFrost will find any available MSVC(Windows) or GCC(Linux) compiler and use it to compile the main code and the kernels. In OpenGL mode the driver compiles the kernels. (TODO: compile the main code into python for faster compile times, MSVC is super slow, 1.5 seconds for a single function)
[!TIP] If you are compiling a large program it is useful to change the compilation flags to just "" to avoid the long compile times. Especially a problem on Windows.
tf.initialize(tf.opengl, "")
You can have TensorFrost in code generation mode instead (you cant run tensor programs here), it is much faster, but you would need to use the code manually afterwards:
tf.initialize(tf.codegen, kernel_lang = tf.hlsl_lang) # or tf.glsl_lang for OpenGL, or tf.cpp_lang for C++
After you compiled all the tensor programs you need, you can get all the generated code and save it to a file:
# Save all the compiled functions
cpp_header = tf.get_cpp_header()
all_main_functions = tf.get_all_generated_main_functions() #always in C++
with open('tensorfrost_main.cpp', 'w') as f:
f.write(cpp_header)
for func in all_main_functions:
f.write(func)
# Save all the compiled kernels
all_kernels = tf.get_all_generated_kernels() #depends on the kernel_lang
for i, kernel in enumerate(all_kernels):
with open('generated_kernels/kernel_{}.hlsl'.format(i), 'w') as f:
f.write(kernel)
Right now you cant just compile the code and run it, since it also requires a Kernel compiler and executor as well as memory manager for tensors. In the future I plan to add all the required functions for that too, for better portability.
Basic usage
Now you can create and compile functions, for example here is a very simple function does a wave simulation:
def WaveEq():
#shape is not specified -> shape is inferred from the input tensor (can result in slower execution)
u = tf.input([-1, -1], tf.float32)
#shape must match
v = tf.input(u.shape, tf.float32)
i,j = u.indices
laplacian = u[i-1, j] + u[i+1, j] + u[i, j-1] + u[i, j+1] - u * 4.0
v_new = v + dt*laplacian
u_new = u + dt*v_new
return v_new, u_new
wave_eq = tf.compile(WaveEq)
As you can see, inputs are not arguments to the function, but are created inside the function. This is because some inputs can be constrained by the shape of other inputs, and the shape of the input tensor is not known at compile time. You can give shape arguments to the input function, constants for exactly matching shapes, or -1 for any shape. If you want to constrain the shape of the input tensor, you need to get the shape of the other tensor and use it as an argument to the input function.
The tensor programs take and output tensor memory buffers, which can be created from numpy arrays:
A = tf.tensor(np.zeros([100, 100], dtype=np.float32))
B = tf.tensor(np.zeros([100, 100], dtype=np.float32))
Then you can run the program:
A, B = wave_eq(A, B)
As you can see the inputs are given to the compiled function in the same order as they are created in the function.
To get the result back into a numpy array, you can use the numpy property:
Anp = A.numpy
Operations
TensorFrost supports most of the basic numpy operations, including indexing, arithmetic, and broadcasting.
The core operation is the indexing operation, which is used to specify indices for accessing the tensor data. Depending on the dimensinality of the tensor there can be N indices. This operation is similar to numpy's np.ogrid and np.mgrid functions, but it is basically free due to fusion.
#can be created either from a provided shape or from a tensor
i,j = tf.indices([8, 8])
i,j = A.indices
For example i contains:
[[0, 0, 0, ..., 0, 0, 0],
[1, 1, 1, ..., 1, 1, 1],
[2, 2, 2, ..., 2, 2, 2],
...,
[7, 7, 7, ..., 7, 7, 7]]
And analogously for j.
These indices can then be used to index into the tensor data, to either read or write data:
#set elements [16:32, 16:32] to 1.0
i,j = tf.indices([16, 16])
B[i+16, j+16] = 1.0
#read elements [8:24, 8:24]
i,j = tf.indices([16, 16])
C = B[i+8, j+8]
Here we can see that the shape of the "computation" is not the same as the shape of the tensor, and one thread is spawned for each given index. Then all sequential computations of the same shape are fused into a single kernel, if their computaion is not dependent on each other.
When doing out-of-bounds indexing, the index is currently clamped to the tensor shape. This is required to avoid undefined behaviour, in the future I plan to give the user the option to specify the behaviour of out-of-bounds indexing.
You can also use the index_grid operation which is similar to numpy's np.meshgrid function and provides a grid of indices for each dimension:
p, k = tf.index_grid([0, i + 1], [m, n])
Which is equivalent to numpy's np.meshgrid function (only for ints with step 1 for now):
p, k = np.meshgrid(np.arange(0, m), np.arange(i + 1, n))
Slicing is still not implemented, as that would require better shape comparison for undefined shapes, without it, you would get a lot of errors where there should not be any.
Currently supported operations
All the default arithmetic operations are supported:
+, -, *, /, **, ==, !=, >, <, >=, <=, &, |, ~, neg
Note that the boolean operations and, or, not are not overloaded yet, and you should use &, |, ~ instead on boolean tensors. (Might be changed in the future)
Also there are these provided functions:
abs, sign, ceil, floor, round, frac, exp, exp2, log, log2, sqrt, rsqrt, rcp, sin, cos, tan, asin, acos, atan, sinh, cosh, tanh, reversebits, pow, atan2, modf, step, clamp, lerp, fma, smoothstep, select, const.
Additionally, you can use uint, int, float, bool to cast between types, and asuint, asint, asfloat, asbool to reinterpret the bits of the number.
If needed, you can copy a value with the copy operation which is useful as you can not assign a tensor to another tensor directly.
Random number generation
For random number generation you can either implement your own hashing function, or use the provided pcg32 hash.
#generate a random number between 0 and 1
value = tf.pcgf(seed)
#generate a random uint32 number
value = tf.pcg(seed)
Additionally, TensorFrost provides a random submodule with a set of functions for generating random numbers and shuffling indices.
#generate a random number between 0 and 1
value = tf.random.rand(shape, seed=seed)
#generate a random uint32 number
value = tf.random.randint(seed, max_value)
#generate a random normal number
value = tf.random.randn(shape, seed=seed)
#generate a pair of random normal numbers (more efficiently using the box-muller transform)
value1, value2 = tf.random.randn2(shape, seed=seed)
#generate a random normal number with the same shape as the input tensor
value = tf.random.randn_like(tensor, seed=seed)
#generate a random number with the same shape as the input tensor
value = tf.random.rand_like(tensor, seed=seed)
#generate a random permutation of the numbers from 0 to n
value = tf.random.permutation(n, seed=seed)
#generate a random shuffle of the input index value
new_idx = tf.random.shuffle(idx, n, seed=seed, iters=16)
TensorFrost does not have a built-in seed, so its similar to JAX where you need to provide your own seed. This is useful for reproducibility, as you can just provide the same seed to the program and get the same results.
