Speaker embedding for anime speech domain based on ECAPA_TDNN

Project description
Anime Speaker Embedding
Overview
- ECAPA-TDNN model (from SpeechBrain) trained on OOPPEENN/VisualNovel_Dataset (a.k.a. Galgame_Dataset)
- This model is designed for speaker embedding tasks in anime and visual novel contexts.
Features
- Well-suited for Japanese anime-like voices, including non-verbal vocalizations or acted voices
- Also this model works well for NSFW erotic utterances and vocalizations such as aegi (喘ぎ) and chupa-sound (チュパ音) which are important culture in Japanese Visual Novel games, while other usual speaker embedding models cannot distinguish such voices of different speakers at all!
Installation
pip install torch --index-url https://download.pytorch.org/whl/cu128 # if you want to use GPU
pip install anime_speaker_embedding
Usage
from anime_speaker_embedding.model import AnimeSpeakerEmbedding
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
model = AnimeSpeakerEmbedding(device=device)
audio_path = "path/to/audio.wav" # Path to the audio file
embedding = model.get_embedding(audio_path)
print(embedding.shape) # np.array with shape (192,)
See example.ipynb for some usage and visualization examples.
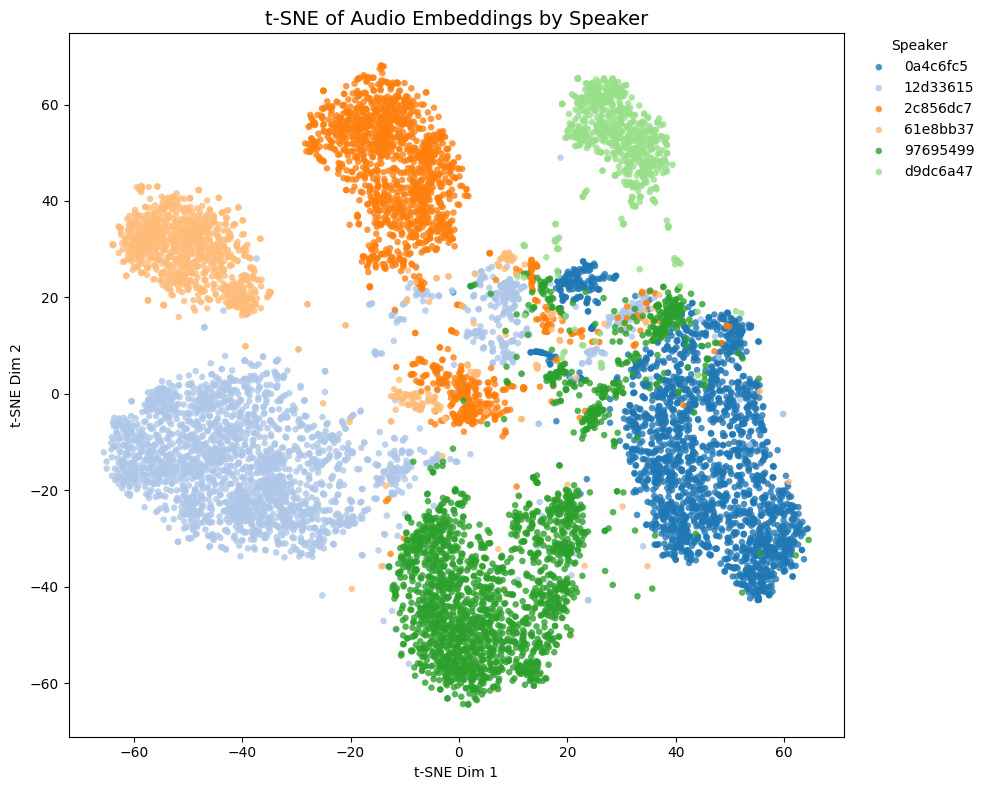
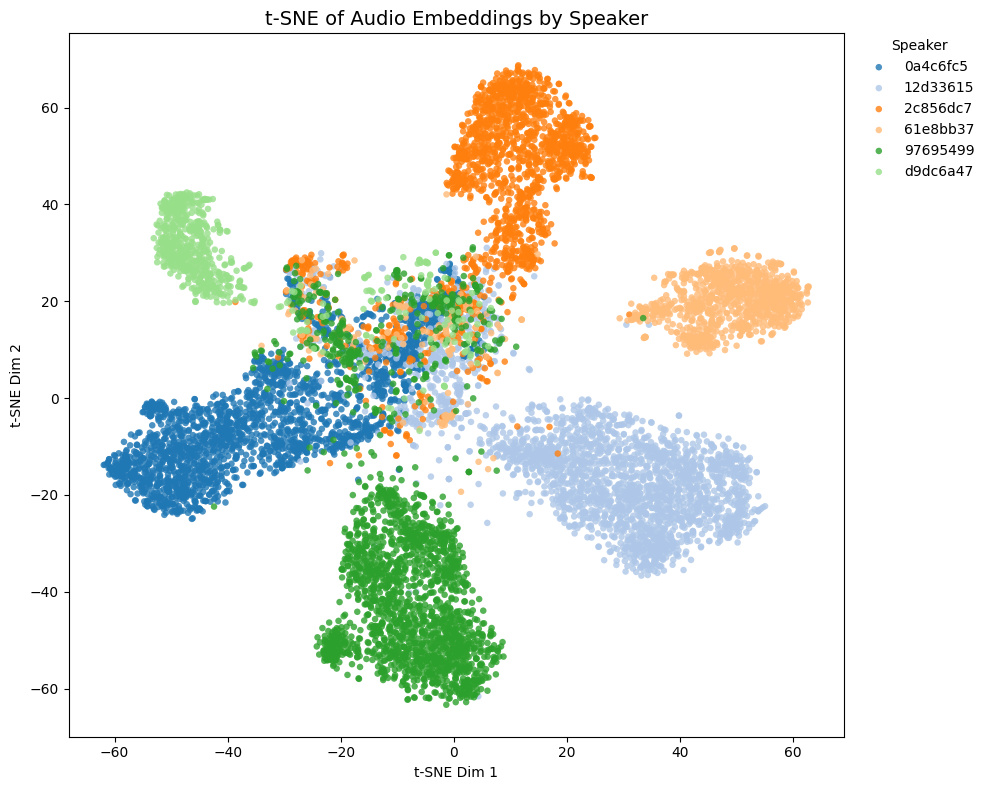
