A family of highly efficient, lightweight yet powerful optimizers.

Project description
Advanced Optimizers (AIO)
A comprehensive, all-in-one collection of optimization algorithms for deep learning, designed for maximum efficiency, minimal memory footprint, and superior performance across diverse model architectures and training scenarios.

📦 Installation
pip install adv_optm
🧠 Core Innovations
This library integrates multiple state-of-the-art optimization techniques validated through extensive research and practical training, with 1-bit compression for optimizer states:
Memory-Efficient Optimization (SMMF-inspired)
- Paper: SMMF: Square-Matricized Momentum Factorization
- Approach: Uses rank-1 non-negative matrix factorization with reconstruction cycle (factor → reconstruct → update → factor)
- Innovation:
- First moment split into 1-bit sign + absolute value
- Final storage: four factored vectors + one 1-bit sign state
- Preserves Adam-like update quality with drastically reduced memory
⚡ Performance Characteristics
Memory Efficiency (SDXL Model – 6.5GB)
| Optimizer | Memory Usage | Description |
|---|---|---|
Adopt_Factored |
328 MB | 4 small vectors + 1-bit state |
Adopt_Factored + AdEMAMix |
625 MB | 6 small vectors + two 1-bit states |
Simplified_AdEMAMix |
328 MB | Same as standard factored (no extra state) |
Speed Comparison (SDXL, Batch Size 4)
| Optimizer | Speed | Notes |
|---|---|---|
Adafactor |
~8.5s/it | Baseline |
Adopt_Factored |
~10s/it | +18% overhead from compression |
Adopt_Factored + AdEMAMix |
~12s/it | +41% overhead (3 factored states) |
🧪 Available Optimizers
Standard Optimizers (All support factored=True/False)
| Optimizer | Description | Best For |
|---|---|---|
Adam_Adv |
Advanced Adam implementation | General purpose |
Adopt_Adv |
Adam-variant with independent beta2 | Stable training for small batch size regimes |
Prodigy_Adv |
Prodigy with D-Adaptation | Adam with automatic LR tuning |
Simplified_AdEMAMix |
Adam variant with accumulator momentum | Small/large batch training when tuned correctly |
Lion_Adv |
Advanced Lion implementation | Memory-constrained environments |
Prodigy_Lion_Adv |
Prodigy + Lion combination | Lion with automatic LR tuning |
⚙️ Feature Matrix
| Feature | Adam_Adv | Adopt_Adv | Prodigy_Adv | Simplified_AdEMAMix | Lion_Adv |
|---|---|---|---|---|---|
| Factored | ✓ | ✓ | ✓ | ✓ | ✓ |
| AdEMAMix | ✓ | ✓ | ✓ | ✗ | ✗ |
| Simplified_AdEMAMix | ✗ | ✓ | ✓ | ✓ | ✗ |
| OrthoGrad | ✓ | ✓ | ✓ | ✓ | ✓ |
| Grams | ✓ | ✓ | ✓ | ✗ | ✗ |
| Cautious | ✓ | ✓ | ✓ | ✗ | ✓ |
| atan2 | ✓ | ✓ | ✓ | ✗ | ✗ |
| Stochastic Rounding | ✓ | ✓ | ✓ | ✓ | ✓ |
| Fused Backward Pass | ✓ | ✓ | ✓ | ✓ | ✓ |
| Kourkoutas-β | ✓ | ✓ | ✓ | ✓ | ✗ |
🛠️ Comprehensive Feature Guide
A. Universal Safe Features
These features work with all optimizers and are generally safe to enable.
