Speaker embedding for anime speech domain based on ECAPA_TDNN

Project description
Anime Speaker Embedding
Speaker embedding model for suitable for anime domain. English README
アニメドメインに適した話者埋め込みモデル。
概要
- SpeechBrain の ECAPA-TDNN モデルを、OOPPEENN/56697375616C4E6F76656C5F44617461736574 で学習
- アニメおよびビジュアルノベルの文脈での話者埋め込みタスク向けに設計
- 2025-06-22: Voice Actor(VA)バリアントを追加(バージョン0.2.0)。デフォルトのモデルよりも同一キャラがまとまりやすくなるモデル(比較は表参照)
特長
- 日本語アニメ調の演技音声や非言語発話に特化
- 他の通常の話者埋め込みモデルではまったく区別できない、日本のノベルゲーの文化の中で非常に重要なNSFWな性的発声(喘ぎ・チュパ音など)にも対応
モデルバリアント
- char(デフォルト): キャラクターを推定するようにトレーニングされたモデル。声優ではなくキャラクターを区別(同じ声優が演じる別キャラクターも別話者として学習)
- va(バージョン0.2.0で追加): 声優を推定するようにトレーニングされたモデル。キャラクターのスタイル差よりも声優ごとの一貫性を重視
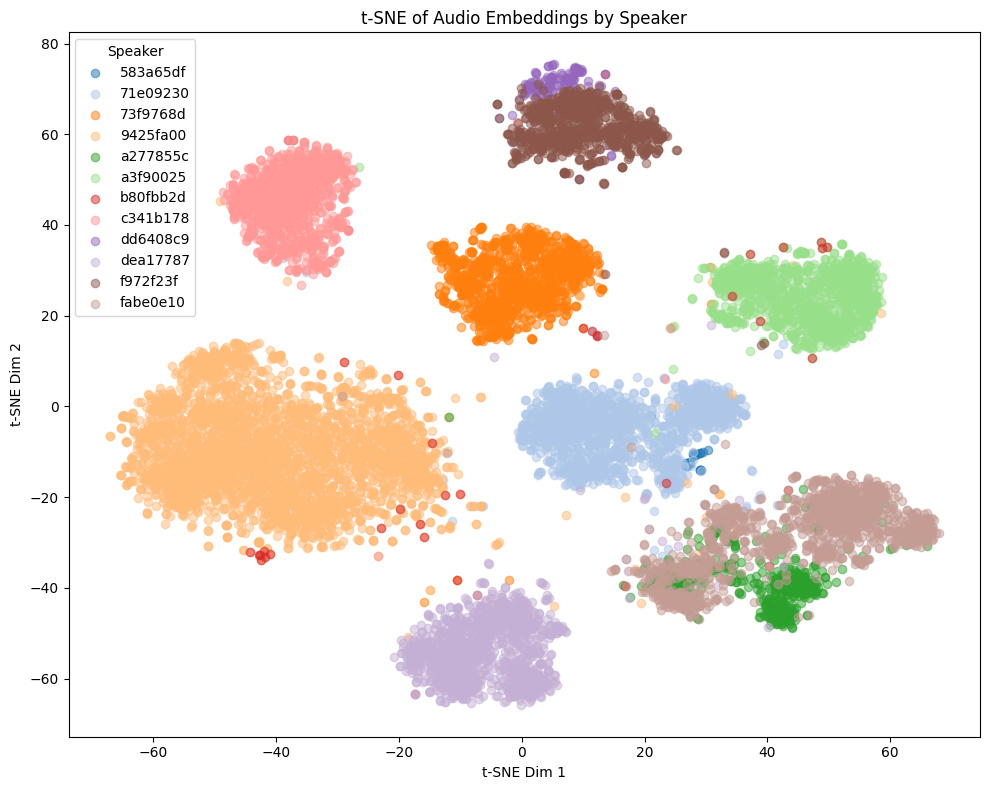
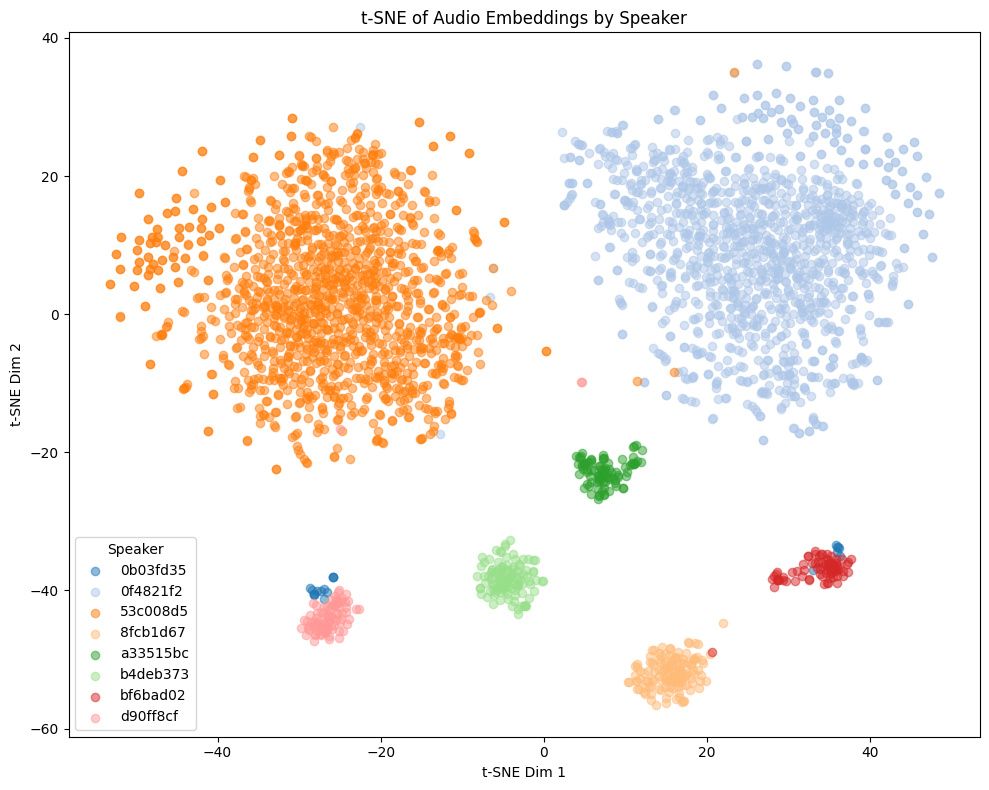
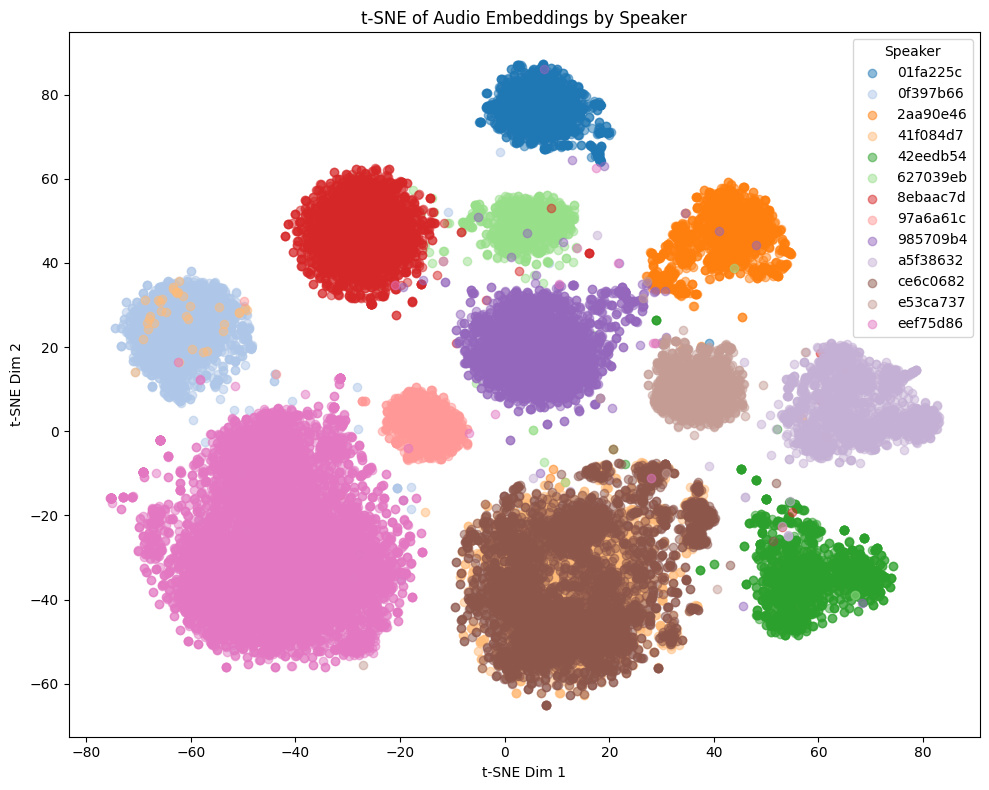
同一キャラクターに対して、charモデルは埋め込みの分散が大きく、vaモデルは分散が小さくなる傾向があります。例えば下記のGame1での違いを見ると、charモデルは細かく同一話者でも分離されているのに対し、vaモデルは同一話者の埋め込みが近くに集まっています。
注意
- 話者を積極的に区別しようとする性質のため、同一話者の埋め込み間のコサイン類似度は他モデルより低めです
インストール
