a Python package that helps you to create a graph database using Azure Database for PostgreSQL.

Project description
AGEFreighter


a Python package that helps you to create a graph database using Azure Database for PostgreSQL.
Apache AGE™ is a PostgreSQL Graph database compatible with PostgreSQL's distributed assets and leverages graph data structures to analyze and use relationships and patterns in data.
Azure Database for PostgreSQL is a managed database service that is based on the open-source Postgres database engine.
Introducing support for Graph data in Azure Database for PostgreSQL (Preview).
Table of Contents
- Version1.0
- Features
- Prerequisites
- Install
- Usage
- load subcommand
- view subcommand
- convert subcommand
- parse subcommand
- generate subcommand
- prepare subcommand
- How to edit the CSV files to load them to the graph database with AGEFreighter
- Release Notes
- Known Issues
- For More Information
- License
Version1.0
AGEFreighter 1.0 is totally refactored as a CLI tool for loading data into Apache AGE and viewing graph data in Apache AGE.
Features
- Asynchronous connection pool support for psycopg PostgreSQL driver
- COPY protocol support for loading data into the graph.
- On macOS / Linux, 'tab' completion is available.
agefreighter --generate-completion
Writing completion script to /Users/rifujita/.agefreighter/_agefreighter.completion
Completion script generated successfully.
Please execute `source /Users/rifujita/.zprofile` or restart your shell to enable completion.
- On demand Python package installation to reduce installation time.
agefreighter load
required module 'neo4j' is not installed. Install it? [Y/n]: Y
pip module is not available. Trying with uv...
Subcommands
loadsubcommand to load CSV files, graph data in Neo4j, Cosmos DB for NoSQL into Apache AGE.viewsubcommand to view graph data in Apache AGE.convertsubcommand to convert Gremlin queries to Cypher queries.parsesubcommand to parse a Cypher query.generatesubcommand to generate dummy graph data.preparesubcommand to prepare environment for testing AGEFreighter.
Prerequisites
- Python 3.13 and above
- This module runs on psycopg and psycopg_pool
- Enable the Apache AGE extension in your Azure Database for PostgreSQL instance. Login Azure Portal, go to 'server parameters' blade, and check 'AGE" on within 'azure.extensions' and 'shared_preload_libraries' parameters. See, above blog post for more information.
- Load the AGE extension in your PostgreSQL database.
CREATE EXTENSION IF NOT EXISTS age CASCADE;
Install
- with brew
brew tap rioriost/agefreighter https://github.com/rioriost/agefreighter.git
brew install agefreighter
- with uv
uv init your_project
cd your_project
uv venv
source .venv/bin/activate
uv add agefreighter
- with python venv on macOS / Linux
mkdir your_project
cd your_project
python3 -m venv .venv
source .venv/bin/activate
python3 -m pip install agefreighter
- with python venv on Windows
mkdir your_project
cd your_project
python -m venv venv
.\venv\Scripts\activate
python -m pip install agefreighter
Usage
agefreighter --help
usage: agefreighter [-h] [--graphname GRAPHNAME] [--pg-con-str PG_CON_STR] [--pg-min-connections PG_MIN_CONNECTIONS] [--pg-max-connections PG_MAX_CONNECTIONS] [--debug] [--version] [--generate-completion]
{load,view,parse,generate,convert,prepare} ...
AGEFreighter, a tool to export data from various sources and load it into Apache AGE.
positional arguments:
{load,view,parse,generate,convert,prepare}
load Load data into Apache AGE
view View data in Apache AGE
parse Parse a cypher query
generate Generate dummy data
convert Convert Gremlin queries to Cypher queries.
prepare Prepare data for testing AGEFreighter.
options:
-h, --help show this help message and exit
--graphname GRAPHNAME
Name of a new graph on Apache AGE
--pg-con-str PG_CON_STR
Connection string of the Azure Database for PostgreSQL
--pg-min-connections PG_MIN_CONNECTIONS
Minimum number of connections to PostgreSQL
--pg-max-connections PG_MAX_CONNECTIONS
Maximum number of connections to PostgreSQL
--debug Enable debug logging
--version Show version information
--generate-completion
Generate the completion script and exit
Each subcommand has its own set of options.
For example, the load subcommand has options for specifying the source type of the graph data, addition to the above options.
load subcommand
agefreighter % agefreighter load --help
usage: agefreighter load [-h] [--source-type {neo4j,cosmosdb,pgsql,csv}] [--trial] [--no-of-edges-trial NO_OF_EDGES_TRIAL] [--save-temps] [--chunk-size CHUNK_SIZE] [--progress]
[--config CONFIG] [--neo4j-uri NEO4J_URI] [--neo4j-user NEO4J_USER] [--neo4j-password NEO4J_PASSWORD] [--neo4j-database NEO4J_DATABASE]
[--cosmos-endpoint COSMOS_ENDPOINT] [--cosmos-key COSMOS_KEY] [--cosmos-database COSMOS_DATABASE] [--cosmos-container COSMOS_CONTAINER]
[--src-pg-con-str SRC_PG_CON_STR]
options:
-h, --help show this help message and exit
--source-type {neo4j,cosmosdb,pgsql,csv}
Source type of the graph data
--trial Extract only 100 edges per relationship type
--no-of-edges-trial NO_OF_EDGES_TRIAL
The number of edges to extract per relationship type
--save-temps Save data from source as CSV files into a directory
--chunk-size CHUNK_SIZE
Chunk size for exporting data
--progress Show progress
--config CONFIG Path to the configuration file
--neo4j-uri NEO4J_URI
Neo4j URI
--neo4j-user NEO4J_USER
Neo4j username
--neo4j-password NEO4J_PASSWORD
Neo4j password
--neo4j-database NEO4J_DATABASE
Neo4j database
--cosmos-endpoint COSMOS_ENDPOINT
Cosmos endpoint
--cosmos-key COSMOS_KEY
Cosmos key
--cosmos-database COSMOS_DATABASE
Cosmos database
--cosmos-container COSMOS_CONTAINER
Cosmos container
--src-pg-con-str SRC_PG_CON_STR
Source PostgreSQL connection string
Load from Neo4j
To load graph data from Neo4j, use the following command:
agefreighter --pg-con-str "host=YOUR_SERVER.postgres.database.azure.com port=5432 dbname=postgres user=YOUR_USERNAME password=YOUR_PASSWORD" load --neo4j-uri neo4j://localhost:7687 --neo4j-user neo4j --neo4j-password password
Or, you can use the environment variables:
- macOS / Linux
export PG_CONNECTION_STRING="host=YOUR_SERVER.postgres.database.azure.com port=5432 dbname=postgres user=YOUR_USERNAME password=YOUR_PASSWORD"
export NEO4J_URI="neo4j://localhost:7687"
export NEO4J_USER="neo4j"
export NEO4J_PASSWORD="password"
- Windows (cmd.exe)
set PG_CONNECTION_STRING=host=YOUR_SERVER.postgres.database.azure.com port=5432 dbname=postgres user=YOUR_USERNAME password=YOUR_PASSWORD
set NEO4J_URI=neo4j://localhost:7687
set NEO4J_USER=neo4j
set NEO4J_PASSWORD=password
- PowerShell
$env:PG_CONNECTION_STRING="host=YOUR_SERVER.postgres.database.azure.com port=5432 dbname=postgres user=YOUR_USERNAME password=YOUR_PASSWORD"
$env:NEO4J_URI="neo4j://localhost:7687"
$env:NEO4J_USER="neo4j"
$env:NEO4J_PASSWORD="password"
If all the required environment variables are set, you can just run:
agefreighter load
Load from CSV Files
To load data from CSV files, you need to prepare a configuration JSON file that specifies how to load the CSV files into your PostgreSQL.
(supposed $PG_CONNECTION_STRING is set)
agefreighter load --source-type csv --config config.json
We have 4 structure patterns of nodes and edges.