| Feature | Description | Recommended Usage | Performance Impact | Theoretical Basis | Compatibility |
|---|---|---|---|---|---|
| Fused Back Pass | Fuses backward pass; gradients used immediately and memory freed on-the-fly | Memory-constrained environments | Reduces peak memory | Memory optimization | All optimizers |
| Stochastic Rounding | Replaces nearest rounding with stochastic rounding to preserve small gradient updates in BF16 | BF16 training | Minimal overhead (<5%) | Revisiting BFloat16 Training | All optimizers |
| OrthoGrad | Removes gradient component parallel to weights to reduce overfitting | Full fine-tuning without weight decay | +33% time overhead (BS=4); less at larger BS | Grokking at Edge | All optimizers |
| Factored | Memory-efficient optimization via rank-1 1-bit factorization of optimizer states | Large models / memory-limited hardware | Adds compression overhead | SMMF | All optimizers |
B. Individual Features
| Feature | Description | Recommended Usage | Performance Impact | Theoretical Basis | Compatibility |
|---|---|---|---|---|---|
| Cautious | Only applies update if gradient direction aligns with momentum direction | Accelerating convergence | No overhead | C-Optim | Adam/Adopt/Prodigy/Lion |
| Grams | Update direction derived purely from current gradient | When Cautious is insufficient | No overhead | Grams | Adam/Adopt/Prodigy |
| AdEMAMix | Dual EMA system that retains relevance of gradients over tens of thousands of steps | Long training runs, especially where model forgetting is a concern | +1 state memory | AdEMAMix | Adam/Adopt/Prodigy |
| Simplified_AdEMAMix | Accumulator-based momentum, single EMA variant of AdEMAMix | All scenarios when tuned correctly | No overhead | Connections | Adam/Adopt/Prodigy |
| atan2 | Robust epsilon replacement with built-in gradient clipping | Use for stable bounded updates (or for Adopt as it needs that) | No overhead | Adam-atan2 | Adam/Adopt/Prodigy |
| Kourkoutas-β | Layer-wise adaptive β₂ based on gradient “sunspike” ratio | Noisy/small/large-batch/high-LR training | No overhead | Kourkoutas-β | Adam/Adopt/Prodigy/Simplified_AdEMAMix |
Note: If both Cautious and Grams are enabled, Grams takes precedence and Cautious is disabled.
🔍 Feature Deep Dives
AdEMAMix
- Adds a slow-decaying second EMA (
beta3) that retains gradient memory over tens of thousands of steps. - Particularly effective for small batch sizes, where Adam’s standard first moment is nearly useless.
- Reference: AdaMeM: Memory Efficient Momentum for Adafactor
Tunable Hyperparameters
| Parameter | Default | Tuning Guide |
|---|---|---|
beta3 |
0.9999 | • Runs >120k steps: 0.9999 • Runs ≤120k steps: 0.999 |
alpha |
5 | • Reduce to 2–3 if diverging • Increase to strengthen long-term memory |
✅ Pro Tip: Set
beta1=0in Adam/Adopt/Prodigy to skip standard EMA entirely and rely solely on AdEMAMix’s slow EMA, ideal for small-batch regimes.
Simplified_AdEMAMix
- Introduced in Connections between Schedule-Free Optimizers, AdEMAMix, and Accelerated SGD Variants (arXiv:2502.02431).
- Replaces Adam’s first moment with a gradient accumulator, combining the stability of long memory with responsiveness to recent gradients.
- Key insight: Classical momentum does not accelerate in noisy (small-batch) regimes; this accumulator do.
Tunable Hyperparameters
| Parameter | Default | Tuning Guide |
|---|---|---|
beta1 |
0.99 | Controls accumulator memory length: • Small BS: 0.99–0.9999 • Large BS: 0.9 |
Grad α |
100 | Most critical parameter: • Inversely scales with batch size • 100–10 for small BS (≤32) • 1–0.1 for large BS (≥512) |
⚠️ Critical: Requires ~100x smaller learning rate than AdamW (e.g., 1e-6 vs 1e-4).
ForProdigy_Adv, setinitial_dto:
- LoRA:
1e-8- Full FT:
1e-10- Embedding:
1e-7
⚠️ Incompatible with: Cautious, Grams, atan2, and standard gradient clipping.