pip install torch --index-url https://download.pytorch.org/whl/cu128 # GPU利用時
pip install anime_speaker_embedding
使い方
from anime_speaker_embedding import AnimeSpeakerEmbedding
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
model = AnimeSpeakerEmbedding(device=device, variant="char") # variant="va" でVAモデル
audio_path = "path/to/audio.wav"
embedding = model.get_embedding(audio_path)
print(embedding.shape) # (192,) の np.ndarray
使用例や可視化例は example.ipynb を参照してください。
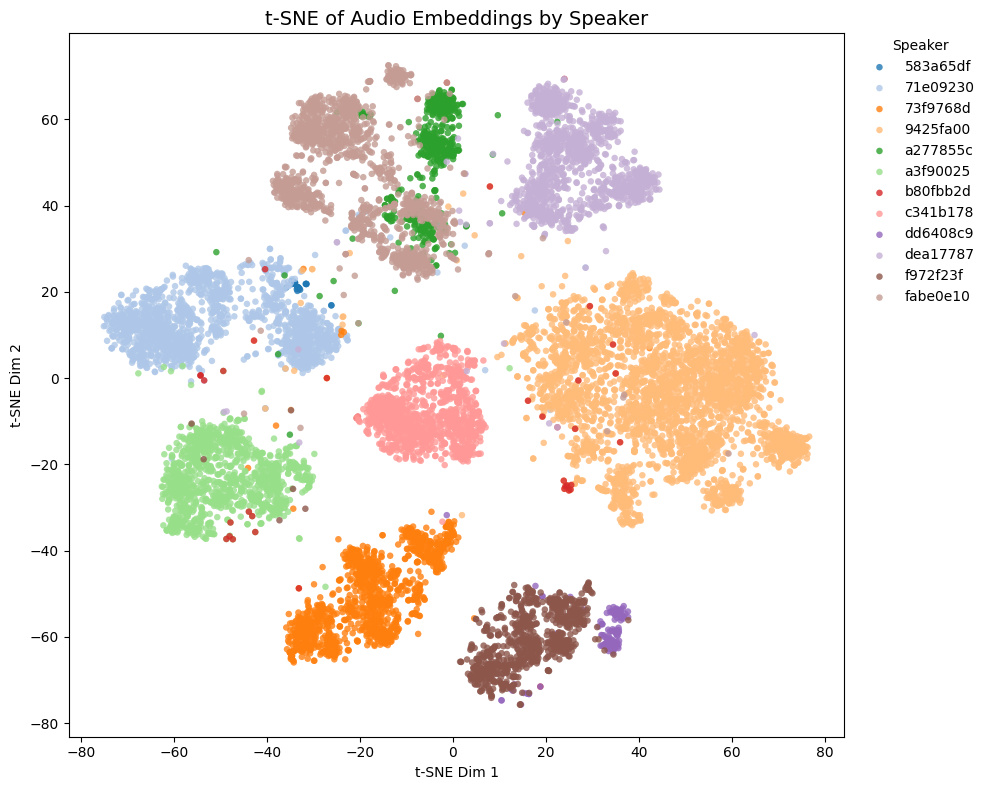
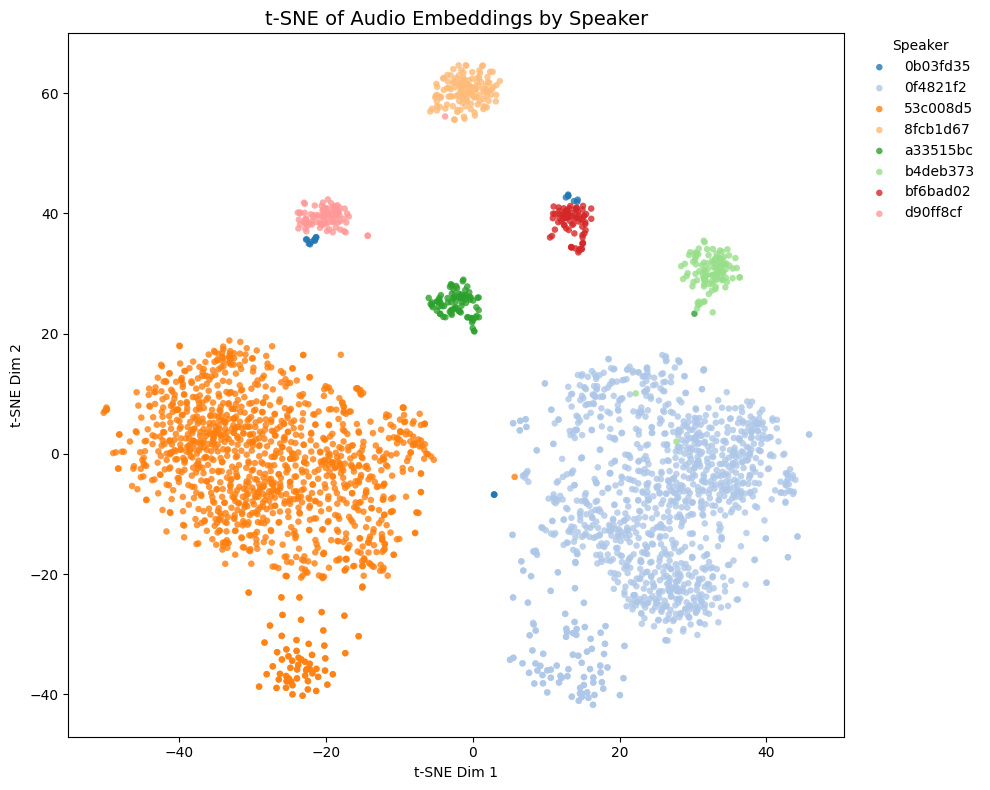
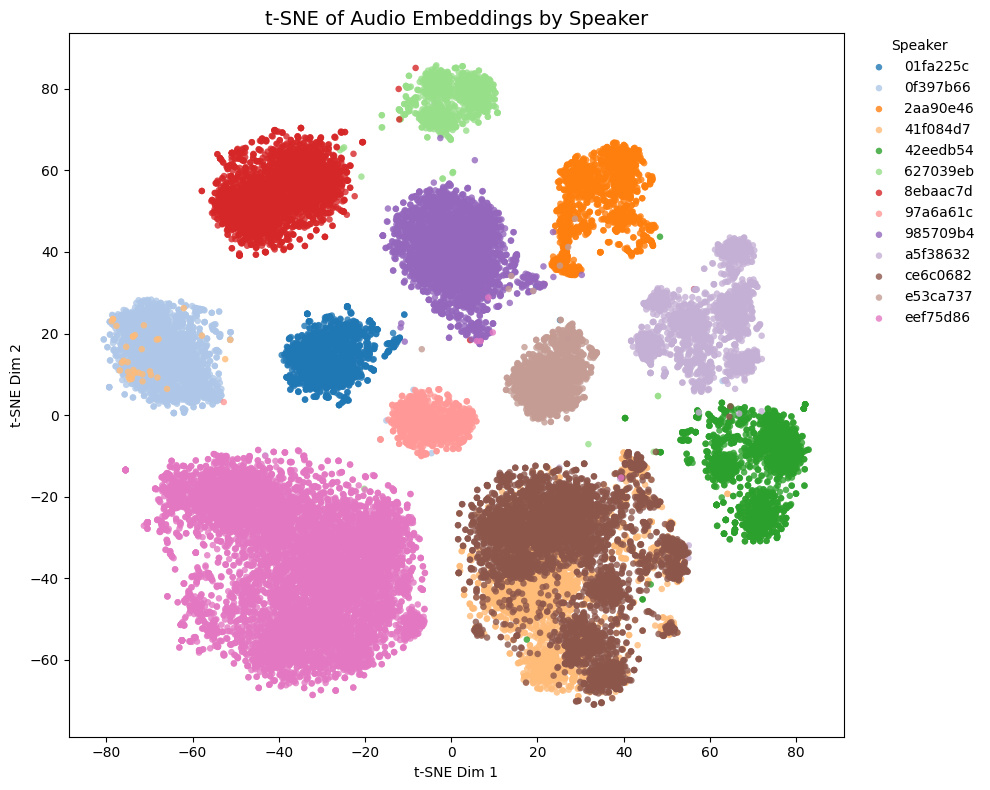
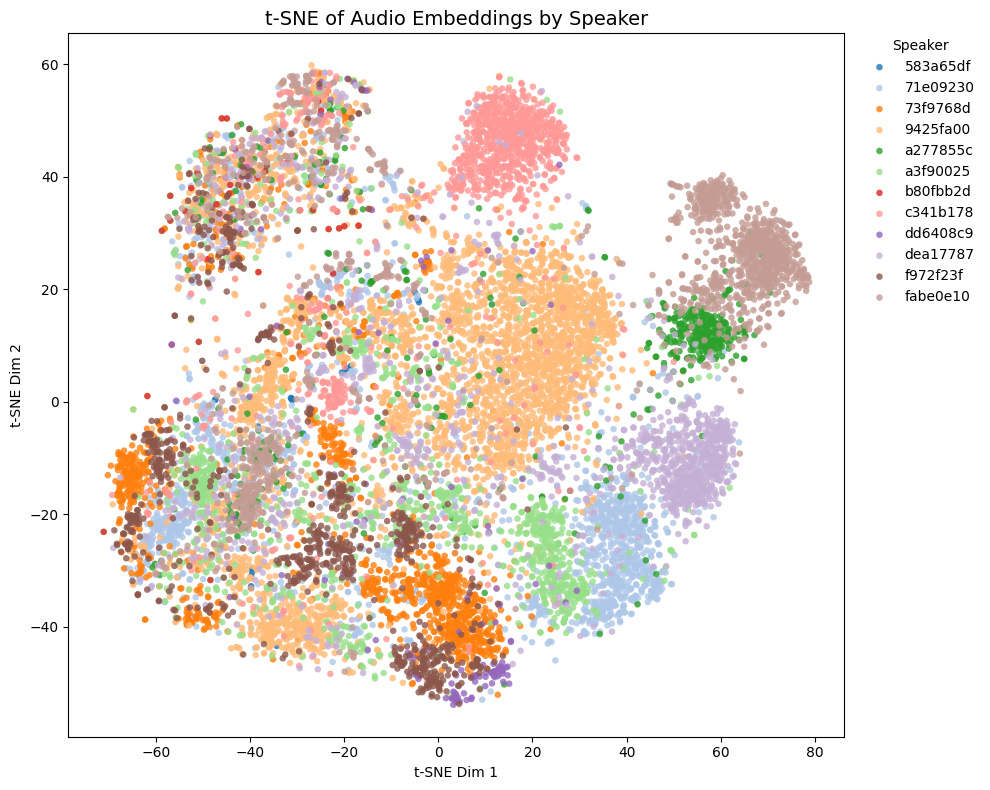
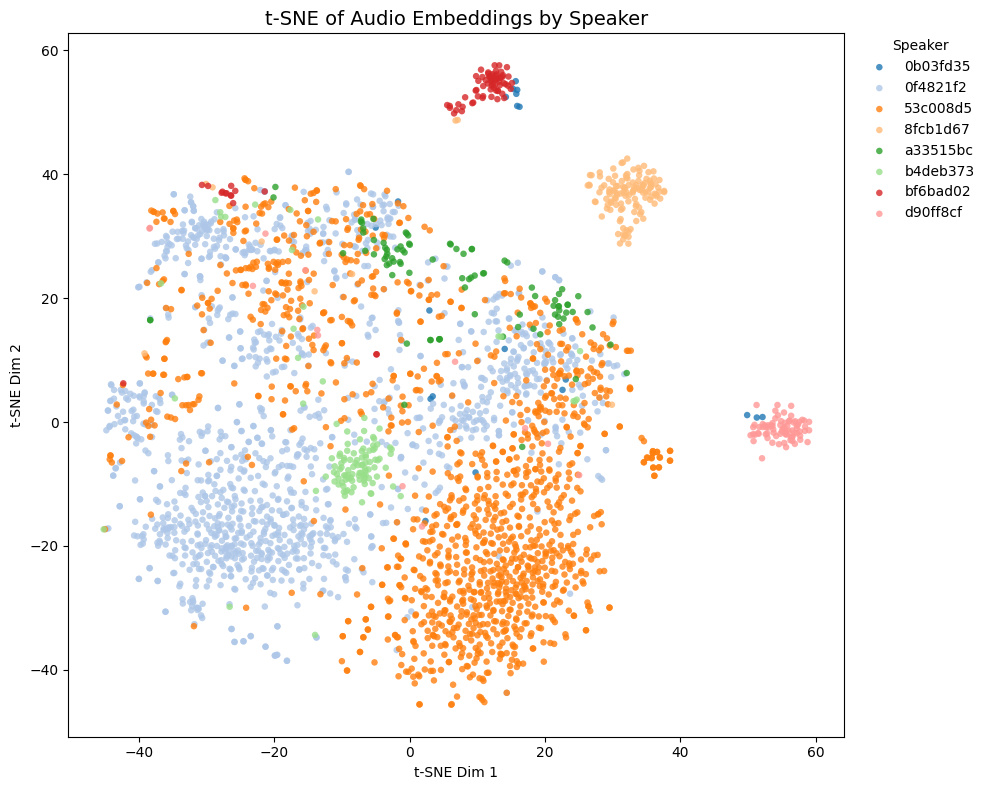
他モデルとの比較
トレーニングセットに含まれないゲーム音声の埋め込みの様子:
| モデル | Game1 | Game2 | Game3 | Game4 |
|---|---|---|---|---|
| ⭐ VA model | 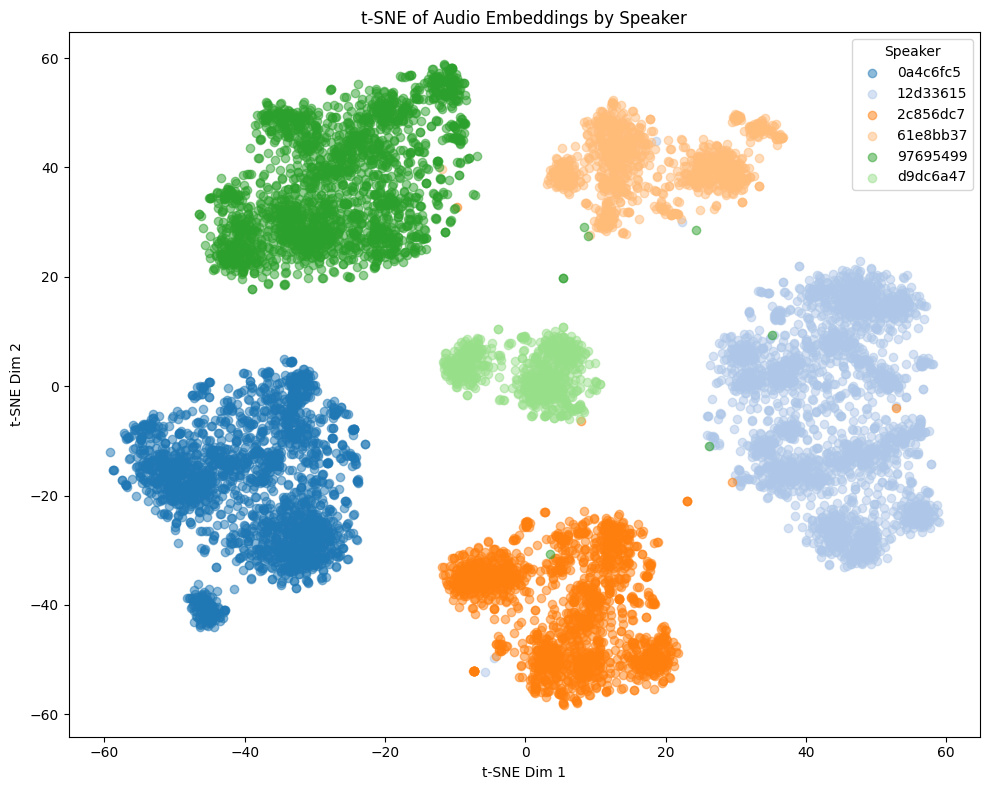 |
 |
 |
 |
| ⭐ Char model | 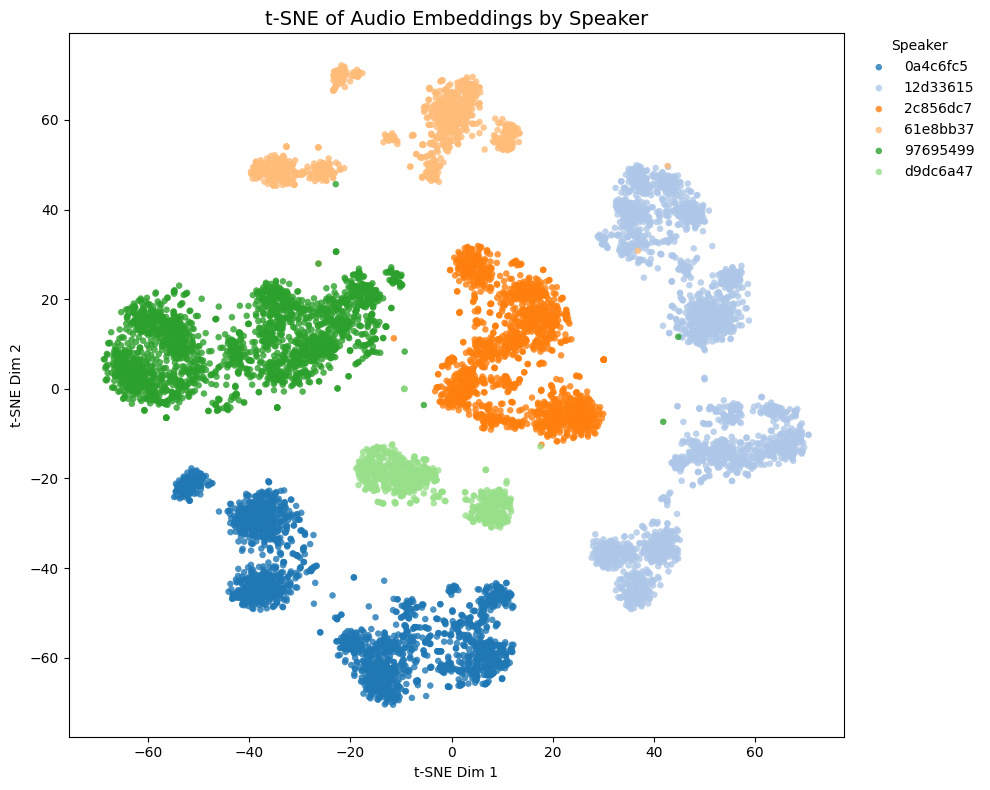 |
 |
 |
 |
| speechbrain/spkrec-ecapa-voxceleb | 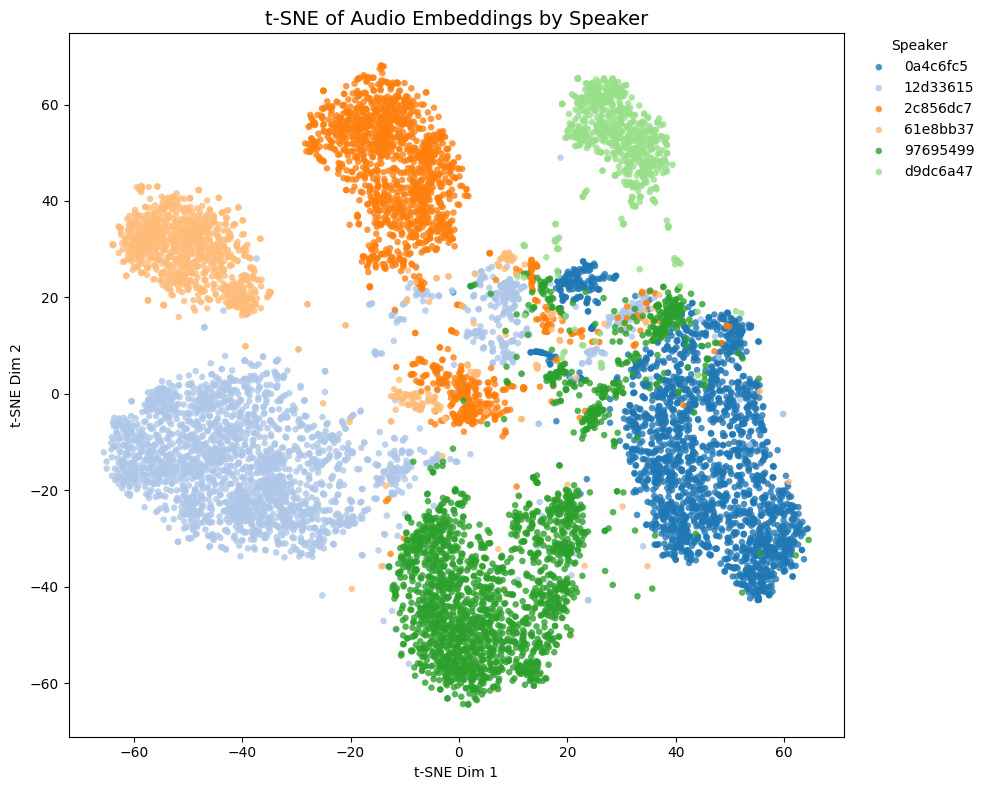 |
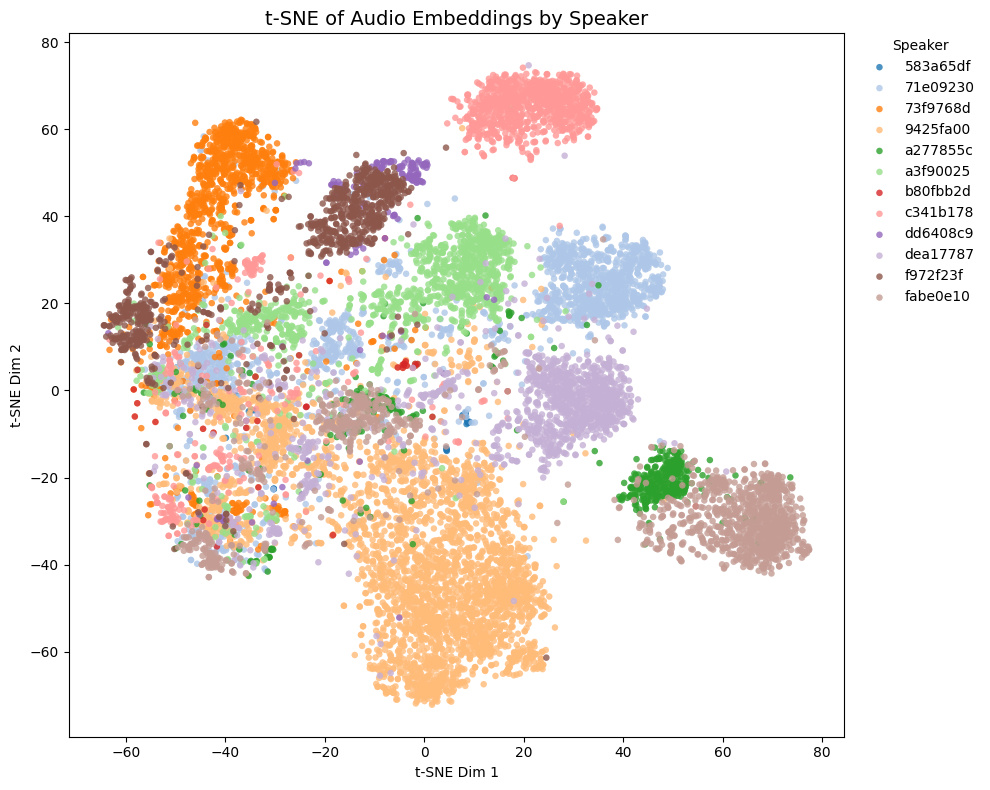 |
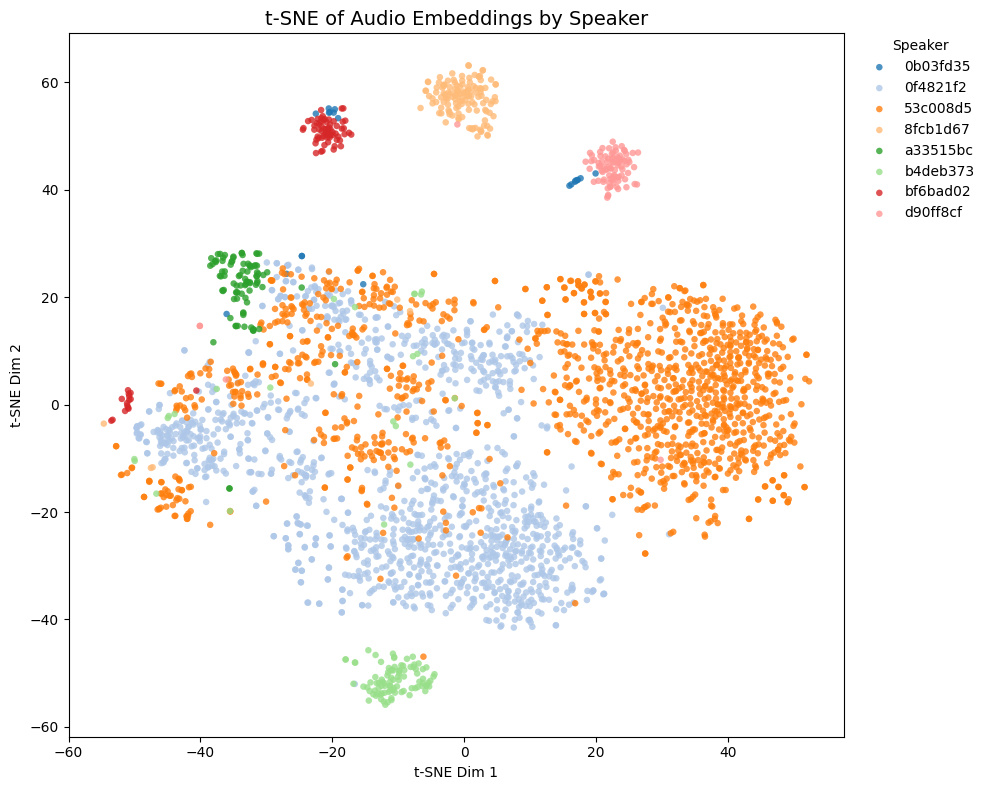 |