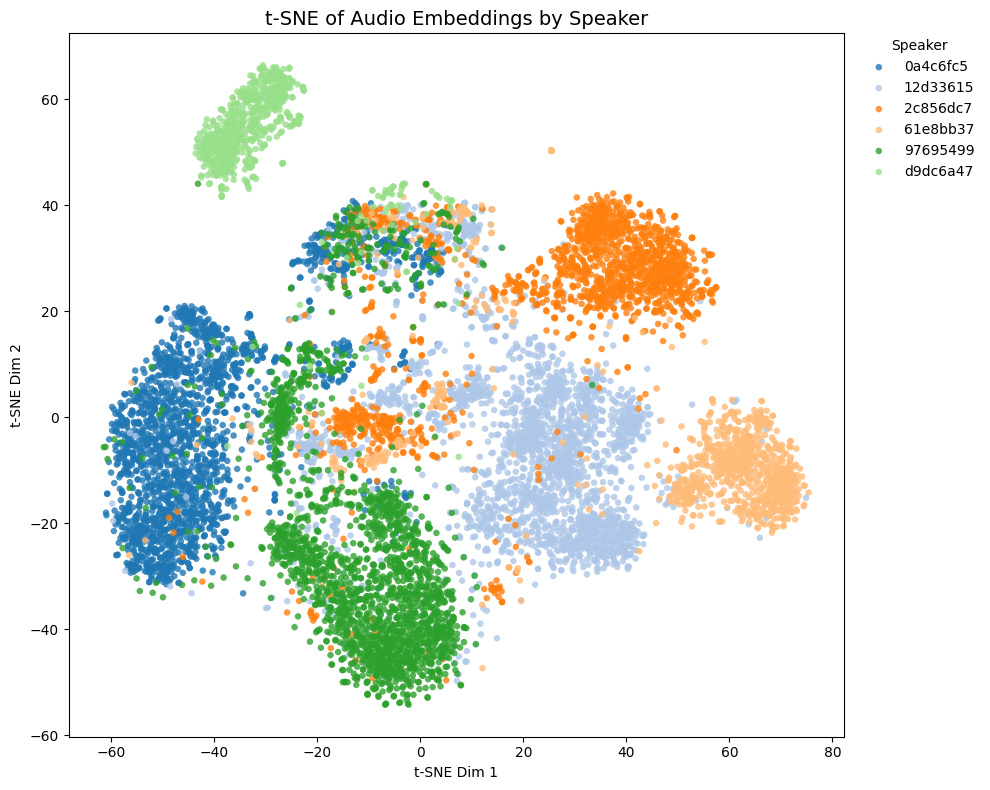
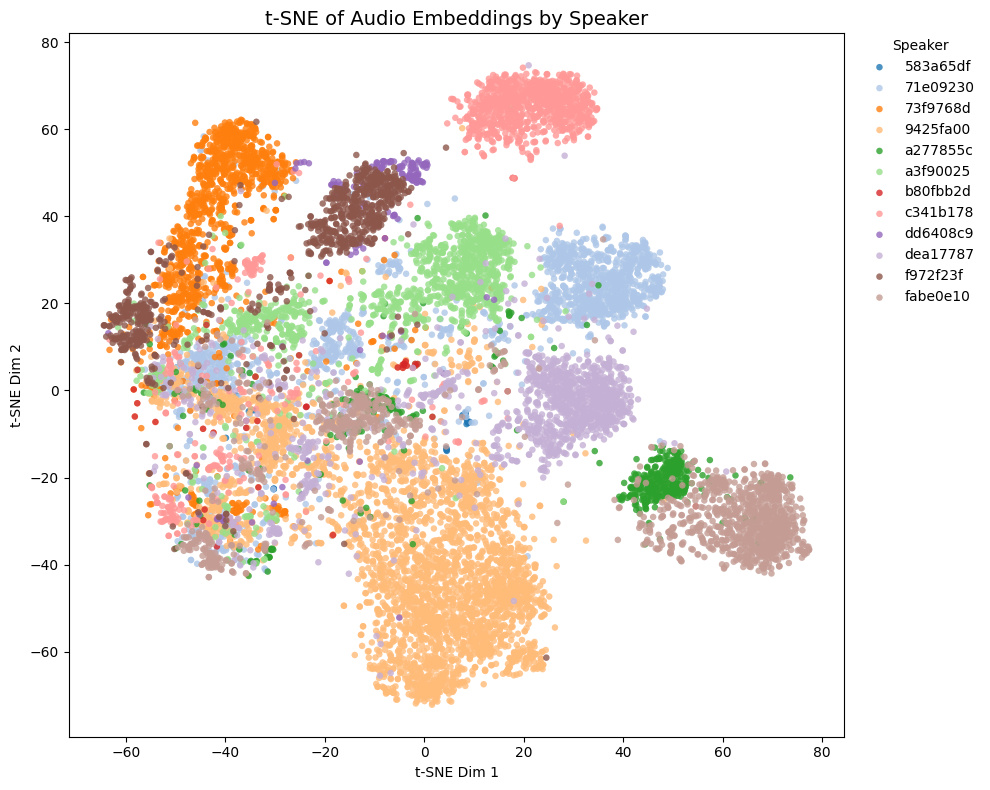
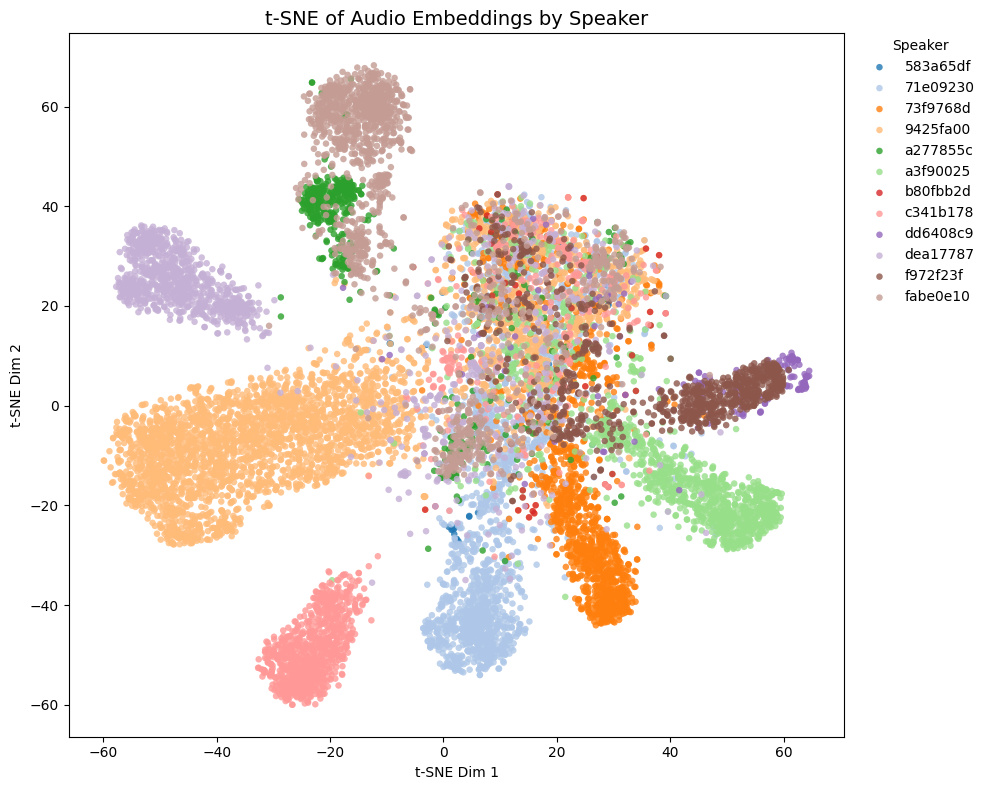
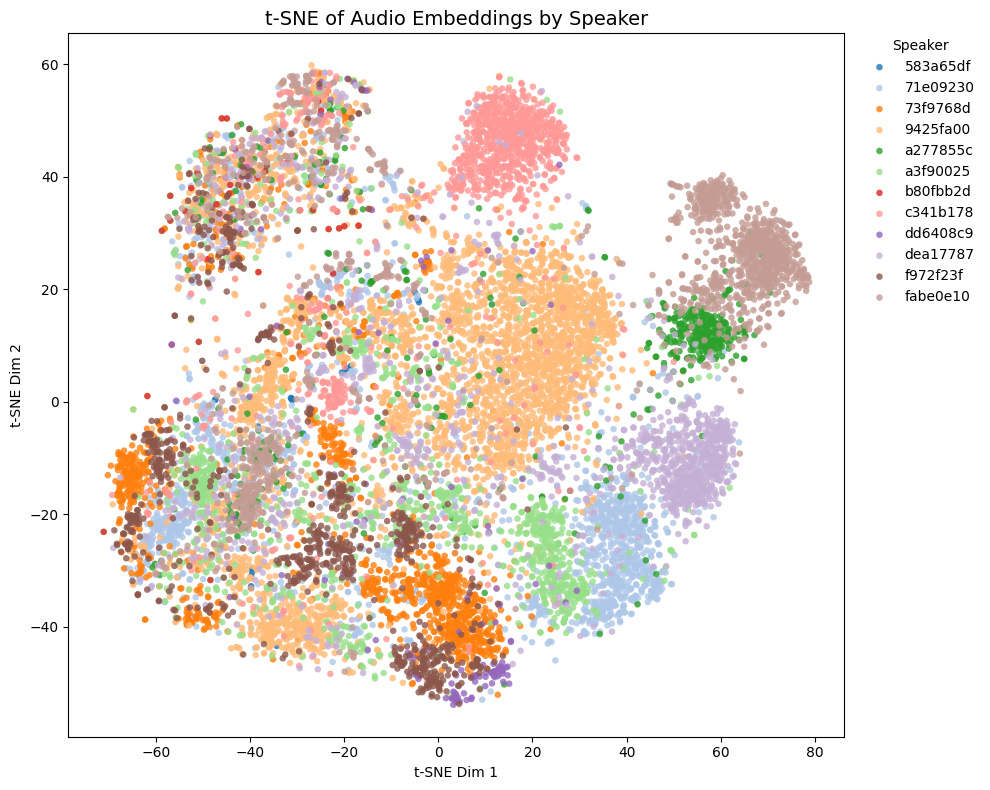
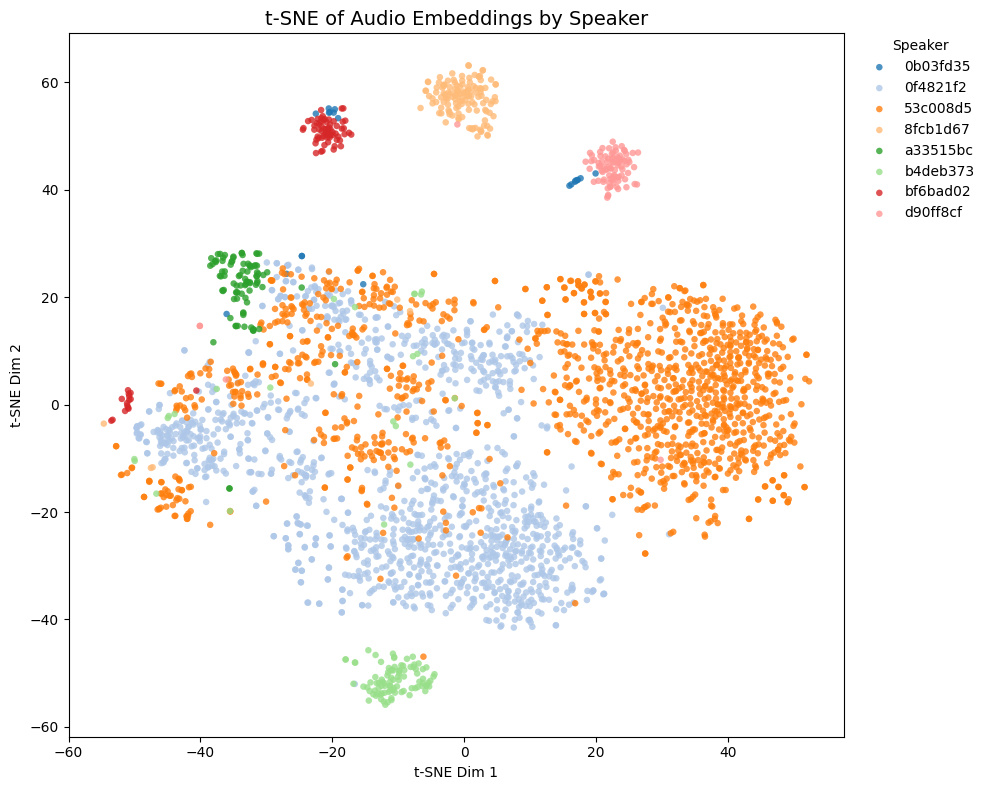
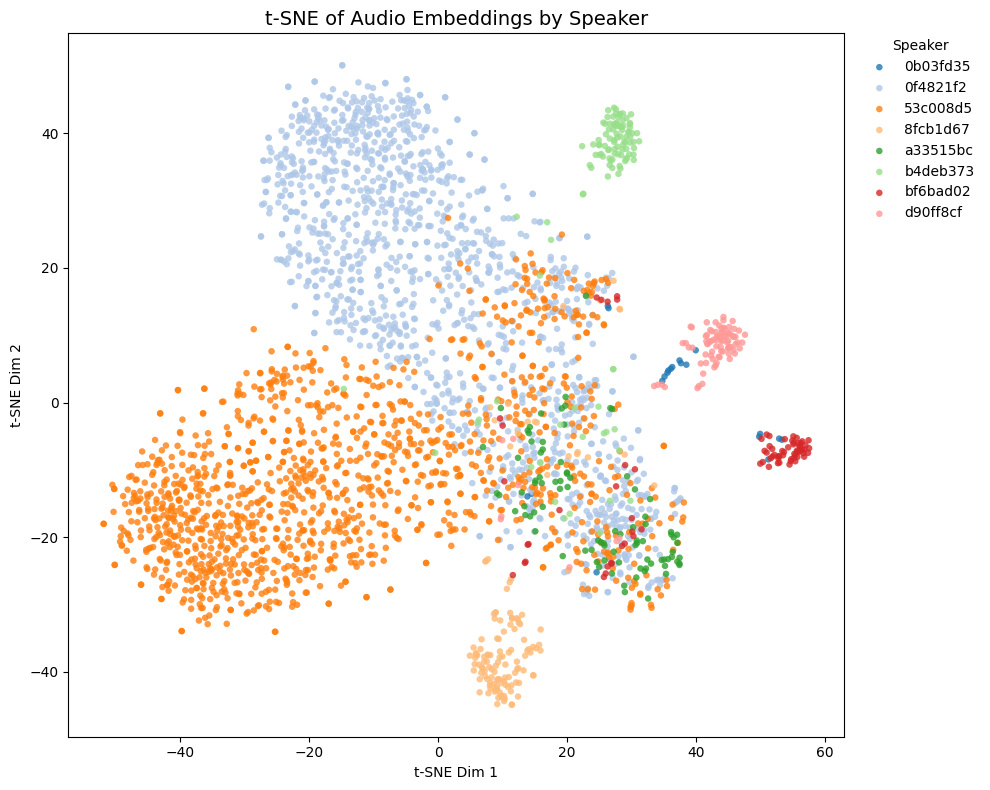