Scatter operations
These operations allow implementing non-trivial reduction operations, and are basically equivalent to atomics in compute shaders. For example, here is a simple example of a scatter operation:
def ScatterMatrixMultiplication():
A = tf.input([-1, -1], tf.float32)
N, M = A.shape
B = tf.input([M, -1], tf.float32) #M must match
K = B.shape[1]
C = tf.zeros([N, K])
i, j, k = tf.indices([N, K, M])
tf.scatterAdd(C[i, j], A[i, k] * B[k, j])
return C
matmul = tf.compile(ScatterMatrixMultiplication)
Here the 3D nature of the matrix multiplication is apparent. The scatter operation is used to accumulate the results of the row-column dot products into the elements of the resulting matrix.
The compiler will optimize the scatter operation into a loop in this particular case, so this will not be too slow, but you should prefer to just use A @ B for matrix multiplication.
Reduction operations
Reduction operations are used to reduce the tensor data along one dimension. For example, here is a simple example of a sum reduction:
def MatrixMultiplication():
A = tf.input([-1, -1], tf.float32)
N, M = A.shape
B = tf.input([M, -1], tf.float32) #M must match
K = B.shape[1]
i, j, k = tf.indices([N, K, M])
C = tf.sum(A[i, k] * B[k, j], axis=2) #by default axis is -1 (last axis)
return C
matmul = tf.compile(MatrixMultiplication)
Here the sum operation is used to sum the dot products of the rows and columns of the input matrices along the k axis.
The following reduction operations are supported: sum, mean, max, min, all, any, prod and norm
In the future I plan to add support for multiple reduction axes.
[!TIP] If the shape is specified explicitly, for reductions >= 1024 elements, the reduction will be split into stages and will have much better performance.
Scan operations
Right now only prefix_sum is supported (numpy's np.cumsum).
An automatic optimization pass that does staged prefix sum is planned for the future, but right now you can use:
def PrefixSum(A, axis = -1):
axis = len(A.shape) + axis if axis < 0 else axis
group_size = 64
grouped = tf.split_dim(A, group_size, axis)
group_scan = tf.prefix_sum(tf.sum(grouped, axis = axis + 1), axis = axis)
ids = grouped.indices
gid, eid = ids[axis], ids[axis + 1]
ids = [ids[i] for i in range(len(ids)) if i != axis + 1]
ids[axis] = gid - 1
group_scan = tf.prefix_sum(grouped + tf.select((gid == 0) | (eid != 0), 0, group_scan[tuple(ids)]), axis = axis + 1)
full_scan = tf.merge_dim(group_scan, target_size = A.shape[axis], axis = axis + 1)
return full_scan
Sorting operations
Sort is not yet built-in the library, but you can use a custom implemented one from the sorting test in examples folder. There is a relatively optimized histogram radix sort as well as a simple bitonic sort.
Broadcasting
Broadcasting is used to make the shapes of the input tensors compatible. For example, here is a simple example of a broadcasting operation:
def Broadcasting():
A = tf.input([1, 3], tf.float32)
B = tf.input([3, 1], tf.float32)
C = A + B
return C
Here the + operation is used to add the two input tensors. The shapes of the input tensors are [1, 3] and [3, 1], and the shape of the output tensor is [3, 3]. The + operation is broadcasted over the input tensors, and the result is a tensor with the shape [3, 3].
The rules are the same as in numpy essentially.
Reshape
Reshape operation is used to change the shape of the tensor. For example, here is a simple example of a reshape operation:
def Reshape():
A = tf.input([2, 3], tf.float32)
B = tf.reshape(A, [3, 2])
return B
Here the reshape operation is used to change the shape of the input tensor from [2, 3] to [3, 2].
At the moment this is implemented in a very crude way, so doing this will always halt kernel fusion, so use it only when you are sure things are unfusable
(usually at the beginning or end of the program).
Additionally, you can also use transpose, unsqueeze and squeeze operations to change the shape of the tensor, which work fine with fusion.
def Transpose():
A = tf.input([2, 3], tf.float32)
B = tf.transpose(A) #shape is [3, 2]
C = B.T #shape is [2, 3]
return C
def Unsqueeze():
A = tf.input([2, 3], tf.float32)
B = tf.unsqueeze(A, 1) #shape is [2, 1, 3]
return B
Additionally there are merge_dim and split_dim operations that can be used to merge or split dimensions of the tensor.
A = tf.input([2, 3, 4], tf.float32)
B = tf.merge_dim(A, axis = 1) #shape is [2, 12]
A = tf.input([2, 12], tf.float32)
B = tf.split_dim(A, 4, axis = 1) #shapes are [2, 3, 4]
[!TIP] If you want the compiler to be able to merge kernels with reshape, you should try using
merge_dimandsplit_diminstead.
Matrix operations
Matrix operations are used to perform matrix operations on the tensor data. For example, here is a simple example of a matrix multiplication:
def MatrixMultiplication():
A = tf.input([-1, -1], tf.float32)
N, M = A.shape
B = tf.input([M, -1], tf.float32) #M must match
C = tf.matmul(A, B) #or A @ B
return C
matmul = tf.compile(MatrixMultiplication)
A = tf.tensor(np.zeros([100, 100], dtype=np.float32))
B = tf.tensor(np.zeros([100, 100], dtype=np.float32))
C = matmul(A, B)
Here the matmul operation is used to multiply the input matrices A and B. The shapes of the input tensors are [N, M] and [M, K], and the shape of the output tensor is [N, K].
The inputs can have any shape of the form [A, B, ..., N, M], and as long as they are broadcastable, the operation will work.
Loops and conditionals
#Mandelbrot set
z_re = tf.const(0.0)
z_im = tf.const(0.0)
with tf.loop(128) as k: #or tf.loop(0, 128) for a range loop, or tf.loop(0, 128, 2) for a range loop with step
z_re_new = z_re*z_re - z_im*z_im + c_re
z_im_new = 2.0*z_re*z_im + c_im
z_re.val = z_re_new
z_im.val = z_im_new
with tf.if_cond(z_re*z_re + z_im*z_im > 256.0):
tf.break_loop()
Scopes in TensorFrost are implemented through python context managers. There are tf.loop and tf.if_cond context managers that can be used to create loops and conditionals. The loop context manager takes the number of iterations as an argument, and the if_cond context manager takes a condition as an argument. The condition can be any tensor operation that returns a boolean tensor.
Also since the setting operation can not be overloaded in python, the set method must be used to update the tensor data outside of this scope, or alternatively the val property can be used to set the value of the tensor.
z_re = tf.const(0.0)
with tf.loop(128):
z_re.set(z_re_new) #this is fine
z_re.val = z_re_new #this is also fine
z_re = z_re_new #this is not fine
Just setting the tensor to a new value will actually create a new tensor on top of the old one, and the old one will not be updated.