- Single kind of nodes and single kind of edges:
(AirPort) - [AirRoute] -> (AirPort)
This pattern is described in JSON as follows docs/configs/csv/single_edge_single_node.json:
{
"edge": {
"csv_path": "data/airroute/airroute_airport_airport.csv",
"type": "AirRoute",
"props": ["distance"],
"start_vertex": {
"csv_path": "data/airroute/airroute_airport_airport.csv",
"id": "start_id",
"label": "AirPort",
"props": []
},
"end_vertex": {
"csv_path": "data/airroute/airroute_airport_airport.csv",
"id": "end_id",
"label": "AirPort",
"props": []
}
}
}
And the contents of the CSV files data/airroute/airroute_airport_airport.csv:
"id","start_id","start_vertex_type","end_id","end_vertex_type","distance"
"1","1388","AirPort","794","AirPort","1373"
"2","2998","AirPort","823","AirPort","11833"
"3","2058","AirPort","2423","AirPort","2180"
"4","794","AirPort","2868","AirPort","880"
- Single kind of nodes and multiple kinds of edges:
(Person) - [KNOWS | LIKES] -> (Person)
This pattern is described in JSON as follows docs/configs/csv/multiple_edges_single_node.json:
{
"edge": [
{
"csv_path": "data/persons/knows_person_person.csv",
"type": "KNOWS",
"props": ["since"],
"vertex": {
"csv_path": "data/persons/person.csv",
"id": "id",
"label": "Person",
"props": ["Name"]
}
},
{
"csv_path": "data/persons/likes_person_person.csv",
"type": "LIKES",
"props": ["since"],
"vertex": {
"csv_path": "data/persons/person.csv",
"id": "id",
"label": "Person",
"props": ["Name"]
}
}
]
}
And the contents of the CSV files:
"id","Name"
"1","Donna Smith"
"2","Kristin Villanueva"
"3","Margaret Jackson"
"4","Emily Morrison"
data/persons/knows_person_person.csv
"id","start_id","start_vertex_type","end_id","end_vertex_type"
"1","247","Person","818","Person"
"2","609","Person","62","Person"
"3","687","Person","573","Person"
"4","975","Person","963","Person"
data/persons/likes_person_person.csv
"id","start_id","start_vertex_type","end_id","end_vertex_type"
"1","566","Person","892","Person"
"2","263","Person","409","Person"
"3","637","Person","788","Person"
"4","454","Person","487","Person"
- Multiple kinds of nodes and single kind of edges:
(Country) - [has] -> (City)
This pattern is described in JSON as follows docs/configs/csv/single_edge_multiple_nodes.json:
{
"edge": {
"csv_path": "data/countries/has_country_city.csv",
"type": "has",
"props": ["since"],
"start_vertex": {
"csv_path": "data/countries/country.csv",
"id": "id",
"label": "Country",
"props": ["Name", "Capital", "Population", "ISO", "TLD", "FlagURL"]
},
"end_vertex": {
"csv_path": "data/countries/city.csv",
"id": "id",
"label": "City",
"props": ["Name", "Latitude", "Longitude"]
}
}
}
And the contents of the CSV files:
""id"",""Name"",""Capital"",""Population"",""ISO"",""TLD"",""FlagURL""
""1"",""El Salvador"",""Kristybury"",""355169921"",""TN"",""wxu"",""https://dummyimage.com/777x133""
""2"",""Lebanon "for" Special Character testing"",""New William"",""413929227"",""UK"",""akj"",""https://picsum.photos/772/459""
""3"",""Pakistan"",""Justinstad"",""568781337"",""PG"",""rqv"",""https://dummyimage.com/245x330""
""4"",""Bahamas"",""Williamland"",""115914464"",""TD"",""nzd"",""https://placekitten.com/425/474""
"id","Name","Latitude","Longitude"
"1","東京","-56.4217435","-44.924586"
"2","Bryantton","-62.714695","-162.083092"
"3","Royview","-72.721467","-33.926544"
"4","New Jonathanfurt","18.281926","-63.675749"
data/countries/has_country_city.csv
"id","start_id","start_vertex_type","end_id","end_vertex_type","since"
"1","86","Country","3633","City","1975-12-07 04:45:00.790431"
"2","22","Country","6194","City","1984-06-05 13:23:51.858147"
"3","80","Country","6479","City","1986-10-20 01:18:47.200926"
"4","185","Country","8148","City","1990-01-05 14:47:47.343686"
- Multiple kinds of nodes and multiple kinds of edges:
(Cookie | CreditCard) - [UsedIn | PerformedBy] -> (Payment)
This pattern is a little complicatedlly described in JSON as follows docs/configs/csv/multiple_edges_multiple_nodes.json:
{
"edge": [
{
"csv_path": "data/paymemt/usedin_cookie_payment.csv",
"type": "UsedIn",
"props": ["available_since", "inserted_at", "schema_version"],
"start_vertex": {
"csv_path": "data/paymemt/cookie.csv",
"id": "id",
"label": "Cookie",
"props": ["available_since", "inserted_at", "uaid", "schema_version"]
},
"end_vertex": {
"csv_path": "data/paymemt/payment.csv",
"id": "id",
"label": "Payment",
"props": [
"available_since",
"inserted_at",
"payment_id",
"schema_version"
]
}
},
{
"csv_path": "data/paymemt/usedin_creditcard_payment.csv",
"type": "UsedIn",
"props": ["available_since", "inserted_at", "schema_version"],
"start_vertex": {
"csv_path": "data/paymemt/creditcard.csv",
"id": "id",
"label": "CreditCard",
"props": [
"available_since",
"inserted_at",
"expiry_month",
"expiry_year",
"masked_number",
"creditcard_identifier",
"schema_version"
]
},
"end_vertex": {
"csv_path": "data/paymemt/payment.csv",
"id": "id",
"label": "Payment",
"props": [
"available_since",
"inserted_at",
"payment_id",
"schema_version"
]
}
},
{
"csv_path": "data/paymemt/performedby_cookie_payment.csv",
"type": "PerformedBy",
"props": ["available_since", "inserted_at", "schema_version"],
"start_vertex": {
"csv_path": "data/paymemt/cookie.csv",
"id": "id",
"label": "Cookie",
"props": ["available_since", "inserted_at", "uaid", "schema_version"]
},
"end_vertex": {
"csv_path": "data/paymemt/payment.csv",
"id": "id",
"label": "Payment",
"props": [
"available_since",
"inserted_at",
"payment_id",
"schema_version"
]
}
},
{
"csv_path": "data/paymemt/performedby_creditcard_payment.csv",
"type": "PerformedBy",
"props": ["available_since", "inserted_at", "schema_version"],
"start_vertex": {
"csv_path": "data/paymemt/creditcard.csv",
"id": "id",
"label": "CreditCard",
"props": [
"available_since",
"inserted_at",
"expiry_month",
"expiry_year",
"masked_number",
"creditcard_identifier",
"schema_version"
]
},
"end_vertex": {
"csv_path": "data/paymemt/payment.csv",
"id": "id",
"label": "Payment",
"props": [
"available_since",
"inserted_at",
"payment_id",
"schema_version"
]
}
}
]
}
And the contents of the CSV files:
"id","available_since","inserted_at","uaid","schema_version"
"1","2025-01-13 03:17:10.612472","2025-01-13 03:17:10.612472","a3ef7bff-1d7f-4e59-9963-79139940d9b4","1"
"2","2025-01-02 02:05:26.888933","2025-01-02 02:05:26.888933","23cbd6f6-b11d-4594-a2b5-87243725abe1","1"
"3","2025-01-03 14:46:58.899109","2025-01-03 14:46:58.899109","0891cfda-3c0a-4089-ba35-a5b30c0e2d26","1"
"4","2025-01-04 18:57:37.857941","2025-01-04 18:57:37.857941","2e8c8f67-b1cd-429d-b856-3599ee2cdd59","1"
"id","available_since","inserted_at","expiry_month","expiry_year","masked_number","creditcard_identifier","schema_version"
"1","2025-01-22 00:25:27.612965","2025-01-22 00:25:27.612965","12","1969","30473257263635","28d9abb3-0ce5-415e-b179-3aef91d9aaab","1"
"2","2025-01-18 16:23:55.876961","2025-01-18 16:23:55.876961","12","1969","4618391378453392","a4050d78-a224-4269-9377-5b7fa39d4c4e","1"
"3","2025-01-20 11:23:23.517449","2025-01-20 11:23:23.517449","12","1969","2720988758344312","ba65d7ff-769c-441a-bce6-3a9daae1a7a7","1"
"4","2025-01-17 03:11:17.633718","2025-01-17 03:11:17.633718","12","1969","2706558801011685","7cde9b77-ba58-4779-b435-3a22733a363a","1"
"id","available_since","inserted_at","payment_id","schema_version"
"1","2025-01-06 06:03:20.048255","2025-01-06 06:03:20.048255","8dd082fa-cb55-450c-aee4-04893a282f41","1"
"2","2025-01-13 20:41:58.478938","2025-01-13 20:41:58.478938","ec490576-65ca-414f-9914-929ba1ffe26f","1"
"3","2025-01-19 07:58:39.699038","2025-01-19 07:58:39.699038","124659b6-0d7c-4de1-bba8-6de9f1dfee3c","1"
"4","2025-01-10 00:33:53.890556","2025-01-10 00:33:53.890556","6a455a45-a156-44e4-8f01-0750a8f2a9ca","1"
data/paymemt/usedin_cookie_payment.csv
"id","start_id","start_vertex_type","end_id","end_vertex_type","available_since","inserted_at","schema_version"
"1","251","Cookie","10","Payment","2025-01-01 22:27:01.284325","2025-01-01 22:27:01.284325","1"
"2","1045","Cookie","4967","Payment","2025-01-02 09:39:38.392602","2025-01-02 09:39:38.392602","1"
"3","351","Cookie","6635","Payment","2025-01-09 13:35:43.667663","2025-01-09 13:35:43.667663","1"
"4","714","Cookie","6532","Payment","2025-01-19 23:54:52.656538","2025-01-19 23:54:52.656538","1"
data/paymemt/usedin_creditcard_payment.csv
"id","start_id","start_vertex_type","end_id","end_vertex_type","available_since","inserted_at","schema_version"
"1","592","CreditCard","1252","Payment","2025-01-17 19:03:49.372280","2025-01-17 19:03:49.372280","1"
"2","353","CreditCard","6369","Payment","2025-01-02 12:14:50.556809","2025-01-02 12:14:50.556809","1"
"3","815","CreditCard","3581","Payment","2025-01-06 02:18:22.648581","2025-01-06 02:18:22.648581","1"
"4","1187","CreditCard","5420","Payment","2025-01-12 12:09:19.853148","2025-01-12 12:09:19.853148","1"
data/paymemt/performedby_cookie_payment.csv
"id","start_id","start_vertex_type","end_id","end_vertex_type","available_since","inserted_at"
"1","211","Cookie","6806","Payment","2025-01-15 18:16:30.558804","2025-01-15 18:16:30.558804"
"2","900","Cookie","4174","Payment","2025-01-03 04:26:16.651747","2025-01-03 04:26:16.651747"
"3","1002","Cookie","5877","Payment","2025-01-15 00:25:23.377948","2025-01-15 00:25:23.377948"
"4","215","Cookie","2852","Payment","2025-01-05 15:35:52.251420","2025-01-05 15:35:52.251420"
data/paymemt/performedby_creditcard_payment.csv
"id","start_id","start_vertex_type","end_id","end_vertex_type","available_since","inserted_at"
"1","719","CreditCard","1532","Payment","2025-01-05 18:59:48.910719","2025-01-05 18:59:48.910719"
"2","1025","CreditCard","2153","Payment","2025-01-03 17:06:29.660728","2025-01-03 17:06:29.660728"
"3","563","CreditCard","2622","Payment","2025-01-01 05:33:03.489332","2025-01-01 05:33:03.489332"
"4","1042","CreditCard","350","Payment","2025-01-12 06:40:14.256650","2025-01-12 06:40:14.256650"
Load from Cosmos DB
To load graph data created with Cosmos DB for Apache Gremlin API via Cosmos DB for NoSQL API, use the following command:
(supposed $PG_CONNECTION_STRING is set)
agefreighter load --source-type cosmosdb --cosmos-endpoint https://YOUR_ACCOUNT.documents.azure.com:443/ --cosmos-key YOUR_KEY --cosmos-database YOUR_DB --cosmos-container YOUR_CONTAINER
Or, you can use the environment variables:
- macOS / Linux
export COSMOS_ENDPOINT="http://YOUR_ACCOUNT.documents.azure.com:443/"
export COSMOS_KEY="YOUR_KEY"
export COSMOS_DATABASE="YOUR_DB"
export COSMOS_CONTAINER="YOUR_CONTAINER"
- Windows (cmd.exe)
set COSMOS_ENDPOINT=http://YOUR_ACCOUNT.documents.azure.com:443/
set COSMOS_KEY=YOUR_KEY
set COSMOS_DATABASE=YOUR_DB
set COSMOS_CONTAINER=YOUR_CONTAINER
- PowerShell
$env:COSMOS_ENDPOINT="http://YOUR_ACCOUNT.documents.azure.com:443/"
$env:COSMOS_KEY="YOUR_KEY"
$env:COSMOS_DATABASE="YOUR_DB"
$env:COSMOS_CONTAINER="YOUR_CONTAINER"
If all the required environment variables are set, you can just run:
agefreighter load --source-type cosmos
Load from PostgreSQL
To load data from PostgreSQL, you need to prepare a configuration JSON file that specifies how to dump from your 'source' PostgreSQL and load the data into your 'target'PostgreSQL with Apache AGE. The configuration JSON files are very similar to ones for CSV.