Performance Validation
Small Batch Training (SDXL, BS=2, 1.8K steps)
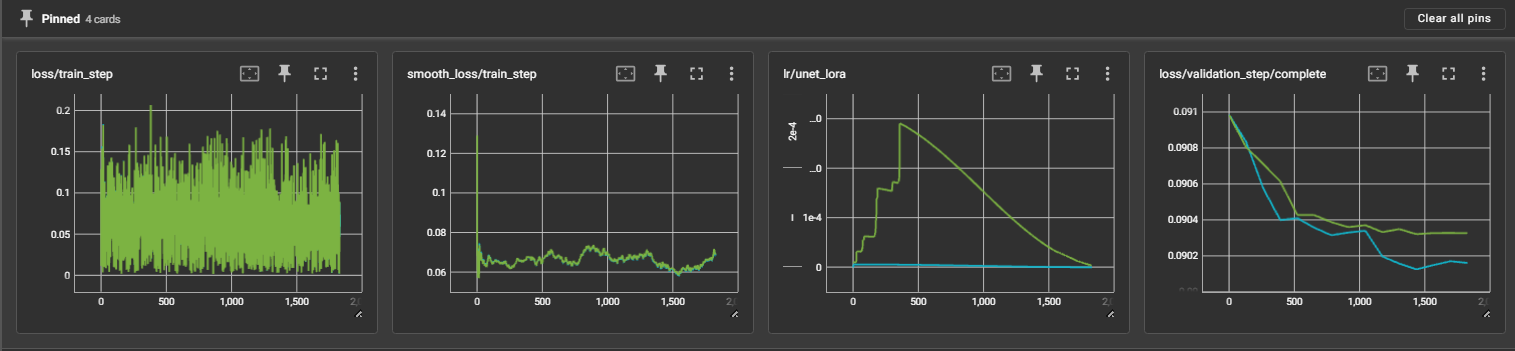
- 🟢 Prodigy_Adv (beta1=0.9, d0=1e-5): Final LR = 2.9e-4
- 🔵 Prodigy_Adv + Simplified_AdEMAMix (beta1=0.99, α=100, d0=1e-7): Final LR = 5.8e-6
Results:
- Faster convergence and higher final performance with Simplified_AdEMAMix
- D-Adaptation automatically compensates for aggressive updates
- Generated samples show significantly better quality
atan2
- Replaces
epsin Adam-family optimizers with a scale-invariant, bounded update rule. - Automatically clips updates to [-2, 2], preventing destabilizing jumps.
- Highly recommended for
Adopt_Adv, which is prone to instability without clipping.
Kourkoutas-β
Kourkoutas-β introduces a sunspike-driven, layer-wise adaptive second-moment decay (β₂) as an optional enhancement for Adam_Adv, Adopt_Adv, Prodigy_Adv, and Simplified_AdEMAMix.
Instead of using a fixed β₂ (e.g., 0.999 or 0.95), it dynamically modulates β₂ per layer based on a bounded sunspike ratio:
- During gradient bursts → β₂ ↓ toward
Lower β₂→ faster reaction - During calm phases → β₂ ↑ toward
The Selected β₂→ stronger smoothing
This is especially effective for noisy training, small batch sizes, and high learning rates, where gradient norms shift abruptly due to noise or aggressive LR schedules.
Pros/Cons
| Category | Details |
|---|---|
| ✅ Pros | • Layer-wise adaptation blends benefits of high β₂ (strong smoothing) and low β₂ (fast reaction). • Robust to sudden loss landscape shifts, reacts quickly during gradient bursts, smooths during calm phases. • High tolerance to aggressive learning rates. |
| ⚠️ Cons | • Potentially unstable at the start of training due to unreliable early gradient norms; mitigated by using K-β Warmup Steps. |
💡 Best Practice: Set
K_warmup_stepsequal to your standard LR warmup steps. During warmup, the optimizer uses the staticbeta2; adaptation begins only after warmup ends.
🔍 Debugging Aid: Enable
K_Loggingto monitor (min, max, mean) of dynamic β₂ values across layers every N steps.