Loops and conditionals can be stacked and nested. Usually they are compiled into a single kernel with the scopes inside it, but they can be compiled into separate kernels if the data dependencies are not local (look at the QR decomposition example in the examples folder). Not all possible loop and conditional can be valid here, if the loop iteration count has a shape incompatible with the shapes of the tensors in the loop body, the program will not compile correctly.
PS: You can also provide a function instead of using a context manager, but it is not recommended, as it is less readable.
def loop_body(k):
z_re_new = z_re*z_re - z_im*z_im + c_re
z_im_new = 2.0*z_re*z_im + c_im
z_re.val = z_re_new
z_im.val = z_im_new
with tf.if_cond(z_re*z_re + z_im*z_im > 256.0):
tf.break_loop()
tf.loop(0, 128, 1, loop_body)
Autodifferentiation
Currently only backward mode autodifferentiation is supported, and can not properly be applied at control flow operations.
y_pred = x @ W + b
loss = tf.mean((y - y_pred)**2)
dW = tf.grad(loss, W)
db = tf.grad(loss, b)
In this example, the grad function is used to compute the gradients of the loss with respect to the weights W and the bias b. If the gradient is taken from the same "loss" tensor, the compiler will still only do one backward pass. At the moment doing gradients from gradients might not work correctly.
Additionally, if the loss is not a scalar, the initial gradient tensor will be assumed to be the same shape as the loss tensor and equal to 1.0. For most cases this is quite useful, as you can compute the gradients of multiple outputs at the same time, as long as they are not dependent on each other. Like doing a gradient of a potential for N particles at the same time.
dx = x1 - x2
dist = tf.sqrt(tf.sum(dx**2))
pot = 1.0 / dist
force = - tf.grad(pot, dx)
In this example, the grad function is used to compute the gradient of the potential with respect to the distance between two particles. The force is then computed as the negative gradient of the potential with respect to the distance.
You can also stop the gradient computation for some tensors by tensor.detach_grad(). In that case the autograd algorithm will stop at this tensor.
Or if you want to force the gradient through a operation without applying the operation gradient you can do tensor.pass_grad(). This is useful for example when you want to optimize discrete parameters like a quantized weight.
Registering new operations
You can register a new operation with a custom vector jacobian product (VJP) like this:
def custom_op(inputs, tensor, axes):
return [tf.tanh(inputs[0])]
def custom_op_vjp(inputs, gradient, tensor):
return [gradient * (1.0 - tensor * tensor)]
tf.register_custom_operation("new_tanh", ["f_f"], custom_op, custom_op_vjp)
The first argument is the name of the operaiton. The second argument is the list of overloads, that are defined like "xyz_a", where xyz can be any of f, b, u, i for float, boolean, uint, and int types of the input arguments, and a is the output type. The third a fourth argument are the operation implementation and its VJP. This function is used at the "insert algorithmic primitives" stage.
The first function has arguments: list of input arguments, the original custom operation tensor, and the value passed as axes in the custom operation.
The second function also has: list of input arguments, the gradient tensor, and the original custom operation tensor result. This function is used in the "autodiff" stage.
The registered function can then be used like this:
def ProgramTest():
A = tf.input([-1],tf.float32)
B = tf.custom("new_tanh", [A])
dB_dA = tf.grad(B, A)
return B, dB_dA
Registering custom functions can be useful when having a computation which can not be automatically differentiated, or if the automatically generated gradient is of poor quality.
Modules
TensorFrost has a simple module system similar to PyTorch, where you can define a module with trainable parameters and a forward function that computes the output of the module as well as a loss function.
class SmolNet(tf.Module):
def __init__(self):
#specify a custom random scale and offset for the weights when initializing
self.W = tf.Parameter([16, -1], tf.float32, random_scale=0.01, random_offset=0.0)
#dont compute gradients for the bias
self.b = tf.Parameter([-1], tf.float32, optimize=False)
def assert_parameters(self):
#makes sure that the compiler knows that b has shape compatible with W
self.b = tf.assert_tensor(self.b, [self.W.shape[1]], tf.float32)
def forward(self, x):
return x @ self.W + self.b
def loss(self, x, y):
y_pred = self.forward(x, y)
return tf.mean((y - y_pred)**2)
When initializing the module you can add 3 types of TensorFrost accessible parameters:
tf.Parameter- a tensor that will be passed to the TensorProgram as an argumenttf.ParameterArray- a dynamic list of parameters, all of them will be passed to the TensorProgram as argumentstf.Module- another module, all of its parameters will be passed to the TensorProgram as arguments
The shape argument of the parameter can be a list of integers, where -1 means that the shape is not specified yet, and will be inferred from the input tensor. If you need to compute an operation over several tensors of unspecified shape, you need to assert the shapes in the assert_parameters function.
random_scale and random_offset are used to initialize the weights with random values, and are optional, by default the weights are initialized with Xavier initialization for normal random values.
optimize is used to specify if the parameter should be trained or not, by default all parameters are trainable. This argument does not stop you from computing tf.grad manually, it is just used to specify if the parameter should be updated by the optimizer module.
By itself the module does not do anything, you need to do a second initialization step to either use it inside a TensorProgram, or initialize it as a container for the tensors outside of the program.
def ComputeForward():
model = SmolNet()
#creates tf.input tensors from all the parameters of the module
model.initialize_input()
X = tf.input([-1, -1], tf.float32)
return model.forward(X)
forward = tf.compile(ComputeForward)
model_container = SmolNet()
#creates tf.tensor tensors from all the parameters of the module and initializes them
model_container.initialize_parameters()
#you can change them afterwards too
model_container.W = tf.tensor(np.zeros([16, 100], dtype=np.float32))
X = tf.tensor(np.zeros([100, 100], dtype=np.float32))
#the module is passed as an argument to the compiled function, in the same order as they are created in the function
Y = forward(model_container, X)
model.initialize_input() creates put tf.input() tensors for all the parameters of the module. Afterwards assert_parameters is automatically called for this and all child modules. This is useful if you want to use the module inside a TensorProgram, as you can just pass the module as an argument to the compiled function, and all the parameters will be automatically created and the shapes will be asserted.
model.initialize_parameters() creates tf.tensor() tensors for all the parameters of the module and initializes them with random values. This is useful if you want to use the module outside of a TensorProgram, as you can just pass the module as an argument to the compiled function.
You can not, however, do both at the same time, as the module will not know if it is used inside or outside of a TensorProgram.
Optimizer modules
TensorFrost has a set of built-in optimizer modules that can be used to train the parameters of the module.
tf.optimizers.sgd- Stochastic Gradient Descent, has alearning_rateandgrad_clipparameters, default values are 0.001 and 0.0 respectively.tf.optimizers.adam- Adam optimizer, has alearning_rate,beta1,beta2andgrad_clipparameters, default values are 0.001, 0.9, 0.999 and 0.0 respectively.tf.optimizers.rmsprop- RMSProp optimizer, has alearning_rate,decayandgrad_clipparameters, default values are 0.001, 0.9 and 0.0 respectively.
