AirLLM allows single 4GB GPU card to run 70B large language models without quantization, distillation or pruning.

Project description

AirLLM optimizes inference memory usage, allowing 70B large language models to run inference on a single 4GB GPU card. No quantization, distillation, pruning or other model compression techniques that would result in degraded model performance are needed.
AirLLM优化inference内存,4GB单卡GPU可以运行70B大语言模型推理。不需要任何损失模型性能的量化和蒸馏,剪枝等模型压缩。
Updates
[2023/12/03] added support of ChatGLM, QWen!
[2023/12/02] added support for safetensors. Now support all top 10 models in open llm leaderboard.
[2023/12/01] airllm 2.0. Support compressions: 3x run time speed up!
[2023/11/20] airllm Initial verion!
Quickstart
1. install package
First, install airllm pip package.
首先安装airllm包。
pip install airllm
如果找不到package,可能是因为默认的镜像问题。可以尝试制定原始镜像:
pip install -i https://pypi.org/simple/ airllm
2. Inference
Then, initialize AirLLMLlama2, pass in the huggingface repo ID of the model being used, or the local path, and inference can be performed similar to a regular transformer model.
然后,初始化AirLLMLlama2,传入所使用模型的huggingface repo ID,或者本地路径即可类似于普通的transformer模型进行推理。
(You can can also specify the path to save the splitted layered model through layer_shards_saving_path when init AirLLMLlama2.
如果需要指定另外的路径来存储分层的模型可以在初始化AirLLMLlama2是传入参数:layer_shards_saving_path。)
from airllm import AirLLMLlama2
MAX_LENGTH = 128
# could use hugging face model repo id:
model = AirLLMLlama2("garage-bAInd/Platypus2-70B-instruct")
# or use model's local path...
#model = AirLLMLlama2("/home/ubuntu/.cache/huggingface/hub/models--garage-bAInd--Platypus2-70B-instruct/snapshots/b585e74bcaae02e52665d9ac6d23f4d0dbc81a0f")
input_text = [
'What is the capital of United States?',
#'I like',
]
input_tokens = model.tokenizer(input_text,
return_tensors="pt",
return_attention_mask=False,
truncation=True,
max_length=MAX_LENGTH,
padding=True)
generation_output = model.generate(
input_tokens['input_ids'].cuda(),
max_new_tokens=20,
use_cache=True,
return_dict_in_generate=True)
output = model.tokenizer.decode(generation_output.sequences[0])
print(output)
Note: During inference, the original model will first be decomposed and saved layer-wise. Please ensure there is sufficient disk space in the huggingface cache directory.
注意:推理过程会首先将原始模型按层分拆,转存。请保证huggingface cache目录有足够的磁盘空间。
3. Model Compression - 3x Inference Speed Up!
We just added model compression based on block-wise quantization based model compression. Which can further speed up the inference speed for up to 3x , with almost ignorable accuracy loss! (see more performance evaluation and why we use block-wise quantization in this paper)
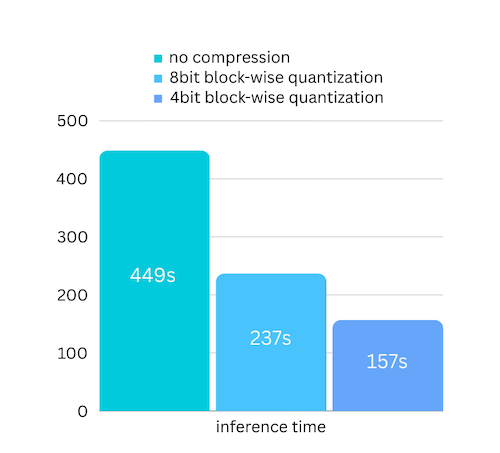
how to enalbe model compression speed up:
- Step 1. make sure you have bitsandbytes installed by
pip install -U bitsandbytes - Step 2. make sure airllm verion later than 2.0.0:
pip install -U airllm - Step 3. when initialize the model, passing the argument compression ('4bit' or '8bit'):
model = AirLLMLlama2("garage-bAInd/Platypus2-70B-instruct",
compression='4bit' # specify '8bit' for 8-bit block-wise quantization
)
4. All supported configurations
When initialize the model, we support the following configurations:
- compression: supported options: 4bit, 8bit for 4-bit or 8-bit block-wise quantization, or by default None for no compression
- profiling_mode: supported options: True to output time consumptions or by default False
- layer_shards_saving_path: optionally another path to save the splitted model
5. Supported Models
HF open llm leaderboard top models
Including but not limited to the following: (Most of the open models are based on llama2, so should be supported by default)
@12/01/23
| Rank | Model | Supported | Model Class |
|---|---|---|---|
| 1 | TigerResearch/tigerbot-70b-chat-v2 | ✅ | AirLLMLlama2 |