📊 Performance Validation
ADAMW_ADV - full SDXL finetuning (aggressive LR: 3e-5) (BS=4, 2.5K steps)
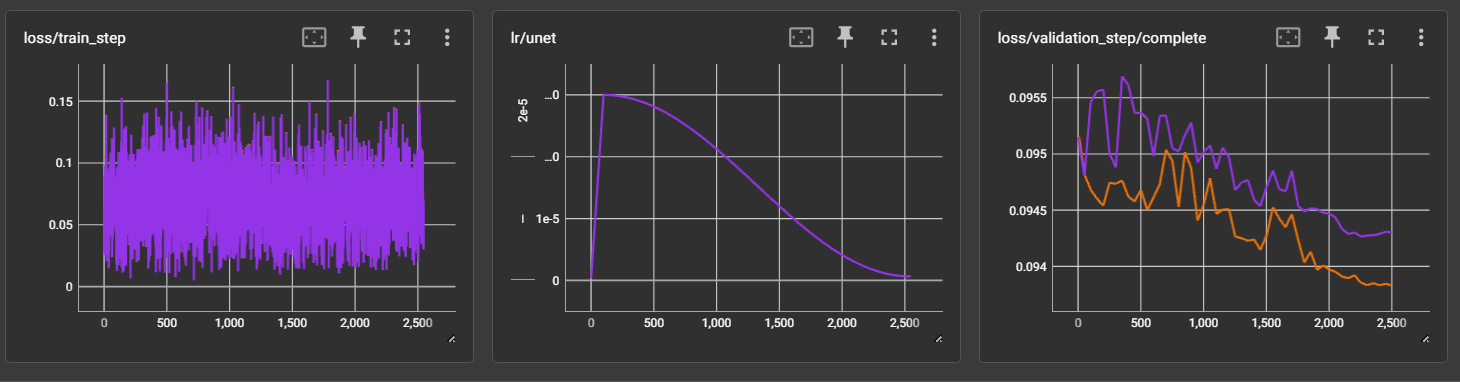
- 🟣 Fixed
beta2=0.999 - 🟠 Auto K-beta
Observations:
- K-beta is clearly better and more robust/stable for high LRs.
📚 Reference:
Recommended Preset (Tested on LoRA/FT/Embedding)
Learning Rate: 1
optimizer: PRODIGY_Adv
settings:
- beta1: 0.99 # Controls momentum decay, ~100-step effective memory. Adjust to 0.999 (1000 steps) or 0.9999 (10000 steps) based on training length and stability needs.
- beta2: 0.999
- kourkoutas_beta: True # For Kourkoutas-β
- K-β Warmup Steps: 50 # Or 100, 200, depending on your run
- Simplified_AdEMAMix: True
- Grad α: 100
- OrthoGrad: True
- weight_decay: 0.0
- initial_d:
• LoRA: 1e-8
• Full fine-tune: 1e-10
• Embedding: 1e-7
- d_coef: 1
- d_limiter: True # To stablizie Prodigy with Simplified_AdEMAMix
- factored: False # Can be true or false, quality should not degrade due to Simplified_AdEMAMix’s high tolerance to 1-bit factorization.
✅ Why it works:
Kourkoutas-βhandles beta2 valuesSimplified_AdEMAMixensures responsiveness in small-batch noiseOrthoGradprevents overfitting without weight decay
📚 References
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file adv_optm-1.2.dev7.tar.gz.
File metadata
- Download URL: adv_optm-1.2.dev7.tar.gz
- Upload date:
- Size: 44.4 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
25e03db3c7f0f7a6a5b37ed04677b900c934ed9c0f10a970fd9c1f65dede245f
|
|
| MD5 |
b010f043d94f1d0680741281d625f5b9
|
|
| BLAKE2b-256 |
a9a02725592a8b8e8132eb0e646b1450d75378f83613fbca283160133c3f702b
|
File details
Details for the file adv_optm-1.2.dev7-py3-none-any.whl.
File metadata
- Download URL: adv_optm-1.2.dev7-py3-none-any.whl
- Upload date:
- Size: 58.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
2096c94bb362aa8280e86a6e21ef0ab4c181f5700273576940f3085382419a3c
|
|
| MD5 |
6579489957d1760af79a99eece955c58
|
|
| BLAKE2b-256 |
53fce444d2be71958234a267beb3b915875c951b95e9907015ddafb343510cd6
|