(supposed $PG_CONNECTION_STRING is set)
agefreighter load --source-type pgsql --src-pg-con-str "host=localhost port=5432 dbname=postgres user=YOUR_USERNAME password=YOUR_PASSWORD" --config config.json
Or, you can use the environment variables:
- macOS / Linux
export SRC_PG_CONNECTION_STRING="host=localhost port=5432 dbname=postgres user=YOUR_USERNAME password=YOUR_PASSWORD"
- Windows (cmd.exe)
set SRC_PG_CONNECTION_STRING=host=localhost port=5432 dbname=postgres user=YOUR_USERNAME password=YOUR_PASSWORD
- PowerShell
$env:SRC_PG_CONNECTION_STRING="host=localhost port=5432 dbname=postgres user=YOUR_USERNAME password=YOUR_PASSWORD"
If all the required environment variables are set, you can just run:
agefreighter load --source-type pgsql --config config.json
We have 4 structure patterns of nodes and edges.
- Single kind of nodes and single kind of edges:
(AirPort) - [AirRoute] -> (AirPort)
This pattern is described in JSON as follows docs/configs/pgsql/single_edge_single_node.json:
{
"edge": {
"table": "airroute",
"type": "airroute",
"start_id": "start_id",
"end_id": "end_id",
"props": ["distance"],
"start_vertex": {
"table": "airroute",
"id": "start_id",
"label": "airport",
"props": []
},
"end_vertex": {
"table": "airroute",
"id": "end_id",
"label": "airport",
"props": []
}
}
}
And the table, 'airroute':
CREATE TABLE airroute (
id SERIAL PRIMARY KEY,
start_id INTEGER NOT NULL,
end_id INTEGER NOT NULL,
distance INTEGER NOT NULL
);
- Single kind of nodes and multiple kinds of edges:
(Person) - [KNOWS | LIKES] -> (Person)
This pattern is described in JSON as follows docs/configs/pgsql/multiple_edges_single_node.json:
{
"edge": {
"table": "has",
"type": "has",
"start_id": "country_id",
"end_id": "city_id",
"props": ["since"],
"start_vertex": {
"table": "country",
"id": "id",
"label": "Country",
"props": ["Name", "Capital", "Population", "ISO", "TLD", "FlagURL"]
},
"end_vertex": {
"table": "city",
"id": "id",
"label": "City",
"props": ["Name", "Latitude", "Longitude"]
}
}
}
And the tables:
CREATE TABLE country (
id SERIAL PRIMARY KEY,
Name VARCHAR(255) NOT NULL,
Capital VARCHAR(255) NOT NULL,
Population INTEGER NOT NULL,
ISO VARCHAR(2) NOT NULL,
TLD VARCHAR(5) NOT NULL,
FlagURL VARCHAR(255) NOT NULL
);
CREATE TABLE city (
id SERIAL PRIMARY KEY,
Name VARCHAR(255) NOT NULL,
Latitude DECIMAL(9,6) NOT NULL,
Longitude DECIMAL(9,6) NOT NULL
);
CREATE TABLE has (
id SERIAL PRIMARY KEY,
country_id INTEGER NOT NULL REFERENCES country(id),
city_id INTEGER NOT NULL REFERENCES city(id),
since DATE NOT NULL
);
- Multiple kinds of nodes and single kind of edges:
(Country) - [has] -> (City)
This pattern is described in JSON as follows docs/configs/pgsql/single_edge_multiple_nodes.json:
{
"edge": [
{
"table": "knows",
"type": "KNOWS",
"start_id": "person1_id",