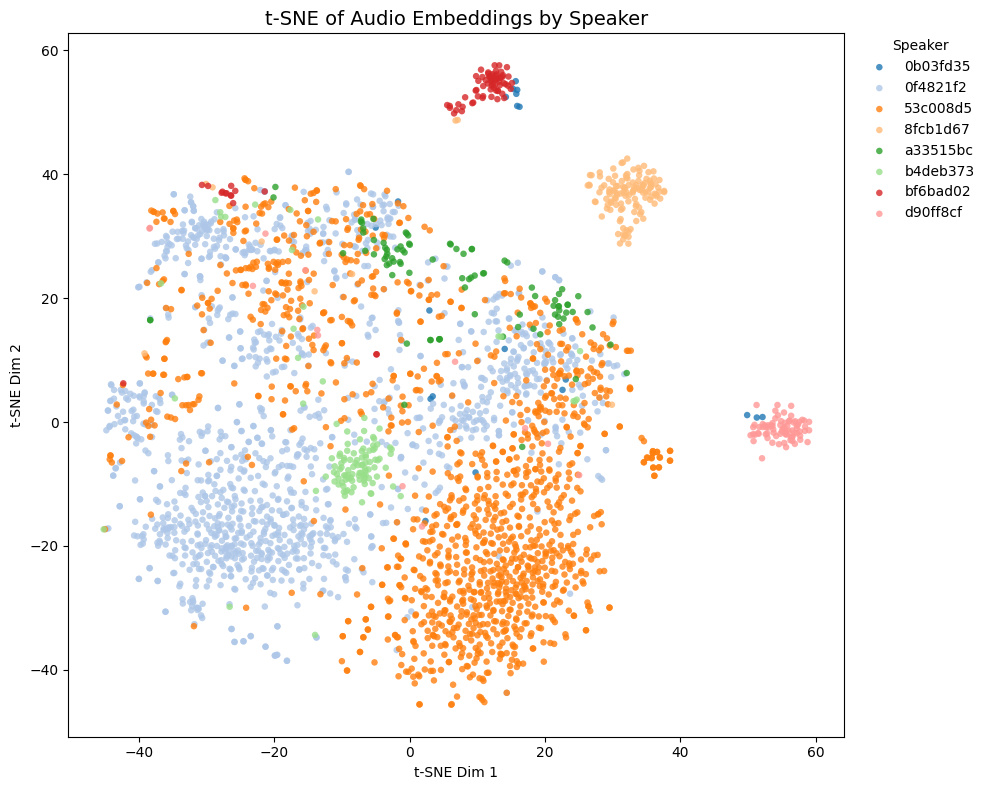
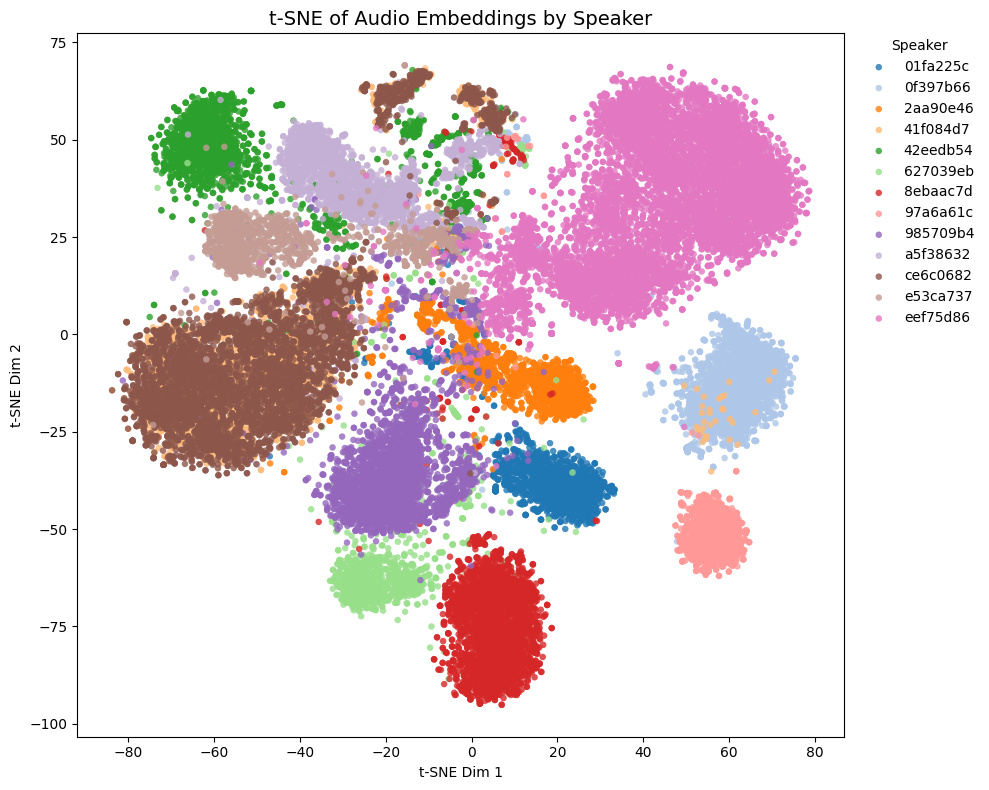
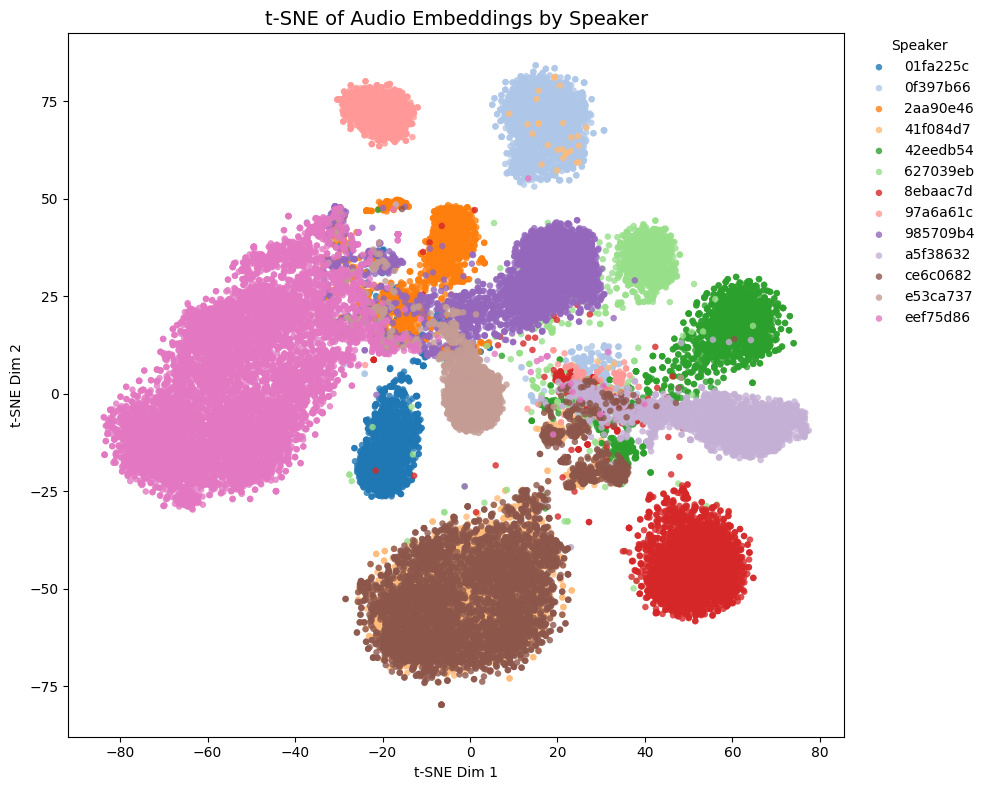
Comparison with other models
The t-SNE plot of embeddings from some Galgames (not included in the training set!) is shown below.