| 2 | upstage/SOLAR-0-70b-16bit | ✅ | AirLLMLlama2 |
| 3 | ICBU-NPU/FashionGPT-70B-V1.1 | ✅ | AirLLMLlama2 |
| 4 | sequelbox/StellarBright | ✅ | AirLLMLlama2 |
| 5 | bhenrym14/platypus-yi-34b | ✅ | AirLLMLlama2 |
| 6 | MayaPH/GodziLLa2-70B | ✅ | AirLLMLlama2 |
| 7 | 01-ai/Yi-34B | ✅ | AirLLMLlama2 |
| 8 | garage-bAInd/Platypus2-70B-instruct | ✅ | AirLLMLlama2 |
| 9 | jondurbin/airoboros-l2-70b-2.2.1 | ✅ | AirLLMLlama2 |
| 10 | chargoddard/Yi-34B-Llama | ✅ | AirLLMLlama2 |
opencompass leaderboard top models
Including but not limited to the following: (Most of the open models are based on llama2, so should be supported by default)
@12/01/23
| Rank | Model | Supported | Model Class |
|---|---|---|---|
| 1 | GPT-4 | closed.ai😓 | N/A |
| 2 | TigerResearch/tigerbot-70b-chat-v2 | ✅ | AirLLMLlama2 |
| 3 | THUDM/chatglm3-6b-base | ✅ | AirLLMChatGLM |
| 4 | Qwen/Qwen-14B | ✅ | AirLLMQWen |
| 5 | 01-ai/Yi-34B | ✅ | AirLLMLlama2 |
| 6 | ChatGPT | closed.ai😓 | N/A |
| 7 | OrionStarAI/OrionStar-Yi-34B-Chat | ✅ | AirLLMLlama2 |
| 8 | Qwen/Qwen-14B-Chat | ✅ | AirLLMQWen |
| 9 | Duxiaoman-DI/XuanYuan-70B | ✅ | AirLLMLlama2 |
| 10 | internlm/internlm-20b | ⏰(adding, to accelerate😀) | |
| 26 | baichuan-inc/Baichuan2-13B-Chat | ⏰(adding, to accelerate😀) |
example of other models (ChatGLM, QWen, etc):
- ChatGLM:
from airllm import AirLLMChatGLM
MAX_LENGTH = 128
model = AirLLMChatGLM("THUDM/chatglm3-6b-base")
input_text = ['What is the capital of China?',]
input_tokens = model.tokenizer(input_text,
return_tensors="pt",
return_attention_mask=False,
truncation=True,
max_length=MAX_LENGTH,
padding=True)
generation_output = model.generate(
input_tokens['input_ids'].cuda(),
max_new_tokens=5,
use_cache= True,
return_dict_in_generate=True)
model.tokenizer.decode(generation_output.sequences[0])
- QWen:
from airllm import AirLLMQWen
MAX_LENGTH = 128
model = AirLLMQWen("Qwen/Qwen-7B")
input_text = ['What is the capital of China?',]
input_tokens = model.tokenizer(input_text,
return_tensors="pt",
return_attention_mask=False,
truncation=True,
max_length=MAX_LENGTH)
generation_output = model.generate(
input_tokens['input_ids'].cuda(),
max_new_tokens=5,
use_cache=True,
return_dict_in_generate=True)
model.tokenizer.decode(generation_output.sequences[0])
Acknowledgement
A lot of the code are based on SimJeg's great work in the Kaggle exam competition. Big shoutout to SimJeg:
GitHub account @SimJeg, the code on Kaggle, the associated discussion.
FAQ
1. MetadataIncompleteBuffer
safetensors_rust.SafetensorError: Error while deserializing header: MetadataIncompleteBuffer
If you run into this error, most possible cause is you run out of disk space. The process of splitting model is very disk-consuming. See this. You may need to extend your disk space, clear huggingface .cache and rerun.
如果你碰到这个error,很有可能是空间不足。可以参考一下这个 可能需要扩大硬盘空间,删除huggingface的.cache,然后重新run。
Contribution
Welcome contribution, ideas and discussions!
If you find it useful, please ⭐ or buy me a coffee! 🙏

Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file airllm-2.3.0.tar.gz.
File metadata
- Download URL: airllm-2.3.0.tar.gz
- Upload date:
- Size: 20.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.8.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
da8fc6dc928d24acd0ef281aa122a1481cbe8246602cf343b2b7c6afc9848881
|
|
| MD5 |
eb31c521d1e097fda74588c9c89ebcdf
|
|
| BLAKE2b-256 |
478ce4a5b9b5bbfe2eda1111a73fac876baed56cde9366981eadea202d6f4462
|
File details
Details for the file airllm-2.3.0-py3-none-any.whl.
File metadata
- Download URL: airllm-2.3.0-py3-none-any.whl
- Upload date:
- Size: 31.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.8.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e21064cdd8d20f2c8e140304b6d3f2d14b53a0904e8baf25d35dca6e976c2371
|
|
| MD5 |
c74a4e13060d4b16536ee635924584eb
|
|
| BLAKE2b-256 |
ce74a3beb7eff1b161605fa6022fbefafd291f6da951ed1a4db685804d46ef59
|