"end_id": "person2_id",
"props": ["since"],
"vertex": {
"table": "person",
"id": "id",
"label": "Person",
"props": ["Name"]
}
},
{
"table": "likes",
"type": "LIKES",
"start_id": "person1_id",
"end_id": "person2_id",
"props": ["since"],
"vertex": {
"table": "person",
"id": "id",
"label": "Person",
"props": ["Name"]
}
}
]
}
And the tables:
CREATE TABLE person (
id SERIAL PRIMARY KEY,
Name VARCHAR(255) NOT NULL
);
CREATE TABLE knows (
id SERIAL PRIMARY KEY,
person1_id INTEGER NOT NULL REFERENCES person(id),
person2_id INTEGER NOT NULL REFERENCES person(id),
since DATE NOT NULL
);
CREATE TABLE likes (
id SERIAL PRIMARY KEY,
person1_id INTEGER NOT NULL REFERENCES person(id),
person2_id INTEGER NOT NULL REFERENCES person(id),
since DATE NOT NULL
);
- Multiple kinds of nodes and multiple kinds of edges:
(Cookie | CreditCard) - [UsedIn | PerformedBy] -> (Payment)
This pattern is a little complicatedlly described in JSON as follows docs/configs/pgsql/multiple_edges_multiple_nodes.json:
{
"edge": [
{
"table": "usedin_cookie_payment",
"type": "UsedIn",
"start_id": "cookie_id",
"end_id": "payment_id",
"props": ["available_since", "inserted_at", "schema_version"],
"start_vertex": {
"table": "cookie",
"id": "id",
"label": "Cookie",
"props": ["available_since", "inserted_at", "uaid", "schema_version"]
},
"end_vertex": {
"table": "payment",
"id": "id",
"label": "Payment",
"props": [
"available_since",
"inserted_at",
"payment_id",
"schema_version"
]
}
},
{
"table": "usedin_creditcard_payment",
"type": "UsedIn",
"start_id": "creditcard_id",
"end_id": "payment_id",
"props": ["available_since", "inserted_at", "schema_version"],
"start_vertex": {
"table": "creditcard",
"id": "id",
"label": "CreditCard",
"props": [
"available_since",
"inserted_at",
"expiry_month",
"expiry_year",
"masked_number",
"creditcard_identifier",
"schema_version"
]
},
"end_vertex": {
"table": "payment",
"id": "id",
"label": "Payment",
"props": [
"available_since",
"inserted_at",
"payment_id",
"schema_version"
]
}
},
{
"table": "performedby_cookie_payment",
"type": "PerformedBy",
"start_id": "cookie_id",
"end_id": "payment_id",
"props": ["available_since", "inserted_at", "schema_version"],
"start_vertex": {
"table": "cookie",
"id": "id",
"label": "Cookie",
"props": ["available_since", "inserted_at", "uaid", "schema_version"]
},
"end_vertex": {
"table": "payment",
"id": "id",
"label": "Payment",
"props": [
"available_since",
"inserted_at",
"payment_id",
"schema_version"
]
}
},
{
"table": "performedby_creditcard_payment",
"type": "PerformedBy",
"start_id": "creditcard_id",
"end_id": "payment_id",
"props": ["available_since", "inserted_at", "schema_version"],
"start_vertex": {
"table": "creditcard",
"id": "id",
"label": "CreditCard",
"props": [
"available_since",
"inserted_at",
"expiry_month",