All optimizer modules are initialized with the module as the first argument, and the training hyperparameters as the rest of the arguments.
def OptimizerStep():
X = tf.input([-1, -1], tf.float32)
Y = tf.input([-1, 10], tf.float32)
model = SmolNet()
opt = tf.optimizers.adam(model, learning_rate=0.001, beta1=0.9, beta2=0.999)
opt.initialize_input()
#do a single step of the optimizer (automatically computes gradients and updates the parameters)
L = opt.step(X, Y)
#or
#L = model.loss(X, Y)
#opt.step(L)
params = opt.parameters()
params.append(L)
return params
step = tf.compile(OptimizerStep)
model_container = SmolNet()
opt = tf.optimizers.adam(model_container)
opt.initialize_parameters()
X = tf.tensor(np.zeros([100, 100], dtype=np.float32))
Y = tf.tensor(np.zeros([100, 10], dtype=np.float32))
out = step(X, Y, opt)
opt.update_parameters(res[:-1])
loss = res[-1].numpy[0]
Outputting the optimizer state is somewhat inconvenient at the moment, as you can only output a list of tensors from the compiled function, so you need to append the loss to the list of parameters and then extract it from the list afterwards. The optimizer state is not saved in the module, so you need to pass it as an argument to the compiled function, and then update the parameters of the module with the updated parameters from the optimizer.
Optionally you can also enable regularization for the parameters of the module, by specifying the l1 and l2 regularization parameters in the initialize_parameters function. This will apply regularization to the parameters after the optimizer step, meaning the adam optimizer will behave like adamw optimizer.
optimizer = tf.optimizers.adam(model_container, beta1 = 0.0, beta2 = 0.999, reg_type = tf.regularizers.l2, reg = 0.02, clip = 0.01)
optimizer.set_clipping_type(tf.clipping.norm)
You can also specify the clipping type for the gradients, by default the value of clip is zero which turns it off. The clipping type can be tf.clipping.norm or tf.clipping.clamp.
Debugging
For debugging convenience there are 2 function types that you can call inside a tensor program:
tf.renderdoc_start_capture()
tf.renderdoc_end_capture()
These functions will start and end a RenderDoc capture, only if python is started from the RenderDoc GUI. This is useful for debugging the OpenGL backend, as it allows you to inspect compiled kernel execution, its code and buffers.
tf.region_begin('Region name')
tf.region_end('Region name')
When debugging from RenderDoc (or any other OpenGL debugger), these functions will create a region in the RenderDoc capture, which can be useful for profiling and seeing what parts of the program are slow. The placement of these functions might not reflect their position in the code, as the code is heavily optimized and fused, so if you placed a region in the middle of a generated kernel, it will be placed at the beginning or end of the kernel. Placing them in a scoped operation might make the compilation fail or unfuse kernels, so be careful with that.
To debug the generated code you can either look at the generated code in the Temp folder with tf.cpu backend enabled if you need kernel code. If you want to debug the GPU kernel code, you can use RenderDoc.
[!TIP] You can print out tensors at compilation time in the main function by just doing
print(tensor). This will output its debug information, its shape, its data type, what operation it is, shape (inverted), its arguments, etc.
If you want to print out the tensor data at runtime, you can use the tf.print_value(string, tensor_val) function, which will print out the tensor data to the console, only if the value is scalar.
You can also have an assertion that will throw an error if the boolean scalar tensor value is false, with the tf.assert_value(string, tensor_val) function.
Custom kernels
You can also write custom "kernel" scopes which are guaranteed to be compiled to a single kernel. You can use special low level shader features like groupshared memory and barriers in these scopes. At the moment barriers only work correctly on GPU backends.
def FasterMatmul():
A = tf.input([-1, -1], tf.float32)
N, M = A.shape
B = tf.input([M, -1], tf.float32)
K = B.shape[1]
C = tf.buffer([N, K], tf.float32)
BK = 32
with tf.kernel(C.shape, group_size=[BK,BK]) as (i, j):
A_tile = tf.group_buffer(BK*BK, tf.float32)
B_tile = tf.group_buffer(BK*BK, tf.float32)
tx = i.block_thread_index(1)
ty = i.block_thread_index(0)
result = tf.const(0.0)
with tf.loop(0, K, BK) as blk:
A_tile[tx * BK + ty] = A[i, ty + blk]
B_tile[tx * BK + ty] = B[tx + blk, j]
tf.group_barrier()
with tf.loop(BK) as k:
result.val += A_tile[tx * BK + k] * B_tile[k * BK + ty]
tf.group_barrier()
C[i, j] = result.val
return C
Here is an example of a tiled matrix multiplication kernel. The tf.kernel context manager is used to create a custom kernel scope. The first argument is the shape of the kernel compute, the second argument is the group size, which is optional, if its not specified it will automatically estimated from the kernel shape. The group_size argument is used to specify the size of the thread group, and the block_thread_index method is used to get the thread index in the group. The group_barrier method is used to wait for all threads in the group to reach the barrier.
If the dimension count of the group shape is less than the kernel it will only make the group based on the last dimensions. Only up to 3D groups are supported. The automatic group shape estimation can make an up to 3d group with number of thread <= 1024. If the shape of the kernel is small, the group shape will match the kernel shape of those dimensions.
You can define groupshared memory buffers with the tf.group_buffer function. The first argument is the size of the buffer, and the second argument is the data type of the buffer. You must use a barrier if you want to exchange data between threads in the groupshared memory.
You can also define local memory arrays with tf.local_buffer, which works the same as tf.group_buffer, but is local to the thread.
[!TIP] To check if you are currently with a CPU backend you can do
tf.current_backend() == tf.cpu
GUI and visualization
TensorFrost has simple bindings for the GLFW window library, and some ImGui bindings for GUI. You can render tensors as images (only [-1, -1, 3] float32 tensors for now) and display them in a window. You can also use ImGui to create simple GUIs for your programs. Do note that this only works in the OpenGL backend.
#creates a single global window (can only be one at the moment)
tf.window.show(1280, 720, "a window")
while not tf.window.should_close(): #window will close if you press the close button and this will return True
mx, my = tf.window.get_mouse_position()
wx, wy = tf.window.get_size()
#simple input example
if tf.window.is_mouse_button_pressed(tf.window.MOUSE_BUTTON_0):
tf.imgui.text("Mouse button 0 is pressed")
if tf.window.is_key_pressed(tf.window.KEY_W):
tf.imgui.text("W is pressed")
#ImGui example
tf.imgui.begin("an imgui window")
tf.imgui.text("some text")
value = tf.imgui.slider("slider", value, 0.0, 10.0)
if(tf.imgui.button("a button")):
print("button pressed")
tf.imgui.end()
#exectute a tensorfrost program that outputs a [-1, -1, 3] float32 tensor
img = render_image(...)