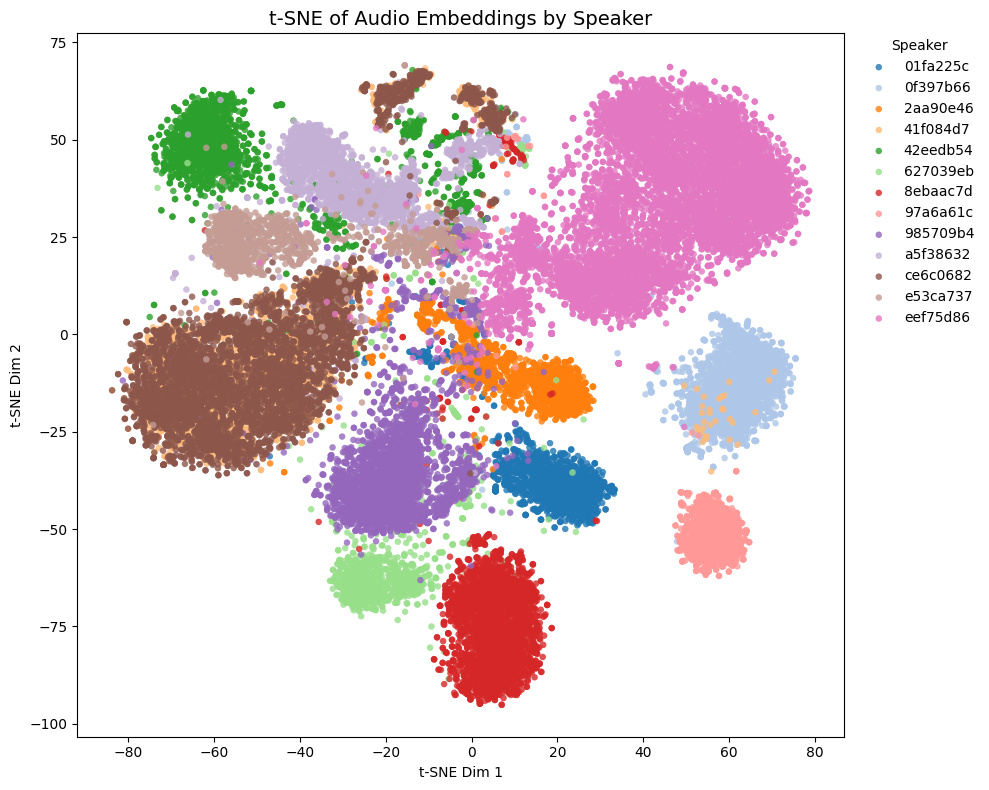 |
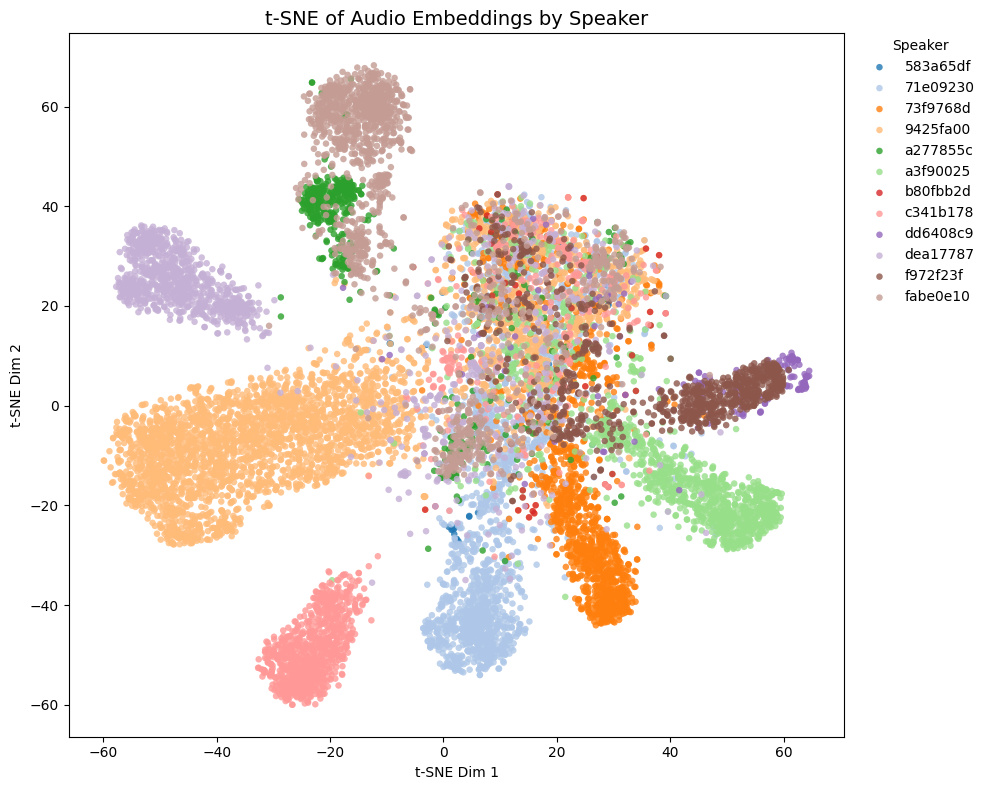
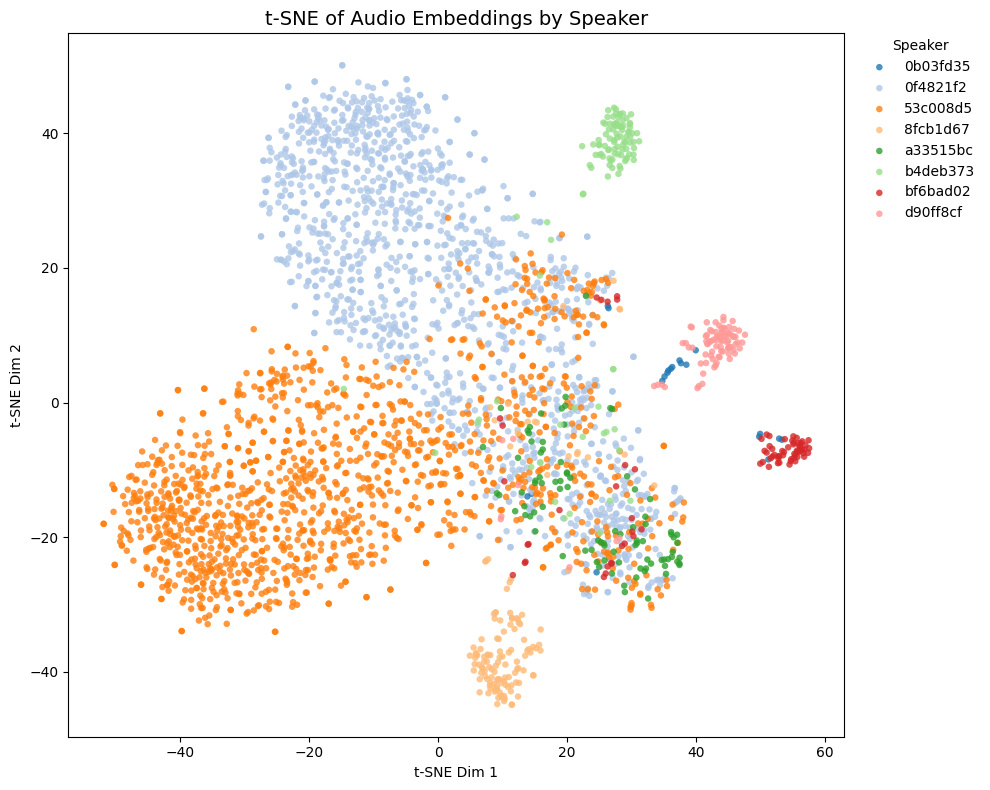
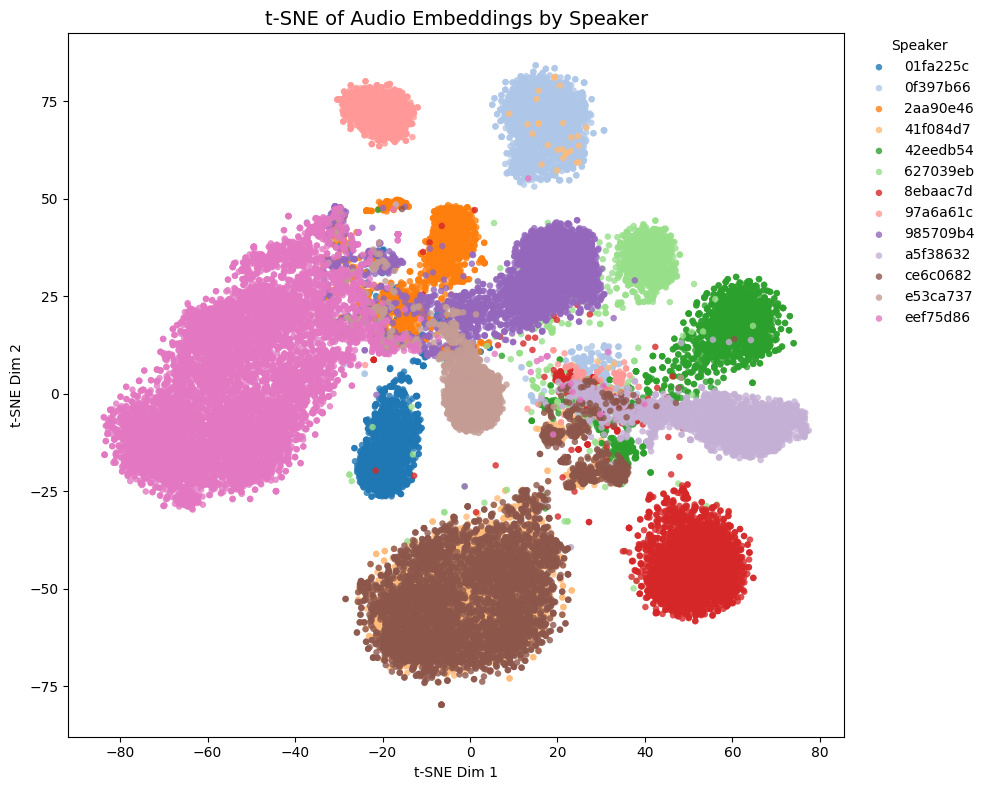
| pyannote/wespeaker-voxceleb-resnet34-LM | 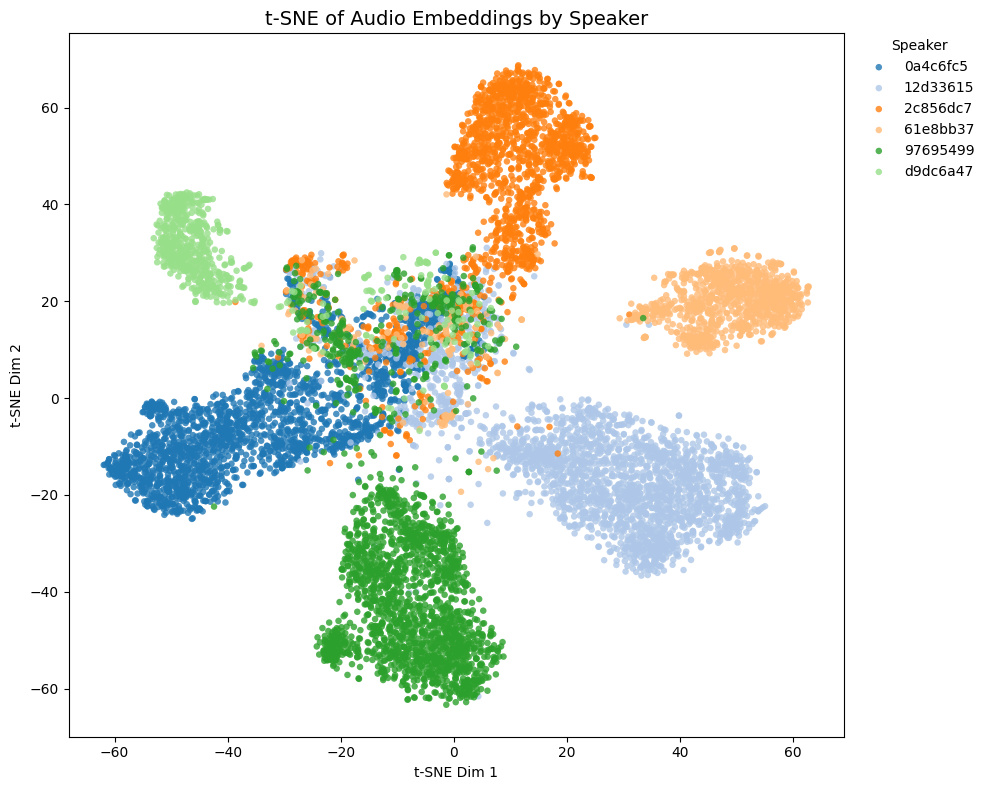 |
 |
 |
 |
| Resemblyzer | 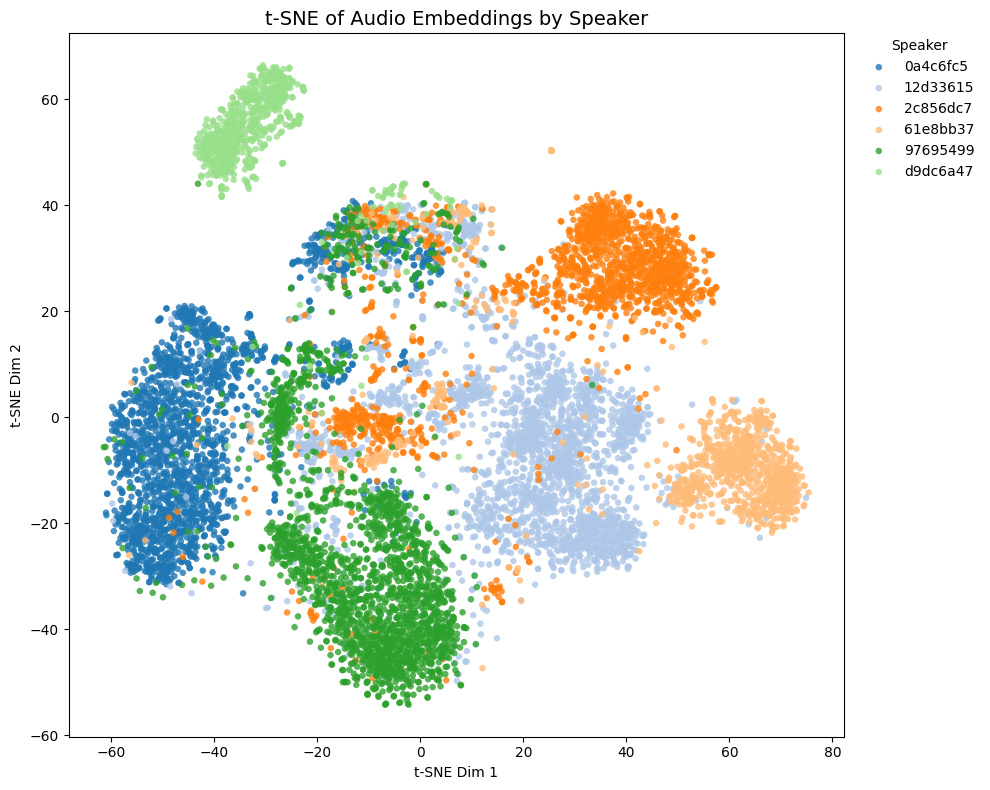 |
 |
 |
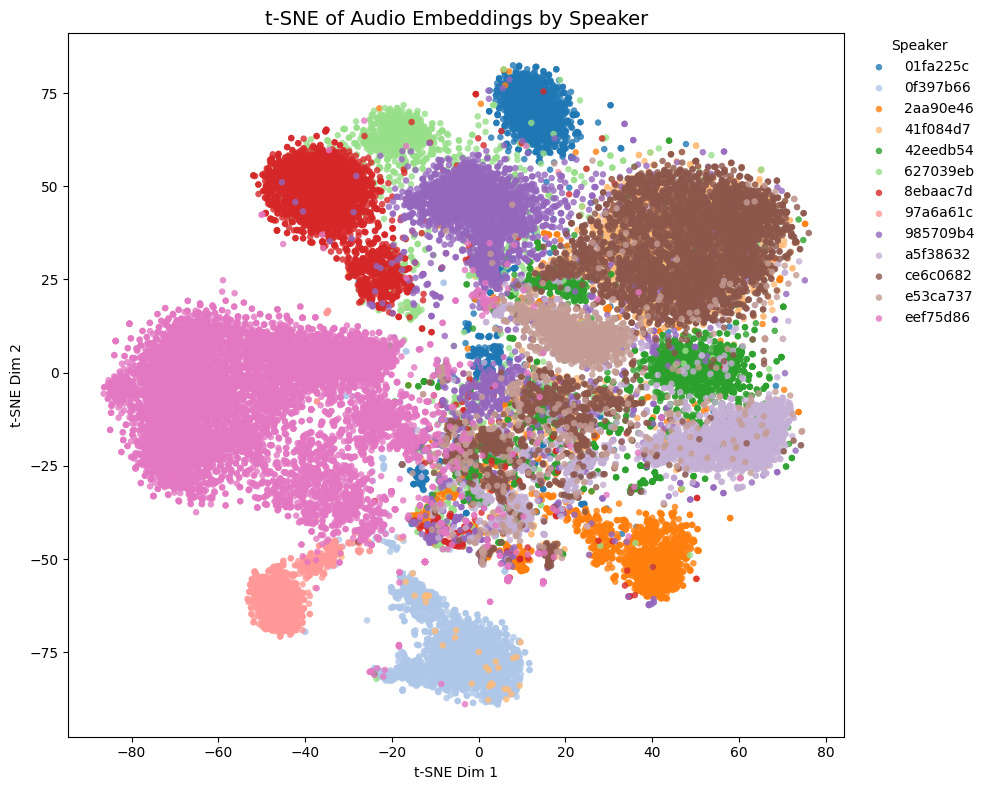 |
- Game1とGame2はNSFW音声を含み、Game3とGame4は含まない
- Game4では茶色と黄色の話者は実際には同一キャラクター
モデル詳細
モデルアーキテクチャ
本モデルはSpeechBrainのECAPA-TDNN全てのBatchNormレイヤーをGroupNormに置き換えています。元のBatchNorm層で評価時におそらく統計のドリフトが発生し、うまく推論できなかったためです。
データセット
charバリアント
OOPPEENN/56697375616C4E6F76656C5F44617461736574の全音声ファイルから破損ファイル等を除外し、100ファイル未満の話者を除外。最終データセット:
- train: 6,260,482 ファイル、valid: 699,488 ファイル、合計 6,959,970 ファイル
- 7,357 人のキャラクター
vaバリアント
litagin/VisualNovel_Dataset_Metadataを用いて、VNDBに声優が登録されているキャラクターのみ使用。最終データセット:
- train: 6,603,080 ファイル、valid: 348,034 ファイル、合計 6,951,114 ファイル
- 989 人の声優
学習プロセス
charバリアント
- speechbrain/spkrec-ecapa-voxcelebをベースモデルとして使用
- その後BatchNormをすべてGroupNormに置換
- fbank前に