"expiry_year",
"masked_number",
"creditcard_identifier",
"schema_version"
]
},
"end_vertex": {
"table": "payment",
"id": "id",
"label": "Payment",
"props": [
"available_since",
"inserted_at",
"payment_id",
"schema_version"
]
}
}
]
}
And the tables:
CREATE TABLE cookie (
id SERIAL PRIMARY KEY,
available_since TIMESTAMP NOT NULL,
inserted_at TIMESTAMP NOT NULL,
uaid VARCHAR(36) NOT NULL,
schema_version INTEGER NOT NULL
);
CREATE TABLE creditcard (
id SERIAL PRIMARY KEY,
available_since TIMESTAMP NOT NULL,
inserted_at TIMESTAMP NOT NULL,
expiry_month INTEGER NOT NULL,
expiry_year INTEGER NOT NULL,
masked_number VARCHAR(32) NOT NULL,
creditcard_identifier VARCHAR(36) NOT NULL,
schema_version INTEGER NOT NULL
);
CREATE TABLE payment (
id SERIAL PRIMARY KEY,
available_since TIMESTAMP NOT NULL,
inserted_at TIMESTAMP NOT NULL,
payment_id VARCHAR(36) NOT NULL,
schema_version INTEGER NOT NULL
);
CREATE TABLE usedin_cookie_payment (
id SERIAL PRIMARY KEY,
cookie_id INTEGER NOT NULL REFERENCES cookie(id),
payment_id INTEGER NOT NULL REFERENCES payment(id),
available_since TIMESTAMP NOT NULL,
inserted_at TIMESTAMP NOT NULL,
schema_version INTEGER NOT NULL
);
CREATE TABLE usedin_creditcard_payment (
id SERIAL PRIMARY KEY,
creditcard_id INTEGER NOT NULL REFERENCES creditcard(id),
payment_id INTEGER NOT NULL REFERENCES payment(id),
available_since TIMESTAMP NOT NULL,
inserted_at TIMESTAMP NOT NULL,
schema_version INTEGER NOT NULL
);
CREATE TABLE performedby_cookie_payment (
id SERIAL PRIMARY KEY,
cookie_id INTEGER NOT NULL REFERENCES cookie(id),
payment_id INTEGER NOT NULL REFERENCES payment(id),
available_since TIMESTAMP NOT NULL,
inserted_at TIMESTAMP NOT NULL,
schema_version INTEGER NOT NULL
);
CREATE TABLE performedby_creditcard_payment (
id SERIAL PRIMARY KEY,
creditcard_id INTEGER NOT NULL REFERENCES creditcard(id),
payment_id INTEGER NOT NULL REFERENCES payment(id),
available_since TIMESTAMP NOT NULL,
inserted_at TIMESTAMP NOT NULL,
schema_version INTEGER NOT NULL
);
view subcommand
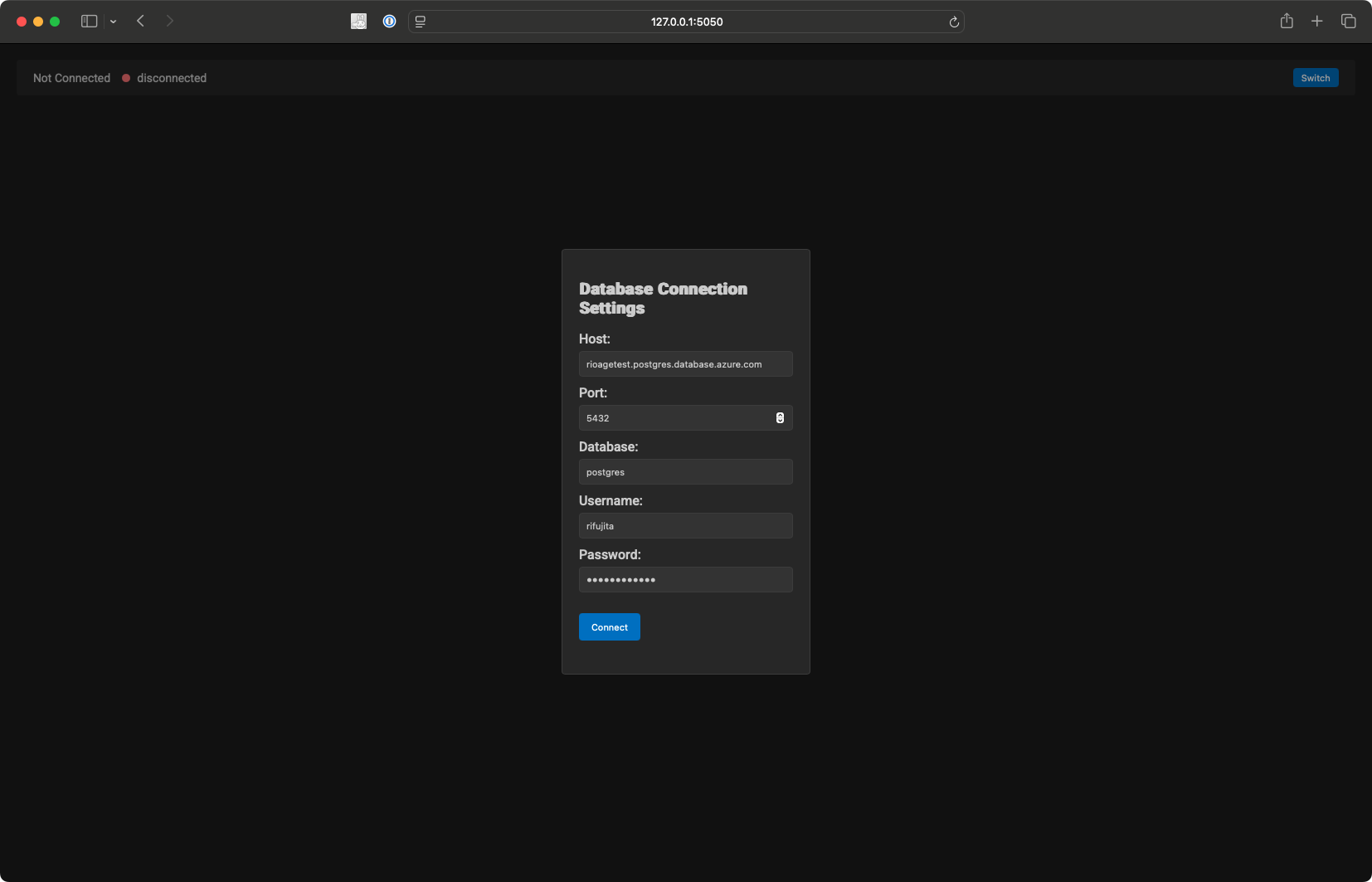
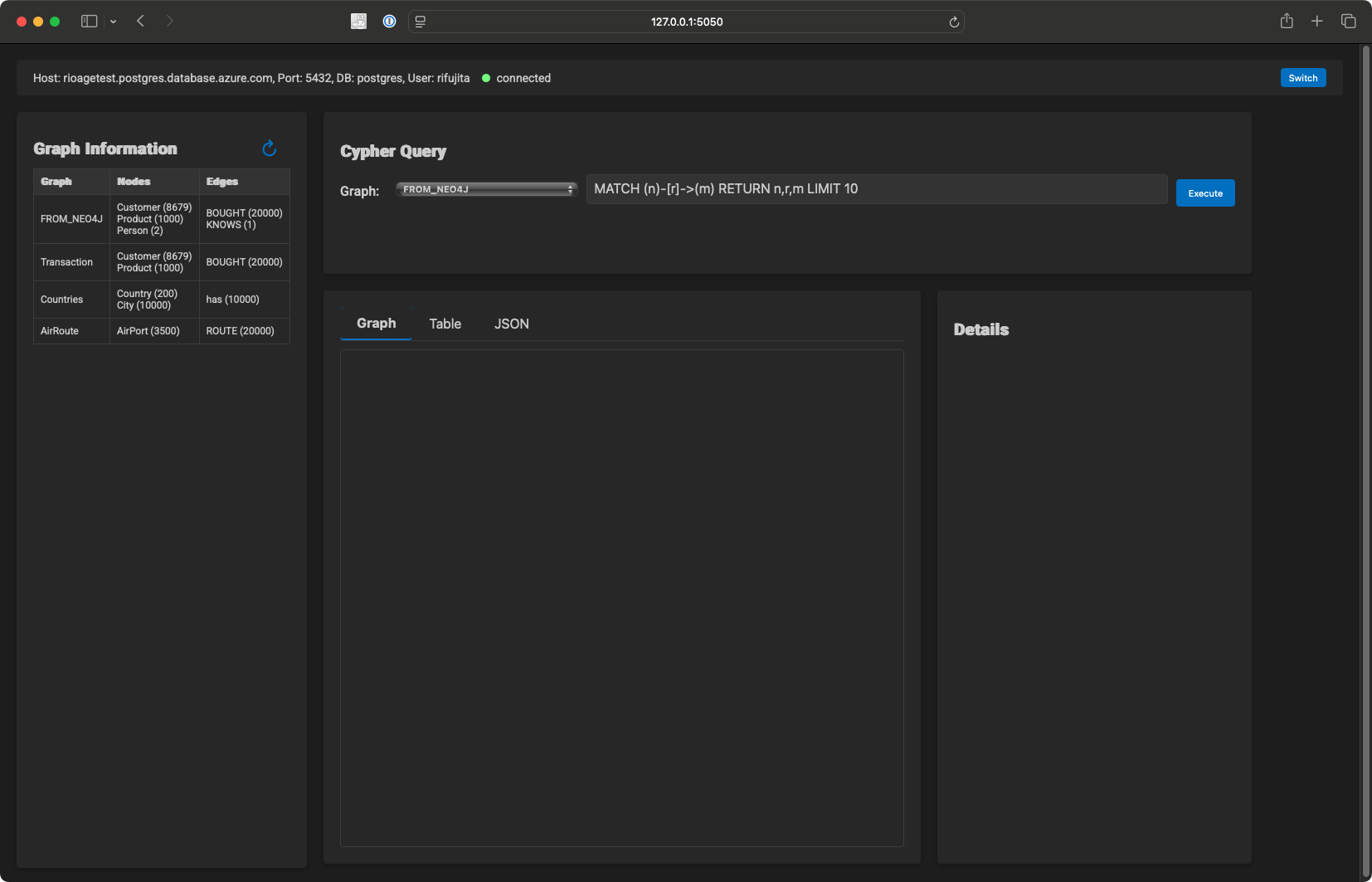
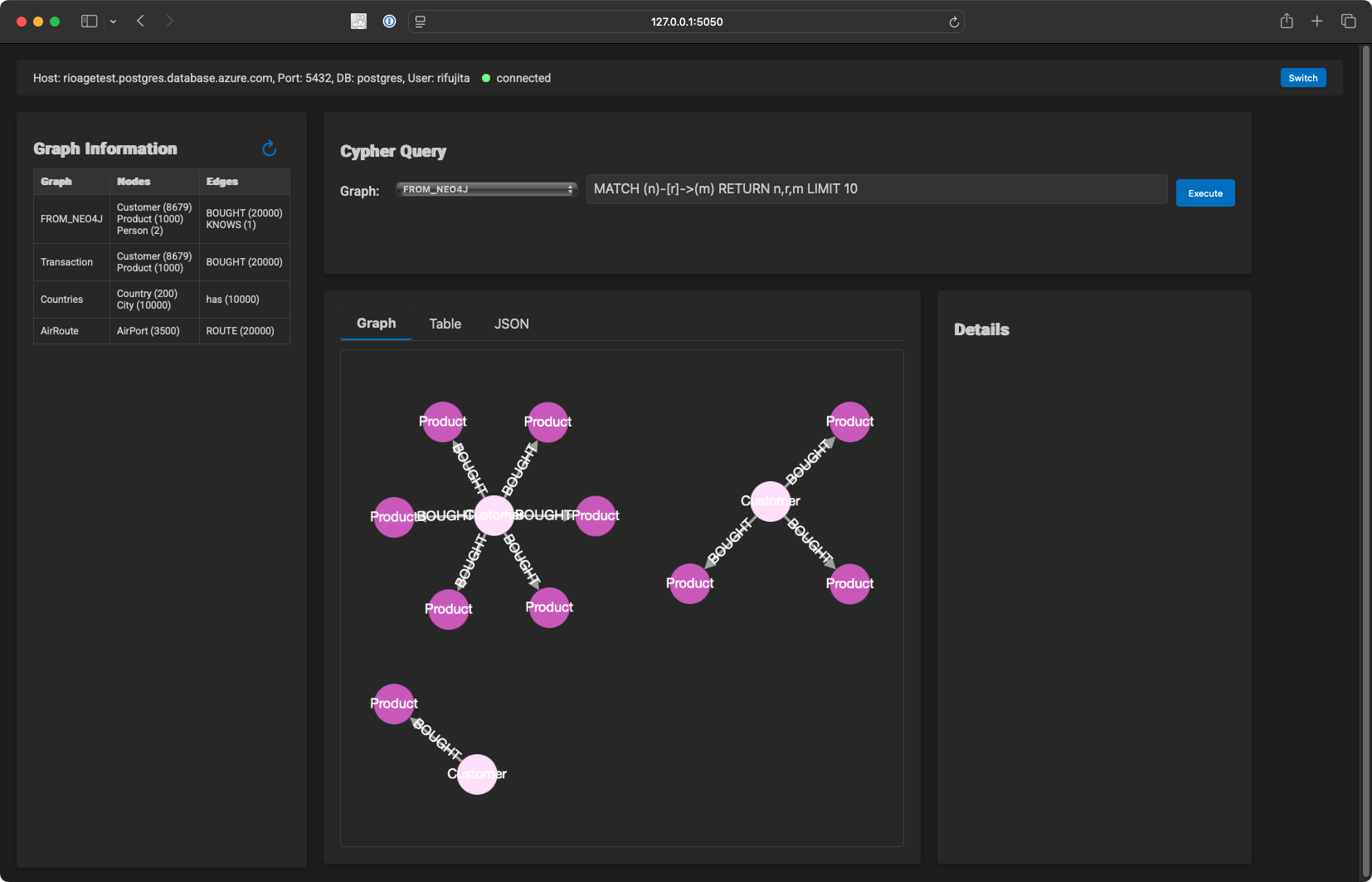
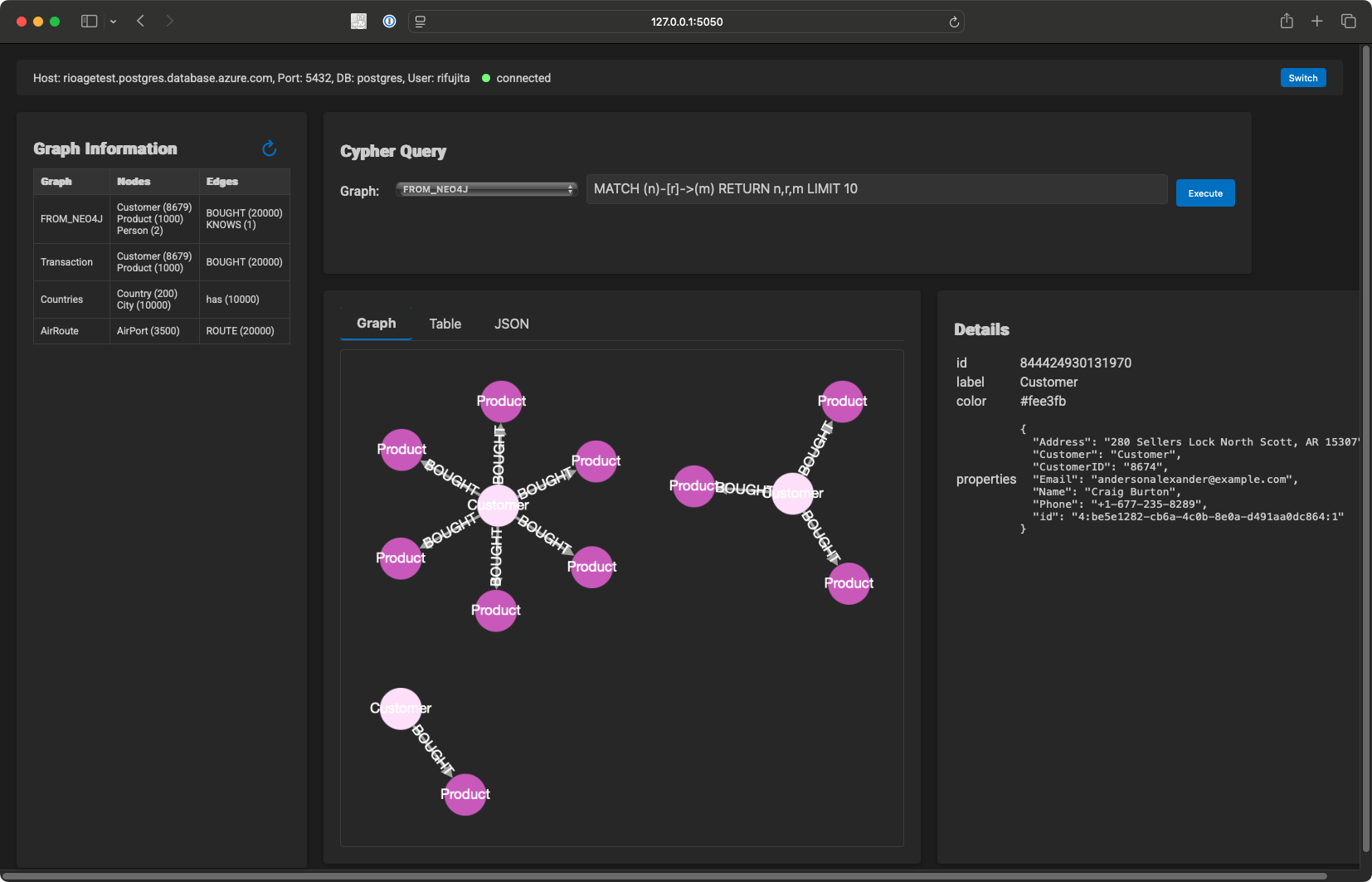
If you want just to view the graph data on PostgreSQL, I also provide a Docker image on Docker Hub.
agefreighter view --help
usage: agefreighter view [-h] [--flask-port FLASK_PORT]
options:
-h, --help show this help message and exit
--flask-port FLASK_PORT
Port to run the server on
You can watch the graph data on PostgreSQL by running the following command:
(supposed $PG_CONNECTION_STRING is set)
agefreighter view
INFO:werkzeug:WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead.
* Running on http://127.0.0.1:5000
INFO:werkzeug:Press CTRL+C to quit
Click on the link above to open the graph data in your browser.