#display the image (will be stretched to the window size with nearest neighbor interpolation)
tf.window.render_frame(img)
Currently provided window submodule functions are:
show(width, height, title)- creates a windowhide()- hides the windowshould_close()- returnsTrueif the window should closeget_mouse_position()- returns the mouse positionget_size()- returns the window sizeis_mouse_button_pressed(button)- returnsTrueif the mouse button is pressedis_key_pressed(key)- returnsTrueif the key is pressedrender_frame(tensor)- renders the tensor as an image
Currently provided imgui submodule functions are:
begin(name)- begins an ImGui windowend()- ends an ImGui windowtext(text)- displays textslider(name, value, min, max)- displays a sliderbutton(text)- displays a button, returnsTrueif the button is pressedcheckbox(text, value)- displays a checkboxplotlines(label, values, values_offset, overlay_text, scale_min, scale_max, graph_size, stride)- displays a plotscale_all_sizes(scale)- scales all ImGui sizes by a factoradd_background_text(text, pos, color)- adds background text at the specified position with the specified color
Usage tips
-
Using an explicit shape for the input tensors can help the compiler to optimize the program better, as it can infer the shapes of the tensors in the program better. On top of that some optimizations like loop unrolls or staged reductions only happen if the shape is known at compile time.
-
Large matrix multiplications are currently very much not optimized, as the compiler does not use groupshared memory or any other optimizations for matrix multiplication. This is planned for the future. For now using TensorFrost mostly makes sense for small to medium sized architectures where cache hits are high.
-
Complex operations like convolutions can be implemented through sum + indexing operaitons, example below (taken from here)
While this might seem less optimal than a hand optimized convolution kernel especially when computing its gradient, but it is much more flexible and is actually optimized quite well by the compiler. While the gradient of the indexing operations is an atomicAdd operation, in this case, several of the dimensions of the gradient kernel are not used in the index of the tensors, and get unrolled into sums removing the atomics from the kernel. In such a way you can implement any operation you want, even matrix multiplication works fine (
tf.sum(A[i, k] * B[k, j])), and the compiler will optimize it and its gradient quite well. Not all atomics will get optimized out however, so be careful when taking gradients of indexed tensors, as the current atomicAdd for floats is an emulated operation and is can get extremely slow with high write contention.
def conv2d(self, X, W, b):
bi, wi, hi, cout, cin, it = tf.indices([X.shape[0], X.shape[1] - W.shape[2] + 1, X.shape[2] - W.shape[3] + 1, W.shape[0], W.shape[1], W.shape[2] * W.shape[3]])
i, j = it%W.shape[2], it/W.shape[2]
conv = tf.sum(tf.sum(X[bi, wi + i, hi + j, cin] * W[cout, cin, i, j]))
return conv + b
- Inplace operation gradients simply don't work, even though it does compile, the gradients are not computed correctly. This is planned to be fixed in the future.
- You can check the compiled code in the Temp folder in
generated_lib_*.cppfiles, it is not very readable, but you can see the operations and the memory allocations, the kernel code is in the same file, only on CPU backend.
Roadmap
Core features:
- Basic operations (memory, indexing, arithmetic, etc.)
- Basic kernel fusion and compilation
- Advanced built-in functions (random, special functions, etc.)
- Advanced operations (loops, conditionals, etc.)
- Kernel code and execution graph export and editing
- Backward mode autodifferentiation
- Module system
- Optimizer modules (SGD, Adam, RMSProp)
- GUI and visualization
- Compiled
TensorProgramexport and import - Forward mode autodifferentiation
- Gradients of control flow operations and gradients from gradients
- Advanced data types and quantization
- Compile from Python AST instead of tracing
- Groupshared and local memory support (no CPU yet)
- Automatic data caching and reuse
Algorithm library:
- Scan, reduction, etc.
- Module system
- Optimizer modules (SGD, Adam, RMSProp)
- Matrix operations (matrix multiplication, etc.)
- Sorting algorithms (module partially done, no autodiff support yet)
- Advanced matrix operations (QR, SVD, eigenvalues, etc.) (some examples already in the examples folder)
- Fast Fourier Transform (some examples already in the examples folder)
- High-level neural network layers (convolution, etc.) (some examples already in the examples folder)
Platforms:
- Windows
- Linux
- MacOS
Backends:
- CPU (C++ OpenMP backend)
- OpenGL (most basic GPU backend, has a lot of driver bugs)
- CUDA
- Vulkan
- ISPC (for better CPU utilization)
- WGPU (for web)
Contributing
Contributions are welcome! If you want to contribute, please open an issue first to discuss the changes you want to make.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distributions
Built Distributions
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file tensorfrost-0.7.3-cp314-cp314-win_amd64.whl.
File metadata
- Download URL: tensorfrost-0.7.3-cp314-cp314-win_amd64.whl
- Upload date:
- Size: 1.8 MB
- Tags: CPython 3.14, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.14.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
583485f5e3eb88d3ac7f3b36091b0aec085057133e52a83609f2f74d0516453b
|
|
| MD5 |
8030f6240a4f7af5992861fd10259f76
|
|
| BLAKE2b-256 |
c1bc38321fb4d322449b2c1e2e9734023f1044304de4689ceec0abc90bb03a3d
|
File details
Details for the file tensorfrost-0.7.3-cp314-cp314-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl.
File metadata
- Download URL: tensorfrost-0.7.3-cp314-cp314-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl
- Upload date:
- Size: 1.9 MB
- Tags: CPython 3.14, manylinux: glibc 2.27+ x86-64, manylinux: glibc 2.28+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.14.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
1e87794a454187d6e28d02a0365a1f18fbfeed331c5d60985246937361a00e41
|
|
| MD5 |
5b6ce8a3c890e59f5bdff7168379dcd4
|
|
| BLAKE2b-256 |
4bbfbd507faccc552264edea2c1a1fa95f01efdde26ac1e385e32ae5b7851830
|
File details
Details for the file tensorfrost-0.7.3-cp314-cp314-macosx_15_0_arm64.whl.
File metadata
- Download URL: tensorfrost-0.7.3-cp314-cp314-macosx_15_0_arm64.whl
- Upload date:
- Size: 1.3 MB
- Tags: CPython 3.14, macOS 15.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.14.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ef2902253fb809e89e42717e6b0262041c669675fd911f3fedcf940e34c00c52
|
|
| MD5 |
bcbd59176604dae8d64ac2d526e4c326
|
|
| BLAKE2b-256 |
c409db9673d55d0ee9dbf1b02b99f1120112c86c6cfe4e3e121d43a7eb6012f8
|
File details
Details for the file tensorfrost-0.7.3-cp313-cp313-win_amd64.whl.