x = x * 32768.0のスケーリングを追加(ChatGPTがそういうコード出してきたので……。あとからこのスケーリングは互換性上よくないことに気づいたけど手遅れでした) - いろいろ変えてるので、実際はファインチューニングではなくスクラッチからの学習に近いと思います
- ファイル数が多い上位100、1000キャラクターのサブセットで事前学習
- フルデータセットで学習
- オンラインデータ拡張(リバーブ、バックグラウンドノイズ、各種フィルタ等)を加えて再学習
- 同一シリーズ・同一キャラクター名で混同行列が高いキャラクター(同じゲームシリーズの同一キャラ相当)をいくつかマージして学習
vaバリアント
- Charバリアントの埋め込み器をベースに、データセットを声優のに変えてファインチューニング
- オーグメンテーション確率0.8
- バリデーションセットでMacro精度・再現率・F1・EERを評価し、EER0.41%のモデルを採用 (Macro precision 95.97%, Recall 97.83%、F1 96.80%)
トレーニングコードは別リポジトリで公開予定です。
English README
Overview
- ECAPA-TDNN model (from SpeechBrain) trained on OOPPEENN/56697375616C4E6F76656C5F44617461736574
- This model is designed for speaker embedding tasks in anime and visual novel contexts.
- 2025-06-22: Added Voice Actor (VA) variant in version 0.2.0, which is less eager to distinguish speakers compared to the default Character (char) variant.
Features
- Well-suited for Japanese anime-like voices, including non-verbal vocalizations or acted voices