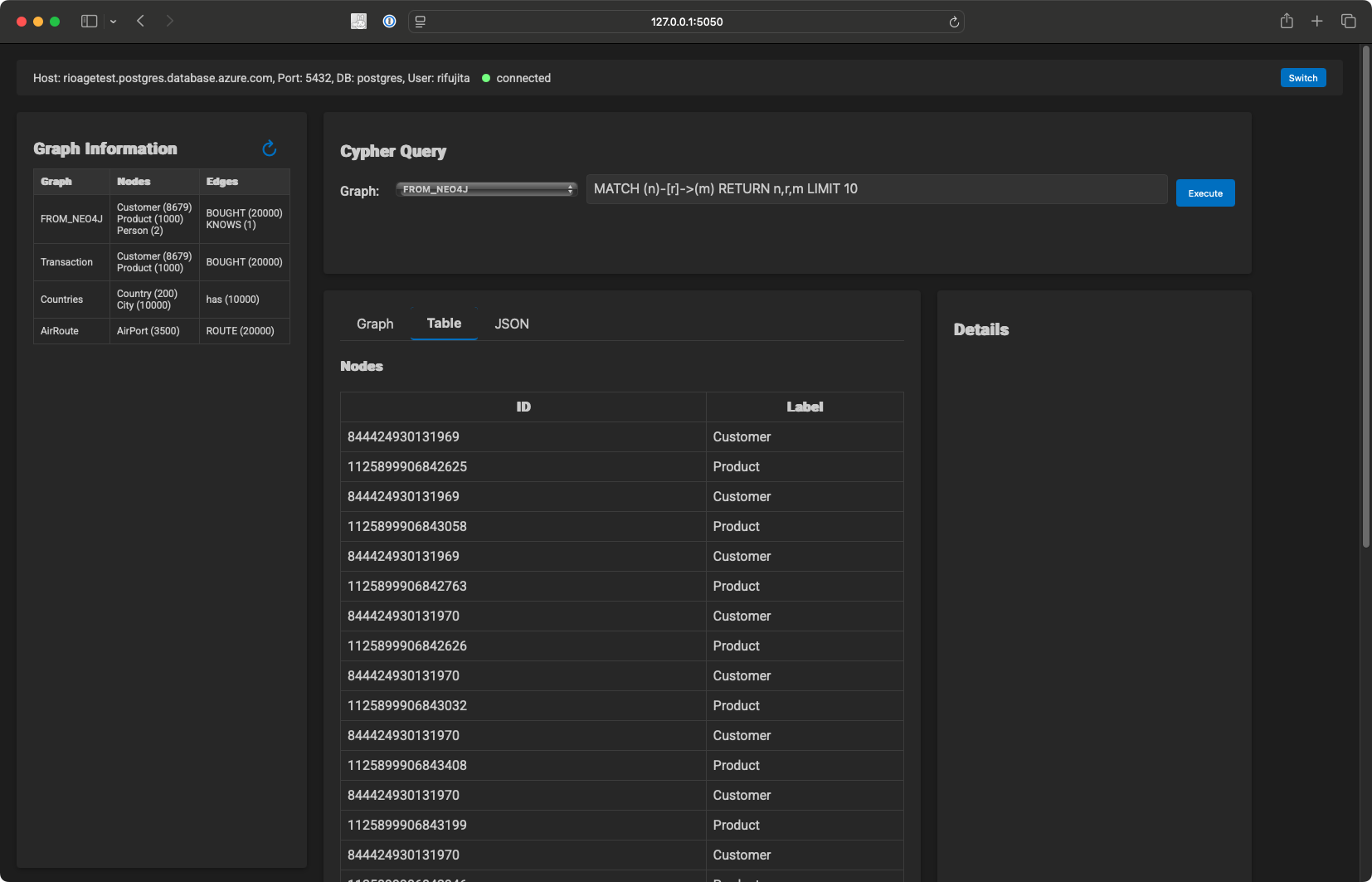
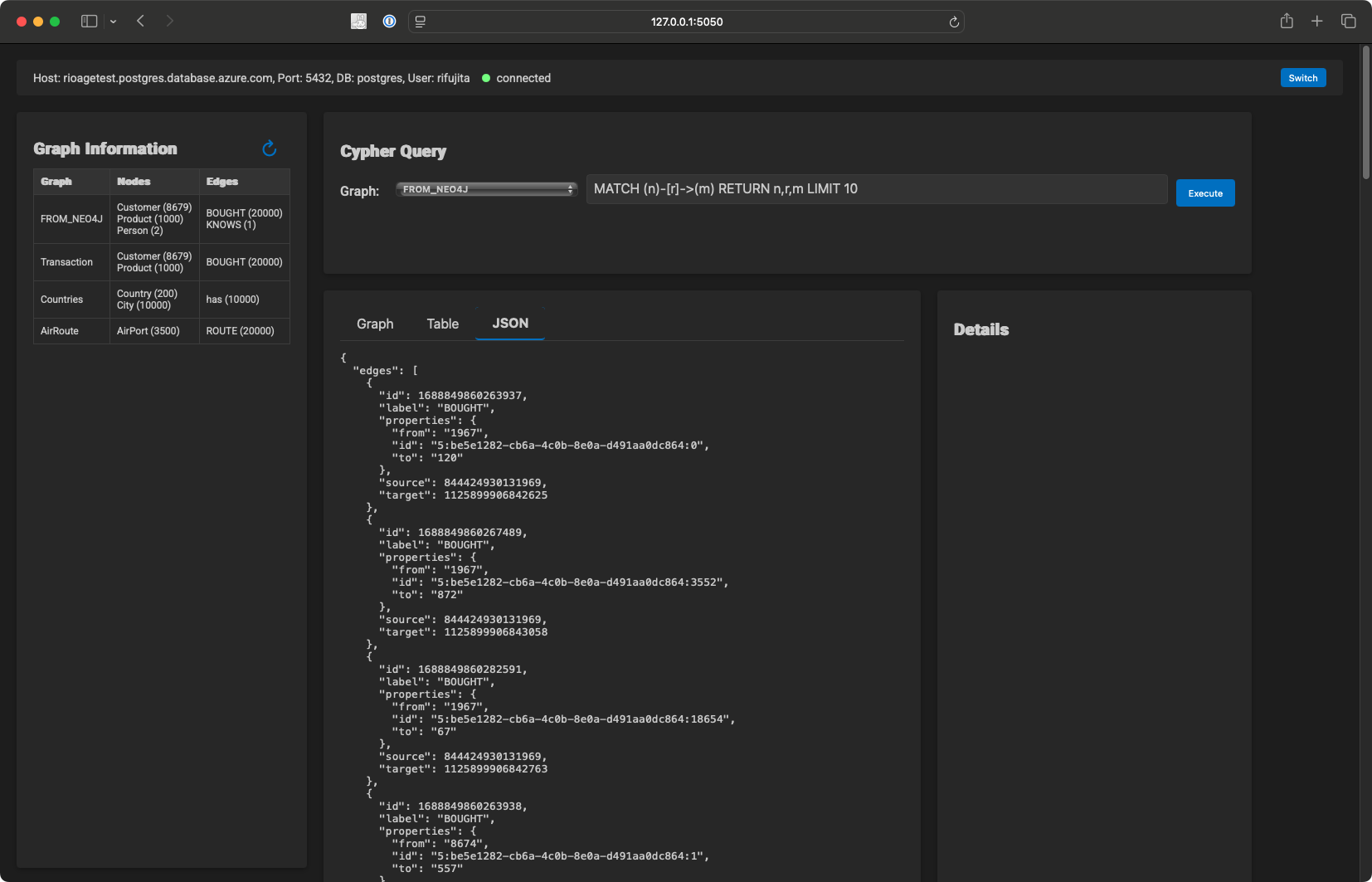
convert subcommand
agefreighter convert --help
usage: agefreighter convert [-h] [-l {gremlin,cypher}] [-k OPENAI_API_KEY] [-m MODEL] [-d] [--pg-con-str-for-dryrun PG_CON_STR_FOR_DRYRUN] [--graph-for-dryrun GRAPH_FOR_DRYRUN] (-q QUERY | -f FILEPATH | -u URL)
options:
-h, --help show this help message and exit
-l, --query-language {gremlin,cypher}
Source language of the query
-k, --openai-api-key OPENAI_API_KEY
OpenAI API key to use.
-m, --model MODEL OpenAI model to use.
-d, --dryrun Dry run with PostgreSQL.
--pg-con-str-for-dryrun PG_CON_STR_FOR_DRYRUN
Connection string of the Azure Database for PostgreSQL
--graph-for-dryrun GRAPH_FOR_DRYRUN
Graph name for dry run with PostgreSQL.
-q, --query QUERY Graph name for dry run with PostgreSQL.
-f, --filepath FILEPATH
Path to the source code file (.py, .java, .cs, .txt)
-u, --url URL URL to the source code file (.py, .java, .cs, .txt)
The indentical usage is shown below.
with -l gremlin -q
agefreighter convert -l gremlin -q 'g.V().has(“name”, “Alice”).as(“a”).V().has(“name”, “Bob”).as(“b”).select(“a”, “b”).by(“name”)'
Converted Cypher queries:
line 1, g.V().has("name", "Alice").as("a").V().has("name", "Bob").as("b").select("a", "b").by("name") ->
SELECT * FROM cypher('GRAPH_FOR_DRYRUN', $$ MATCH (a {name: "Alice"}), (b {name: "Bob"}) RETURN a.name AS a, b.name AS b $$) AS (a agtype, b agtype);
with -l gremlin -u(--url)
agefreighter convert -l gremlin -u https://raw.githubusercontent.com/nedlowe/gremlin-python-example/refs/heads/master/app.py
Converted Cypher queries:
line 42, g.V(person_id).toList() ->
DEALLOCATE ALL; PREPARE cypher_stored_procedure(agtype) AS SELECT * FROM cypher('GRAPH_FOR_DRYRUN', $$ MATCH (n) WHERE id(n) = $person_id RETURN n $$, $1) AS (n agtype);EXECUTE cypher_stored_procedure('{"person_id": 12345}');
line 42, g.V(person_id) ->
DEALLOCATE ALL; PREPARE cypher_stored_procedure(agtype) AS SELECT * FROM cypher('GRAPH_FOR_DRYRUN', $$ MATCH (n) WHERE id(n) = $person_id RETURN n $$, $1) AS (n agtype);EXECUTE cypher_stored_procedure('{"person_id": 12345}');
line 55, g.V(vertex).valueMap().toList() ->
DEALLOCATE ALL; PREPARE cypher_stored_procedure(agtype) AS SELECT * FROM cypher('GRAPH_FOR_DRYRUN', $$ MATCH (n) WHERE ID(n) = $vertex RETURN properties(n) $$, $1) AS (properties agtype);EXECUTE cypher_stored_procedure('{"vertex": 12345}');
......
with -l gremlin -f(--filepath)
agefreighter convert -l gremlin -f docs/gremlin_samples.py
Converted Cypher queries:
line 1, g.V() ->
SELECT * FROM cypher('GRAPH_FOR_DRYRUN', $$ MATCH (n) RETURN n $$) AS (n agtype);
line 2, g.E() ->
SELECT * FROM cypher('GRAPH_FOR_DRYRUN', $$ MATCH ()-[r]-() RETURN r $$) AS (r agtype);
line 3, g.V().hasLabel('person') ->
SELECT * FROM cypher('GRAPH_FOR_DRYRUN', $$ MATCH (n:person) RETURN n $$) AS (n agtype);
line 4, g.V().hasLabel('software') ->
SELECT * FROM cypher('GRAPH_FOR_DRYRUN', $$ MATCH (n:software) RETURN n $$) AS (n agtype);
......
with -l gremlin -d(--dryrun) -q
agefreighter convert -l gremlin -d -q "g.V().hasLabel('person').aggregate('a')"
Converted Cypher queries:
line 1, g.V().hasLabel('person').aggregate('a') ->
SELECT * FROM cypher('GRAPH_FOR_DRYRUN', $$ MATCH (n:person) WITH collect(n) AS a RETURN a $$) AS (a agtype);
[Query executed successfully]
agefreighter convert -l gremlin -d -q "g.V(person).property(prop_name, prop_value)"
Converted Cypher queries:
line 1, g.V(person).property(prop_name, prop_value) ->
DEALLOCATE ALL; PREPARE cypher_stored_procedure(agtype) AS SELECT * FROM cypher('GRAPH_FOR_DRYRUN', $$ MATCH (n) WHERE ID(n) = $person SET n[$prop_name] = $prop_value RETURN n $$, $1) AS (n agtype);EXECUTE cypher_stored_procedure('{"person": 12345, "prop_name": 12345, "prop_value": 12345}');
[Error executing query: SET clause expects a property name
LINE 2: ...R_DRYRUN', $$ MATCH (n) WHERE ID(n) = $person SET n[$prop_na...