File metadata
- Download URL: tensorfrost-0.7.3-cp313-cp313-win_amd64.whl
- Upload date:
- Size: 1.8 MB
- Tags: CPython 3.13, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
823fb9620c4b76b2281ae38c606da9f3e3093239c4d677c4ea0d21ba340d99d9
|
|
| MD5 |
7a08e78f61b2701128326c44e817112e
|
|
| BLAKE2b-256 |
4344ca4a92ef5d25327d380616e4f7c6dca6c1ca525e460347a2908a8c10ae5a
|
File details
Details for the file tensorfrost-0.7.3-cp313-cp313-manylinux_2_28_x86_64.whl.
File metadata
- Download URL: tensorfrost-0.7.3-cp313-cp313-manylinux_2_28_x86_64.whl
- Upload date:
- Size: 1.9 MB
- Tags: CPython 3.13, manylinux: glibc 2.28+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6ccc3cbb8b522d7f3b0d06178313f88b9c4c6d4ab1907b1b759cc24eaaa8ee99
|
|
| MD5 |
822dda5197ed3b0325b1c2f56212acae
|
|
| BLAKE2b-256 |
e01f8de16d1b43a7fa4c7069b38f6226bde1b7df57c5e50e8aab85196b412490
|
File details
Details for the file tensorfrost-0.7.3-cp313-cp313-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl.
File metadata
- Download URL: tensorfrost-0.7.3-cp313-cp313-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl
- Upload date:
- Size: 1.9 MB
- Tags: CPython 3.13, manylinux: glibc 2.27+ x86-64, manylinux: glibc 2.28+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.14.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
16f75fd0785c5c9f6e13b8bd0ee206d7c115563b1f48ba42f0540ce8806f3181
|
|
| MD5 |
eb12d6d7f884fb1c990bdd05d3149369
|
|
| BLAKE2b-256 |
61938cbe79e89c59f8c936b2a8b632f81c948424e4082a1947ee7f62951c60c1
|
File details
Details for the file tensorfrost-0.7.3-cp313-cp313-macosx_15_0_arm64.whl.
File metadata
- Download URL: tensorfrost-0.7.3-cp313-cp313-macosx_15_0_arm64.whl
- Upload date:
- Size: 1.3 MB
- Tags: CPython 3.13, macOS 15.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.14.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
310322f50f37c4b936c6dcc2ec2741e0d3dc6ebb15ef2f4fefe69d04df096165
|
|
| MD5 |
a16ed3d5b9b66c071b54198be682b27c
|
|
| BLAKE2b-256 |
c2c7c196e1b526d977b89847eea3559b565d7813ee2b62acc759b2a9191aaa15
|
File details
Details for the file tensorfrost-0.7.3-cp313-cp313-macosx_14_0_arm64.whl.
File metadata
- Download URL: tensorfrost-0.7.3-cp313-cp313-macosx_14_0_arm64.whl
- Upload date:
- Size: 1.3 MB
- Tags: CPython 3.13, macOS 14.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ac219628046e4cc80d29b4f4f9267d8f5cb9fc8a9e4daebbd713d13817c3c0f2
|
|
| MD5 |
65e473dafca39fd19462036d681ea078
|
|
| BLAKE2b-256 |
b33e529fabb28c21fcb626589f736f796c9417b8c89901b79345c7b67b8d28d4
|
File details
Details for the file tensorfrost-0.7.3-cp312-cp312-win_amd64.whl.
File metadata
- Download URL: tensorfrost-0.7.3-cp312-cp312-win_amd64.whl
- Upload date:
- Size: 1.8 MB
- Tags: CPython 3.12, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
2252c8df7e4ea823b4f5bd530d3afcd08abfe0197968e23782eb7f38c73d5a61
|
|
| MD5 |
c87707912882569dfcf25b3e65429872
|
|
| BLAKE2b-256 |
f81d3cdee485b19d11eabf0651db1943b33aa987f4f7bee9927fb8b30df76af8
|
File details
Details for the file tensorfrost-0.7.3-cp312-cp312-manylinux_2_28_x86_64.whl.
File metadata
- Download URL: tensorfrost-0.7.3-cp312-cp312-manylinux_2_28_x86_64.whl
- Upload date:
- Size: 1.9 MB
- Tags: CPython 3.12, manylinux: glibc 2.28+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c4c92bdf2b117973726a24252336b40b935e62e11e4db93fbd96e2cde3c3702a
|
|
| MD5 |
0205b88975777b0f1414e511b429aba6
|
|
| BLAKE2b-256 |
079b1208d3c555f96b2e1e96d2bb6ed290a28cf36a204349a9b674a1a2876270
|
File details
Details for the file tensorfrost-0.7.3-cp312-cp312-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl.
File metadata
- Download URL: tensorfrost-0.7.3-cp312-cp312-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl
- Upload date:
- Size: 1.9 MB
- Tags: CPython 3.12, manylinux: glibc 2.27+ x86-64, manylinux: glibc 2.28+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.14.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a8067d4e772fdb7bece0ad224a9c1b522f862125f34fd763d234e8a0407573f5
|
|
| MD5 |
2d41b77e6fa911ff86f6071be8fd2e78
|
|
| BLAKE2b-256 |
76c6d07fb153b8556d789e61f2e75a0a15ef646a7303115dab6c8b3f34f847c3
|
File details
Details for the file tensorfrost-0.7.3-cp312-cp312-macosx_15_0_arm64.whl.
File metadata
- Download URL: tensorfrost-0.7.3-cp312-cp312-macosx_15_0_arm64.whl
- Upload date:
- Size: 1.3 MB
- Tags: CPython 3.12, macOS 15.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.14.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
afbbe9c129720d54ea2972306508e4ed8312441e67431cff12fd5e6537e30a39
|
|
| MD5 |
a8509f2325ea5fc5908e6a37c6997c7a
|
|
| BLAKE2b-256 |
0b6c2cd031246896ef8fc7d83faf22758e43f42ad51e9b730e7ebdc7ba5fc9cc
|
File details
Details for the file tensorfrost-0.7.3-cp312-cp312-macosx_14_0_arm64.whl.
File metadata
- Download URL: tensorfrost-0.7.3-cp312-cp312-macosx_14_0_arm64.whl
- Upload date:
- Size: 1.3 MB
- Tags: CPython 3.12, macOS 14.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
dadd45ed743506435988aa5376bfc0740cdc74f614863cb4286bebfea58c2ce4
|
|
| MD5 |
e1d3fe4c23526485d07651d388818012
|
|
| BLAKE2b-256 |
39dcb9a15aa1ed0fc879198aa23c7db8cf224c784067c4bdc3ada90277a45c8e
|
File details
Details for the file tensorfrost-0.7.3-cp311-cp311-win_amd64.whl.