| Game | THIS MODEL | speechbrain/spkrec-ecapa-voxceleb | pyannote/wespeaker-voxceleb-resnet34-LM | Resemblyzer |
|---|---|---|---|---|
| Game1 |  |
 |
 |
 |
| Game2 |  |
 |
 |
 |
| Game3 |  |
 |
 |
 |
| Game4 |  |
 |
 |
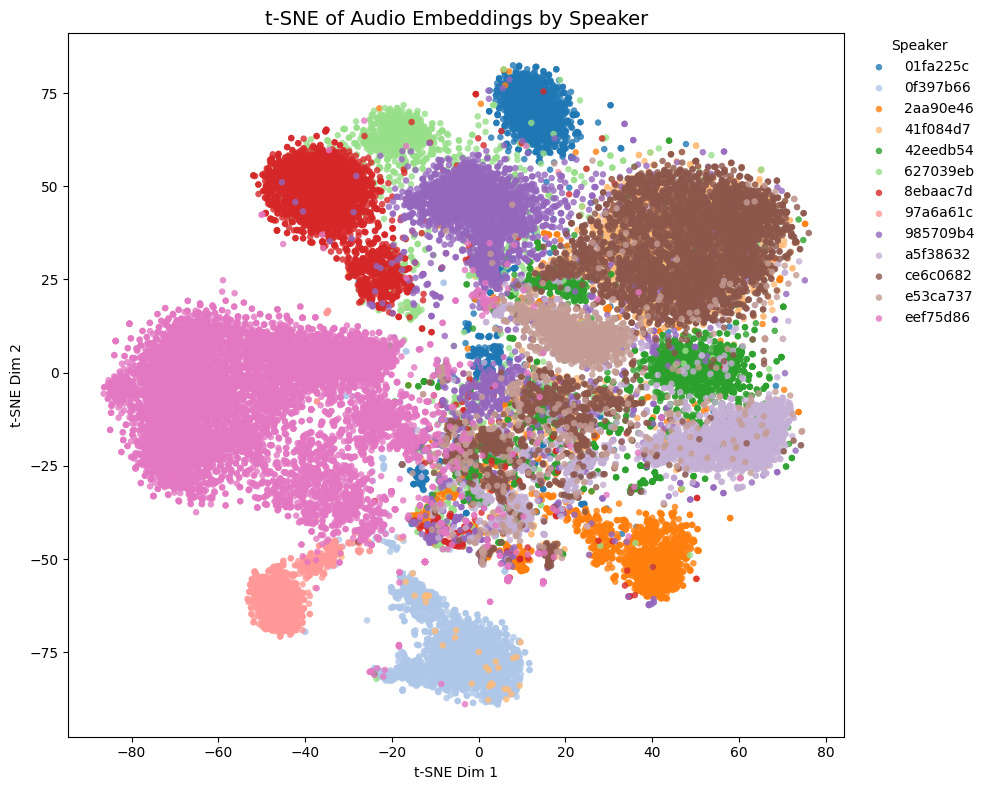 |
- Game1 and Game2 contains NSFW voices, while Game3 and Game4 does not.
- In Game4, Brown and yellow speakers are actually the same character
Model Details
Model Architecture
The actual model is SpeechBrain's ECAPA-TDNN with all BatchNorm layers replaced with GroupNorm. This is because I encountered a problem with the original BathNorm layers when evaluating the model (maybe some statistics drifted).
Dataset
From all the audio files in the OOPPEENN/VisualNovel_Dataset dataset, we filtered out some broken audio files, and exluded the speakers with less than 100 audio files. The final dataset contains:
- train: 6,260,482 audio files, valid: 699,488 audio files, total: 6,959,970 audio files
- 7,357 speakers
Training process
- I used speechbrain/spkrec-ecapa-voxceleb as the base model
- But after some fine-tuning, I replaced all BN with GN, so I don't know how actually the base model effects the final model
- Also the scaling before fbank is added (
x = x * 32768.0) (by misadvice of ChatGPT), so the original knowledge may not be fully transferred
- First I trained the model on the small subset (the top 100 or 1000 speakers w.r.t. the number of audio files)
- Then I trained the model on the full dataset
- Finally I trained the model on the full dataset with many online augmentations (including reverb, background noise, various filters, etc.)
- At some point, since some characters appear in several games (like FD or same series), I computed the confusion matrix of the model on the validation set, and merged some speakers with high confusion if they are from the same game maker and same character name
The training code will be released in maybe another repo.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file anime_speaker_embedding-0.1.1.tar.gz.
File metadata
- Download URL: anime_speaker_embedding-0.1.1.tar.gz
- Upload date:
- Size: 120.4 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.7.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
0706fbe0737eabdc22b55453c708ab78d9d91ff50fe27d18732903b7b0513739
|
|
| MD5 |
ad06cb99ddac1e08fd31ae45ae712299
|
|
| BLAKE2b-256 |
c05449447c4a44ccd091e946e0b54f7ca37a5db58df005cb2fa53d24963fb7a3
|
File details
Details for the file anime_speaker_embedding-0.1.1-py3-none-any.whl.
File metadata
- Download URL: anime_speaker_embedding-0.1.1-py3-none-any.whl
- Upload date:
- Size: 29.8 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.7.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ae88905371ff04e985592b50d926e23573364c09b93b7f801b97f6b7660ce880
|
|
| MD5 |
8bf12fe1990ad930df42c8a108f5552a
|
|
| BLAKE2b-256 |
7400417a2e760e2fbeed6f960be065e13d56544b54a8cb560ede5854206bf780
|