^]
with -l cypher -q
agefreighter convert -l cypher -q 'MATCH (n) RETURN n'
Converted Cypher queries for Apache AGE:
line 1, MATCH (n) RETURN n ->
SELECT * FROM cypher('GRAPH_FOR_DRYRUN', $$ MATCH (n) RETURN n $$) AS (n agtype);
parse subcommand
agefreighter parse --help
usage: agefreighter parse [-h] cypher_query
positional arguments:
cypher_query Cypher query to be parsed
options:
-h, --help show this help message and exit
agefreighter parse "CREATE (adam:User {name: 'Adam'}), (pernilla:User {name: 'Pernilla'}), (david:User {name: 'David'}), (adam)-[:FRIEND]->(pernilla), (pernilla)-[:FRIEND]->(david)"
[('CREATE', [('node', 'adam', ['User'], [('name', 'Adam')]), ('node', 'pernilla', ['User'], [('name', 'Pernilla')]), ('node', 'david', ['User'], [('name', 'David')]), ('chain', ('node', 'adam', [], None), [(('directed', ('relationship', [{'variable': None, 'type': 'FRIEND'}], None, None)), ('node', 'pernilla', [], None))]), ('chain', ('node', 'pernilla', [], None), [(('directed', ('relationship', [{'variable': None, 'type': 'FRIEND'}], None, None)), ('node', 'david', [], None))])])]
generate subcommand
agefreighter generate --help
usage: agefreighter generate [-h] [--pattern-no PATTERN_NO] [--multiplier MULTIPLIER]
options:
-h, --help show this help message and exit
--pattern-no PATTERN_NO
Pattern number to generate
--multiplier MULTIPLIER
Multiplier for the number of nodes and edges
agefreighter generate --pattern-no 1
Creating directory generated_dummy_20250308_132130
Creating directory generated_dummy_20250308_132130/transaction
Generating Bought: 20050...
head generated_dummy_20250308_132130/transaction/customer_product_bought.csv
"id","start_id","start_vertex_type","Name","Address","Email","Phone","end_id","end_vertex_type","Phrase","SKU","Price","Color","Size","Weight"
"1","9233","Customer","Julie Williamson","168 Smith Walks Suite 295 Jacksonville, MA 08548","joshua82@example.com","503.987.6985x70933","205","Product","Networked reciprocal challenge","0102257078617","169.55","BlanchedAlmond","S","257"
"2","2765","Customer","Laura Hall","5840 Schneider Row Apt. 902 Port Tinafurt, VI 31305","xhunt@example.com","(688)567-4883x722","399","Product","Streamlined background parallelism","6243358057911","761.59","LavenderBlush","L","994"
"3","5682","Customer","Stefanie Dawson","622 Roy Prairie Lake Cheryl, DE 04519","jared70@example.com","772.783.0617x206","757","Product","Object-based demand-driven encryption","2539370263589","807.36","LightBlue","M","838"
"4","1888","Customer","Amy Orr","32361 Green Ports Port Steven, VA 20010","joesampson@example.net","228.860.4374","121","Product","Optional cohesive success","3053544413475","400.16","Lavender","M","492"
"5","525","Customer","Dana Cook","7517 Hannah Crest Port Sabrina, WY 86600","angelamoore@example.com","714-219-2207x67960","123","Product","Synergistic bifurcated contingency","8416136503223","390.23","PaleTurquoise","L","686"
"6","3087","Customer","Phillip Booker","665 Hailey Ports North Ronaldmouth, ND 28714","david41@example.net","+1-955-721-5633x28944","224","Product","Realigned real-time encryption","1460321914797","901.44","SpringGreen","S","331"
"7","3134","Customer","Miranda Wilson","82965 Dakota Squares Apt. 260 Meganville, OR 32907","david03@example.org","7676919040","150","Product","Balanced modular approach","3699817802098","629.91","ForestGreen","S","905"
"8","7935","Customer","Victoria Lowe","00325 Tiffany Mount North Morgan, AS 36897","shawn47@example.com","5587080795","795","Product","Intuitive well-modulated superstructure","3671127475940","795.46","LimeGreen","M","856"
"9","7597","Customer","Dr. Jessica Mcintosh MD","9870 William Trafficway Apt. 430 Robynport, AZ 81619","gonzalezjohn@example.org","(881)385-8102","882","Product","Inverse national contingency","7080557840833","532.9","Purple","XL","966"
prepare subcommand
agefreighter prepare --help
usage: agefreighter prepare [-h] [--target-type {neo4j,cosmosdb,pgsql}] [--data-dir DATA_DIR] [--base-file BASE_FILE] [--neo4j-uri NEO4J_URI] [--neo4j-user NEO4J_USER] [--neo4j-password NEO4J_PASSWORD]
[--neo4j-database NEO4J_DATABASE] [--cosmos-gremlin-endpoint COSMOS_GREMLIN_ENDPOINT] [--cosmos-key COSMOS_KEY] [--cosmos-database COSMOS_DATABASE]
[--cosmos-container COSMOS_CONTAINER] [--src-pg-con-str SRC_PG_CON_STR]
options:
-h, --help show this help message and exit
--target-type {neo4j,cosmosdb,pgsql}
Targeted type of the source of graph data.
--data-dir DATA_DIR Directory containing the data files
--base-file BASE_FILE
Base file name for the data files
--neo4j-uri NEO4J_URI
Neo4j URI
--neo4j-user NEO4J_USER
Neo4j username
--neo4j-password NEO4J_PASSWORD
Neo4j password
--neo4j-database NEO4J_DATABASE
Neo4j database
--cosmos-gremlin-endpoint COSMOS_GREMLIN_ENDPOINT
Cosmos Gremlinendpoint
--cosmos-key COSMOS_KEY
Cosmos key
--cosmos-database COSMOS_DATABASE
Cosmos database
--cosmos-container COSMOS_CONTAINER
Cosmos container
--src-pg-con-str SRC_PG_CON_STR
Source PostgreSQL connection string
Windows Security Warning
When trying to execute load on Windows, you might encounter a security warning that prevents it from starting. This is often due to Windows SmartScreen or your antivirus/firewall software blocking the app. Here are some steps you can take:
• SmartScreen:
When the security warning appears, click on “More info” and then select “Run anyway” to bypass the warning and launch the app.
• Firewall/Antivirus Settings:
Check your Windows Defender or any other security software settings to ensure that Python and Flask are not being blocked. You may need to add an exception or whitelist for the application.
• Run as Administrator:
Try running your command prompt or PowerShell as an administrator and then start the Flask application.
If these steps do not resolve the issue, there might be a problem with your Flask application or the environment setup. In that case, review the error messages or logs for additional details.
How to edit the CSV files to load them to the graph database with AGEFreighter
Example: krlawrence graph
-
Download air-routes-latest-edges.csv and air-routes-latest-nodes.csv
-
Edit air-routes-latest-nodes.csv
- original
~id,~label,type:string,code:string,icao:string,desc:string,region:string,runways:int,longest:int,elev:int,country:string,city:string,lat:double,lon:double,author:string,date:string
0,version,version,0.89,,Air Routes Data - Version: 0.89 Generated: 2022-08-29 14:10:18 UTC; Graph created by Kelvin R. Lawrence; Please let me know of any errors you find in the graph or routes that should be added.,,,,,,,,,Kelvin R. Lawrence,2022-08-29 14:10:18 UTC
- edited
id,label,type,code,icao,desc,region,runways,longest,elev,country,city,lat,lon,author,date
1,airport,airport,ATL,KATL,Hartsfield - Jackson Atlanta International Airport,US-GA,5,12390,1026,US,Atlanta,33.6366996765137,-84.4281005859375,,
- remove the second line
- edit the first line (CSV Header)
- Edit air-routes-latest-edges.csv
- original
~id,~from,~to,~label,dist:int
3749,1,3,route,809
- edited
id,start_id,end_id,label,dist,start_vertex_type,end_vertex_type
3749,1,3,route,809,airport,airport
- edit the first line (CSV Header)
- add start_vertex_type and end_vertex_type columns to each lines
-
Install agefreighter
-
Make a JSON file and save it as 'config.json'
{
"edge": {
"csv_path": "air-routes-latest-edges.csv",
"type": "AirRoute",
"props": ["dist"],
"start_vertex": {
"csv_path": "air-routes-latest-nodes.csv",
"id": "start_id",
"label": "AirPort",
"props": ["code", "icao", "desc", "region", "runways", "longest", "elev", "country", "city", "lat", "lon", "author", "date"]
},
"end_vertex": {
"csv_path": "air-routes-latest-nodes.csv",
"id": "end_id",
"label": "AirPort",
"props": ["code", "icao", "desc", "region", "runways", "longest", "elev", "country", "city", "lat", "lon", "author", "date"]
}
}
}
-
Deploy Azure Database for PostgreSQL and enable Apache AGE extension on Azure Portal Introducing support for Graph data in Azure Database for PostgreSQL (Preview).