File metadata
- Download URL: tensorfrost-0.7.3-cp311-cp311-win_amd64.whl
- Upload date:
- Size: 1.7 MB
- Tags: CPython 3.11, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
704dafe71f871783ee0fee2f02b0222e2ebc96211d1f408222a5399fb901be0d
|
|
| MD5 |
d9723e8670506f21bee7d5beb0311fd9
|
|
| BLAKE2b-256 |
ce9da74f62fecb341a48e999494df6468cafd30d2df0ceb9bbc54e20c5e238d4
|
File details
Details for the file tensorfrost-0.7.3-cp311-cp311-manylinux_2_28_x86_64.whl.
File metadata
- Download URL: tensorfrost-0.7.3-cp311-cp311-manylinux_2_28_x86_64.whl
- Upload date:
- Size: 1.9 MB
- Tags: CPython 3.11, manylinux: glibc 2.28+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a10dd6252ade6d4f682b730e603bbace28aa2d3eaa58bff91dc11c8626818572
|
|
| MD5 |
17078ff65d6d970b5ccfc090f97fb465
|
|
| BLAKE2b-256 |
2b5b4b233b56ca5a7876e065c2f9b5adf772e49ceb6ddd87bd9fd622a7719d2f
|
File details
Details for the file tensorfrost-0.7.3-cp311-cp311-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl.
File metadata
- Download URL: tensorfrost-0.7.3-cp311-cp311-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl
- Upload date:
- Size: 1.9 MB
- Tags: CPython 3.11, manylinux: glibc 2.27+ x86-64, manylinux: glibc 2.28+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.14.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8c60f9d3e419cc80010deda68d7d11985c6bbc4bcbf760f25a18f948cbf44fe3
|
|
| MD5 |
23c5fbe2f2b9feb9b8863deeae2c9147
|
|
| BLAKE2b-256 |
d900988c1dded08805b55c0b41b0b365d5dc529517cc3f55d14d188cf3ea8f71
|
File details
Details for the file tensorfrost-0.7.3-cp311-cp311-macosx_15_0_arm64.whl.
File metadata
- Download URL: tensorfrost-0.7.3-cp311-cp311-macosx_15_0_arm64.whl
- Upload date:
- Size: 1.3 MB
- Tags: CPython 3.11, macOS 15.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.14.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c58d07f804c7dfb5110376ee72a8ba883393efbb739f0b44f03bdaf29fa90b86
|
|
| MD5 |
425901d952bad616018c1465e0d2e74e
|
|
| BLAKE2b-256 |
d5c8ab1e85d59fa656afa0d580b4a85c3dd3924bb081d935b3bc2632eb8571d5
|
File details
Details for the file tensorfrost-0.7.3-cp311-cp311-macosx_14_0_arm64.whl.
File metadata
- Download URL: tensorfrost-0.7.3-cp311-cp311-macosx_14_0_arm64.whl
- Upload date:
- Size: 1.3 MB
- Tags: CPython 3.11, macOS 14.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ad0d26c970279982ef78f58690c3bb3ec02ed6f19c267c411c3ba6b96a984753
|
|
| MD5 |
6290c36d0cdc6f9fe497d7fcfeef2ba9
|
|
| BLAKE2b-256 |
fb33c2137756ef4991a4c704e53e3f5be0760583ce9e8c53672e9fb7850be902
|
File details
Details for the file tensorfrost-0.7.3-cp310-cp310-win_amd64.whl.
File metadata
- Download URL: tensorfrost-0.7.3-cp310-cp310-win_amd64.whl
- Upload date:
- Size: 1.7 MB
- Tags: CPython 3.10, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9b458e94369eb9cd12fcbfdfeb2c9b63aae6bd852cee87379e510b1dcdf60059
|
|
| MD5 |
9e1e8709bee16c73bd285246d2bb5bd6
|
|
| BLAKE2b-256 |
bf52f2286fbfc91e55366bbc71dcf73a5f816fa90113c5282e9bdf5f549ce545
|
File details
Details for the file tensorfrost-0.7.3-cp310-cp310-manylinux_2_28_x86_64.whl.
File metadata
- Download URL: tensorfrost-0.7.3-cp310-cp310-manylinux_2_28_x86_64.whl
- Upload date:
- Size: 1.9 MB
- Tags: CPython 3.10, manylinux: glibc 2.28+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9d9899a71c18d1bd79f83c8f1400582f360772cb716252761f142d0193b99817
|
|
| MD5 |
a03bf72c1f7c0ac6b9a9ee8714ea5807
|
|
| BLAKE2b-256 |
94333cdb5742e9568d6b028a564a00b6b62dbd12da31b035c7e3bce8a3202069
|
File details
Details for the file tensorfrost-0.7.3-cp310-cp310-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl.
File metadata
- Download URL: tensorfrost-0.7.3-cp310-cp310-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl
- Upload date:
- Size: 1.9 MB
- Tags: CPython 3.10, manylinux: glibc 2.27+ x86-64, manylinux: glibc 2.28+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.14.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
0bd416ef534eee68cf3f6181fcf8a04e2ac36253c89c74b812e2404dc3294927
|
|
| MD5 |
383083a641185868f13417d5b1ead4ff
|
|
| BLAKE2b-256 |
2badfd6cdb9adae8b1dafc5dcaa883ed327aaf3ea513915415613827583f3fdf
|
File details
Details for the file tensorfrost-0.7.3-cp310-cp310-macosx_15_0_arm64.whl.
File metadata
- Download URL: tensorfrost-0.7.3-cp310-cp310-macosx_15_0_arm64.whl
- Upload date:
- Size: 1.3 MB
- Tags: CPython 3.10, macOS 15.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.14.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
0463e74312df0509ed52b7f8ed779b1c689db97a65dac4b26a16e280accd9cbd
|
|
| MD5 |
5f9938c8e09edebb34d4f48a0ceb3fee
|
|
| BLAKE2b-256 |
a3cccf8c845ef9f8f6bda23b27eecd4c66e3b0c54bdf3a7b19e4311370ebadea
|
File details
Details for the file tensorfrost-0.7.3-cp310-cp310-macosx_14_0_arm64.whl.
File metadata
- Download URL: tensorfrost-0.7.3-cp310-cp310-macosx_14_0_arm64.whl
- Upload date:
- Size: 1.3 MB
- Tags: CPython 3.10, macOS 14.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
269975665ff9ffeff8d21748b459067a3880ad642d8e82c56211194428d3cc32
|
|
| MD5 |
da6788096f3702715c2c4ec327bd58f7
|
|
| BLAKE2b-256 |
e8a37e74c4ba3c067da16e831b57219f2298a797835aea34f70bd00ac1c92c2e
|
File details
Details for the file tensorfrost-0.7.3-cp39-cp39-win_amd64.whl.
