A family of highly efficient, lightweight yet powerful optimizers.

Project description
Advanced Optimizers (AIO)
A comprehensive, all-in-one collection of optimization algorithms for deep learning, designed for maximum efficiency, minimal memory footprint, and superior performance across diverse model architectures and training scenarios.

📦 Installation
pip install adv_optm
🧠 Core Innovations
This library integrates multiple state-of-the-art optimization techniques validated through extensive research and practical training, with 1-bit compression for optimizer states:
Memory-Efficient Optimization (SMMF-inspired)
- Paper: SMMF: Square-Matricized Momentum Factorization
- Approach: Uses rank-1 non-negative matrix factorization with reconstruction cycle (factor → reconstruct → update → factor)
- Innovation:
- First moment split into 1-bit sign + absolute value
- Final storage: four factored vectors + one 1-bit sign state
- Preserves Adam-like update quality with drastically reduced memory
⚡ Performance Characteristics
Memory Efficiency (SDXL Model - 6.5GB)
| Optimizer | Memory Usage | Description |
|---|---|---|
Adopt_Factored |
328 MB | 4 small vectors + 1-bit state |
Adopt_Factored + AdEMAMix |
625 MB | 6 small vectors + two 1-bit states |
Simplified_AdEMAMix |
328 MB | Same as standard factored (no extra state) |
Speed Comparison (SDXL, Batch Size 4)
| Optimizer | Speed | Notes |
|---|---|---|
Adafactor |
~8.5s/it | Baseline |
Adopt_Factored |
~10s/it | +18% overhead from compression |
Adopt_Factored + AdEMAMix |
~12s/it | +41% overhead (3 factored states) |
🧪 Available Optimizers
Standard Optimizers (All support factored=True/False)
| Optimizer | Description | Best For |
|---|---|---|
Adam_Adv |
Advanced Adam implementation | General purpose |
Adopt_Adv |
Adam-variant with independent beta2 | Stable training for small batch size regimes |
Prodigy_Adv |
Prodigy with D-Adaptation | Adam with automatic LR tuning |
Simplified_AdEMAMix |
Adam variant with accumulator momentum | Small/large batch training when tuned correctly |
Lion_Adv |
Advanced Lion implementation | Memory-constrained environments |
Prodigy_Lion_Adv |
Prodigy + Lion combination | Lion with automatic LR tuning |
Feature Matrix
| Feature | Adam_Adv | Adopt_Adv | Prodigy_Adv | Simplified_AdEMAMix | Lion_Adv |
|---|---|---|---|---|---|
| Factored | ✓ | ✓ | ✓ | ✓ | ✓ |
| AdEMAMix | ✓ | ✓ | ✓ | ✗ | ✗ |
| Simplified_AdEMAMix | ✗ | ✗ | ✓ | ✓ | ✗ |
| OrthoGrad | ✓ | ✓ | ✓ | ✓ | ✓ |
| Grams | ✓ | ✓ | ✓ | ✗ | ✗ |
| Cautious | ✓ | ✓ | ✓ | ✗ | ✓ |
| atan2 | ✓ | ✓ | ✓ | ✗ | ✗ |
| Stochastic Rounding | ✓ | ✓ | ✓ | ✓ | ✓ |
| Fused Backward Pass | ✓ | ✓ | ✓ | ✓ | ✓ |
⚙️ Key Features & Parameters
Comprehensive Feature Guide
| Feature | Description | Recommended Usage | Performance Impact | Theoretical Basis | Compatibility |
|---|---|---|---|---|---|
| Factored | Memory-efficient optimization using rank-1 factorization | Enable for large models (>1B params) or limited VRAM | +12-41% time overhead, 1-bit memory usage | SMMF | All optimizers |
| AdEMAMix | Dual EMA system for momentum | Use for long training runs (10k+ steps) | +1 state memory. | AdEMAMix | Adam/Adopt/Prodigy |
| Simplified_AdEMAMix | Accumulator-based momentum | Small batch training (≤32) | Same memory as standard, no extra overhead | Schedule-Free Connections | Adam/Prodigy |
| OrthoGrad | Removes gradient component parallel to weights | Full finetuning without weight decay | +33% time overhead, no memory impact | Grokking at Edge | All optimizers |
| Stochastic Rounding | Improves precision for BF16 training | BF16 training | Minimal overhead (<5%) | Revisiting BFloat16 Training | All optimizers |
| atan2 | Robust eps replacement + built-in clipping | Use with Adopt or unstable training | No overhead | Adam-atan2 | Adam/Adopt/prodigy |
| Cautious | Update only when the direction align with the gradients | should faster the convergence | No overhead | C-Optim | Adam/Adopt/prodigy |
| Grams | Update direction from the gradients | should have a stronger effect than cautious | No overhead | Grams | Adam/Adopt/prodigy |
Simplified_AdEMAMix Parameters
Simplified_AdEMAMix replaces standard momentum with an accumulator for better small-large batch performance.