- Also works well for NSFW erotic utterances and vocalizations such as aegi (喘ぎ) and chupa-sound (チュパ音), which are important in Japanese Visual Novel games, while other usual speaker embedding models cannot distinguish such voices of different speakers at all!
Model Variants
- char (default): Trained to guess character voices, not voice actors; eager to distinguish speakers (even two characters with the same voice actor).
- va (added in ver 0.2.0): Trained on voice actors, not characters; less eager to distinguish speakers.
For a single fixed character, the char model produces embeddings with higher variance by style, while the va model keeps embeddings more similar (lower variance).
Note
- Because this model tries to eagerly distinguish speakers, cosine similarity values between embeddings of the same speaker are usually lower than in other embedding models.
Installation
pip install torch --index-url https://download.pytorch.org/whl/cu128 # if you want to use GPU
pip install anime_speaker_embedding
Usage
from anime_speaker_embedding import AnimeSpeakerEmbedding
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
model = AnimeSpeakerEmbedding(device=device, variant="char") # or variant="va" for Voice Actor model
audio_path = "path/to/audio.wav"
embedding = model.get_embedding(audio_path)
print(embedding.shape) # np.ndarray with shape (192,)
See example.ipynb for usage and visualization examples.
Comparison with other models
t-SNE plots of embeddings from some Galgames (not included in the training set!):
| Model | Game1 | Game2 | Game3 | Game4 |
|---|---|---|---|---|
| ⭐ VA model | |
|
|
|
| ⭐ Char model | |
|
|
|
| speechbrain/spkrec-ecapa-voxceleb | |
|
|
|
| pyannote/wespeaker-voxceleb-resnet34-LM | |
|
|
|
| Resemblyzer | |
|
|
|
- Game1 and Game2 contain NSFW voices; Game3 and Game4 do not.
- In Game4, the brown and yellow speakers are actually the same character.
Model Details
Model Architecture
The actual model is SpeechBrain’s ECAPA-TDNN with all BatchNorm layers replaced by GroupNorm, due to statistical drift issues during evaluation.
Dataset
Char variant