-
Set the PostgreSQL connection string as an environment variable
- macOS / Linux
export PG_CONNECTION_STRING="host=YOUR_SERVER.postgres.database.azure.com port=5432 dbname=postgres user=YOUR_USERNAME password=YOUR_PASSWORD"
- Windows (cmd.exe)
set PG_CONNECTION_STRING=host=YOUR_SERVER.postgres.database.azure.com port=5432 dbname=postgres user=YOUR_USERNAME password=YOUR_PASSWORD
- PowerShell
$env:PG_CONNECTION_STRING="host=YOUR_SERVER.postgres.database.azure.com port=5432 dbname=postgres user=YOUR_USERNAME password=YOUR_PASSWORD"
- Run the script
agefreighter load --source-type csv --config config.json
- Check the graph created in the PostgreSQL database
% psql $PG_CONNECTION_STRING
psql (16.6 (Homebrew), server 16.4)
SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, compression: off)
Type "help" for help.
postgres=> SET search_path = ag_catalog, "$user", public;
SET
postgres=> select * from air_route.airport limit 1;
id | properties
-----------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
844424930131969 | {"id": "1", "lat": "33.6366996765137", "lon": "-84.4281005859375", "city": "Atlanta", "code": "ATL", "date": "nan", "desc": "Hartsfield - Jackson Atlanta International Airport", "elev": "1026.0", "icao": "KATL", "type": "airport", "label": "airport", "author": "nan", "region": "US-GA", "country": "US", "longest": "12390.0", "runways": "5.0"}
(1 row)
postgres=> select * from air_route.route limit 1;
id | start_id | end_id | properties
------------------+-----------------+-----------------+---------------------------------------------------
1125899906842625 | 844424930131969 | 844424930131971 | {"id": "3749", "dist": "809.0", "label": "route"}
(1 row)
Release Notes
1.0.33 Release
- Dependency update
1.0.32 Release
- Dependency update
1.0.31 Release
- Dependency update
1.0.30 Release
- Dependency update
1.0.29 Release
- Dependency update
1.0.28 Release
- Fix ID collision bugs and O(n²) CSV reading performance issue
1.0.27 Release
- Dependency update
1.0.26 Release
- Dependency update
1.0.25 Release
- Dependency update
1.0.24 Release
- Dependency update
1.0.23 Release
- Secutiry update
1.0.22 Release
- Dependency update
1.0.21 Release
- Dependency update
1.0.20 Release
- Dependency update
1.0.19 Release
- Dependency update
1.0.18 Release
- Dependency update
1.0.17 Release
- Dependency update
1.0.16 Release
- Dependency update
1.0.15 Release
- Dependency update
1.0.14 Release
- Dependency update
1.0.13 Release
- Dependency update
1.0.12 Release
- Dependency update
1.0.11 Release
- Dependency update
1.0.10 Release
- Dependency update
1.0.9 Release
- Dependency update
1.0.8 Release
- Dependency update
1.0.7 Release
- Dependency update
1.0.6 Release
- Dependency update
1.0.5 Release
- Dependency update
1.0.4 Release
- Added escaping of back slashes
1.0.3 Release
- Added escaping of double quotes
1.0.2 Release
- Dependency update
1.0.1 Release
- Fixed
converter.pyandview.pyto parseRETURNvalues
1.0.0 Release
- Moved to the stable branch
1.0.0a16 Release
- Dependency update
1.0.0a15 Release
- Fixed tests for
--no-of-edges-trial
1.0.0a14 Release
- Fixed a bug in view.py
- Added Docker support again
1.0.0a13 Release
- Added
--no-of-edges-trialargument toloadsubcommand. - Fixed some issues.
1.0.0a12 Release
- Updated README.md
1.0.0a12 Release
- Refactored g2c.py to converter.py
- Added new feature: support Cypher to Apache AGE conversion
1.0.0a11 Release
- Fixed lack of a resource definition of shtab in Formula.
- Added some guards to make an error clearer.
1.0.0a10 Release
- Added --version argument.
- Reimplemented completion. Removed
completionsubcommand and added--generate-completionargument.
1.0.0a9 Release
- Replaced regular expression parser with CypherParser in view.py
- Refactored generator.py
1.0.0a8 Release
- Fixed a bug that outputs unnecessary information by PGSQLExporter
- Replaced regular expression parser with CypherParser in g2c.py
1.0.0a7 Release
- Implemented
load --source-type pgsql
1.0.0a6 Release
- Added explanations for the subcommands.
1.0.0a5 Release
- Fixed character escaping.
1.0.0a4 Release
- Fixed potential issues with data integrity.
- Fixed documents.
1.0.0a3 Release
- Fixed documents.
1.0.0a2 Release
- Various bug fixes, improve the robustness of the application.
1.0.0a1 Release
- Totally new release, refactored codebase.
0.9.2 Release
- Fixed an error message from 'neo2age.py'.
0.9.1 Release
- Fixed asyncio on Windows.
0.9.0 Release
- Added 'neo2age.py' based on 'neo2mcsv.py'.
- Added 'copy()' method to AgeFreighter class.
0.8.13 Release
- Added handling of special characters in 'neo2mcsv.py'.
0.8.12 Release
- Added handling of 'labelless' nodes in 'neo2mcsv.py' and others.
0.8.11 Release
- Fixed a bug confusing elementId and id if the graph is exported from Neo4j with 'neo2mcsv.py'.
0.8.10 Release
- Added a handling of 'labelless' nodes in 'neo2mcsv.py'.
0.8.9 Release
- Fixed minor issue in 'neo2mcsv.py' on Windows.
0.8.8 Release
- Added
source_columnsparameter to PGFreighter class.
0.8.7 Release
- Fixed minor issue in 'neo2mcsv.py' on Windows.
0.8.6 Release
- Fixed minor issue in 'neo2mcsv.py' on Windows.
0.8.5 Release
- Fixed minor issue in 'neo2mcsv.py'.
0.8.4 Release
- Fixed unicode encoding issue in 'neo2mcsv.py'.
0.8.3 Release
- Added 'neo2mcsv.py' to export a graph from Neo4j for MultiCSVFreighter.
0.8.2 Release
- Updated for the dependencies
0.8.1 Release
- Added CosmosNoSQLFreighter class.
- CosmosGremlinFreighter class will be obsoleted in the future.
0.8.0 Release
- Introduced unit tests for the classes to improve the quality of the package. Currently, the tests are only for a few classes.
- Fixed code to improve the robustness of the package.
0.7.5 Release
- Added 'progress' argument to the load() method. It's implemented as an optional argument for all the classes. Thanks to @cjoakim for the suggestion.
0.7.4 Release
- Changed the required module from psycopg / psycopg_pool to psycopg[binary,pool]
0.7.3 Release
- Added min_connections argument to the connect() method. Added the limitation of UNIX environment to import 'resource' module.
0.7.2 Release
- Added Mermaid diagram for the document.
0.7.1 Release
- Tuned MultiAzureStorageFreighter.
0.7.0 Release
- Added MultiAzureStorageFreighter.
0.6.1 Release
- Refactored the documents. Added sample data. Fixed some bugs.
0.6.0 Release
- Added edge properties support.
- 'edge_props' argument (list) is added to the 'load()' method.
- 'drop_graph' argument is obsoleted. 'create_graph' argument is added.
- 'create_graph' is set to True by default. CAUTION: If the graph already exists, the graph is dropped before loading the data.
- If 'create_graph' is False, the data is loaded into the existing graph.
0.5.3 Release -AzureStorageFreighter-
- AzureStorageFreighter class is totally refactored for better performance and scalability.
- 0.5.2 didn't work well for large files.
- Now, it works well for large files. Checked with a 5.4GB CSV file consisting of 10M of start vertices, 10K of end vertices, and 25M edges, it took 512 seconds to load the data into the graph database with PostgreSQL Flex, Standard_D32ds_v4 (32 vcpus, 128 GiB memory) and 512TB / 7500 iops of storage.
- Tested data was generated with tests/generate_dummy_data.py.
- UDF to load the data to graph is no longer used.
- However, please note that it is still in the early stages of implementation, so there is room for optimization and potential issues due to insufficient testing.
0.5.2 Release -AzureStorageFreighter-
- AzureStorageFreighter class is used to load data from Azure Storage into the graph database. It's totally different from other classes. The class works as follows:
- If the argument, 'subscription_id' is not set, the class tries to find the Azure Subscription ID from your local environment using the 'az' command.
- Creates an Azure Storage account and a blob container under the resource group where the PostgreSQL server runs in.
- Enables the 'azure_storage' extension in the PostgreSQL server, if it's not enabled.
- Uploads the CSV file to the blob container.
- Creates a UDF (User Defined Function) named 'load_from_azure_storage' in the PostgreSQL server. The UDF loads data from the Azure Storage into the graph database.
- Executes the UDF.
- The above process takes time to prepare for loading data, making it unsuitable for loading small files, but effective for loading large files. For instance, it takes under 3 seconds to load 'actorfilms.csv' after uploading.
- However, please note that it is still in the early stages of implementation, so there is room for optimization and potential issues due to insufficient testing.
0.5.0 Release
Refactored the code to make it more readable and maintainable with the separated classes for factory model. Please note how to use the new version of the package is tottally different from the previous versions.
Known Issues
- Apache AGE 1.5 doesn't support:
- tab (chr(9)) in agtype. If AGEFreighter detects replacing tab with '\t', writes a log file in a directory named
tab_replaced_YYYYMMDD_HHiiSSin the current directory. - multiple labels for nodes due to design limitations. (https://github.com/apache/age/discussions/109)
- tab (chr(9)) in agtype. If AGEFreighter detects replacing tab with '\t', writes a log file in a directory named
For More Information
- Apache AGE : https://age.apache.org/
- GitHub : https://github.com/apache/age
- Document : https://age.apache.org/age-manual/master/index.html
License
MIT License
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file agefreighter-1.0.33.tar.gz.
File metadata
- Download URL: agefreighter-1.0.33.tar.gz
- Upload date:
- Size: 1.8 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.9.27 {"installer":{"name":"uv","version":"0.9.27","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null}
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e88f1904d549868181cb382d96223cf54ce7dd5a05acaaffe203d8478324e440
|
|
| MD5 |
3893703c09623abe3bc32fadb78d3a6f
|
|
| BLAKE2b-256 |
df22366000df0beb89029d0bf18ecb90eccbd59ccf68fa69143966148cb9d35c
|
File details
Details for the file agefreighter-1.0.33-py3-none-any.whl.
File metadata
- Download URL: agefreighter-1.0.33-py3-none-any.whl
- Upload date:
- Size: 1.8 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.9.27 {"installer":{"name":"uv","version":"0.9.27","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null}
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
4cb593e45b953f68a1073bd5a0cfe64779e5ea81b19f87bd0aeba04b854f10d4
|
|
| MD5 |
8de4a64cb50c12376d979e2f856c6caa
|
|
| BLAKE2b-256 |
27f23aa26243b7d4615fd2d6b6a2d2bc9614a4780340bcf48265343e4cdeda34
|