| Parameter | Recommended Values | Description |
|---|---|---|
beta1 |
0.9 (large BS), 0.99-0.9999 (small BS) | Determines memory length of accumulator |
alpha |
100-10 (small BS), 1-0 (large BS) | Gradient smoothing factor |
Alpha Tuning Guide:
| Batch Size | Recommended α | Rationale |
|---|---|---|
| Small (≤32) | 100, 50, 20, 10 | Emphasizes recent gradients for quick adaptation |
| Medium (32-512) | 10, 5, 2, 1 | Balanced approach |
| Large (≥512) | 1, 0.5, 0 | Emphasizes historical gradients for stability |
⚠️ Important: Use ~100x smaller learning rate with Simplified_AdEMAMix compared to AdamW (e.g., 1e-6 instead of 1e-4)
📊 Performance Validation
Small Batch Training (SDXL, BS=2, 1.8K steps)
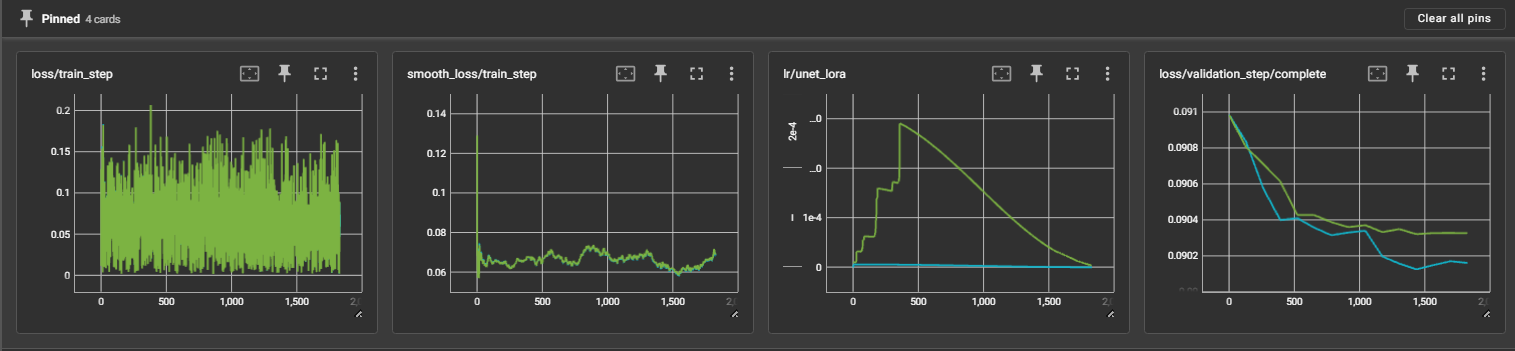
- 🟢 Prodigy_adv (beta1=0.9, d0=1e-5): Final LR=2.9e-4
- 🔵 Prodigy_adv + Simplified_AdEMAMix (beta1=0.99, α=100, d0=1e-7): Final LR=5.8e-6
Results:
- Simplified_AdEMAMix shows faster convergence and better final performance
- D-Adaptation automatically handles aggressive updates (50x smaller LR)
- Generated samples show significantly better quality with Simplified_AdEMAMix
⚠️ Known Limitations
1. Prodigy_Adv Sensitivity
- Highly sensitive to gradient modifications (Adopt normalization, low-rank factorization)
- May fail to increase learning rate in some LoRA scenarios
- Fix: Disable factorization or set beta1=0
2. Aggressive Learning Rates
- Can destabilize factored first moment
- Recommendation: Check Prodigy learning rate as reference for safe LR threshold
📚 References
- SMMF: Square-Matricized Momentum Factorization
- The AdEMAMix Optimizer: Better, Faster, Older
- Connections between Schedule-Free Optimizers, AdEMAMix, and Accelerated SGD Variants
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file adv_optm-1.1.0.dev4.tar.gz.
File metadata
- Download URL: adv_optm-1.1.0.dev4.tar.gz
- Upload date:
- Size: 30.3 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
25611b5bd2e8027f5f89cf119685b40a4bfbaac0d037e91f1b271be7a9432ee8
|
|
| MD5 |
1bd66b31f1cf48843c0e9c5dfdb4a543
|
|
| BLAKE2b-256 |
22bbeeea9f2f20afd0c8c12994c07be6f01bcf55442ccc5afae0a484724de31e
|
File details
Details for the file adv_optm-1.1.0.dev4-py3-none-any.whl.
File metadata
- Download URL: adv_optm-1.1.0.dev4-py3-none-any.whl
- Upload date:
- Size: 42.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9fb5730f864867c030fb05b72e33158b167a25a4c8205e5e0cdbb0985db586f8
|
|
| MD5 |
387e868aa1901b0c1c9084e3009c49d8
|
|
| BLAKE2b-256 |
13c28d6d5da70b544346e4d76bc6df6ecc4341bc1d4ca0d968281c3e509057db
|