From the OOPPEENN/56697375616C4E6F76656C5F44617461736574 dataset, broken files and speakers with fewer than 100 files were excluded. Final:
- train: 6,260,482 files, valid: 699,488 files, total: 6,959,970 files
- 7,357 speakers
VA variant
Using litagin/VisualNovel_Dataset_Metadata, only characters whose VAs are in VNDB were kept. Final:
- train: 6,603,080 files, valid: 348,034 files, total: 6,951,114 files
- 989 speakers
Training process
char variant
- Base: speechbrain/spkrec-ecapa-voxceleb; replaced BN→GN; added
x = x * 32768.0before fbank- ChatGPT suggested this scaling, but it turned out to be incompatible later.
- I guess the model is rather trained from scratch, not fine-tuned actually.
- Pretrained on top-100/1000 speakers subset
- Trained on full dataset
- Retrained with online augmentations (reverb, noise, filters)
- Merged speakers with high confusion from same series/character
va variant
- Fine-tuned
charbackbone (aug prob 0.8) - Selected model with best EER (0.41%); Macro precision 95.97%, recall 97.83%, F1 96.80%
Training code to be released separately.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file anime_speaker_embedding-0.2.1.tar.gz.
File metadata
- Download URL: anime_speaker_embedding-0.2.1.tar.gz
- Upload date:
- Size: 97.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.7.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
d5264a3ee0856e8cc4fb7e4610920389b11388b25791c277944cbd99acba3bf3
|
|
| MD5 |
d35a81eeb53297da265ee57231656d2e
|
|
| BLAKE2b-256 |
66ca4918776b0ed569b3e6b71e6bbfa4670e53a37d82e67b66b09ce370e0c2ab
|
File details
Details for the file anime_speaker_embedding-0.2.1-py3-none-any.whl.
File metadata
- Download URL: anime_speaker_embedding-0.2.1-py3-none-any.whl
- Upload date:
- Size: 9.2 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.7.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e19baf99c3c803743d8b9705a87aa1068c6a019bef949a2f8c4869f8c7f680c4
|
|
| MD5 |
76d7ea431595122cd3af403cf4a9d04e
|
|
| BLAKE2b-256 |
9b64ecc2de00810c7a23ab8b7dadd9f05a51e9b59bd338f3d5e8c95a5899bc94
|