File metadata
- Download URL: tensorfrost-0.7.3-cp39-cp39-win_amd64.whl
- Upload date:
- Size: 1.7 MB
- Tags: CPython 3.9, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8fda198edbdec3b5cb89bb35e55789a87ec3fbe028f76904c41ec2e515705eed
|
|
| MD5 |
339005eaa97ac4ac2cfffe1f61a0c9a3
|
|
| BLAKE2b-256 |
e6beb4f50dffe0fbfaf2bc406c78eec4eada5ddeda47289c263aa883089c4b7e
|
File details
Details for the file tensorfrost-0.7.3-cp39-cp39-manylinux_2_28_x86_64.whl.
File metadata
- Download URL: tensorfrost-0.7.3-cp39-cp39-manylinux_2_28_x86_64.whl
- Upload date:
- Size: 1.9 MB
- Tags: CPython 3.9, manylinux: glibc 2.28+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e18d5f3b83ffde7e69d964e75654834f78a0e1551b9c6f2b4e4d8004f7b44c83
|
|
| MD5 |
7ce1022956ebf108fbf9fc12ee9976f6
|
|
| BLAKE2b-256 |
b2fbfa09ea889f7497fd77ec329b360ffc280b4424845c680497ebff40817884
|
File details
Details for the file tensorfrost-0.7.3-cp39-cp39-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl.
File metadata
- Download URL: tensorfrost-0.7.3-cp39-cp39-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl
- Upload date:
- Size: 1.9 MB
- Tags: CPython 3.9, manylinux: glibc 2.27+ x86-64, manylinux: glibc 2.28+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.14.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
85881bcdbc505e23ae5fe7189f2ead9f9ee52331f9de6096a48f70b5e61d26c8
|
|
| MD5 |
d5041e4373073542ed840dad301b3abf
|
|
| BLAKE2b-256 |
c7a3fd5180e3891c6daebf1e2e5ad7e33bc8572aa04281b329ecd579facbbfcb
|
File details
Details for the file tensorfrost-0.7.3-cp39-cp39-macosx_15_0_arm64.whl.
File metadata
- Download URL: tensorfrost-0.7.3-cp39-cp39-macosx_15_0_arm64.whl
- Upload date:
- Size: 1.3 MB
- Tags: CPython 3.9, macOS 15.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.14.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
dfb18e41012e9668cca3f226b2af6ce6eb67f0b1bce00546aec2c1ca44fa9bca
|
|
| MD5 |
4e6500d0ed98cd513e1c8c194faeb94d
|
|
| BLAKE2b-256 |
8a21297f54a35ae8ff53af21a33ec3640de70fe6fa3f5af9f4ce3fdaf97e9308
|
File details
Details for the file tensorfrost-0.7.3-cp39-cp39-macosx_14_0_arm64.whl.
File metadata
- Download URL: tensorfrost-0.7.3-cp39-cp39-macosx_14_0_arm64.whl
- Upload date:
- Size: 1.3 MB
- Tags: CPython 3.9, macOS 14.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
96a5811e7df84282569fb77e9f0093867cc0d83e9ddbffb221487046ab3f32a3
|
|
| MD5 |
da81d39aebbedd695e56c2134a168ef0
|
|
| BLAKE2b-256 |
92b2119e09ba5fb7c7cc7c543168d5d76c0c4530e72eca76989676d0aaa55f74
|
File details
Details for the file tensorfrost-0.7.3-cp38-cp38-win_amd64.whl.
File metadata
- Download URL: tensorfrost-0.7.3-cp38-cp38-win_amd64.whl
- Upload date:
- Size: 1.7 MB
- Tags: CPython 3.8, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8f50de6622c57a4e09b22d7ab5a2955c940292cf0ea723067446d81f1f6c151d
|
|
| MD5 |
6f55cf32410fc5309f1730f13c824974
|
|
| BLAKE2b-256 |
8adedfdc3a6c1862a473e4af7d08fff804ed95503e9ec587a7e71d206892a673
|
File details
Details for the file tensorfrost-0.7.3-cp38-cp38-manylinux_2_28_x86_64.whl.
File metadata
- Download URL: tensorfrost-0.7.3-cp38-cp38-manylinux_2_28_x86_64.whl
- Upload date:
- Size: 1.9 MB
- Tags: CPython 3.8, manylinux: glibc 2.28+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
0bc55c8216502f452ad38c46349a24b341943401b8bb6d17a29c2052a3931b48
|
|
| MD5 |
5651072afa951a553c7f24959dfe69c5
|
|
| BLAKE2b-256 |
f2ba9ced312b4f70dfe38f8ae5f0226d4e8e4051406816047e564105fd0f4d66
|
File details
Details for the file tensorfrost-0.7.3-cp38-cp38-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl.
File metadata
- Download URL: tensorfrost-0.7.3-cp38-cp38-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl
- Upload date:
- Size: 1.9 MB
- Tags: CPython 3.8, manylinux: glibc 2.27+ x86-64, manylinux: glibc 2.28+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.14.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ac741be74394ee3056e3ddc7b0ecdb8b09c9b48d8a9cd96dd5c21af9a3e82d8a
|
|
| MD5 |
08dc1b859f7f3c1c71e34eff1bf01239
|
|
| BLAKE2b-256 |
89c2c19e0305f1099199addad5985b587e39c2818e3e32c14f563de157016528
|
File details
Details for the file tensorfrost-0.7.3-cp38-cp38-macosx_15_0_arm64.whl.
File metadata
- Download URL: tensorfrost-0.7.3-cp38-cp38-macosx_15_0_arm64.whl
- Upload date:
- Size: 1.3 MB
- Tags: CPython 3.8, macOS 15.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.14.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6bb1dfda7576db42b6d8775611b2c25f0647f93622ea6f7657e33a6742950179
|
|
| MD5 |
3e5f623a8c2c40e1b95d0becfe1eca82
|
|
| BLAKE2b-256 |
639d58031e498731e185002be0676e68d5436986967a9a0f048b97dd0ff22623
|
File details
Details for the file tensorfrost-0.7.3-cp38-cp38-macosx_14_0_arm64.whl.
File metadata
- Download URL: tensorfrost-0.7.3-cp38-cp38-macosx_14_0_arm64.whl
- Upload date:
- Size: 1.3 MB
- Tags: CPython 3.8, macOS 14.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f2675ba76ff7ec1a25036dc22903a6c55766fa2485db014d0be38d1c8f04a7bd
|
|
| MD5 |
6cd7265ff71ca643c55a4a311d4e5d17
|
|
| BLAKE2b-256 |
baeda0c4c35a763c41225a2a62711b080f62c7d7a377ccc714d5805c6373fe00
|







